Auf dieser Seite wird beschrieben, wie Sie die Bereitstellung von GKE Inference Gateway anpassen.
Diese Seite richtet sich an Netzwerkexperten, die für die Verwaltung der GKE-Infrastruktur verantwortlich sind, und an Plattformadministratoren, die KI-Arbeitslasten verwalten.
Sie konfigurieren erweiterte Funktionen von GKE Inference Gateway, um Inferenzarbeitslasten zu verwalten und zu optimieren.
Machen Sie sich mit den folgenden erweiterten Funktionen vertraut und konfigurieren Sie sie:
- Wenn Sie die Model Armor-Integration verwenden möchten, konfigurieren Sie die KI-Sicherheitsprüfungen.
- Wenn Sie GKE Inference Gateway mit Funktionen wie API-Sicherheit, Ratenbegrenzung und Analysen erweitern möchten, konfigurieren Sie Apigee für die Authentifizierung und API-Verwaltung.
- Wenn Sie Anfragen anhand des Modellnamens im Anfragetext weiterleiten möchten, konfigurieren Sie das Body-basierte Routing.
- Wenn Sie Messwerte und Dashboards für GKE Inference Gateway und Modellserver aufrufen und HTTP-Zugriffsprotokollierung aktivieren möchten, konfigurieren Sie die Beobachtbarkeit.
- Wenn Sie Ihre GKE Inference Gateway-Bereitstellungen automatisch skalieren möchten, konfigurieren Sie die automatische Skalierung.
KI-Sicherheits- und ‑Sicherheitsprüfungen konfigurieren
GKE Inference Gateway ist in Model Armor integriert, um Sicherheitsprüfungen für Prompts und Antworten für Anwendungen durchzuführen, die Large Language Models (LLMs) verwenden. Diese Integration bietet eine zusätzliche Ebene für die Durchsetzung von Sicherheitsmaßnahmen auf Infrastrukturebene, die die Sicherheitsmaßnahmen auf Anwendungsebene ergänzt. So können Richtlinien zentral auf den gesamten LLM-Traffic angewendet werden.
Das folgende Diagramm zeigt die Integration von Model Armor in das GKE Inference Gateway in einem GKE-Cluster:
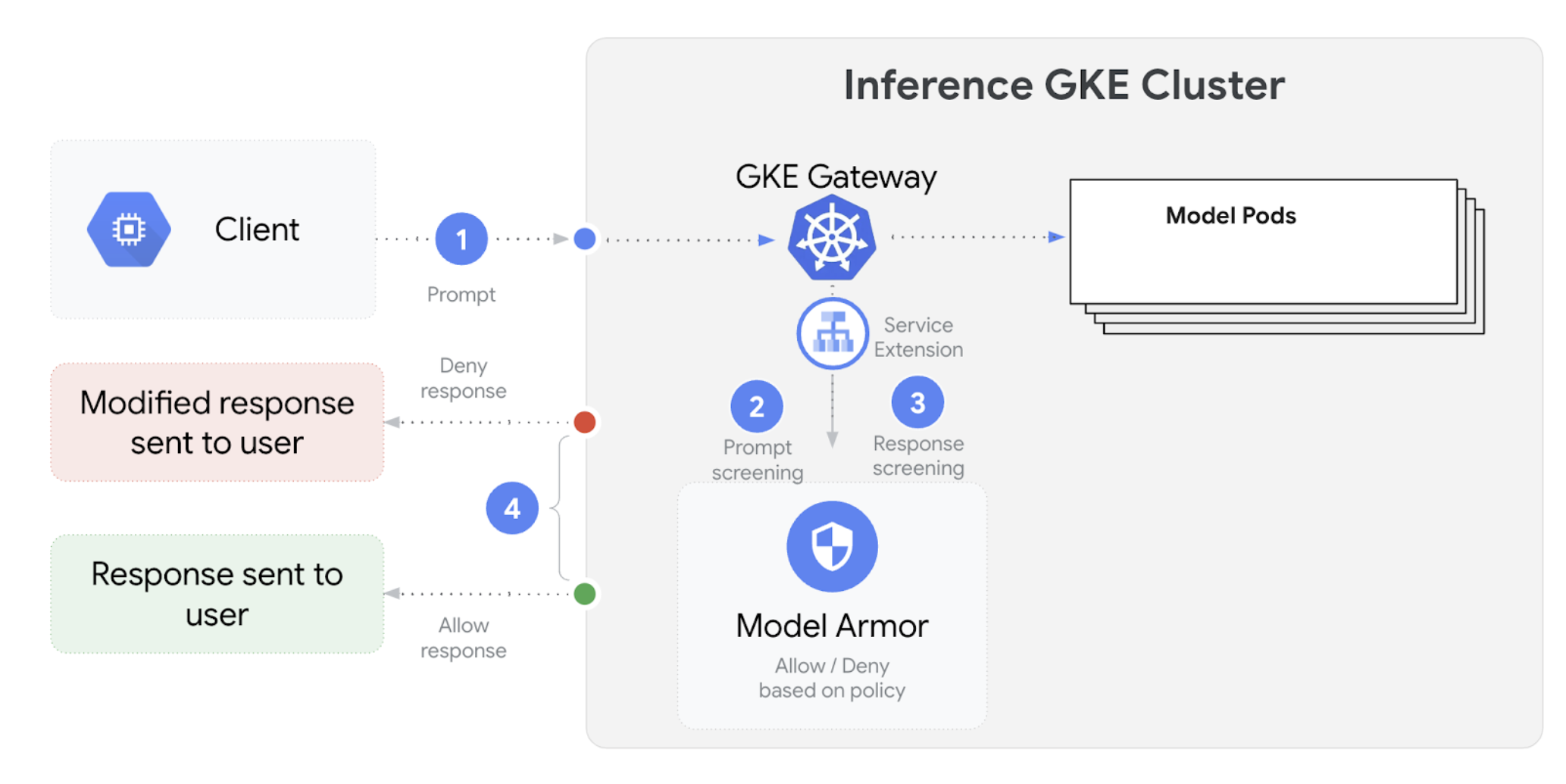
So konfigurieren Sie KI-Sicherheitsprüfungen:
Vorbereitung
- Aktivieren Sie den Model Armor-Dienst in Ihrem Google Cloud -Projekt.
Erstellen Sie die Model Armor-Vorlagen mit der Model Armor-Konsole, der Google Cloud CLI oder der API. Mit dem folgenden Befehl wird eine Vorlage mit dem Namen
