Vortrainierten Prozessor weiter trainieren
Mit dem Rechnungsparser können Sie einen vortrainierten Prozessor weiter trainieren, um die Genauigkeit zu verbessern. Sie beginnen mit einem vorgefertigten Modell und trainieren es dann mit Ihren Daten, wobei Sie benutzerdefinierte Felder hinzufügen. Rechnungsformate sind vielfältig. Sie können ein Aufbautraining für einen generischen Rechnungsparser mit Ihren eigenen Daten durchführen, um die Genauigkeit bei bestimmten Formaten zu verbessern. Außerdem kann der Parser Felder extrahieren, die vom vortrainierten Modell nicht unterstützt werden. Es werden Beispieldaten bereitgestellt, aber Sie können dieselben Schritte mit Ihren eigenen Daten ausführen.
Eine detaillierte Anleitung dazu finden Sie direkt in der Google Cloud Console. Klicken Sie dazu einfach auf Anleitung:
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Wählen Sie im Google Cloud Navigationsmenü der Console Document AI und dann Prozessorgalerie aus.
Suchen Sie in der Prozessorgalerie
nach Rechnungsparser und wählen Sie Erstellen aus.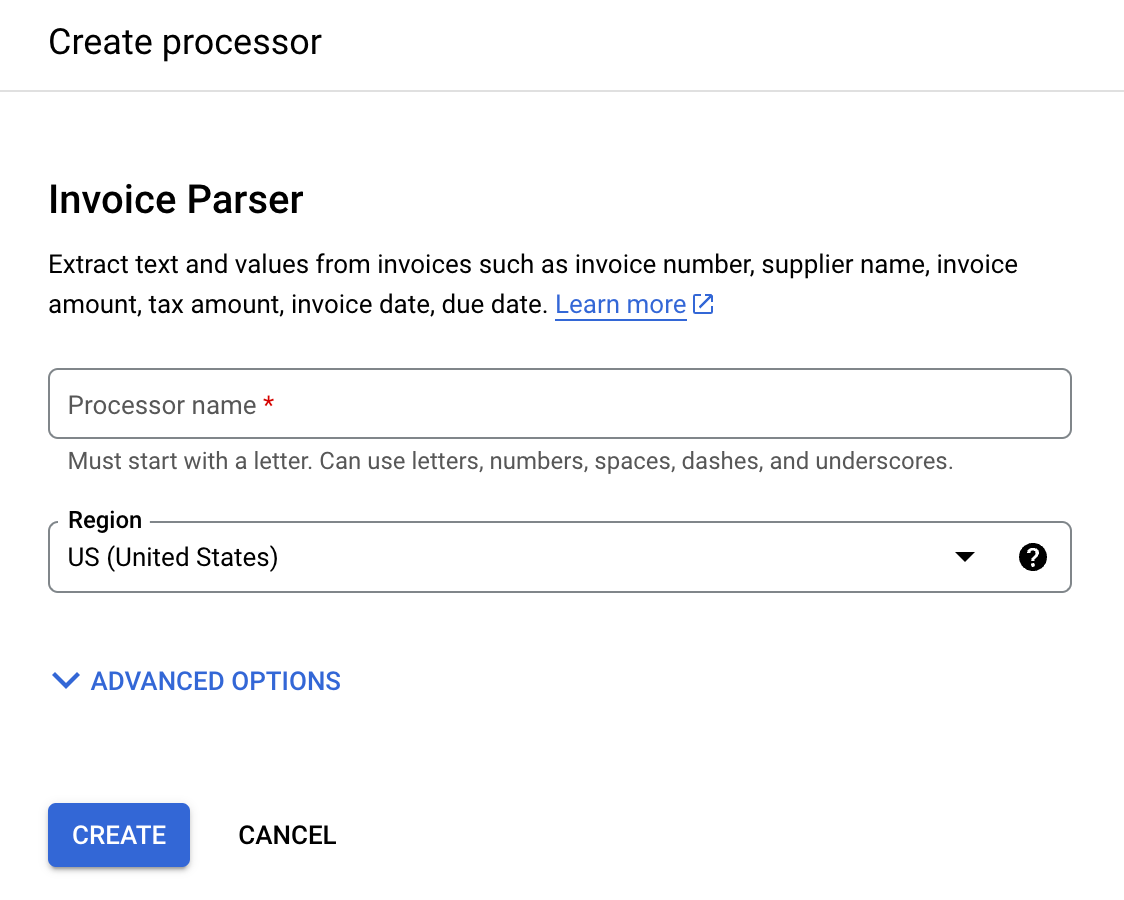
Geben Sie einen Prozessornamen ein, z. B.
invoice-parser-for-uptraining.Wählen Sie die Region aus, die Ihnen am nächsten ist.
