本頁面說明 Google Kubernetes Engine (GKE) Inference Gateway 的主要概念和功能。這項 GKE Gateway 擴充功能可最佳化生成式 AI 應用程式的服務。
本頁假設您瞭解下列事項:
- GKE 中的 AI/機器學習自動化調度管理機制
- 生成式 AI 術語
- GKE 網路概念,包括服務和 GKE Gateway API
- 負載平衡 Google Cloud,特別是負載平衡器與 GKE 的互動方式
本頁面適用於下列對象:
- 有興趣使用 Kubernetes 容器自動化調度管理功能,提供 AI/機器學習工作負載服務的機器學習工程師、平台管理員和營運人員,以及資料和 AI 專家。
- 與 Kubernetes 網路互動的雲端架構師和網路專員。
總覽
GKE Inference Gateway 是 GKE Gateway 的擴充功能,可為提供生成式人工智慧 (AI) 工作負載服務,提供最佳化的路由和負載平衡。可簡化 AI 推論工作負載的部署、管理及可觀測性。
如要為 AI/機器學習工作負載選擇最佳負載平衡策略,請參閱「在 GKE 上為 AI 推論選擇負載平衡策略」。
特色與優點
GKE 推論閘道提供下列主要功能,可有效率地為 GKE 上的生成式 AI 應用程式提供生成式 AI 模型:
- 支援的指標:
KV cache hits:鍵/值 (KV) 快取中成功查閱的次數。- GPU 或 TPU 使用率:GPU 或 TPU 積極處理作業的時間百分比。
- 要求佇列長度:等待處理的要求數量。
- 推論最佳化負載平衡:分配要求,盡量提升 AI 模型服務效能。這項功能會使用模型伺服器的指標 (例如