llmerstellt, in der Vorgänge protokolliert und nach schädlichen Inhalten gefiltert wird.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
IAM-Berechtigungen gewähren
Das Dienstkonto für Dienst-Erweiterungen benötigt Berechtigungen für den Zugriff auf die erforderlichen Ressourcen. Weisen Sie die erforderlichen Rollen mit den folgenden Befehlen zu:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.userGCPTrafficExtensionkonfigurierenWenn Sie die Model Armor-Richtlinien auf Ihr Gateway anwenden möchten, erstellen Sie eine
GCPTrafficExtension-Ressource mit dem richtigen Metadatenformat.Speichern Sie das folgende Beispielmanifest als
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Ersetzen Sie Folgendes:
GATEWAY_NAME: Der Name des Gateways.MODEL_ARMOR_TEMPLATE_NAME: Der Name Ihrer Model Armor-Vorlage.
Die Datei
gcp-traffic-extension.yamlenthält die folgenden Einstellungen:targetRefs: gibt das Gateway an, für das diese Erweiterung gilt.extensionChains: Definiert eine Kette von Erweiterungen, die auf den Traffic angewendet werden sollen.matchCondition: Definiert die Bedingungen, unter denen die Erweiterungen angewendet werden.extensions: Definiert die anzuwendenden Erweiterungen.supportedEvents: Gibt die Ereignisse an, bei denen die Erweiterung aufgerufen wird.timeout: Gibt das Zeitlimit für die Erweiterung an.googleAPIServiceName: Gibt den Dienstnamen für die Erweiterung an.metadata: Gibt die Metadaten für die Erweiterung an, einschließlich derextensionPolicyund der Einstellungen für die Bereinigung von Prompts oder Antworten.
Wenden Sie das Beispielmanifest auf Ihren Cluster an:
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Nachdem Sie die KI-Sicherheitsprüfungen konfiguriert und in Ihr Gateway eingebunden haben, filtert Model Armor Prompts und Antworten automatisch anhand der definierten Regeln.
Apigee für Authentifizierung und API-Verwaltung konfigurieren
GKE Inference Gateway ist in Apigee eingebunden und bietet Authentifizierung, Autorisierung und API-Verwaltung für Ihre Inferenzarbeitslasten. Weitere Informationen zu den Vorteilen von Apigee finden Sie unter Wichtige Vorteile der Verwendung von Apigee.