Wählen Sie Erstellen aus. Der Tab Details zum Prozessor wird angezeigt.
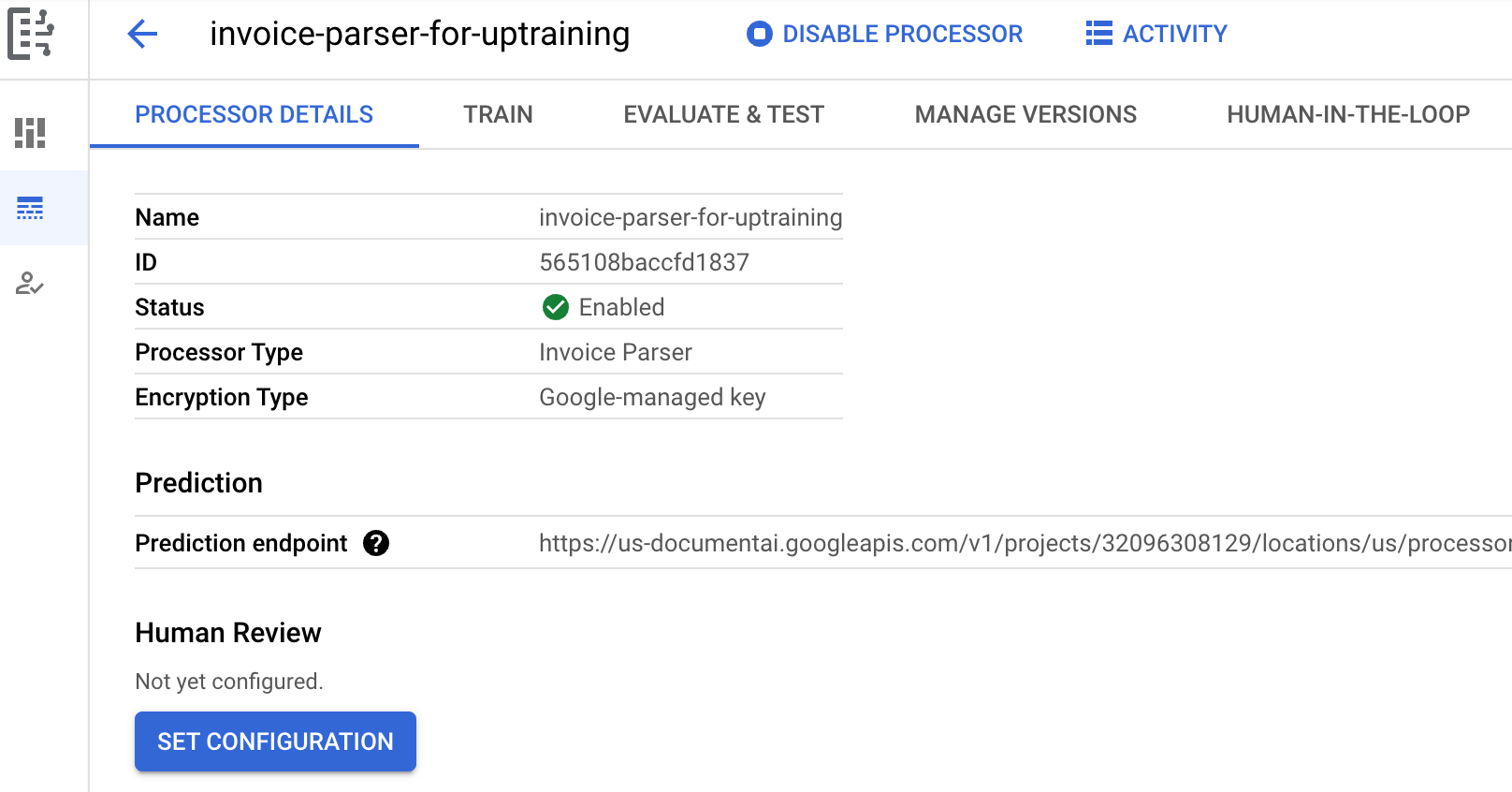
Wechseln Sie zum Tab
Trainieren des Prozessors.Dataset-Speicherort festlegen auswählen: Sie werden aufgefordert, einen leeren Cloud Storage-Bucket oder -Ordner auszuwählen oder zu erstellen.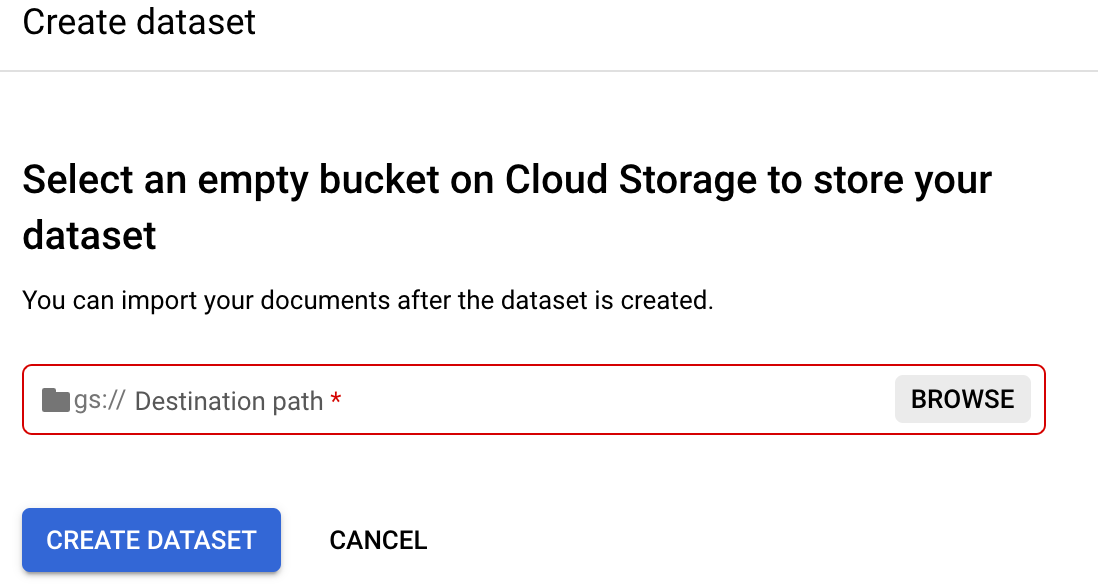
Wählen Sie
Durchsuchen aus, um Ordner auswählen zu öffnen.Wählen Sie
Neuen Bucket erstellen aus und folgen Sie der Anleitung, um einen neuen Bucket zu erstellen. Weitere Informationen zum Erstellen eines Cloud Storage-Buckets finden Sie in Cloud Storage-Buckets.Hinweis: Ein Bucket ist die übergeordnete Speicherentität, in der Sie Ordner verschachteln können. Anstatt einen Bucket zu erstellen und auszuwählen, können Sie auch einen leeren Ordner in einem vorhandenen Bucket erstellen und auswählen, wenn Sie dies vorziehen. Weitere Informationen finden Sie unter Simulierte Ordner.
Nachdem Sie den Bucket erstellt haben, wird die Seite Ordner auswählen für diesen Bucket angezeigt.
Wählen Sie auf der Seite Ordner auswählen für Ihren Bucket die Schaltfläche
Auswählen unten im Dialogfeld aus.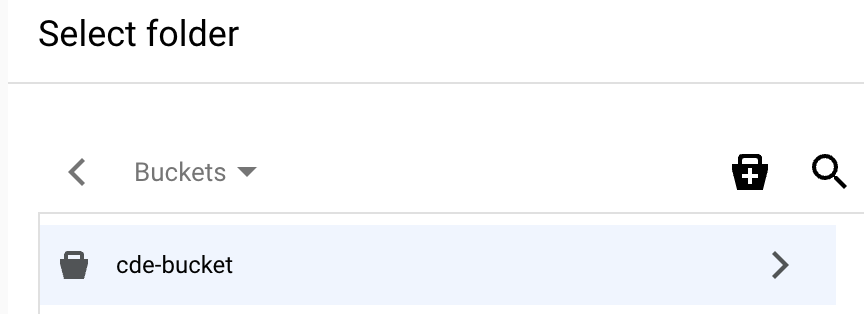
Geben Sie im Feld Zielpfad den von Ihnen ausgewählten Bucket-Namen ein. Wählen Sie
Dataset erstellen aus. Das Erstellen des Datasets kann mehrere Minuten dauern.
Direkt mit dem Uptraining fortfahren: Fahren Sie mit dem Importieren von Daten mit Labels fort. Anstatt ein Beispieldokument zu importieren, verwenden Sie Tools, um die Felder manuell zu kennzeichnen und das Dokument den Trainingsdaten hinzuzufügen.
Dokumente manuell labeln und dem Trainingsset hinzufügen: Bevor Sie mit dem Uptraining fortfahren, folgen Sie der Anleitung unter Beispieldokument zum manuellen Labeln importieren.
Wählen Sie im Tab Trainieren die Option
Dokumente importieren aus.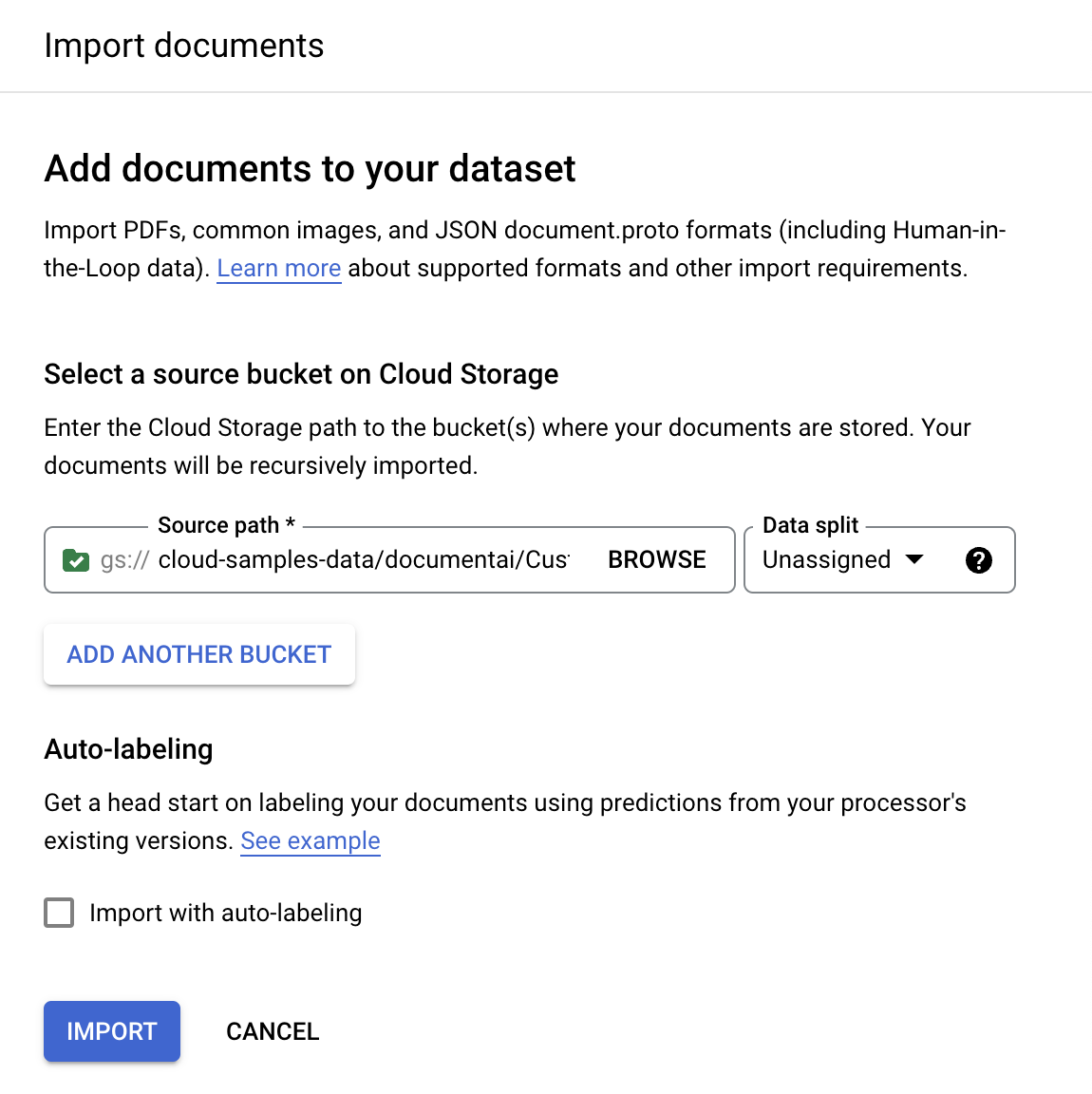
In diesem Beispiel geben Sie diesen Bucket-Namen unter
Quellpfad ein. Dadurch wird direkt auf ein Dokument verwiesen.cloud-samples-data/documentai/codelabs/uptraining/pdfsWählen Sie für Datenaufteilung die Option Nicht zugewiesen. Das Dokument in diesem Ordner ist nicht dem Test- oder Trainings-Dataset zugewiesen. Das Häkchen bei Mit automatischem Labeling importieren darf nicht gesetzt sein.
Wählen Sie Importieren aus. Document AI liest die Dokumente aus dem Bucket in das Dataset. Der Import-Bucket wird nicht geändert und es wird nicht aus dem Bucket gelesen, nachdem der Import abgeschlossen ist.
Wählen Sie im Tab Trainieren links unten die Option
Schema bearbeiten aus. Die Seite Labels verwalten wird geöffnet.Wenn Sie nicht verwendete Labels deaktivieren möchten, klicken Sie die
Kästchen der Felder an, die nicht auf der folgenden Liste stehen, und wählen Sie dann Deaktivieren aus. Die folgenden Felder sollten aktiviert bleiben:invoice_date line_item amount description receiver_address receiver_name supplier_address supplier_name total_amountHinweis: Labels können nicht gelöscht werden. Stattdessen können Sie alle Labels deaktivieren, die Sie nicht verwenden möchten.
Wählen Sie abschließend die Option
Speichern aus.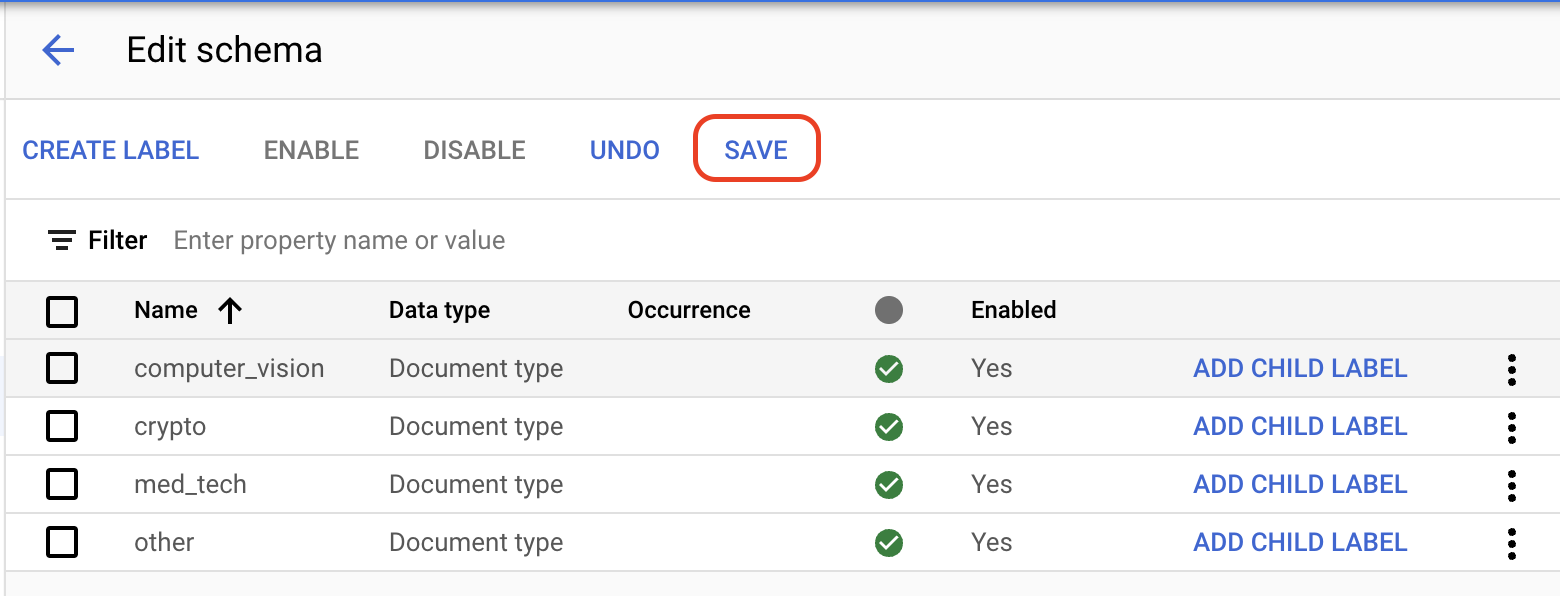
Wählen Sie den
Zurückpfeil aus, um zur Seite Trainieren zurückzukehren.Kehren Sie zum Tab Trainieren zurück und wählen Sie
ein Dokument aus, um die Konsole Labelverwaltung zu öffnen.Als Nächstes wählen Sie im linken Bereich das Schemalabel aus, das dem Wert entspricht, den Sie annotieren möchten, und wenden Sie das Label an.
Verwenden Sie das Tool
Begrenzungsrahmen standardmäßig oder das ToolText auswählen , um mehrzeilige Werte auszuwählen. und weisen Sie das Label zu.In dieser Rechnung soll z. B. dem Text „McWilliam Piping International Piping Company“ das Label
supplier_namezugewiesen werden. Mit dem Textfilter können Sie nach Labelnamen suchen.Hinweis: Das Tool Text auswählen funktioniert nicht für alle Textwerte. Verwenden Sie daher ggf. das Tool Begrenzungsrahmen. Mit dem Tool Begrenzungsrahmen können Sie auch Nicht-Textfelder auswählen, z. B. Kästchen.
Prüfen Sie, ob die erkannten Textwerte den gewünschten Text aus dem Dokument wiederspiegeln.
Wenn Sie Text auswählen, der einem Label entspricht, achten Sie darauf, nur den relevanten Text anzugeben. Fügen Sie beispielsweise für das Label „
invoice_id“ keine Zeichen wie „#“ ein, die häufig vor dem numerischen Wert stehen. Verwenden Sie keine Währungssymbole wie$für Geld.- Sie müssen alle Instanzen einer Entität annotieren. Beispielsweise kann
supplier_nameoderinvoice_idim Dokument mehrmals vorkommen und jede Instanz sollte annotiert werden.
- Sie müssen alle Instanzen einer Entität annotieren. Beispielsweise kann
Wiederholen Sie den Vorgang für jedes Feld, das Sie mit einem Label versehen möchten.
Wählen Sie
Als „Mit Label versehen“ markieren aus, wenn Sie das Dokument fertig annotiert haben.Auf dem Tab Trainieren im linken Bereich wird angezeigt, dass ein Dokument mit einem Label versehen wurde.
Klicken Sie auf dem Tab Trainieren auf das Kästchen
Alle auswählen .Wählen Sie in der Drop-down-Liste
Zu Set zuweisen Training aus.Dokumente importieren auswählen.Geben Sie unter
Quellpfad den folgenden Pfad ein. Dieser Bucket enthält Dokumente mit Labels im Document JSON-Format.cloud-samples-data/documentai/Custom/Invoices/JSONWählen Sie in der Drop-down-Liste Datenaufteilung die Option Automatisch aufteilen. Dadurch werden die Dokumente automatisch so aufgeteilt, dass 80 % im Trainingsset und 20 % im Testset enthalten sind. Das Häkchen bei Mit automatischem Labeling importieren darf nicht gesetzt sein.
Wählen Sie Importieren aus. Der Import kann mehrere Minuten dauern. Anschließend finden Sie die Dokumente auf dem Tab Trainieren.
Klicken Sie auf der Seite Trainieren auf
Dokumente importieren .Kopieren Sie den folgenden Cloud Storage-Pfad und fügen Sie ihn ein. Dieses Verzeichnis enthält fünf Rechnungs-PDFs ohne Labels. Wählen Sie in der Drop-down-Liste Datenaufteilung die Option Training aus.
cloud-samples-data/documentai/Custom/Invoices/PDF_UnlabeledKlicken Sie im Bereich Automatisches Labeling das Kästchen
Mit automatischem Labeling importieren an.Wählen Sie eine vorhandene Prozessorversion aus, um den Dokumenten Labels hinzuzufügen.
- Beispiel:
pretrained-invoice-v1.3-2022-07-15
- Beispiel:
Wählen Sie Importieren aus und warten Sie, bis die Dokumente importiert wurden. Sie können diese Seite in der Zwischenzeit verlassen und später wieder zurückkehren.
- Anschließend werden die Dokumente auf der Seite Trainieren im Bereich Automatisch mit Label versehen angezeigt.
Automatisch mit Labels versehene Dokumente können nicht für Trainings- oder Testzwecke verwendet werden, ohne sie als „Mit Label versehen“ zu markieren. Rufen Sie den Bereich
Automatisch mit Label versehen auf, um die automatisch gekennzeichneten Dokumente anzusehen.Wählen Sie das erste Dokument aus, um die Labeling-Konsole aufzurufen.
Prüfen Sie, ob das Label korrekt ist. Korrigieren Sie die Angabe, falls sie falsch ist.
Wenn Sie fertig sind, wählen Sie
Als „Mit Label versehen“ markieren aus.Wiederholen Sie die Labelüberprüfung für jedes Dokument mit automatischem Label und kehren Sie dann zur Seite Trainieren zurück, um die Daten für das Training zu verwenden.
Wählen Sie
Uptraining für neue Version aus.Geben Sie im Feld
Versionsname einen Namen für diese Prozessorversion ein, z. B.invoice-uptrain-1.Optional: Wählen Sie Labelstatistiken anzeigen aus, um Informationen zu den Dokumentlabels aufzurufen. So können Sie Ihre Abdeckung besser einschätzen. Wählen Sie Schließen, um zur Trainingseinrichtung zurückzukehren.
Wählen Sie
Training starten aus. Sie können den Status im rechten Bereich prüfen.Die Seite Dataset-Verwaltung wird geöffnet. Rechts auf der Seite sehen Sie den Trainingsstatus. Je nach Größe des Datasets kann das Training wahrscheinlich einige Stunden dauern. Sie können diese Seite in der Zwischenzeit verlassen und später wieder zurückkehren.
Wechseln Sie nach Abschluss des Trainings zum Tab
Versionen verwalten . Sie können sich Details zur gerade trainierten Version ansehen.Wählen Sie rechts neben der Version, die Sie bereitstellen möchten, das
Dreipunkt-Menü aus und wählen Sie Version bereitstellen.Wählen Sie im Pop-up-Fenster
Bereitstellen .Die Bereitstellung kann mehrere Minuten dauern.
Wechseln Sie nach Abschluss der Bereitstellung zum Tab
Bewerten und Testen .Auf dieser Seite sehen Sie Bewertungsmesswerte wie den F1-Wert, die Genauigkeit und die Trefferquote für das gesamte Dokument sowie einzelne Labels. Weitere Informationen zu Auswertungen und Statistiken finden Sie in Prozessor auswerten.
Laden Sie ein Dokument herunter, das nicht an vorherigen Trainings oder Tests beteiligt war, damit Sie es zur Bewertung der Prozessorversion verwenden können. Wenn Sie eigene Daten nutzen, verwenden Sie ein speziell dafür gedachtes Dokument.
Wählen Sie
Testdokument hochladen und wählen Sie das Dokument aus, das Sie gerade heruntergeladen haben.Die Seite Analyse des Rechnungsparsers wird geöffnet. Auf dem Bildschirm sehen Sie, wie gut das Dokument klassifiziert wurde.
Sie können die Bewertung auch noch einmal mit einem anderen Testset oder einer anderen Prozessorversion ausführen.
Wählen Sie im Google Cloud Navigationsmenü der Console Document AI und dann Meine Prozessoren aus.
Wählen Sie in der Zeile, in der sich der zu löschende Prozessor befindet,
Weitere Aktionen aus.Wählen Sie Prozessor löschen aus, geben Sie den Namen des Prozessors ein und wählen Sie zur Bestätigung noch einmal Löschen aus.
Prozessor erstellen
Cloud Storage-Bucket für das Dataset erstellen
Zum Trainieren dieses neuen Prozessors müssen Sie ein Dataset mit Trainings- und Testdaten erstellen, damit der Prozessor die Entitäten ermitteln kann, die Sie extrahieren möchten.
Für dieses Dataset ist ein neuer Cloud Storage-Bucket erforderlich. Verwenden Sie nicht denselben Bucket, in dem Ihre Dokumente gespeichert sind.
Beispieldokument zur manuellen Labelerstellung importieren
Als Nächstes importieren Sie eine Beispiel-PDF-Datei in Ihr Dataset. Die Felder in diesem Dokument werden mit einem Label versehen, um den nachfolgenden Uptraining-Prozess zu unterstützen.
In diesem Leitfaden wird eine repräsentative Datei als Beispieldokument bereitgestellt.
Wenn Sie Dokumente importieren, können Sie die Dokumente entweder dem beim Importieren festgelegten Training oder Test zuweisen oder die Zuweisungen später vornehmen.
Wenn Sie ein oder mehrere importierte Dokumente löschen möchten, wählen Sie sie auf dem Tab Trainieren aus und wählen Sie Löschen aus.
Weitere Informationen zur Vorbereitung Ihrer Daten für den Import finden Sie im Leitfaden zur Datenvorbereitung.
Prozessorschema definieren
Ihr Dataset enthält möglicherweise nicht alle Labels, die vom Rechnungsparser unterstützt werden.
In diesem Fall müssen Sie die nicht verwendeten Labels als Inactive markieren, bevor Sie mit dem Training beginnen. Sie können auch ein oder mehrere benutzerdefinierte Labels hinzufügen, bevor Sie mit dem Training beginnen.
Dokument mit Label versehen
Das Auswählen von Text in einem Dokument und das Anwenden von Labels wird als Annotation bezeichnet.
Hier ein Beispiel für den vollständigen Satz von Labels mit entsprechendem Text.
| Labelname | Text |
|---|---|
supplier_name |
McWilliam Piping International Piping Company |
supplier_address |
14368 Pipeline Ave Chino, CA 91710, USA |
invoice_id |
10001 |
due_date |
2020-01-02 |
line_item/description |
Janney-Kupplung |
line_item/quantity |
9 |
line_item/unit_price |
74,43 |
line_item/amount |
669,87 |
line_item/description |
PVC-Rohre 12" |
line_item/quantity |
7 |
line_item/unit_price |
15,90 |
line_item/amount |
111,30 |
line_item/description |
Kupferrohr |
line_item/quantity |
7 |
line_item/unit_price |
91,20 |
line_item/amount |
638,40 |
net_amount |
1.419,57 |
total_tax_amount |
113,57 |
total_amount |
1.533,14 |
currency |
$ |
Dem Trainingsset ein kommentiertes Dokument zuweisen
Nachdem Sie dieses Beispieldokument mit einem Label versehen haben, können Sie es dem Trainingsset zuweisen.
Im linken Bereich ist zu sehen, dass dem Trainingsset ein Dokument zugewiesen wurde.
Mit Labels versehene Daten in Trainings- und Testsets importieren
Das Document AI-Aufbautraining benötigt im Trainings- und im Testset mindestens 10 Dokumente sowie jeweils 10 Instanzen jedes Labels in jedem Set.
Für eine optimale Leistung empfehlen wir, mindestens 50 Dokumente pro Set und 50 Instanzen pro Label zu erstellen. Eine größere Menge an Trainingsdaten führt in der Regel zu einer höheren Genauigkeit.
In diesem Leitfaden finden Sie vorab mit Label versehene Daten. Wenn Sie an Ihrem eigenen Projekt arbeiten, müssen Sie festlegen, wie Ihre Daten mit Labels versehen werden sollen. Weitere Informationen zu Labeling-Optionen.
Optional: neu importierte Dokumente automatisch mit Labels versehen
Nachdem Sie eine trainierte Prozessorversion bereitgestellt haben, können Sie mithilfe der automatischen Labelerstellung beim Importieren neuer Dokumente Zeit bei der Labelerstellung sparen.
Prozessor trainieren
Nachdem Sie die Trainings- und Testdaten importiert haben, können Sie den Prozessor trainieren. Da das Training mehrere Stunden dauern kann, sollten Sie den Prozessor mit den entsprechenden Daten und Labels einrichten, bevor Sie mit dem Training beginnen.
Prozessorversion bereitstellen
Prozessor bewerten und testen
Prozessor verwenden
Sie haben einen Rechnungsparser-Prozessor erfolgreich erstellt und trainiert.
Sie können Ihre benutzerdefiniert trainierten Prozessorversionen wie jede andere Prozessorversion verwalten, z. B. bei der Migration zu einem neueren Prozessor, wenn ein anderer eingestellt wird. Weitere Informationen finden Sie in Prozessorversionen verwalten.
Sie können eine Verarbeitungsanfrage an Ihren benutzerdefinierten Prozessor senden. Die Antwort wird wie die anderer Extraktionsprozessoren verarbeitet.
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden:
Löschen Sie den Prozessor und das Projekt mit Google Cloud console, wenn Sie diese nicht mehr benötigen, um unnötige Google Cloud -Kosten zu vermeiden.
Wenn Sie ein neues Projekt erstellt haben, um mehr über Document AI zu erfahren, und dieses Projekt nicht mehr benötigen, [löschen Sie das Projekt][delete-project].
Wenn Sie ein vorhandenes Google Cloud Projekt verwendet haben, löschen Sie die von Ihnen erstellten Ressourcen. So vermeiden Sie, dass Ihrem Konto Gebühren in Rechnung gestellt werden: