Cette page présente les principaux aspects de la mise en réseau dans le cadre de Google Kubernetes Engine (GKE). Ces informations sont utiles pour ceux qui débutent avec Kubernetes ainsi que pour les opérateurs de cluster ou les développeurs d'applications plus expérimentés, qui ont besoin de détails supplémentaires sur la gestion de réseau Kubernetes afin de mieux concevoir leurs applications ou configurer les charges de travail Kubernetes.
Cette page et le reste de cette documentation s'adressent aux architectes cloud et aux spécialistes de la mise en réseau qui conçoivent et implémentent le réseau pour leur organisation. Si vous ne connaissez pas Kubernetes ni GKE, ou si vous avez besoin d'en savoir plus sur un sujet plus général concernant GKE, consultez la documentation de base de GKE, qui couvre les fonctionnalités de base disponibles pour tous les utilisateurs de GKE. Pour obtenir une présentation de tous les ensembles de documentation GKE, consultez Explorer la documentation GKE. Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenuGoogle Cloud , consultez Rôles utilisateur et tâches courantes de l'utilisateur dans GKE Enterprise.
Kubernetes vous permet de définir de manière déclarative le mode de déploiement de vos applications, la manière dont les applications communiquent entre elles et avec le plan de contrôle de Kubernetes, ainsi que la manière dont les clients peuvent accéder à vos applications. Cette page fournit également des informations sur la manière dont GKE configure les services Google Cloudlorsque cela touche aux aspects réseau.
Pourquoi la mise en réseau Kubernetes est-elle différente ?
Lorsque vous vous servez de Kubernetes pour orchestrer des applications, il est important de changer de point de vue sur la conception du réseau pour vos applications et leurs hôtes. Avec Kubernetes, vous réfléchissez à la façon dont les pods, les services et les clients externes communiquent au lieu de penser à la manière dont vos hôtes ou vos machines virtuelles (VM) sont connectés.
Le réseau défini par logiciel avancé de Kubernetes permet le transfert et le routage de paquets pour les pods, les services et les nœuds dans différentes zones d'un même cluster régional. Kubernetes et Google Cloud configurent également de manière dynamique des règles de filtrage IP, des tables de routage et des règles de pare-feu sur chaque nœud, suivant le modèle déclaratif de vos déploiements Kubernetes et la configuration de votre cluster sur Google Cloud.
Prérequis
Avant de lire cette page, assurez-vous de maîtriser les concepts et utilitaires de gestion de réseau Linux, tels que les règles iptables et le routage.
Assurez-vous également de connaître la terminologie de base des sujets suivants :
- Transport
- Internet
- Couches d'application
- Suite de protocoles Internet, y compris HTTP et DNS
Terminologie liée au réseau Kubernetes
Le modèle de réseau Kubernetes s'appuie fortement sur les adresses IP. Les services, les pods, les conteneurs et les nœuds communiquent via des adresses IP et des ports. Kubernetes propose différents types d'équilibrage de charge pour diriger les requêtes vers les pods adéquats. Tous ces mécanismes sont décrits plus en détail ultérieurement. Gardez les termes suivants liés aux adresses IP à l'esprit durant votre lecture :
- ClusterIP : adresse IP affectée à un service. Dans d'autres documents, elle peut également être désignée par "IP de cluster". Cette adresse est stable pour toute la durée de vie du service, comme indiqué dans la section Services.
- Adresse IP du pod : adresse IP attribuée à un pod donné. Cette adresse est éphémère, comme expliqué à la page Pods.
- Adresse IP du nœud : adresse IP attribuée à un nœud donné.
Exigences de connectivité des clusters
Tous les clusters nécessitent une connectivité à *.googleapis.com, *.gcr.io, *.pkg.dev et l'adresse IP du plan de contrôle. Cette exigence est satisfaite par les règles de sortie autorisée implicites et les règles de pare-feu créées automatiquement créées par GKE.
Mise en réseau au sein du cluster
Cette section traite de la mise en réseau au sein d'un cluster Kubernetes, et plus spécifiquement de l'attribution d'adresses IP, des pods, des services, des DNS et du plan de contrôle.
Attribution d'adresses IP
Kubernetes utilise diverses plages d'adresses IP pour attribuer des adresses aux nœuds, aux pods et aux services.
- Chaque nœud possède une adresse IP attribuée à partir du réseau de cloud privé virtuel (VPC) du cluster. Cette adresse IP de nœud assure la connectivité des composants de contrôle tels que
kube-proxyet lekubeletavec le serveur d'API Kubernetes. Cette adresse IP correspond à la connexion du nœud avec le reste du cluster. Chaque nœud dispose d'un pool d'adresses IP que GKE attribue aux pods en cours d'exécution sur ce nœud (un bloc CIDR /24 par défaut). Vous pouvez éventuellement spécifier la plage d'adresses IP lors de la création du cluster. La fonctionnalité de plage d'adressage CIDR flexible des pods vous permet de réduire la taille de la plage d'adresses IP de pods pour les nœuds d'un pool de nœuds.
Chaque pod possède une seule adresse IP attribuée à partir de la plage CIDR de pods de son nœud. Cette adresse IP est partagée par tous les conteneurs s'exécutant dans le pod, et les connecte aux autres pods qui s'exécutent dans le cluster.
Chaque service possède une adresse IP appelée ClusterIP, attribuée à partir du réseau VPC du cluster. Vous pouvez éventuellement personnaliser le réseau VPC lors de la création du cluster.
Chaque plan de contrôle possède une adresse IP publique ou interne en fonction du type de cluster, de la version et de la date de création. Pour en savoir plus, consultez la description du plan de contrôle.
Le modèle de mise en réseau GKE ne permet pas de réutiliser les adresses IP sur le réseau. Lorsque vous migrez vers GKE, vous devez planifier votre allocation d'adresses IP pour réduire l'utilisation des adresses IP internes dans GKE.
Unité de transmission maximale (MTU)
La MTU sélectionnée pour une interface de pod dépend de l'interface CNI (Container Network Interface) utilisée par les nœuds du cluster et du paramètre de MTU sous-jacent du VPC. Pour en savoir plus, consultez la section Pods.
La valeur de la MTU de l'interface de pod est 1460 ou héritée de l'interface principale du nœud.
| CNI | MTU | GKE Standard |
|---|---|---|
| kubenet | 1460 | Par défaut |
|
kubenet (version 1.26.1 de GKE et versions ultérieures) |
Hérité | Par défaut |
| Calico | 1460 |
Activation à l'aide de Pour en savoir plus, consultez la page Contrôler la communication entre les pods et les services à l'aide de règles de réseau. |
| netd | Hérité | Activation à l'aide de l'une des options suivantes : |
| GKE Dataplane V2 | Hérité |
Activation à l'aide de Pour en savoir plus, consultez la page Utiliser GKE Dataplane V2. |
Pour en savoir plus, consultez la page sur les clusters de VPC natif.
Plug-ins réseau compatibles
- Pour utiliser un plug-in réseau, vous devez l'installer vous-même. GKE propose les plug-ins réseau compatibles de façon native suivants :
- Calico (dans Dataplane V1)
- Cilium (dans Dataplane V2)
- Istio-CNI (dans le contrôleur Dataplane géré pour GKE Enterprise)
Pods
Dans Kubernetes, un pod est l’unité la plus élémentaire pouvant être déployée dans un cluster Kubernetes. Un pod gère un ou plusieurs conteneurs. Un nœud gère zéro, un ou plusieurs pods. Chaque nœud du cluster fait partie d'un pool de nœuds.
Dans GKE, ces nœuds sont des machines virtuelles, chacune s'exécutant en tant qu'instance dans Compute Engine.
Les pods peuvent également se connecter à des volumes de stockage externes et à d'autres ressources personnalisées. Ce diagramme illustre un nœud unique exécutant deux pods, chacun étant attaché à deux volumes.
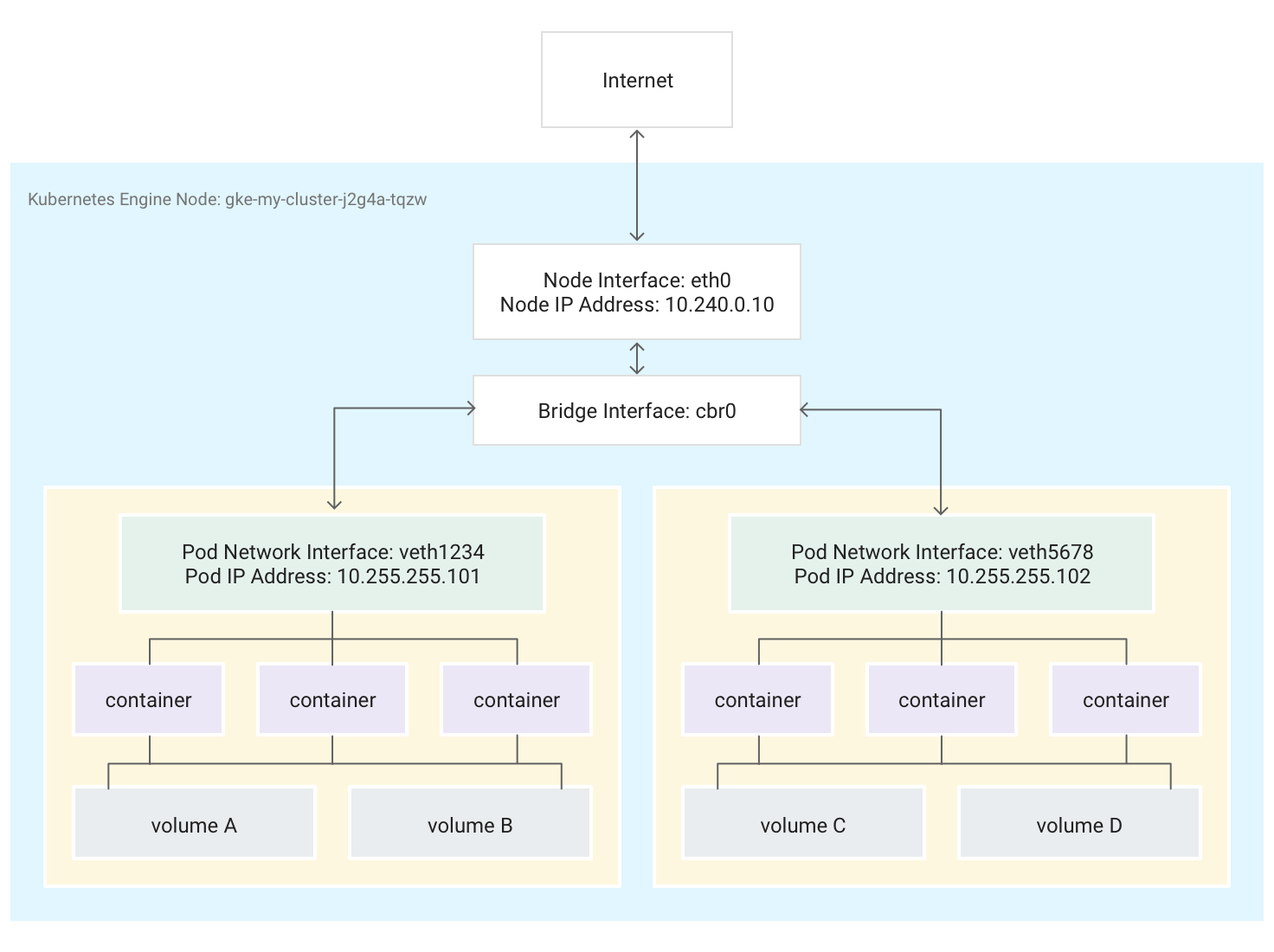
Lorsque Kubernetes planifie l'exécution d'un pod sur un nœud, il crée un espace de noms réseau pour le pod dans le noyau Linux du nœud. Cet espace de noms réseau connecte l'interface réseau physique du nœud (par exemple eth0) au pod au moyen d'une interface réseau virtuelle, de sorte que les paquets peuvent circuler vers et depuis le pod. L'interface réseau virtuelle associée au sein de l'espace de noms réseau racine du nœud se connecte à un pont Linux qui permet la communication entre les pods situés sur le même nœud. Un pod peut également envoyer des paquets en dehors du nœud en utilisant la même interface virtuelle.