Sie können GKE Inference Gateway in Apigee einbinden, um es mit Funktionen wie API-Sicherheit, Ratenbegrenzung, Kontingenten, Analysen und Monetarisierung zu erweitern.
Vorbereitung
Bevor Sie beginnen, benötigen Sie Folgendes:
- Ein GKE-Cluster mit Version 1.34.* oder höher.
- Ein GKE-Cluster mit bereitgestelltem GKE Inference Gateway.
- Eine Apigee-Instanz, die in derselben Region wie Ihr GKE-Cluster erstellt wurde.
- Der Apigee APIM-Operator und seine CRDs sind in Ihrem GKE-Cluster installiert. Eine Anleitung finden Sie unter Apigee APIM-Operator installieren.
kubectlist für die Verbindung zu Ihrem GKE-Cluster konfiguriert.Google Cloud CLIist installiert und authentifiziert.
ApigeeBackendService erstellen
Erstellen Sie zuerst eine ApigeeBackendService-Ressource. GKE Inference Gateway verwendet dies, um einen Apigee Extension Processor zu erstellen.
Speichern Sie das folgende Manifest als
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Ersetzen Sie Folgendes:
APIGEE_ENVIRONMENT_NAME: Der Name Ihrer Apigee-Umgebung. Hinweis: Sie müssen dieses Feld nicht festlegen, wennapigee-apim-operatormit dem FlaggenerateEnv=TRUEinstalliert wird. Erstellen Sie andernfalls eine Apigee-Umgebung. Folgen Sie dazu der Anleitung unter Umgebung erstellen.LOCATION: Der Standort Ihrer Apigee-Instanz.CLUSTER_NETWORK: Das Netzwerk Ihres GKE-Cluster.CLUSTER_SUBNETWORK: Das Subnetzwerk Ihres GKE-Cluster.
Wenden Sie das Manifest auf Ihren Cluster an:
kubectl apply -f my-apigee-backend-service.yamlPrüfen Sie, ob der Status
CREATEDlautet:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
GKE Inference Gateway konfigurieren
Konfigurieren Sie das GKE Inference Gateway, um den Apigee Extension Processor als Load-Balancer-Traffic-Erweiterung zu aktivieren.
Speichern Sie das folgende Manifest als
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Ersetzen Sie
GATEWAY_NAMEdurch den Namen Ihres Gateways.Wenden Sie das Manifest auf Ihren Cluster an:
kubectl apply -f my-apigee-traffic-extension.yamlWarten Sie, bis der Status von
GCPTrafficExtensionzuProgrammedwechselt:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Authentifizierte Anfragen mit API-Schlüsseln senden
So finden Sie die IP-Adresse Ihres GKE Inference-Gateways:
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Ersetzen Sie
GATEWAY_NAMEdurch den Namen Ihres Gateways.Testen Sie eine Anfrage ohne Authentifizierung. Diese Anfrage sollte abgelehnt werden:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Sie erhalten eine Antwort ähnlich der folgenden, die darauf hinweist, dass die Apigee-Erweiterung funktioniert:
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Greifen Sie auf die Apigee-Benutzeroberfläche zu und erstellen Sie einen API-Schlüssel. Eine Anleitung dazu finden Sie unter API-Schlüssel erstellen.
Senden Sie den API-Schlüssel im HTTP-Anfrageheader:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Ersetzen Sie
API_KEYdurch Ihren API-Schlüssel.
Weitere Informationen zum Konfigurieren von Apigee-Richtlinien finden Sie unter API-Verwaltungsrichtlinien mit dem Apigee APIM Operator für Kubernetes verwenden.
Beobachtbarkeit konfigurieren
GKE Inference Gateway bietet Einblicke in den Zustand, die Leistung und das Verhalten Ihrer Inferenzarbeitslasten. So können Sie Probleme identifizieren und beheben, die Ressourcennutzung optimieren und die Zuverlässigkeit Ihrer Anwendungen sicherstellen.
Google Cloud bietet die folgenden Cloud Monitoring-Dashboards, die eine Beobachtbarkeit der Inferenz für das GKE Inference Gateway ermöglichen:
- GKE Inference Gateway-Dashboard: Bietet wichtige Messwerte für die Bereitstellung von LLMs, z. B. Anfrage- und Token-Durchsatz, Latenz, Fehler und Cache-Auslastung für
InferencePool. Eine vollständige Liste der verfügbaren GKE Inference Gateway-Messwerte finden Sie unter Exposed metrics. - AI/ML-Observability-Dashboards: Bietet Dashboards für die Infrastrukturnutzung, DCGM-Messwerte und Leistungsstatistiken für vLLM-Modelle.
- Dashboard für Modellserver: Bietet ein Dashboard für goldene Signale des Modellservers. So können Sie die Last und Leistung der Modellserver überwachen, z. B.
KVCache UtilizationundQueue length. - Load-Balancer-Dashboard: Hier werden Messwerte des Load-Balancers wie Anfragen pro Sekunde, End-to-End-Latenz bei der Anfragebearbeitung und Anfrage-Antwort-Statuscodes angezeigt. Mithilfe dieser Messwerte können Sie die Leistung der End-to-End-Anfragebearbeitung nachvollziehen und Fehler identifizieren.
- Data Center GPU Manager-Messwerte (DCGM): Bietet DCGM-Messwerte wie Leistung und Auslastung von NVIDIA-GPUs. Sie können DCGM-Messwerte in Cloud Monitoring konfigurieren. Weitere Informationen finden Sie unter DCGM-Messwerte erfassen und ansehen.
GKE Inference Gateway-Dashboard aufrufen
So rufen Sie das GKE Inference Gateway-Dashboard auf:
Rufen Sie in der Google Cloud Console die Seite Monitoring auf.
Wählen Sie im Navigationsbereich die Option Dashboards aus.
Wählen Sie im Bereich Integrationen die Option GMP aus.
Suchen Sie auf der Seite Cloud Monitoring Dashboard Templates (Cloud Monitoring-Dashboardvorlagen) nach „Gateway“.
Rufen Sie das GKE Inference Gateway-Dashboard auf.
Alternativ können Sie der Anleitung unter Monitoring-Dashboard folgen.
Observability-Dashboards für KI‑/ML-Modelle aufrufen
So rufen Sie Ihre bereitgestellten Modelle und Dashboards für Beobachtbarkeitsmesswerte eines Modells auf:
Rufen Sie in der Google Cloud Console die Seite Bereitgestellte Modelle auf.
Wenn Sie Details zu einer bestimmten Bereitstellung aufrufen möchten, einschließlich der zugehörigen Messwerte, Logs und Dashboards, klicken Sie in der Liste auf den Modellnamen.
Klicken Sie auf der Seite mit den Modelldetails auf den Tab Beobachtbarkeit, um die folgenden Dashboards aufzurufen. Klicken Sie bei entsprechender Aufforderung auf Aktivieren, um das Dashboard zu aktivieren.
- Im Dashboard Infrastrukturnutzung werden Auslastungsmesswerte angezeigt.
- Im DCGM-Dashboard werden DCGM-Messwerte angezeigt.
- Wenn Sie vLLM verwenden, ist das Dashboard Modellleistung verfügbar und zeigt Messwerte für die vLLM-Modellleistung an.
Dashboard für die Beobachtbarkeit des Modellservers konfigurieren
Wenn Sie Golden Signals von jedem Modellserver erfassen und nachvollziehen möchten, was zur Leistung des GKE Inference Gateway beiträgt, können Sie die automatische Überwachung für Ihre Modellserver konfigurieren. Dazu gehören Modellserver wie die folgenden:
Damit Sie die Integrationsdashboards aufrufen können, müssen Sie zuerst Messwerte von Ihrem Modellserver erfassen. Führen Sie dann folgende Schritte aus:
Rufen Sie in der Google Cloud Console die Seite Monitoring auf.
Wählen Sie im Navigationsbereich die Option Dashboards aus.
Wählen Sie unter Integrationen die Option GMP aus. Die entsprechenden Integrationsdashboards werden angezeigt.
Abbildung : Integrationsdashboards
Weitere Informationen finden Sie unter Überwachung für Anwendungen anpassen.
Cloud Monitoring-Benachrichtigungen konfigurieren
So konfigurieren Sie Cloud Monitoring-Benachrichtigungen für GKE Inference Gateway:
Speichern Sie das folgende Beispielmanifest als
alerts.yamlund passen Sie die Grenzwerte nach Bedarf an:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Führen Sie folgenden Befehl aus, um Benachrichtigungsrichtlinien zu erstellen:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlNeue Benachrichtigungsrichtlinien werden auf der Seite Benachrichtigungen angezeigt.
Benachrichtigungen ändern
Eine vollständige Liste der neuesten verfügbaren Messwerte finden Sie im GitHub-Repository kubernetes-sigs/gateway-api-inference-extension. Sie können dem Manifest auch neue Benachrichtigungen mit anderen Messwerten hinzufügen.
Wenn Sie die Beispielbenachrichtigungen ändern möchten, sehen Sie sich das folgende Beispiel an:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Diese Benachrichtigung wird ausgelöst, wenn das 99. Perzentil der Anfragedauer über 5 Minuten 10 Sekunden überschreitet. Sie können den expr-Abschnitt der Benachrichtigung ändern, um den Schwellenwert an Ihre Anforderungen anzupassen.
Logging für GKE Inference Gateway konfigurieren
Wenn Sie das Logging für GKE Inference Gateway konfigurieren, erhalten Sie detaillierte Informationen zu Anfragen und Antworten, die für die Fehlerbehebung, das Auditieren und die Leistungsanalyse nützlich sind. In HTTP-Zugriffsprotokollen werden alle Anfragen und Antworten aufgezeichnet, einschließlich Headern, Statuscodes und Zeitstempeln. Mit diesem Detaillierungsgrad können Sie Probleme und Fehler identifizieren und das Verhalten Ihrer Inferenzarbeitslasten nachvollziehen.
Wenn Sie die Protokollierung für GKE Inference Gateway konfigurieren möchten, aktivieren Sie die HTTP-Zugriffsprotokollierung für jedes Ihrer InferencePool-Objekte.
Speichern Sie das folgende Beispielmanifest als
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMEErsetzen Sie Folgendes:
NAMESPACE_NAME: der Name des Namespace, in dem IhreInferencePoolbereitgestellt wird.INFERENCE_POOL_NAMEist der Name desInferencePool.
Wenden Sie das Beispielmanifest auf Ihren Cluster an:
kubectl apply -f logging-backend-policy.yaml
Nachdem Sie dieses Manifest angewendet haben, aktiviert GKE Inference Gateway HTTP-Zugriffsprotokolle für die angegebene InferencePool. Sie können diese Logs in Cloud Logging aufrufen. Die Logs enthalten detaillierte Informationen zu jeder Anfrage und Antwort, z. B. die Anfrage-URL, Header, den Antwortstatuscode und die Latenz.
Logbasierte Messwerte erstellen, um Fehlerdetails anzusehen
Sie können logbasierte Messwerte verwenden, um Ihre Load-Balancing-Logs zu analysieren und Fehlerdetails zu extrahieren. Jede GKE-Gateway-Klasse, z. B. die Gateway-Klassen gke-l7-global-external-managed und gke-l7-regional-internal-managed, wird von einem anderen Load-Balancer unterstützt. Weitere Informationen finden Sie unter GatewayClass-Funktionen.
Jeder Load-Balancer hat eine andere überwachte Ressource, die Sie beim Erstellen eines logbasierten Messwerts verwenden müssen. Weitere Informationen zur überwachten Ressource für jeden Load-Balancer finden Sie hier:
- Für regionale externe Load-Balancer: Logbasierte Messwerte für externe HTTP(S)-Load-Balancer
- Für interne Load-Balancer: Logbasierte Messwerte für interne HTTP(S)-Load-Balancer
So erstellen Sie einen logbasierten Messwert, um Fehlerdetails aufzurufen:
Erstellen Sie eine JSON-Datei mit dem Namen
error_detail_metric.jsonund der folgendenLogMetric-Definition. Bei dieser Konfiguration wird ein Messwert erstellt, mit dem das FeldproxyStatusaus Ihren Load-Balancer-Logs extrahiert wird.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Ersetzen Sie
MONITORED_RESOURCEdurch die überwachte Ressource für Ihren Load-Balancer.Öffnen Sie Cloud Shell oder Ihr lokales Terminal, auf dem die gcloud CLI installiert ist.
Führen Sie den Befehl
gcloud logging metrics createmit dem Flag--config-from-fileaus, um den Messwert zu erstellen:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Nachdem der Messwert erstellt wurde, können Sie ihn in Cloud Monitoring verwenden, um die Verteilung der vom Load-Balancer gemeldeten Fehler anzusehen. Weitere Informationen finden Sie unter Logbasierten Messwert erstellen.
Weitere Informationen zum Erstellen von Benachrichtigungen aus logbasierten Messwerten finden Sie unter Benachrichtigungsrichtlinie für einen Zählermesswert erstellen.
Autoscaling konfigurieren
Beim Autoscaling wird die Ressourcenzuweisung als Reaktion auf Lastschwankungen angepasst. Die Leistung und Ressourceneffizienz werden aufrechterhalten, indem Pods je nach Bedarf dynamisch hinzugefügt oder entfernt werden. Für das GKE Inference Gateway umfasst dies das horizontale Autoscaling von Pods in jeder InferencePool. Das horizontale Pod-Autoscaling (HPA) von GKE skaliert Pods automatisch basierend auf Messwerten des Modellservers wie KVCache Utilization. So kann der Inferenzdienst verschiedene Arbeitslasten und Anfragevolumen verarbeiten und gleichzeitig die Ressourcennutzung effizient verwalten.
So konfigurieren Sie InferencePool-Instanzen für das automatische Skalieren basierend auf Messwerten, die von GKE Inference Gateway erzeugt werden:
Stellen Sie ein
PodMonitoring-Objekt im Cluster bereit, um Messwerte zu erfassen, die vom GKE Inference Gateway generiert werden. Weitere Informationen finden Sie unter Observability konfigurieren.Stellen Sie den Stackdriver-Adapter für benutzerdefinierte Messwerte bereit, um HPA Zugriff auf die Messwerte zu gewähren:
Speichern Sie das folgende Beispielmanifest als
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemWenden Sie das Beispielmanifest auf Ihren Cluster an:
kubectl apply -f adapter_new_resource_model.yaml
Führen Sie den folgenden Befehl aus, um dem Adapter die Berechtigung zu erteilen, Messwerte aus dem Projekt zu lesen:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterErsetzen Sie dabei
PROJECT_IDdurch die ID Ihres Projekts in Google Cloud .Stellen Sie für jede
InferencePoolein HPA bereit, das dem folgenden ähnelt:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUEErsetzen Sie Folgendes:
INFERENCE_POOL_NAMEist der Name desInferencePool.INFERENCE_POOL_NAMESPACE: der Namespace desInferencePool.CLUSTER_NAMEist der Name des Clusters.MIN_REPLICAS: Die Mindestverfügbarkeit derInferencePool(Basiskapazität). HPA hält diese Anzahl von Replikaten aufrecht, wenn die Nutzung unter dem HPA-Zielgrenzwert liegt. Bei Arbeitslasten mit hoher Verfügbarkeit muss dieser Wert auf einen Wert über1festgelegt werden, um die Verfügbarkeit bei Pod-Unterbrechungen aufrechtzuerhalten.MAX_REPLICAS: Der Wert, der die Anzahl der Beschleuniger begrenzt, die den imInferencePoolgehosteten Arbeitslasten zugewiesen werden müssen. HPA erhöht die Anzahl der Replikate nicht über diesen Wert hinaus. Behalten Sie während der Spitzenzeiten die Anzahl der Replikate im Blick, um sicherzustellen, dass der Wert des FeldsMAX_REPLICASgenügend Spielraum bietet, damit die Arbeitslast skaliert werden kann, um die ausgewählten Leistungsmerkmale der Arbeitslast beizubehalten.TARGET_VALUE: Der Wert, der das ausgewählte ZielKV-Cache Utilizationpro Modellserver darstellt. Dies ist eine Zahl zwischen 0 und 100 und hängt stark vom Modellserver, Modell, Beschleuniger und den Merkmalen des eingehenden Traffics ab. Sie können diesen Zielwert experimentell ermitteln, indem Sie Lasttests durchführen und ein Diagramm mit Durchsatz und Latenz erstellen. Wählen Sie im Diagramm eine Kombination aus Durchsatz und Latenz aus und verwenden Sie den entsprechendenKV-Cache Utilization-Wert als HPA-Ziel. Sie müssen diesen Wert anpassen und genau im Blick behalten, um die gewünschten Ergebnisse in Bezug auf das Preis-Leistungs-Verhältnis zu erzielen. Sie können die GKE Inference-Kurzanleitung verwenden, um diesen Wert automatisch zu ermitteln.
Nächste Schritte
- Informationen zum GKE Inference Gateway
- GKE Inference Gateway bereitstellen.
- GKE Inference Gateway-Rolloutvorgänge verwalten:
- Mit GKE Inference Gateway bereitstellen: