Auf dieser Seite werden die wichtigsten Konzepte und Funktionen von GKE Inference Gateway erläutert, einer Erweiterung des GKE Gateway für die optimierte Bereitstellung von Anwendungen mit generativer KI.
Auf dieser Seite wird davon ausgegangen, dass Sie mit Folgendem vertraut sind:
- KI‑/ML-Orchestrierung in GKE
- Terminologie für generative KI
- GKE-Netzwerkkonzepte, einschließlich Dienste und der GKE Gateway API
- Load-Balancing in Google Cloud, insbesondere die Interaktion von Load-Balancern mit GKE
Diese Seite richtet sich an folgende Nutzer:
- Entwickler für maschinelles Lernen (ML), Plattformadministratoren und ‑operatoren sowie Daten- und KI-Spezialisten, die daran interessiert sind, Kubernetes-Container-Orchestrierungsfunktionen für die Bereitstellung von KI‑/ML-Arbeitslasten zu nutzen.
- Cloud-Architekten und Netzwerkspezialisten, die mit Kubernetes-Netzwerken interagieren.
Übersicht
Das GKE Inference Gateway ist eine Erweiterung des GKE Gateway, das optimiertes Routing und Load Balancing für die Bereitstellung von Arbeitslasten mit generativer künstlicher Intelligenz (KI) bietet. Sie vereinfacht die Bereitstellung, Verwaltung und Beobachtung von KI-Inferenz-Arbeitslasten.
Informationen zum Auswählen der optimalen Load-Balancing-Strategie für Ihre KI-/ML-Arbeitslasten finden Sie unter Load-Balancing-Strategie für KI-Inferenz in GKE auswählen.
Features und Vorteile
GKE Inference Gateway bietet die folgenden wichtigen Funktionen, um generative KI-Modelle für generative KI-Anwendungen in GKE effizient bereitzustellen:
- Unterstützte Messwerte:
KV cache hits: die Anzahl der erfolgreichen Suchvorgänge im Key-Value-Cache (KV-Cache).- GPU- oder TPU-Auslastung: Der Prozentsatz der Zeit, in der die GPU oder TPU aktiv Daten verarbeitet.
- Länge der Anfragewarteschlange: Die Anzahl der Anfragen, die auf die Verarbeitung warten.
- Optimiertes Load-Balancing für die Inferenz: Anfragen werden verteilt, um die Leistung von KI-Modellen zu optimieren. Dabei werden Messwerte von Modellservern wie
KV cache hitsundqueue length of pending requestsverwendet, um Beschleuniger (z. B. GPUs und TPUs) für generative KI-Arbeitslasten effizienter zu nutzen. Dadurch wird Prefix-Cache Aware Routing aktiviert. Diese wichtige Funktion sendet Anfragen mit gemeinsamem Kontext, der durch Analyse des Anfragetexts ermittelt wird, an dieselbe Modellreplik, um Cache-Treffer zu maximieren. Dieser Ansatz reduziert redundante Berechnungen drastisch und verbessert die Zeit bis zum ersten Token. Daher ist er sehr effektiv für konversationelle KI, Retrieval-Augmented Generation (RAG) und andere vorlagenbasierte Arbeitslasten für generative KI. - Bereitstellung dynamischer LoRA-optimierter Modelle: Unterstützt die Bereitstellung dynamischer LoRA-optimierter Modelle auf einem gemeinsamen Beschleuniger. Dadurch wird die Anzahl der GPUs und TPUs reduziert, die für die Bereitstellung von Modellen erforderlich sind, da mehrere LoRA-abgestimmte Modelle auf einem gemeinsamen Basismodell und Beschleuniger gemultiplext werden.
- Optimiertes Autoscaling für die Inferenz: Der GKE Horizontal Pod Autoscaler (HPA) verwendet Messwerte des Modellservers für das Autoscaling. So wird eine effiziente Nutzung der Rechenressourcen und eine optimierte Inferenzleistung ermöglicht.
- Modellbasiertes Routing: Leitet Inferenzanfragen basierend auf den Modellnamen weiter, die in den
OpenAI API-Spezifikationen in Ihrem GKE-Cluster definiert sind. Sie können Gateway-Routingrichtlinien wie Traffic-Splitting und Anfragen-Mirroring definieren, um verschiedene Modellversionen zu verwalten und die Einführung von Modellen zu vereinfachen. So können Sie beispielsweise Anfragen für einen bestimmten Modellnamen an verschiedeneInferencePool-Objekte weiterleiten, die jeweils eine andere Version des Modells bereitstellen. Weitere Informationen zum Konfigurieren dieser Funktion finden Sie unter Body-Based Routing konfigurieren. - Integrierte KI-Sicherheits- und Inhaltsfilterung: GKE Inference Gateway ist in Google Cloud Model Armor integriert, um KI-Sicherheitsprüfungen und Inhaltsfilterung auf Prompts und Antworten am Gateway anzuwenden. Model Armor stellt Logs von Anfragen, Antworten und der Verarbeitung für die nachträgliche Analyse und Optimierung bereit. Die offenen Schnittstellen von GKE Inference Gateway ermöglichen es Drittanbietern und Entwicklern, benutzerdefinierte Dienste in den Prozess für Inferenzanfragen einzubinden.
- Modellspezifische Bereitstellung
Priority: Hiermit können Sie die BereitstellungPriorityvon KI-Modellen angeben. Priorisieren Sie latenzempfindliche Anfragen gegenüber latenzunempfindlichen Batchinferenzjobs. So können Sie beispielsweise Anfragen von latenzsensiblen Anwendungen priorisieren und weniger zeitkritische Aufgaben verwerfen, wenn die Ressourcen begrenzt sind. - Inference-Beobachtbarkeit: Bietet Beobachtbarkeitsmesswerte für Inferenzanfragen, z. B. Anfragerate, Latenz, Fehler und Sättigung. Sie können die Leistung und das Verhalten Ihrer Inferenzdienste mit Cloud Monitoring und Cloud Logging überwachen. Dazu stehen spezielle vordefinierte Dashboards zur Verfügung, die detaillierte Informationen liefern. Weitere Informationen finden Sie unter GKE Inference Gateway-Dashboard ansehen.
- Erweiterte API-Verwaltung mit Apigee: Wird in Apigee integriert, um Ihr Inferenz-Gateway mit Funktionen wie API-Sicherheit, Ratenbegrenzung und Kontingenten zu erweitern. Eine ausführliche Anleitung finden Sie unter Apigee für Authentifizierung und API-Verwaltung konfigurieren.
- Erweiterbarkeit: Basierend auf einer erweiterbaren, Open-Source-Kubernetes Gateway API Inference Extension, die einen nutzerverwalteten Endpoint Picker-Algorithmus unterstützt.
Schlüsselkonzepte
GKE Inference Gateway erweitert das vorhandene GKE Gateway, das GatewayClass-Objekte verwendet. Mit GKE Inference Gateway werden die folgenden neuen benutzerdefinierten Gateway API-Ressourcendefinitionen (CRDs) eingeführt, die an der OSS Kubernetes Gateway API-Erweiterung für Inference ausgerichtet sind:
InferencePool-Objekt: Stellt eine Gruppe von Pods (Containern) dar, die dieselbe Compute-Konfiguration, denselben Beschleunigertyp, dasselbe Basissprachmodell und denselben Modellserver verwenden. So werden Ihre Ressourcen für das Bereitstellen von KI-Modellen logisch gruppiert und verwaltet. Ein einzelnesInferencePool-Objekt kann sich über mehrere Pods auf verschiedenen GKE-Knoten erstrecken und bietet Skalierbarkeit und Hochverfügbarkeit.InferenceObjective-Objekt: Gibt den Namen des Bereitstellungsmodells ausInferencePoolgemäß derOpenAI API-Spezifikation an. DasInferenceObjective-Objekt gibt auch die Serving-Attribute des Modells an, z. B. diePrioritydes KI-Modells. GKE Inference Gateway bevorzugt Arbeitslasten mit einem höheren Prioritätswert. So können Sie latenzkritische und latenztolerante KI-Arbeitslasten in einem GKE-Cluster multiplexen. Sie können dasInferenceObjective-Objekt auch so konfigurieren, dass LoRA-abgestimmte Modelle bereitgestellt werden.
Das folgende Diagramm zeigt das GKE Inference Gateway und die Integration mit KI-Sicherheit, Observability und Modellbereitstellung in einem GKE-Cluster.
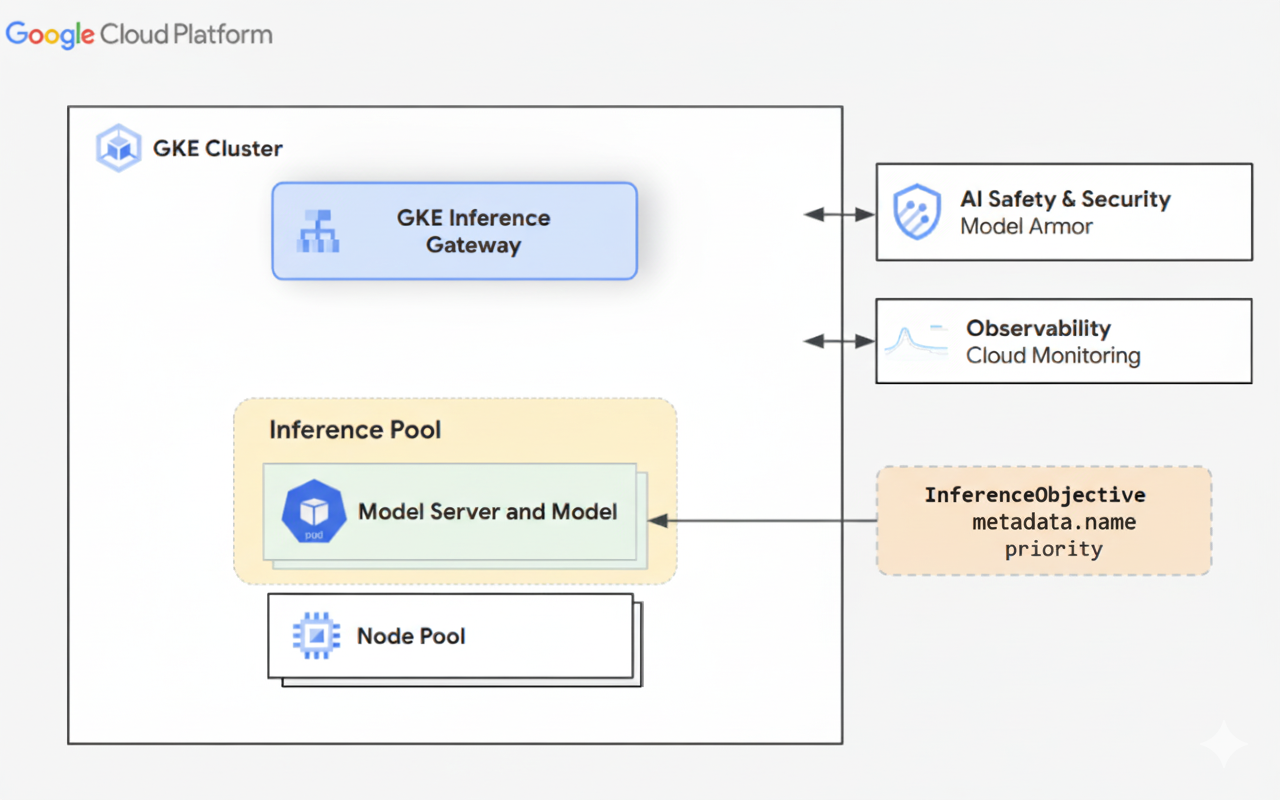
Das folgende Diagramm veranschaulicht das Ressourcenmodell, das sich auf zwei neue auf Inferenz ausgerichtete Rollen und die von ihnen verwalteten Ressourcen konzentriert.

Funktionsweise von GKE Inference Gateway
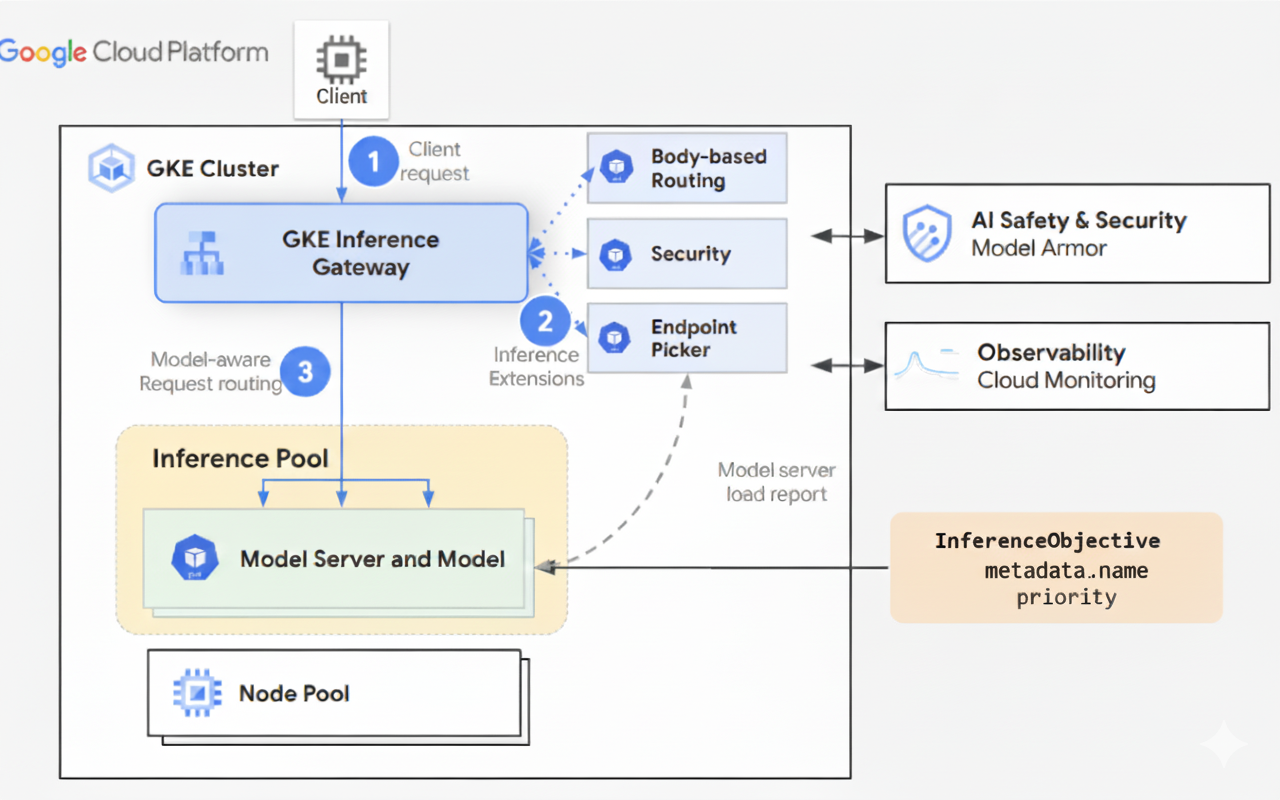
GKE Inference Gateway verwendet Gateway API-Erweiterungen und modellspezifische Routinglogik, um Clientanfragen an ein KI-Modell zu verarbeiten. Im Folgenden wird der Anfrageablauf beschrieben.
So funktioniert der Anfrageablauf
GKE Inference Gateway leitet Clientanfragen von der ursprünglichen Anfrage an eine Modellinstanz weiter. In diesem Abschnitt wird beschrieben, wie GKE Inference Gateway Anfragen verarbeitet. Dieser Anfrageablauf ist für alle Clients üblich.
- Der Client sendet eine Anfrage, die wie in der OpenAI API-Spezifikation beschrieben formatiert ist, an das in GKE ausgeführte Modell.
- GKE Inference Gateway verarbeitet die Anfrage mit den folgenden Inference-Erweiterungen:
- Body-basiertes Routing: Extrahiert die Modellkennung aus dem Anfragetext des Clients und sendet sie an GKE Inference Gateway.
GKE Inference Gateway verwendet diese Kennung dann, um die Anfrage anhand der im Gateway API-Objekt
HTTPRoutedefinierten Regeln weiterzuleiten. Das Routing des Anfragetexts ähnelt dem Routing basierend auf dem URL-Pfad. Der Unterschied besteht darin, dass beim Routing des Anfragetexts Daten aus dem Anfragetext verwendet werden. - Sicherheitserweiterung: Hier werden Model Armor oder unterstützte Drittanbieterlösungen verwendet, um modellspezifische Sicherheitsrichtlinien zu erzwingen, darunter Inhaltsfilterung, Bedrohungserkennung, Bereinigung und Protokollierung. Die Sicherheitserweiterung wendet diese Richtlinien sowohl auf Anfrage- als auch auf Antwortverarbeitungspfade an.
- Erweiterung zur Endpunktauswahl: überwacht wichtige Messwerte von Modellservern innerhalb von
InferencePool. Es wird die Nutzung des Schlüssel/Wert-Caches (KV-Cache), die Warteschlangenlänge ausstehender Anfragen, die Präfix-Cache-Indizes und die aktiven LoRA-Adapter auf jedem Modellserver erfasst. Anschließend wird die Anfrage basierend auf diesen Messwerten an das optimale Modellreplikat weitergeleitet, um die Latenz zu minimieren und den Durchsatz für KI-Inferenz zu maximieren.
- Body-basiertes Routing: Extrahiert die Modellkennung aus dem Anfragetext des Clients und sendet sie an GKE Inference Gateway.
GKE Inference Gateway verwendet diese Kennung dann, um die Anfrage anhand der im Gateway API-Objekt
- GKE Inference Gateway leitet die Anfrage an die Modellreplik weiter, die von der Erweiterung für die Endpunktauswahl zurückgegeben wird.
Das folgende Diagramm veranschaulicht den Anfragefluss von einem Client zu einer Modellinstanz über GKE Inference Gateway.
So funktioniert die Trafficverteilung
GKE Inference Gateway verteilt Inferenzanfragen dynamisch an Modellserver innerhalb des InferencePool-Objekts. So lässt sich die Ressourcennutzung optimieren und die Leistung bei unterschiedlichen Lastbedingungen aufrechterhalten.
GKE Inference Gateway verwendet die folgenden beiden Mechanismen, um die Traffic-Verteilung zu verwalten:
Endpunktauswahl: wählt dynamisch den am besten geeigneten Modellserver für die Verarbeitung einer Inferenzanfrage aus. Es wird die Serverlast und ‑verfügbarkeit überwacht und dann werden optimale Routing-Entscheidungen getroffen, indem für jeden Server ein
scoreberechnet wird, in dem eine Reihe von Optimierungsheuristiken kombiniert werden:- Präfix-Cache-basiertes Routing: GKE Inference Gateway verfolgt die verfügbaren Präfix-Cache-Indizes auf jedem Modellserver und weist einem Server mit einer längeren Präfix-Cache-Übereinstimmung einen höheren Wert zu.
- Lastbezogenes Routing: GKE Inference Gateway überwacht die Serverlast (KV-Cache-Auslastung und Tiefe der ausstehenden Warteschlange) und weist einem Server mit geringerer Last einen höheren Wert zu.
- LoRA-basiertes Routing: Wenn das dynamische Bereitstellen von LoRA aktiviert ist, überwacht GKE Inference Gateway aktive LoRA-Adapter pro Server und weist einem Server mit dem angeforderten aktiven LoRA-Adapter oder zusätzlichem Speicherplatz zum dynamischen Laden des angeforderten LoRA-Adapters einen höheren Wert zu. Es wird ein Server mit der höchsten Gesamtpunktzahl aller oben genannten ausgewählt.
Warteschlangen und Ablegen: Verwaltet den Anfragenfluss und verhindert eine Überlastung des Traffics. Das GKE Inference Gateway speichert eingehende Anfragen in einer Warteschlange und priorisiert Anfragen basierend auf der definierten Priorität.
GKE Inference Gateway verwendet ein numerisches Priority-System, auch bekannt als Criticality, um den Anfragenfluss zu verwalten und Überlastungen zu verhindern. Diese Priority ist ein optionales Ganzzahlfeld, das vom Nutzer für jede InferenceObjective definiert wird. Ein höherer Wert bedeutet eine wichtigere Anfrage. Wenn das System überlastet ist, werden Anfragen mit einem Priority unter 0 als weniger wichtig eingestuft und zuerst verworfen. Es wird ein 429-Fehler zurückgegeben, um wichtigere Arbeitslasten zu schützen. Priority ist standardmäßig auf 0 gesetzt. Anfragen werden nur aufgrund der Priorität verworfen, wenn ihr Priority explizit auf einen Wert unter 0 festgelegt ist. Mit diesem System können Sie latenzempfindlichen Online-Inferenz-Traffic gegenüber weniger zeitkritischen Batchjobs priorisieren.
GKE Inference Gateway unterstützt Streaming-Inferenz für Anwendungen wie Chatbots und Live-Übersetzung, die kontinuierliche oder nahezu in Echtzeit stattfindende Aktualisierungen erfordern. Beim Streaming von Inferenzen werden Antworten in inkrementellen Chunks oder Segmenten statt als einzelne, vollständige Ausgabe geliefert. Wenn während einer Streaming-Antwort ein Fehler auftritt, wird der Stream beendet und der Client erhält eine Fehlermeldung. GKE Inference Gateway versucht nicht noch einmal, Streaming-Antworten zu senden.
Anwendungsbeispiele ansehen
In diesem Abschnitt finden Sie Beispiele für die Verwendung von GKE Inference Gateway für verschiedene generative KI-Anwendungsszenarien.
Beispiel 1: Mehrere generative KI-Modelle in einem GKE-Cluster bereitstellen
Ein Unternehmen möchte mehrere Large Language Models (LLMs) für verschiedene Arbeitslasten bereitstellen. Beispielsweise möchten sie möglicherweise ein Gemma3-Modell für eine Chatbot-Schnittstelle und ein Deepseek-Modell für eine Empfehlungsanwendung bereitstellen. Das Unternehmen muss für diese LLMs eine optimale Bereitstellungsleistung sicherstellen.
Mit GKE Inference Gateway können Sie diese LLMs mit der von Ihnen ausgewählten Beschleunigerkonfiguration in einem InferencePool in Ihrem GKE-Cluster bereitstellen. Anschließend können Sie Anfragen basierend auf dem Modellnamen (z. B. chatbot und recommender) und der Eigenschaft Priority weiterleiten.
Das folgende Diagramm veranschaulicht, wie GKE Inference Gateway Anfragen basierend auf dem Modellnamen und Priority an verschiedene Modelle weiterleitet.
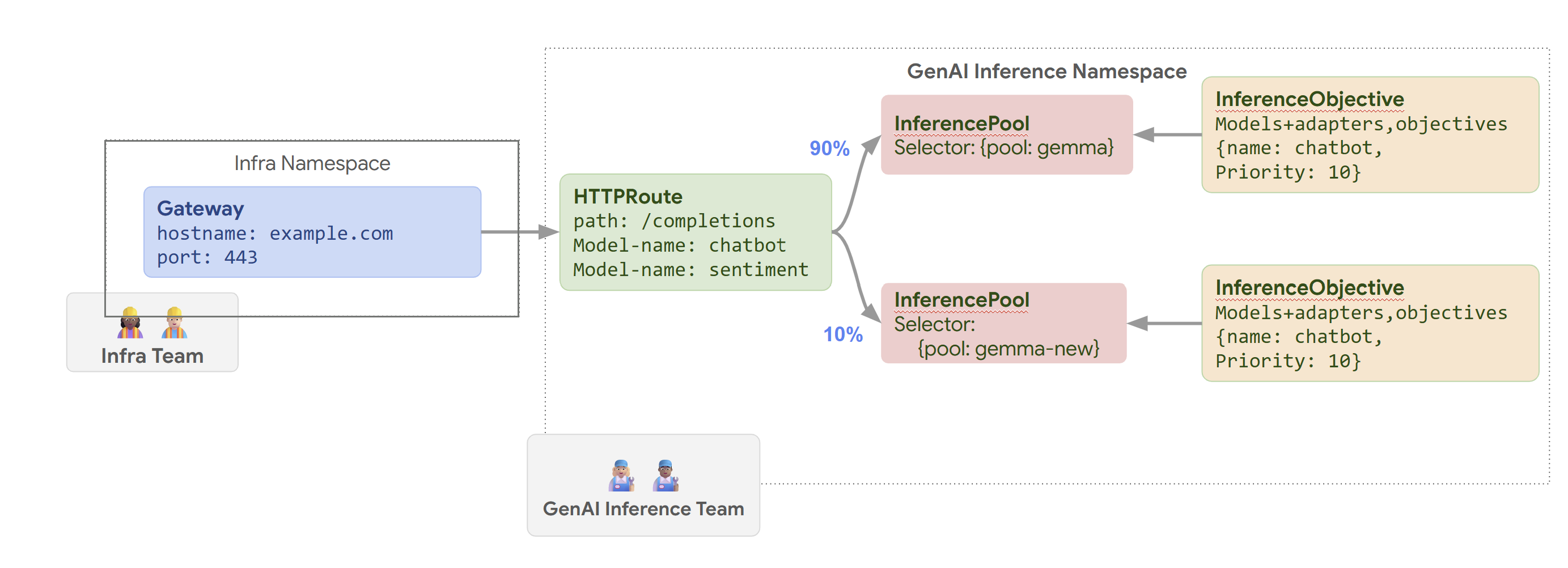
In diesem Diagramm wird veranschaulicht, wie eine Anfrage an einen GenAI-Dienst auf example.com/completions vom GKE Inference Gateway verarbeitet wird. Die Anfrage erreicht zuerst einen Gateway im Namespace Infra. Dieser Gateway leitet die Anfrage an einen HTTPRoute im GenAI Inference-Namespace weiter, der für die Verarbeitung von Anfragen für Chatbot- und Sentimentmodelle konfiguriert ist. Beim Chatbot-Modell wird der Traffic durch HTTPRoute aufgeteilt: 90% werden an eine InferencePool mit der aktuellen Modellversion (ausgewählt von {pool: gemma}) weitergeleitet und 10% an einen Pool mit einer neueren Version ({pool: gemma-new}), in der Regel für Canary-Tests.
Beide Pools sind mit einem InferenceObjective verknüpft, der Anfragen für das Chatbot-Modell eine Priority von 10 zuweist. So werden diese Anfragen als prioritär behandelt.
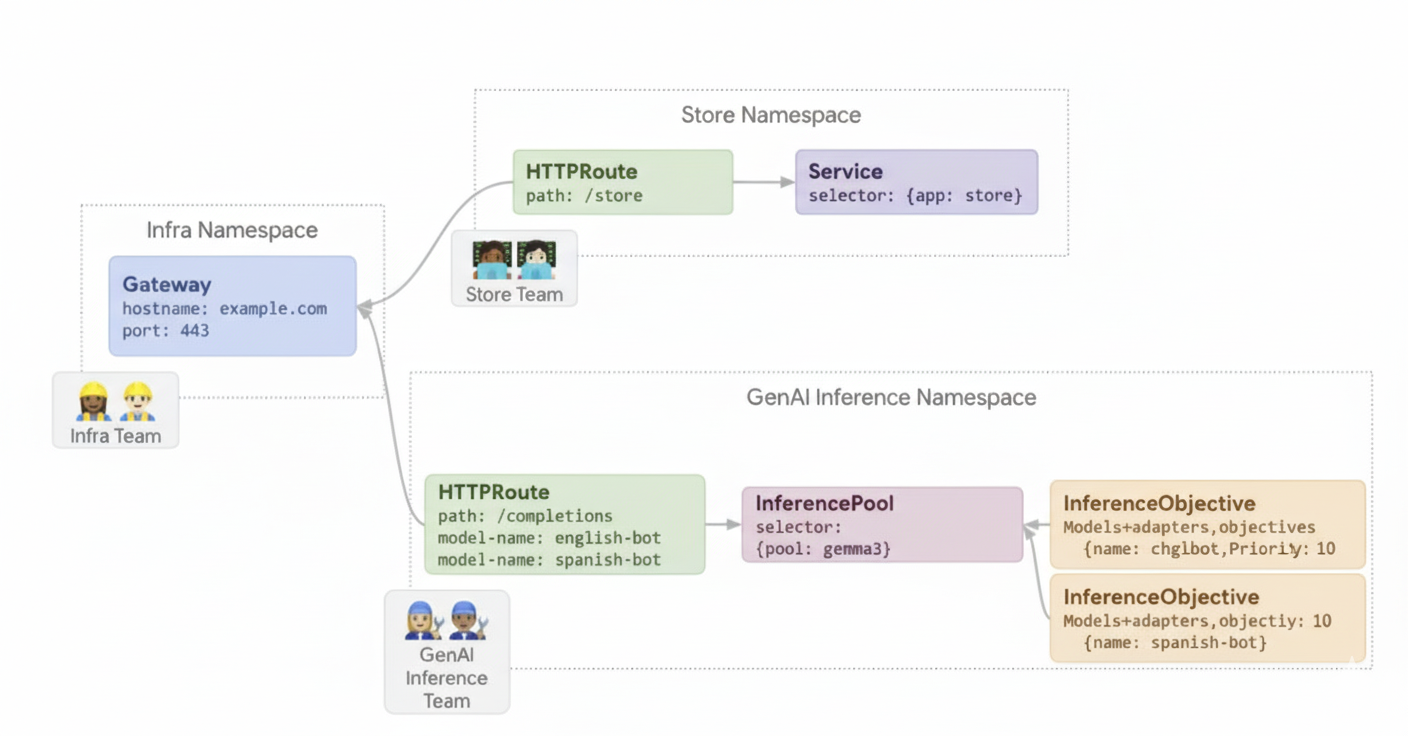
Beispiel 2: LoRA-Adapter auf einem gemeinsam genutzten Beschleuniger bereitstellen
Ein Unternehmen möchte LLMs für die Dokumentanalyse bereitstellen und konzentriert sich auf Zielgruppen in mehreren Sprachen, z. B. Englisch und Spanisch. Sie haben Modelle für jede Sprache optimiert, müssen aber ihre GPU- und TPU-Kapazität effizient nutzen. Mit dem GKE Inference Gateway können Sie dynamische LoRA-Adapter, die für jede Sprache (z. B. english-bot und spanish-bot) optimiert wurden, für ein gemeinsames Basismodell (z. B. llm-base) und einen gemeinsamen Beschleuniger bereitstellen. So können Sie die Anzahl der erforderlichen Beschleuniger reduzieren, indem Sie mehrere Modelle auf einem gemeinsamen Beschleuniger unterbringen.
Das folgende Diagramm veranschaulicht, wie das GKE Inference Gateway mehrere LoRA-Adapter auf einem gemeinsam genutzten Beschleuniger bereitstellt.
Nächste Schritte
- GKE Inference Gateway bereitstellen
- GKE Inference Gateway-Konfiguration anpassen
- LLM mit GKE Inference Gateway bereitstellen