Kubernetes attribue une adresse IP (l'adresse IP du pod) à l'interface réseau virtuelle de l'espace de noms réseau du pod à partir d'une plage d'adresses réservées aux pods du nœud. Cette plage d'adresses constitue un sous-ensemble de la plage d'adresses IP attribuée au cluster pour les pods, que vous pouvez configurer lorsque vous créez un cluster.
Un conteneur s'exécutant dans un pod utilise l'espace de noms réseau du pod. Du point de vue du conteneur, le pod apparaît comme une machine physique dotée d'une seule interface réseau. Tous les conteneurs du pod voient cette même interface réseau.
L'élément localhost de chaque conteneur est connecté, via le pod, à l'interface réseau physique du nœud, par exemple eth0.
Notez que cette connectivité diffère considérablement selon que vous utilisez la CNI (Container Network Interface) de GKE ou que vous choisissez l'implémentation de Calico en activant les règles de réseau lors de la création du cluster.
Si vous utilisez la CNI de GKE, une extrémité de la paire veth est rattachée au pod dans son espace de noms, et l'autre est connectée au périphérique de pont Linux
cbr0.1 Dans ce cas, la commande suivante affiche les adresses MAC des différents pods associées àcbr0:arp -nL'exécution de la commande suivante dans le conteneur de la boîte à outils affiche la fin de l'espace de noms racine de chaque paire veth rattachée à
cbr0:brctl show cbr0Si les règles de réseau sont activées, l'une des extrémités de la paire veth est rattachée au pod, et l'autre à
eth0. Dans ce cas, la commande suivante affiche les adresses MAC des différents pods associées à différents périphériques veth :arp -nL'exécution de la commande suivante dans le conteneur de la boîte à outils montre qu'il n'existe aucun périphérique de pont Linux nommé
cbr0:brctl show
Les règles iptables qui facilitent le transfert au sein du cluster diffèrent d'un scénario à l'autre. Il est important de garder cette distinction à l'esprit lors du dépannage détaillé des problèmes de connectivité.
Par défaut, chaque pod dispose d'un accès non filtré à tous les autres pods s'exécutant sur tous les nœuds du cluster, mais vous pouvez restreindre l'accès entre les pods. Kubernetes détruit et recrée régulièrement les pods. Cela se produit lorsqu'un pool de nœuds est mis à jour, lorsque vous modifiez la configuration déclarative du pod ou l'image d'un conteneur, ou lorsqu'un nœud devient indisponible. Par conséquent, l'adresse IP d'un pod est un détail d'implémentation et vous ne devez pas vous appuyer dessus. Kubernetes fournit des adresses IP stables à l'aide de services.
-
Le pont réseau virtuel
cbr0n'est créé que si des pods définissenthostNetwork: false.↩
Services
Dans Kubernetes, vous pouvez affecter à toutes les ressources des paires clé-valeur arbitraires appelées étiquettes. Kubernetes utilise ces étiquettes pour regrouper plusieurs pods connexes au sein d'une unité logique appelée Service. Un service possède une adresse IP et des ports stables, et fournit un équilibrage de la charge entre l'ensemble des pods dont les étiquettes correspondent à celles que vous définissez dans le sélecteur d'étiquettes lors de la création du service.
Le diagramme suivant illustre deux services distincts, comprenant chacun plusieurs pods. Chacun des pods du diagramme est associé à l'étiquette app=demo, mais leurs autres étiquettes diffèrent. Le service "frontend" correspond à tous les pods dotés des étiquettes app=demo et component=frontend, tandis que le service "users" correspond à tous les pods dotés des étiquettes app=demo et component=users. Le pod Client ne correspond exactement à aucun de ces sélecteurs de services. Il n'est donc associé ni à l'un ni à l'autre. Cependant, le pod Client peut communiquer avec l'un ou l'autre des services car il s'exécute dans le même cluster.
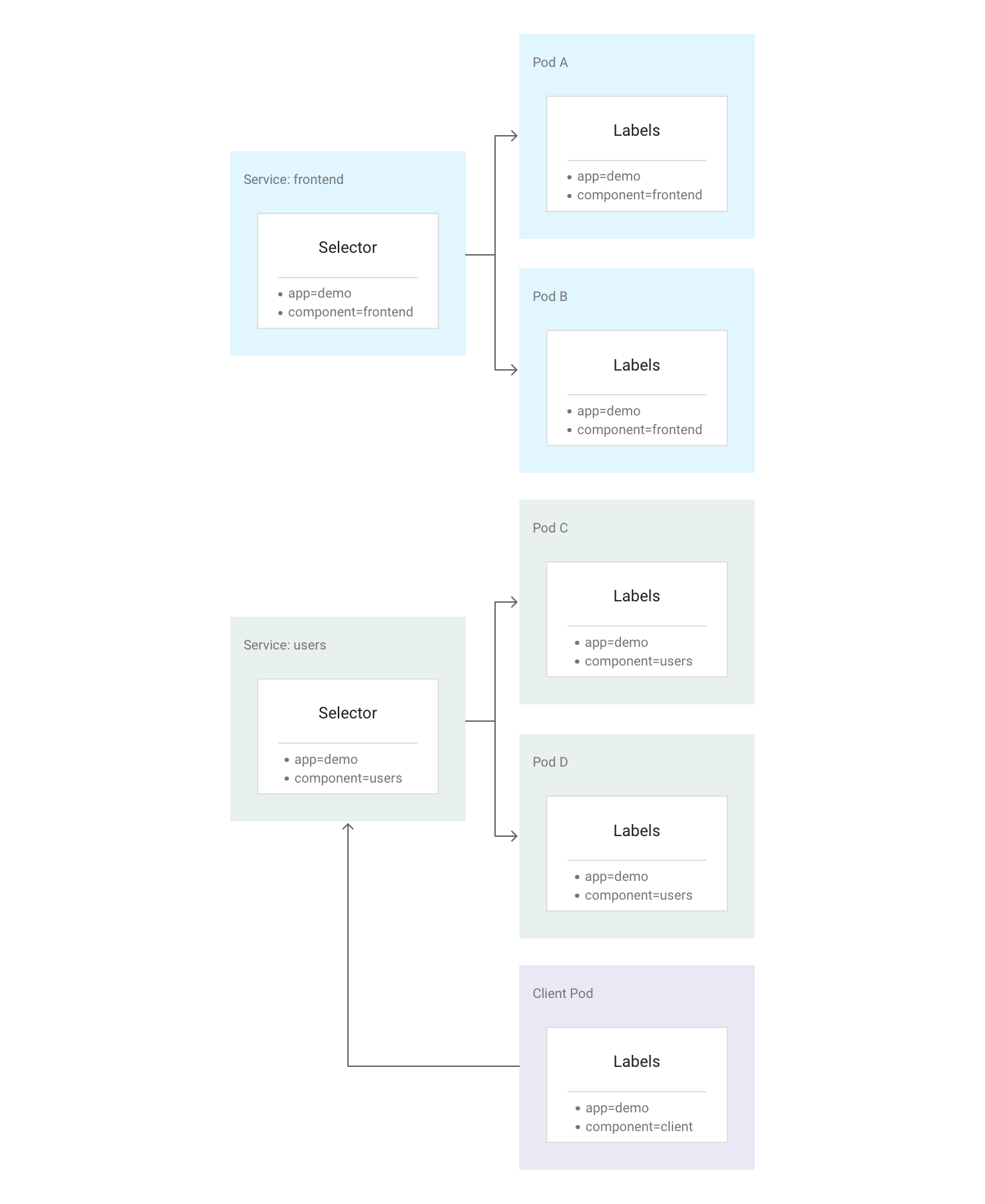
Kubernetes attribue une adresse IP stable et fiable à chaque service qui vient d'être créé (l'adresse ClusterIP) à partir du pool d'adresses IP de services disponibles du cluster. Kubernetes attribue également un nom d'hôte à l'adresse ClusterIP en ajoutant une entrée DNS. L'adresse ClusterIP et le nom d'hôte sont uniques au sein du cluster et ne sont pas modifiés au cours du cycle de vie du service. Kubernetes ne libère l'adresse ClusterIP et le nom d'hôte que si le service est supprimé de la configuration du cluster. Vous pouvez accéder à un pod sain exécutant votre application par le biais soit de son adresse ClusterIP, soit du nom d'hôte du service.
À première vue, un service peut sembler être un point unique de défaillance pour vos applications. Cependant, Kubernetes répartit le trafic de manière aussi uniforme que possible sur l'ensemble des pods s'exécutant sur de nombreux nœuds, afin qu'un cluster puisse résister à une panne affectant un ou plusieurs nœuds (mais pas tous).
Kube-Proxy
Kubernetes gère la connectivité entre les pods et les services à l'aide du composant kube-proxy, qui s'exécute généralement en tant que pod statique sur chaque nœud.
kube-proxy, qui n'est pas un proxy en ligne mais un contrôleur d'équilibrage de charge basé sur la sortie, surveille le serveur d'API Kubernetes et mappe continuellement l'adresse ClusterIP avec les pods sains en ajoutant et en supprimant des règles de destination NAT (DNAT) sur le sous-système iptables du nœud. Lorsqu'un conteneur s'exécutant dans un pod envoie du trafic à l'adresse ClusterIP d'un service, le nœud sélectionne un pod de manière aléatoire et achemine le trafic vers ce pod.
Lorsque vous configurez un service, vous pouvez éventuellement remapper son port d'écoute en définissant des valeurs pour port et targetPort.
portcorrespond à l'endroit où les clients accèdent à l'application.targetPortcorrespond au port sur lequel l'application écoute effectivement le trafic dans le pod.
kube-proxy gère ce remappage de ports en ajoutant et en supprimant des règles iptables sur le nœud.
Ce diagramme illustre le flux de trafic d'un pod client vers un pod serveur situé sur un nœud différent. Le client se connecte au service à l'adresse 172.16.12.100:80.
Le serveur d'API Kubernetes gère une liste des pods exécutant l'application. Le processus kube-proxy de chaque nœud utilise cette liste pour créer une règle iptables pour diriger le trafic vers un pod approprié (tel que 10.255.255.202:8080). Le pod client n'a pas besoin de connaître la topologie du cluster ni les détails sur les pods individuels ou les conteneurs qu'ils hébergent.
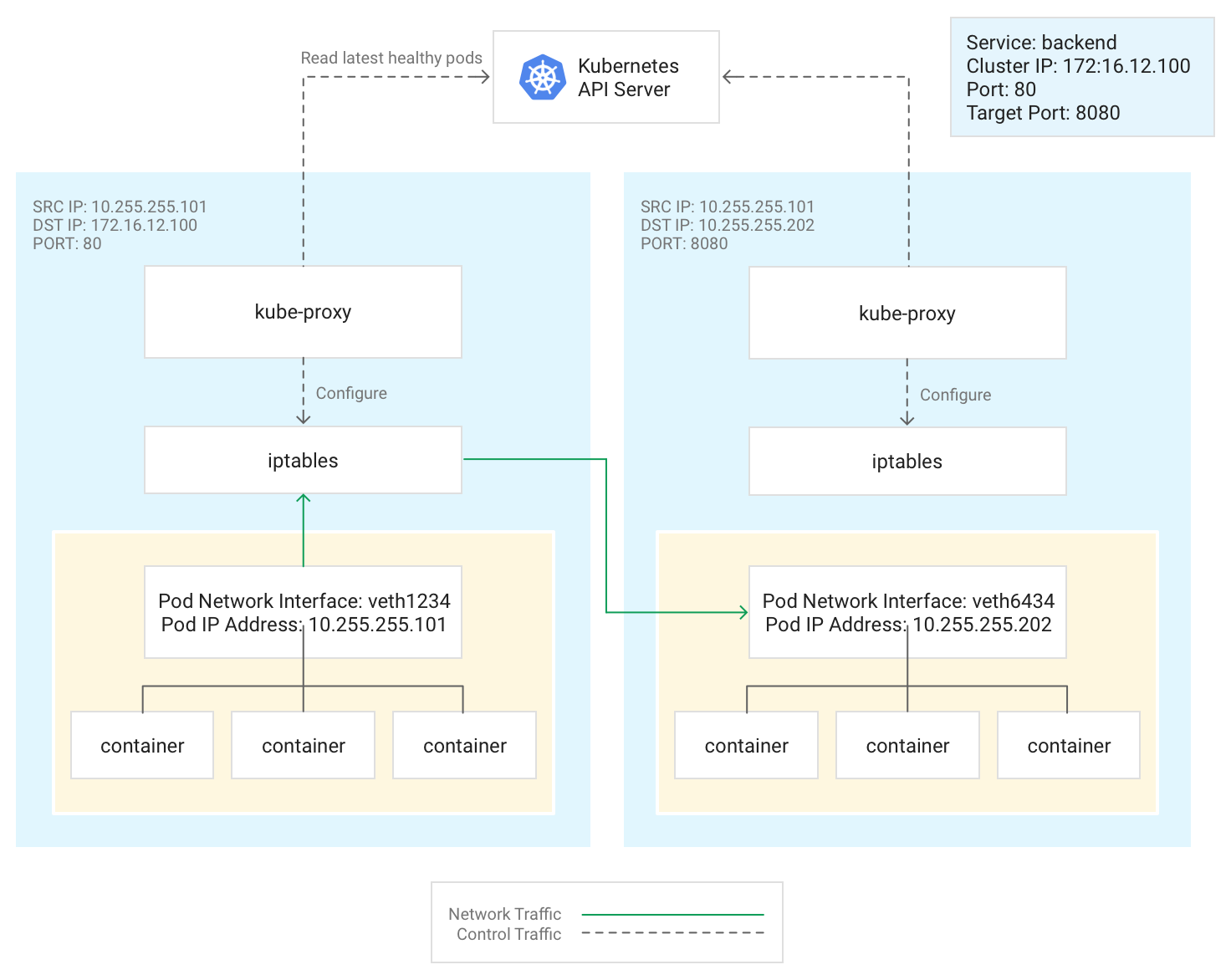
Le mode de déploiement de kube-proxy dépend de la version GKE du cluster :
- Pour les versions 1.16.0 et 1.16.8-gke.13 de GKE,
kube-proxyest déployé en tant que DaemonSet. - Pour les versions plus récentes que GKE 1.16.8-gke.13,
kube-proxyest déployé en tant que pod statique pour les nœuds.
DNS
GKE fournit les options DNS de cluster gérées suivantes pour résoudre les noms de service et les noms externes :
kube-dns : module complémentaire de cluster déployé par défaut dans tous les clusters GKE. Pour en savoir plus, consultez la section Utiliser kube-dns.
Cloud DNS : infrastructure DNS gérée dans le cloud qui remplace kube-dns dans le cluster. Pour en savoir plus, consultez la page Utiliser Cloud DNS pour GKE.
GKE fournit également NodeLocal DNSCache en tant que module complémentaire facultatif utilisable avec kube-dns ou Cloud DNS pour améliorer les performances DNS du cluster.
Pour en savoir plus sur la manière dont GKE fournit le service DNS, consultez la section Détection de services et DNS.
Plan de contrôle
Dans Kubernetes, le plan de contrôle gère les processus du plan de contrôle, y compris le serveur d'API Kubernetes. La façon dont vous accédez au plan de contrôle dépend de la façon dont vous avez configuré l'isolation du réseau du plan de contrôle.
Mise en réseau à l'extérieur du cluster
Cette section explique comment le trafic extérieur au cluster est acheminé vers les applications exécutées dans un cluster Kubernetes. Ces informations sont importantes pour la conception des applications et charges de travail de votre cluster.
Vous avez déjà vu comment Kubernetes utilise les services pour fournir des adresses IP stables aux applications exécutées dans les pods. Par défaut, les pods n'exposent pas d'adresse IP externe, car kube-proxy gère l'ensemble du trafic sur chaque nœud. Les pods et leurs conteneurs peuvent communiquer librement entre eux, mais les connexions extérieures au cluster ne peuvent pas accéder au service. Ainsi, dans l'illustration précédente, les clients extérieurs au cluster ne peuvent pas accéder au service "frontend" à travers son adresse ClusterIP.
GKE fournit trois types différents d'équilibreurs de charge pour contrôler l'accès et répartir le trafic entrant sur votre cluster de manière aussi uniforme que possible. Vous pouvez configurer un même service pour qu'il utilise simultanément plusieurs types d'équilibreurs de charge.
- Les équilibreurs de charge externes gèrent le trafic provenant de l'extérieur du cluster et de votre réseau VPC Google Cloud. Ils utilisent des règles de transfert associées au réseauGoogle Cloud pour acheminer le trafic vers un nœud Kubernetes.
- Les équilibreurs de charge internes gèrent le trafic provenant du même réseau VPC. Tout comme les équilibreurs de charge externes, ils utilisent des règles de transfert associées au réseau Google Cloud pour acheminer le trafic vers un nœud Kubernetes.
- Les équilibreurs de charge d'application sont des équilibreurs de charge externes spécialisés pour le trafic HTTP(S). Ils utilisent une ressource d'entrée plutôt qu'une règle de transfert pour acheminer le trafic vers un nœud Kubernetes.
Lorsque le trafic atteint un nœud Kubernetes, il est traité de la même manière quel que soit le type d'équilibreur de charge. L'équilibreur de charge ne sait pas quels nœuds du cluster exécutent des pods correspondant à son service. Au lieu de cela, il équilibre le trafic à travers tous les nœuds du cluster, y compris ceux qui n'exécutent pas de pod pertinent. Sur un cluster régional, la charge est répartie sur l'ensemble des nœuds à travers toutes les zones de la région du cluster. Lorsque le trafic est acheminé vers un nœud, celui-ci l'achemine vers un pod pouvant s'exécuter sur le même nœud ou sur un nœud différent. Le nœud transfère le trafic vers un pod choisi de manière aléatoire en utilisant les règles iptables gérées par kube-proxy sur le nœud.
Dans le diagramme suivant, l'équilibreur de charge réseau passthrough externe dirige le trafic vers le nœud du milieu. Le trafic est ensuite redirigé vers un pod du premier nœud.