KV cache hits和queue length of pending requests),更有效率地運用加速器 (例如 GPU 和 TPU) 處理生成式 AI 工作負載。這項功能會啟用「前置字元快取感知路由」,這項重要功能會分析要求主體,找出共用內容,並將要求傳送至相同模型副本,盡可能提高快取命中率。這種方法可大幅減少多餘的運算,並縮短第一個權杖的產生時間,因此非常適合用於對話式 AI、檢索增強生成 (RAG) 和其他以範本為基礎的生成式 AI 工作負載。 - 動態 LoRA 微調模型服務:支援在通用加速器上提供動態 LoRA 微調模型。這項功能可在通用基礎模型和加速器上多工處理多個 LoRA 微調模型,減少提供模型服務所需的 GPU 和 TPU 數量。
- 推論最佳化自動調整資源配置:GKE 水平 Pod 自動配置器 (HPA) 會使用模型伺服器指標自動調整資源配置,確保運算資源使用效率,並提升推論效能。
- 模型感知型轉送:根據 GKE 叢集
OpenAI API規格中定義的模型名稱,轉送推論要求。您可以定義閘道轉送政策 (例如流量分割和要求鏡像),管理不同模型版本並簡化模型推出作業。舉例來說,您可以將特定模型名稱的要求,轉送至不同的InferencePool物件,每個物件提供不同版本的模型。如要進一步瞭解如何設定,請參閱「設定以主體為準的轉送」。 - 整合 AI 安全性和內容篩選功能:GKE Inference Gateway 會與 Google Cloud Model Armor 整合,在閘道對提示和回覆套用 AI 安全性檢查和內容篩選功能。Model Armor 會提供要求、回覆和處理作業的記錄,供您回溯分析及最佳化。GKE Inference Gateway 的開放式介面可讓第三方供應商和開發人員,將自訂服務整合至推論要求程序。
- 模型專屬服務
Priority:可指定 AI 模型的服務Priority。相較於可容許延遲的批次推論工作,延遲時間較短的要求優先順序較高。舉例來說,您可以優先處理延遲時間敏感型應用程式的要求,並在資源受限時捨棄時間敏感度較低的作業。 - 推論可觀測性:提供推論要求的可觀測性指標,例如要求率、延遲時間、錯誤和飽和度。