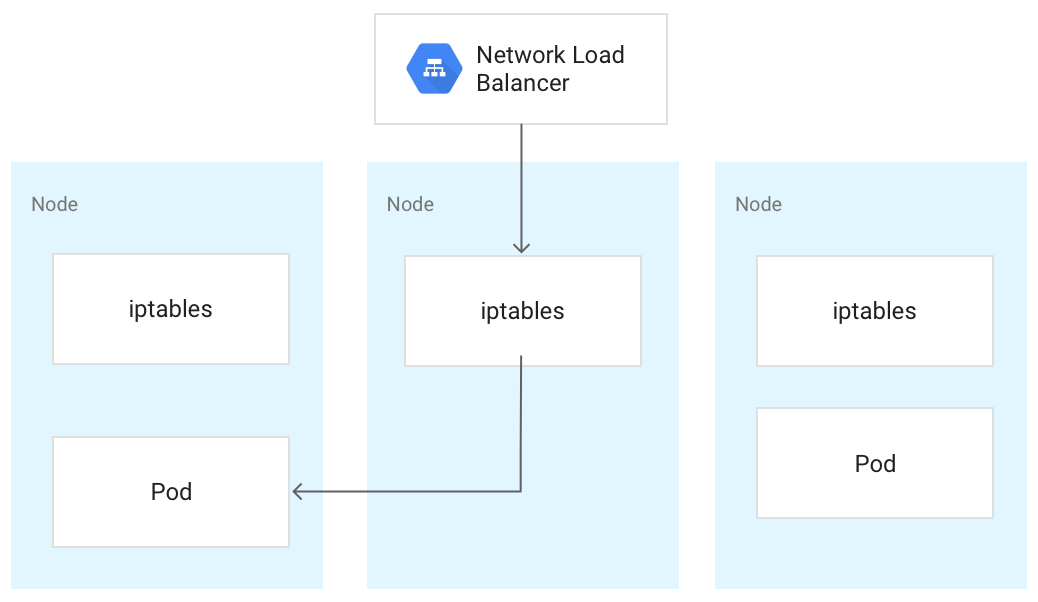
Lorsqu'un équilibreur de charge envoie du trafic à un nœud, le trafic peut être transféré à un pod situé sur un nœud différent. Cela nécessite des sauts de réseau supplémentaires. Pour éviter les sauts supplémentaires, vous pouvez spécifier que le trafic doit aller à un pod qui se trouve sur le même nœud que celui qui reçoit initialement le trafic.
Pour spécifier que le trafic doit aller à un pod sur le même nœud, définissez externalTrafficPolicy sur Local dans le fichier manifeste du service :
apiVersion: v1
kind: Service
metadata:
name: my-lb-service
spec:
type: LoadBalancer
externalTrafficPolicy: Local
selector:
app: demo
component: users
ports:
- protocol: TCP
port: 80
targetPort: 8080
Lorsque vous définissez externalTrafficPolicy sur Local, l'équilibreur de charge n'envoie le trafic qu'aux nœuds qui ont un pod sain appartenant au service.
L'équilibreur de charge effectue une vérification de l'état pour identifier les nœuds qui possèdent les pods appropriés.
Équilibreur de charge externe
Si votre service doit être accessible depuis l'extérieur du cluster et du réseau VPC, vous pouvez configurer le service en tant qu'équilibreur de charge lorsque vous le définissez en attribuant à son champ type la valeur Loadbalancer. GKE provisionne alors un équilibreur de charge réseau passthrough externe devant le service.
L'équilibreur de charge réseau passthrough externe connaît tous les nœuds de votre cluster et configure les règles de pare-feu de votre réseau VPC pour autoriser les connexions au service depuis l'extérieur du réseau VPC à l'aide de l'adresse IP externe du service. Vous pouvez affecter au service une adresse IP externe statique.
Pour en savoir plus, consultez Configurer des noms de domaine avec des adresses IP statiques.
Pour en savoir plus sur les règles de pare-feu, consultez la section Règles de pare-feu créées automatiquement.
Détails techniques
Avec un équilibreur de charge externe, le trafic entrant est initialement acheminé vers un nœud à l'aide d'une règle de transfert associée au réseau Google Cloud .
Une fois que le trafic atteint le nœud, celui-ci utilise sa table NAT iptables pour choisir un pod. kube-proxy gère les règles iptables sur le nœud.
Équilibreur de charge interne
Pour le trafic qui doit accéder à votre cluster depuis le même réseau VPC, vous pouvez configurer votre service pour provisionner un équilibreur de charge réseau passthrough interne. L'équilibreur de charge réseau passthrough interne choisit une adresse IP au sein du sous-réseau VPC de votre cluster, plutôt qu'une adresse IP externe. Les applications ou les services du réseau VPC peuvent utiliser cette adresse IP pour communiquer avec les services du cluster.
Détails techniques
L'équilibrage de charge interne est fourni par Google Cloud. Lorsque le trafic atteint un nœud donné, ce nœud utilise sa table NAT iptables pour choisir un pod, même si celui-ci se trouve sur un autre nœud.
kube-proxy gère les règles iptables sur le nœud.
Pour plus d'informations sur les équilibreurs de charge internes, consultez la page Utiliser un équilibreur de charge réseau passthrough interne.
Équilibreur de charge d'application
De nombreuses applications, telles que les API de services Web RESTful, communiquent via HTTP(S). Vous pouvez autoriser des clients externes à votre réseau VPC à accéder à ce type d'application grâce à un objet Ingress Kubernetes.
Un objet Ingress vous permet de mapper des noms d'hôte et des chemins d'URL sur les services du cluster. Lorsque vous faites appel à un équilibreur de charge d'application, vous devez configurer le service afin d'utiliser un NodePort ainsi qu'une adresse ClusterIP. Quand le trafic accède au service sur l'adresse IP d'un nœud au niveau du NodePort, GKE achemine le trafic vers un pod sain correspondant au service. Vous pouvez spécifier un NodePort ou autoriser GKE à affecter un port inutilisé aléatoire.
Lorsque vous créez la ressource Ingress, GKE provisionne un équilibreur de charge d'application externe dans le projet Google Cloud . L'équilibreur de charge envoie une requête à l'adresse IP d'un nœud au niveau du NodePort. Une fois que la requête atteint le nœud, celui-ci utilise sa table NAT iptables pour choisir un pod. kube-proxy gère les règles iptables sur le nœud.
La définition d'entrée ci-dessous achemine le trafic pour demo.example.com vers un service nommé frontend sur le port 80, et demo-backend.example.com vers un service nommé users sur le port 8080.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: demo
spec:
rules:
- host: demo.example.com
http:
paths:
- backend:
service:
name: frontend
port:
number: 80
- host: demo-backend.example.com
http:
paths:
- backend:
service:
name: users
port:
number: 8080
Pour plus d'informations, consultez la page GKE Ingress pour l'équilibreur de charge d'application.
Détails techniques
Lorsque vous créez un objet Ingress, le contrôleur GKE Ingress configure un équilibreur de charge d'application conformément aux règles définies dans le fichier manifeste Ingress et les fichiers manifestes Service associés. Le client envoie une requête à l'équilibreur de charge d'application. L'équilibreur de charge est un véritable proxy : il choisit un nœud et transfère la requête à la combinaison NodeIP :NodePort de ce nœud. Le nœud utilise sa table NAT iptables pour choisir un pod.
kube-proxy gère les règles iptables sur le nœud.
Sécurité de la mise en réseau
Pour renforcer la sécurité de votre cluster, vous pouvez limiter la connectivité entre les nœuds, entre les pods et vers les équilibreurs de charge.
Limiter la connectivité entre les nœuds
La création de règles de pare-feu d'entrée ou de sortie ciblant les nœuds de votre cluster peut avoir des effets négatifs. Par exemple, l'application de règles de refus de sortie aux nœuds de votre cluster peut interrompre des fonctionnalités telles que NodePort et kubectl exec.
Limiter la connectivité aux pods et aux services
Par défaut, tous les pods exécutés au sein d'un même cluster peuvent communiquer librement entre eux. Cependant, vous pouvez limiter la connectivité au sein d'un cluster de différentes manières suivant vos besoins.
Limiter l'accès entre les pods
Vous pouvez limiter l'accès entre pods au moyen d'une règle de réseau. Les définitions de règles de réseau vous permettent de limiter le trafic d'entrée et de sortie des pods en fonction d'une combinaison arbitraire d'étiquettes, de plages d'adresses IP et de numéros de port.
Par défaut, aucune règle de réseau n'est appliquée et tout trafic est donc autorisé entre les pods du cluster. Dès que vous créez la première règle de réseau dans un espace de noms, tout autre trafic est refusé.
Après avoir créé une règle de réseau, vous devez l'activer explicitement pour le cluster. Pour plus d'informations, consultez la page Configurer des règles de réseau pour les applications.
Restreindre l'accès à un équilibreur de charge externe
Si votre service utilise un équilibreur de charge externe, le trafic en provenance de toute adresse IP externe peut, par défaut, accéder à votre service. Vous pouvez restreindre les plages d'adresses IP autorisées à accéder aux points de terminaison de votre cluster en définissant l'option loadBalancerSourceRanges lorsque vous configurez le service. Vous pouvez spécifier plusieurs plages et vous pouvez à tout moment mettre à jour la configuration d'un service en cours d'exécution. L'instance kube-proxy qui s'exécute sur chaque nœud configure les règles iptables de ce nœud pour refuser tout le trafic ne correspondant pas aux plages spécifiées dans loadBalancerSourceRanges. En outre, lorsque vous créez un service LoadBalancer, GKE crée une règle de pare-feu VPC correspondante pour appliquer ces restrictions au niveau du réseau.
Limiter l'accès à un équilibreur de charge d'application
Si votre service utilise un équilibreur de charge d'application, vous pouvez appliquer une règle de sécurité Google Cloud Armor pour définir les adresses IP externes autorisées à accéder à votre service et les réponses à renvoyer lorsque l'accès est refusé en raison de la stratégie de sécurité. Vous pouvez configurer Cloud Logging pour consigner des informations sur ces interactions.
Si les règles de sécurité Cloud Armor ne sont pas suffisamment précises pour votre application, vous pouvez activer Identity-Aware Proxy sur vos points de terminaison pour mettre en œuvre l'authentification et l'autorisation basées sur l'utilisateur. Pour plus d'informations, consultez le tutoriel détaillé sur la configuration de Cloud IAP.
Problèmes connus
Cette section traite des problèmes connus.
Impossible de connecter le nœud compatible avec les conteneurs à la plage 172.17/16
Une VM de nœud compatible avec containerd ne peut pas se connecter à un hôte disposant d'une adresse IP comprise dans la plage 172.17/16. Pour en savoir plus, consultez la section Conflit avec la plage d'adresses IP 172.17/16.
Ressources restantes des clusters GKE supprimés avec Private Service Connect
Si vous avez créé et supprimé des clusters GKE avec Private Service Connect avant le 7 mai 2024 et que vous avez supprimé le projet contenant le cluster avant le cluster lui-même, vous avez peut-être divulgué des ressources Private Service Connect. Ces ressources restent masquées et ne vous permettent pas de supprimer les sous-réseaux associés. Si vous rencontrez ce problème, contactez l'assistanceGoogle Cloud .
Étapes suivantes
- En savoir plus sur les services.
- En savoir plus sur les pods.
- Configurez un cluster avec un VPC partagé.