透過 Cloud Monitoring 和 Cloud Logging 監控推論服務的效能和行為,並運用預先建構的專用資訊主頁取得詳細洞察資料。詳情請參閱「查看 GKE Inference Gateway 資訊主頁」。
- 透過 Apigee 進行進階 API 管理:與 Apigee 整合,透過 API 安全性、速率限制和配額等功能,強化推論閘道。如需詳細操作說明,請參閱「設定 Apigee 進行驗證和 API 管理」。
- 可擴充性:以可擴充的開放原始碼 Kubernetes Gateway API 推論擴充功能為基礎,支援使用者管理的端點選擇器演算法。
瞭解重要概念
GKE Inference Gateway 強化了現有的 GKE Gateway,後者使用 GatewayClass 物件。GKE 推論閘道導入下列新的 Gateway API 自訂資源定義 (CRD),與 OSS Kubernetes Gateway API 推論擴充功能保持一致:
InferencePool物件:代表一組共用相同運算設定、加速器類型、基礎語言模型和模型伺服器的 Pod (容器)。這會以邏輯方式將 AI 模型服務資源分組及管理。單一InferencePool物件可以跨越多個 Pod,涵蓋不同的 GKE 節點,並提供擴充性和高可用性。InferenceObjective物件:根據OpenAI API規格,從InferencePool指定服務模型的名稱。InferenceObjective物件也會指定模型的服務屬性,例如 AI 模型的Priority。GKE 推論閘道會優先處理優先順序值較高的工作負載。這項功能可讓您在 GKE 叢集上多工處理延遲時間關鍵和延遲時間容許的 AI 工作負載。您也可以設定InferenceObjective物件,提供經過 LoRA 微調的模型。
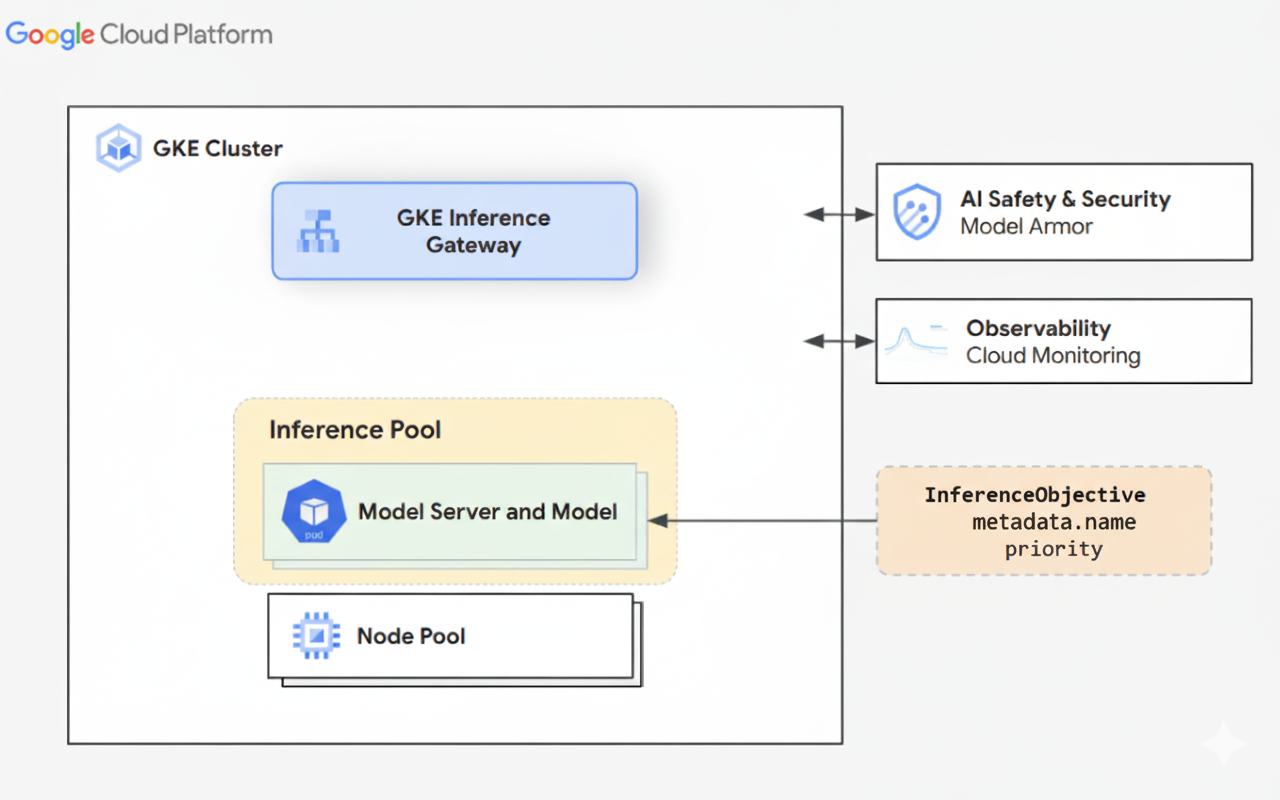
下圖說明 GKE Inference Gateway,以及該閘道在 GKE 叢集內與 AI 安全性、可觀測性和模型服務的整合。
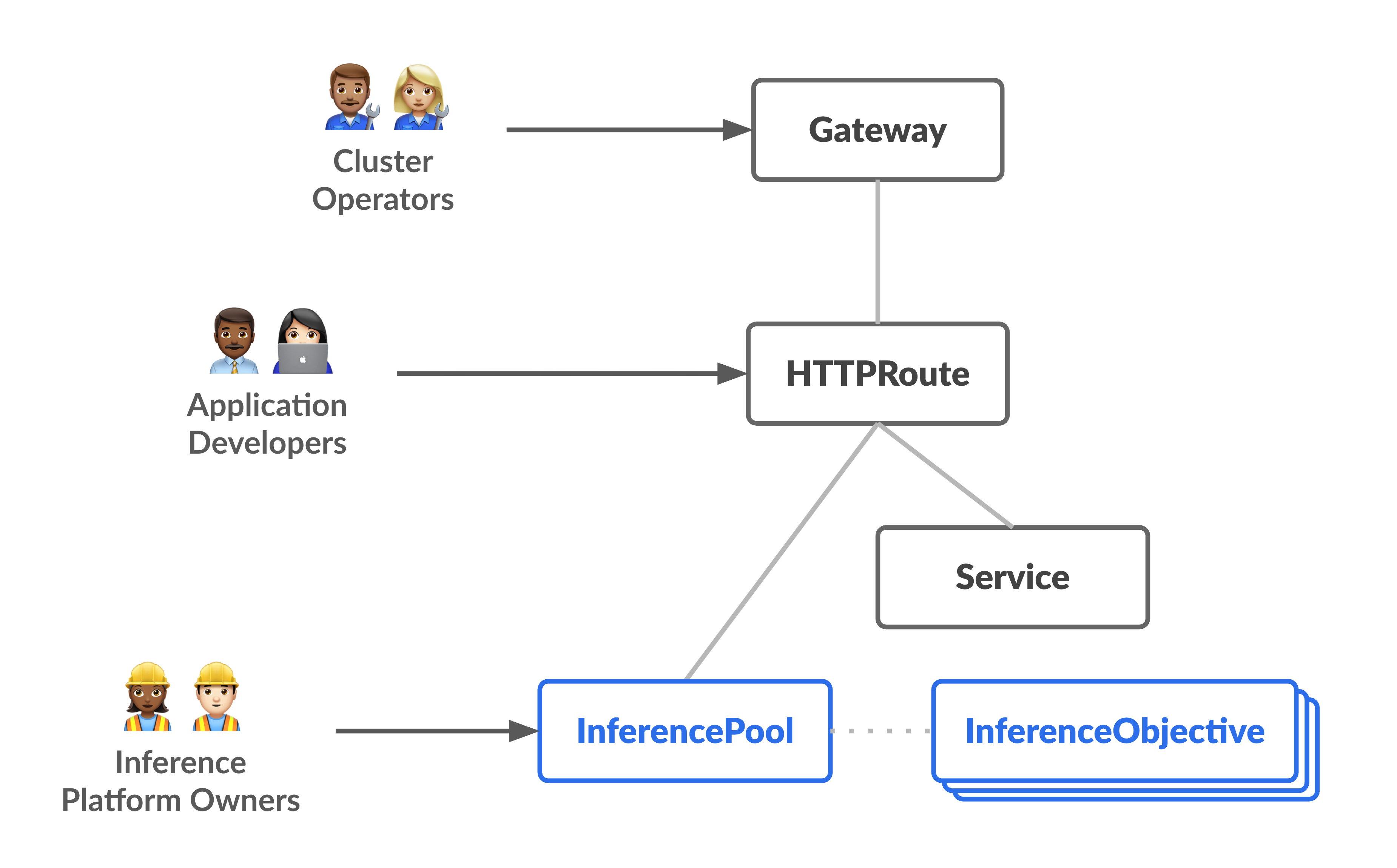
下圖說明資源模型,著重於兩個新的推論導向角色,以及這些角色管理的資源。
GKE Inference Gateway 的運作方式
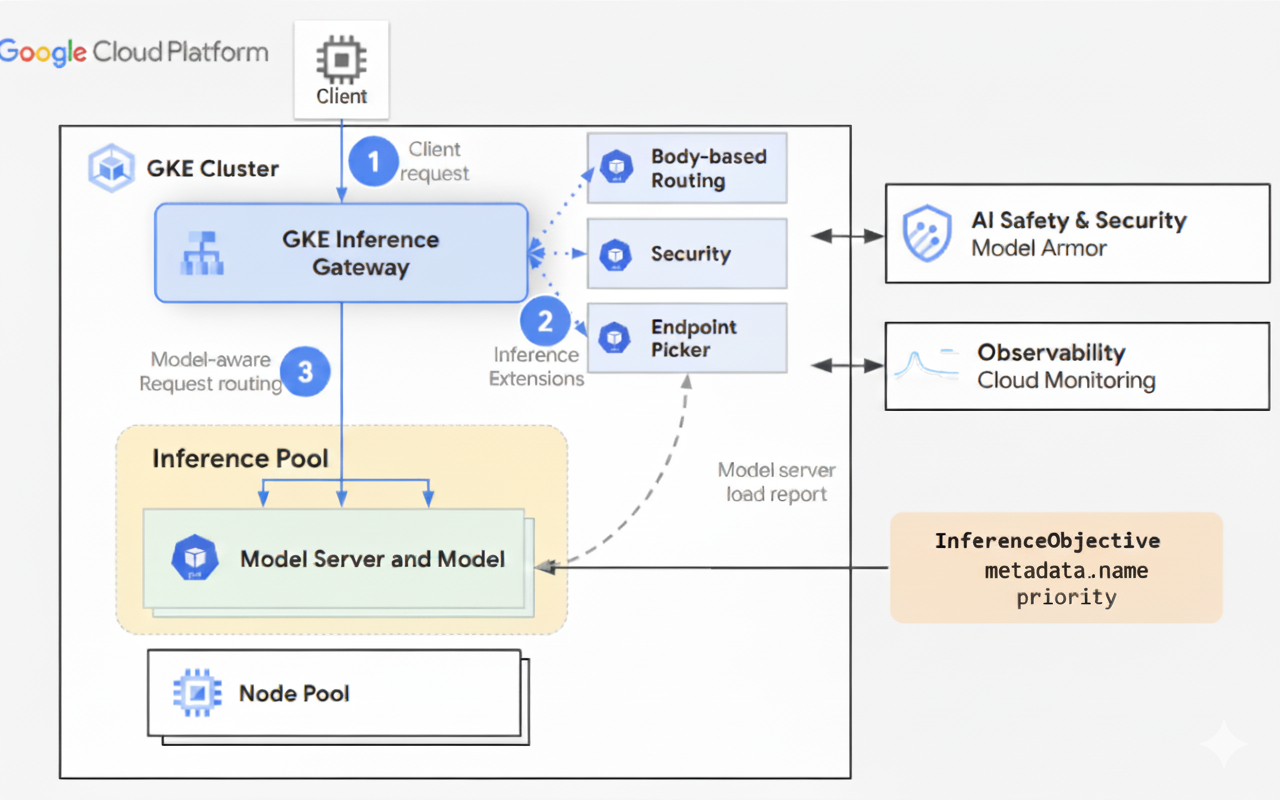
GKE Inference Gateway 會使用 Gateway API 擴充功能和模型專屬的路由邏輯,處理用戶端對 AI 模型的要求。以下步驟說明要求流程。
要求流程的運作方式
GKE Inference Gateway 會將用戶端要求從初始要求轉送至模型執行個體。本節說明 GKE Inference Gateway 如何處理要求。所有用戶端都會採用這個常見的要求流程。
- 用戶端會將要求傳送至 GKE 中執行的模型,要求格式如 OpenAI API 規格所述。
- GKE Inference Gateway 會使用下列推論擴充功能處理要求:
- 以主體為準的轉送擴充功能:從用戶端要求主體擷取模型 ID,並傳送至 GKE Inference Gateway。接著,GKE Inference Gateway 會根據 Gateway API
HTTPRoute物件中定義的規則,使用這個 ID 轉送要求。要求主體轉送與根據網址路徑轉送類似。兩者的差異在於要求主體路徑會使用要求主體的資料。 - 安全性擴充功能:使用 Model Armor 或支援的第三方解決方案,強制執行模型專屬的安全政策,包括內容篩選、威脅偵測、清除和記錄。安全性擴充功能會將這些政策套用至要求和回應處理路徑。
- 端點選擇器擴充功能:監控
InferencePool內模型伺服器的重要指標。這項指標會追蹤每個模型伺服器上的鍵/值快取 (KV 快取) 使用率、待處理要求佇列長度、前置字元快取索引,以及作用中的 LoRA 轉接器。然後根據這些指標,將要求轉送至最佳模型副本,盡量縮短延遲時間,並提高 AI 推論的處理量。
- 以主體為準的轉送擴充功能:從用戶端要求主體擷取模型 ID,並傳送至 GKE Inference Gateway。接著,GKE Inference Gateway 會根據 Gateway API
- GKE Inference Gateway 會將要求轉送至端點選擇器擴充功能傳回的模型副本。
下圖說明從用戶端到模型執行個體的請求流程,該流程會經過 GKE Inference Gateway。
流量分配的運作方式
GKE Inference Gateway 會將推論要求動態分配至 InferencePool 物件中的模型伺服器。這有助於盡可能提高資源使用率,並在不同負載條件下維持效能。GKE Inference Gateway 會使用下列兩種機制管理流量分配:
端點挑選:動態選取最合適的模型伺服器,處理推論要求。負載平衡器會監控伺服器負載和可用性,然後計算每部伺服器的
score,並結合多項最佳化啟發式方法,做出最佳路徑決策:- 前置字元快取感知路由:GKE Inference Gateway 會追蹤每個模型伺服器上的可用前置字元快取索引,並為前置字元快取相符程度較高的伺服器提供較高的分數。
- 負載感知路徑:GKE Inference Gateway 會監控伺服器負載 (KV 快取用量和待處理佇列深度),並為負載較低的伺服器提供較高的分數。
- LoRA 感知路徑:啟用動態 LoRA 服務時,GKE Inference Gateway 會監控每個伺服器的作用中 LoRA 適應器,並為作用中 LoRA 適應器或額外空間的伺服器提供較高分數,以便動態載入要求的 LoRA 適應器。系統會選取總分最高的伺服器。
佇列和卸除:管理要求流程,防止流量過載。GKE Inference Gateway 會將傳入的要求儲存在佇列中,並根據定義的優先順序排定要求優先順序。
GKE Inference Gateway 使用數字 Priority 系統 (也稱為 Criticality) 管理要求流程,並防止過載。這是使用者為每個 InferenceObjective 定義的選填整數欄位。Priority值越高代表要求越重要。當系統負載過重時,Priority 小於 0 的要求會視為優先順序較低,並優先捨棄,傳回 429 錯誤,以保護更重要的工作負載。Priority 的預設值為 0。只有在明確將要求的 Priority 設為小於 0 的值時,系統才會因優先順序而捨棄要求。這個系統可讓您優先處理對延遲時間較敏感的線上推論流量,而非對時間較不敏感的批次工作。
GKE Inference Gateway 支援串流推論,適用於需要持續或近乎即時更新的應用程式,例如聊天機器人和即時翻譯。串流推論會以遞增的區塊或片段傳送回覆,而不是單一的完整輸出內容。如果串流回應期間發生錯誤,系統會終止串流,並向用戶端傳送錯誤訊息。GKE 推論閘道不會重試串流回應。
查看應用程式範例
本節提供使用 GKE Inference Gateway 解決各種生成式 AI 應用程式情境的範例。
範例 1:在 GKE 叢集上提供多個生成式 AI 模型
某公司想部署多個大型語言模型 (LLM),以處理不同的工作負載。舉例來說,他們可能會想為聊天機器人介面部署 Gemma3 模型,並為推薦應用程式部署 Deepseek 模型。公司必須確保這些 LLM 的放送成效達到最佳狀態。
使用 GKE Inference Gateway,您可以在 InferencePool 中,以所選的加速器設定,將這些 LLM 部署至 GKE 叢集。然後,您可以根據模型名稱 (例如 chatbot 和 recommender) 和 Priority 屬性轉送要求。
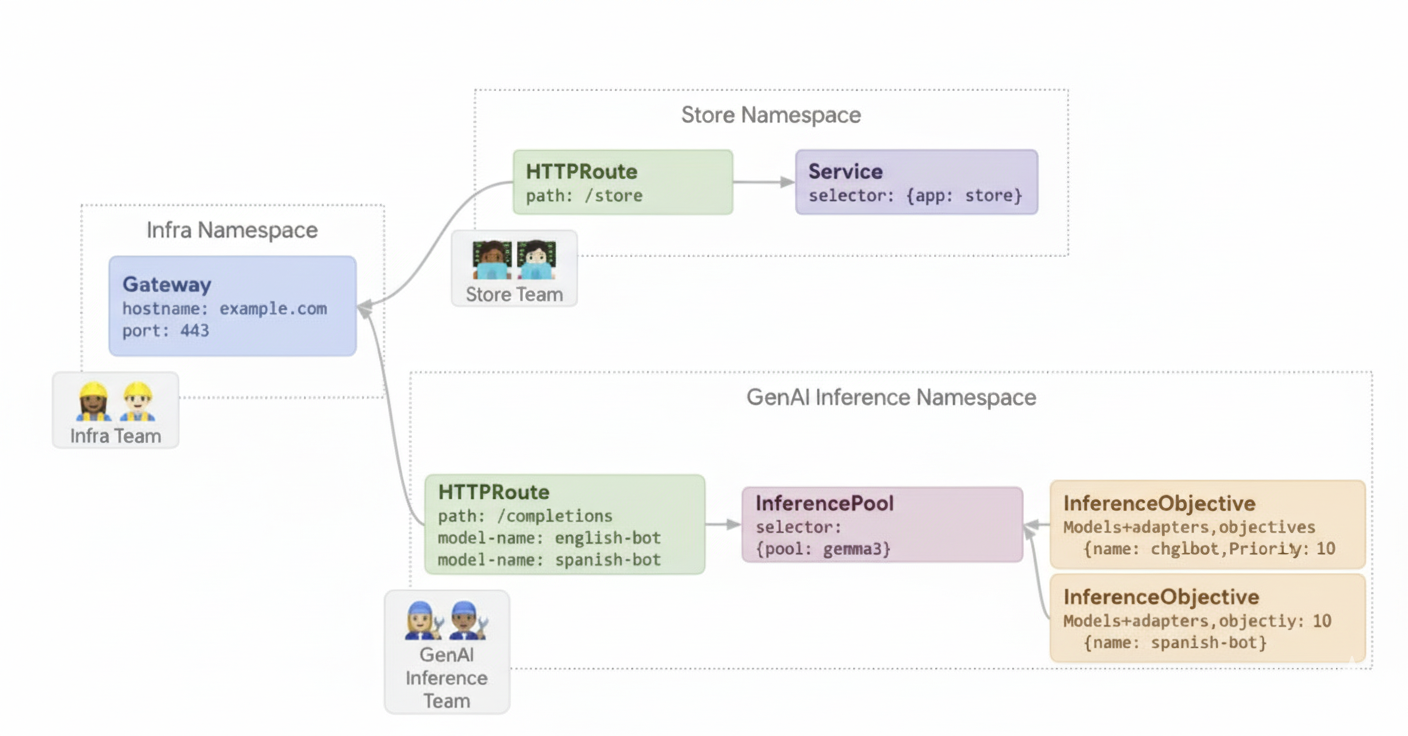
下圖說明 GKE Inference Gateway 如何根據模型名稱和 Priority,將要求轉送至不同模型。
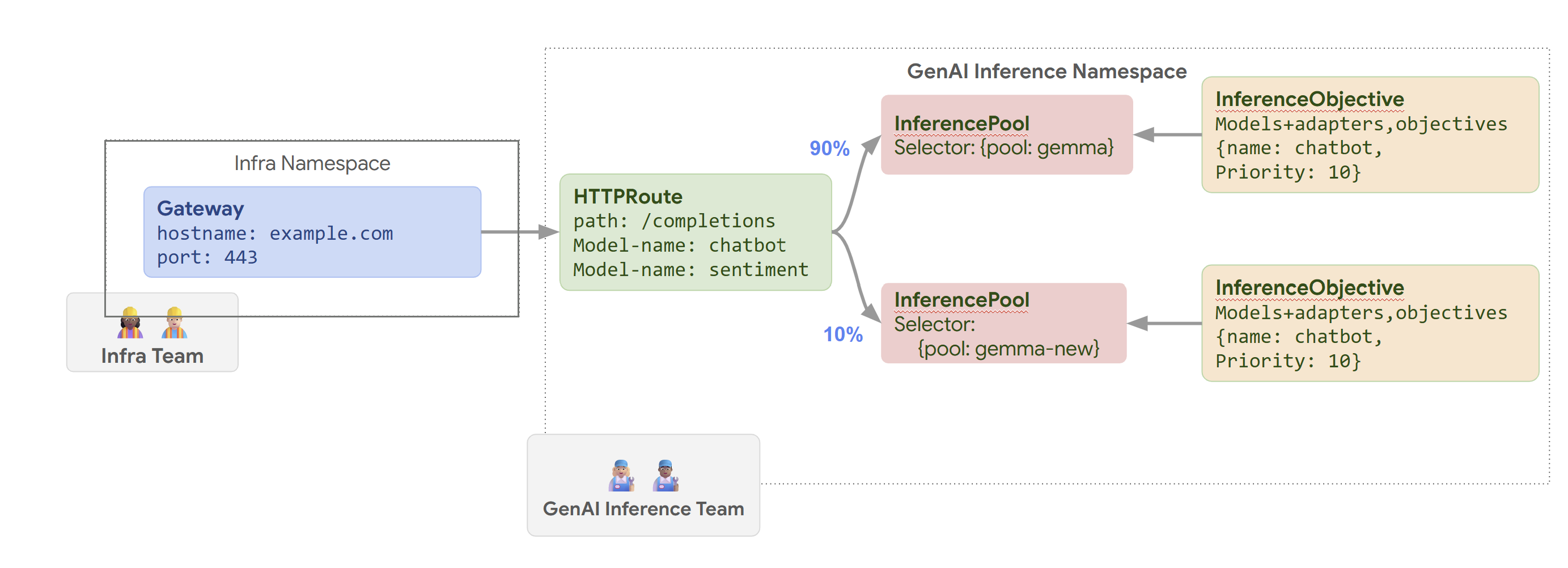
這張圖說明 GKE Inference Gateway 如何處理對 example.com/completions 上生成式 AI 服務的請求。要求會先抵達 Infra 命名空間中的 Gateway。這個 Gateway 會將要求轉送至 GenAI Inference 命名空間中的 HTTPRoute,該 HTTPRoute 已設定為處理聊天機器人和情緒模型的要求。對於聊天機器人模型,HTTPRoute 會分割流量:90% 的流量會導向執行目前模型版本 (由 {pool: gemma} 選取) 的 InferencePool,10% 的流量則會導向較新版本的集區 ({pool: gemma-new}),通常用於初期測試。這兩個集區都會連結至 InferenceObjective,為聊天機器人模型的要求指派 Priority 10,確保這些要求會以高優先順序處理。
範例 2:在共用加速器上提供 LoRA 適應器
某公司想提供大型語言模型進行文件分析,並以多種語言 (例如英文和西班牙文) 的目標對象為重。他們已針對每種語言微調模型,但需要有效運用 GPU 和 TPU 容量。您可以使用 GKE Inference Gateway,在通用基礎模型 (例如 llm-base) 和加速器上,為每種語言 (例如 english-bot 和 spanish-bot) 部署動態 LoRA 微調轉接程式。這樣一來,您就能在共用加速器上密集封裝多個模型,減少所需的加速器數量。
下圖說明 GKE Inference Gateway 如何在共用加速器上提供多個 LoRA 配接器。