Enterprise Document OCR
Sie können Enterprise Document OCR als Teil von Document AI verwenden, um Text und Layoutinformationen aus verschiedenen Dokumenten zu erkennen und zu extrahieren. Mit konfigurierbaren Funktionen können Sie das System an bestimmte Anforderungen der Dokumentverarbeitung anpassen.
Übersicht
Sie können Enterprise Document OCR für Aufgaben wie die Dateneingabe auf der Grundlage von Algorithmen oder maschinellem Lernen sowie für die Verbesserung und Überprüfung der Datenrichtigkeit verwenden. Sie können Enterprise Document OCR auch für Aufgaben wie die folgenden verwenden:
- Text digitalisieren:Text- und Layoutdaten aus Dokumenten für Suchanfragen, regelbasierte Pipelines zur Dokumentverarbeitung oder zum Erstellen benutzerdefinierter Modelle extrahieren.
- Anwendungen für Large Language Models verwenden:Mit dem Kontextverständnis von LLMs und den Text- und Layout-Extraktionsfunktionen von OCR können Sie Fragen und Antworten automatisieren. Gewinnen Sie Erkenntnisse aus Daten und optimieren Sie Workflows.
- Archivierung: Papierdokumente in maschinenlesbaren Text digitalisieren, um die Barrierefreiheit von Dokumenten zu verbessern.
Die beste OCR für Ihren Anwendungsfall auswählen
| Lösung | Produkt | Beschreibung | Anwendungsfall |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Spezielles Modell für Anwendungsfälle im Bereich Dokumente. Zu den erweiterten Funktionen gehören der Qualitätsfaktor für Bilder, Sprachhinweise und die Drehkorrektur. | Empfohlen, wenn Text aus Dokumenten extrahiert werden soll. Anwendungsfälle sind z. B. PDFs, gescannte Dokumente als Bilder oder Microsoft DocX-Dateien. |
| Document AI | OCR-Add-ons | Premium-Funktionen für bestimmte Anforderungen Nur mit Enterprise Document OCR Version 2.0 und höher kompatibel. | Sie müssen mathematische Formeln erkennen, Informationen zur Schriftart erhalten oder die Auslösung von Kästchen aktivieren. |
| Cloud Vision API | Texterkennung | Global verfügbare REST API, die auf dem Google Cloud Standard-OCR-Modell basiert. Das Standardkontingent beträgt 1.800 Anfragen pro Minute. | Allgemeine Anwendungsfälle für die Textextraktion, die eine niedrige Latenz und eine hohe Kapazität erfordern. |
| Cloud Vision | OCR Google Distributed Cloud (nicht mehr unterstützt) | Google Cloud Marketplace-Anwendung, die als Container in jedem GKE-Cluster bereitgestellt werden kann, der GKE Enterprise verwendet. | Um die Anforderungen an den Datenstandort oder die Compliance zu erfüllen. |
Erkennung und Extraktion
Mit der Enterprise Document OCR können Blöcke, Absätze, Zeilen, Wörter und Symbole aus PDFs und Bildern erkannt sowie Dokumente zur Verbesserung der Genauigkeit entschränkt werden.
Unterstützte Attribute für die Layouterkennung und -extraktion:
| Gedruckter Text | Handschrift | Absatz | Blockieren | Linie | Wortmarke | Symbolebene | Seitennummer |
|---|---|---|---|---|---|---|---|
| Standard | Standard | Standard | Standard | Standard | Standard | Konfigurierbar | Standard |
Zu den konfigurierbaren Funktionen von Enterprise Document OCR gehören:
Eingebetteten oder nativen Text aus digitalen PDFs extrahieren:Mit dieser Funktion werden Text und Symbole genau so extrahiert, wie sie in den Quelldokumenten erscheinen, auch bei gedrehtem Text, extremen Schriftgrößen oder -stilen und teilweise ausgeblendetem Text.
Rotationskorrektur:Verwenden Sie Enterprise Document OCR, um Dokumentbilder vorzuverarbeiten und Rotationsprobleme zu korrigieren, die sich auf die Extraktionsqualität oder -verarbeitung auswirken können.
Bildqualitätsbewertung:Sie erhalten Qualitätsmesswerte, die beim Dokumenten-Routing helfen können. Der Bewertung der Bildqualität enthält Qualitätsmesswerte auf Seitenebene in acht Dimensionen, darunter Unschärfe, Schriftarten, die kleiner als üblich sind, und Blendeffekte.
Seitenbereich angeben:Gibt den Bereich der Seiten in einem Eingabedokument für die OCR an. So werden Ausgaben und Verarbeitungszeit für nicht benötigte Seiten gespart.
Spracherkennung:Hiermit werden die Sprachen erkannt, die in den extrahierten Texten verwendet werden.
Sprach- und Handschrifthinweise:Sie können die Genauigkeit verbessern, indem Sie dem OCR-Modell einen Sprach- oder Handschrifthinweis basierend auf den bekannten Merkmalen Ihrer Datasets zur Verfügung stellen.
Informationen zum Aktivieren von OCR-Konfigurationen finden Sie unter OCR-Konfigurationen aktivieren.
OCR-Add-ons
Enterprise Document OCR bietet optionale Analysefunktionen, die bei Bedarf für einzelne Verarbeitungsanfragen aktiviert werden können.
Die folgenden Add-on-Funktionen sind für die stabilen Versionen pretrained-ocr-v2.0-2023-06-02 und pretrained-ocr-v2.1-2024-08-07 sowie für die Release-Kandidatenversion pretrained-ocr-v2.1.1-2025-01-31 verfügbar.
- Mathematische OCR: Formeln aus Dokumenten im LaTeX-Format erkennen und extrahieren.
- Kästchenextraktion: In der OCR-Antwort für Enterprise-Dokumente werden Kästchen erkannt und ihr Status (angeklickt/nicht angeklickt) extrahiert.
- Schriftstilerkennung: Erkennen von Schrifteigenschaften auf Wortebene, einschließlich Schriftart, Schriftstil, Handschrift, Stärke und Farbe.
Informationen zum Aktivieren der aufgeführten Add-ons finden Sie unter OCR-Add-ons aktivieren.
Unterstützte Dateiformate
Die OCR-Funktion für Dokumente im Enterprise-Tarif unterstützt die Dateiformate PDF, GIF, TIFF, JPEG, PNG, BMP und WebP. Weitere Informationen finden Sie unter Unterstützte Dateien.
Enterprise Document OCR unterstützt auch DocX-Dateien mit bis zu 15 Seiten synchron und 30 Seiten asynchron. Die Unterstützung von DocX befindet sich in der privaten Vorschau. Wenn Sie Zugriff anfordern möchten, reichen Sie das Antragsformular für den DocX-Support ein .
Erweiterte Versionsverwaltung
Die erweiterte Versionierung befindet sich in der Vorabversion. Upgrades an den zugrunde liegenden KI-/ML-OCR-Modellen können zu Änderungen am OCR-Verhalten führen. Wenn eine strenge Konsistenz erforderlich ist, verwenden Sie eine eingefrorene Modellversion, um das Verhalten für bis zu 18 Monate an ein älteres OCR-Modell anzupinnen. So wird sichergestellt, dass für die OCR-Funktion immer dasselbe Bild verwendet wird. Weitere Informationen finden Sie in der Tabelle zu Prozessorversionen.
Prozessorversionen
Die folgenden Prozessorversionen sind mit dieser Funktion kompatibel. Weitere Informationen finden Sie unter Prozessorversionen verwalten.
| Versions-ID | Release-Version | Beschreibung |
|---|---|---|
pretrained-ocr-v1.0-2020-09-23 |
Stabil | Die Verwendung wird nicht empfohlen und die Funktion wird ab dem 30. April 2025 in den USA und der EU eingestellt. |
pretrained-ocr-v1.1-2022-09-12 |
Stabil | Die Verwendung wird nicht empfohlen und die Funktion wird ab dem 30. April 2025 in den USA und der EU eingestellt. |
pretrained-ocr-v1.2-2022-11-10 |
Stabil | Eingefrorene Modellversion von Version 1.0: Modelldateien, Konfigurationen und Binärdateien eines Versions-Snapshots, die bis zu 18 Monate lang in einem Container-Image eingefroren sind. |
pretrained-ocr-v2.0-2023-06-02 |
Stabil | Produktionsreifes Modell, das speziell für Anwendungsfälle im Bereich Dokumente entwickelt wurde. Beinhaltet Zugriff auf alle OCR-Add-ons. |
pretrained-ocr-v2.1-2024-08-07 |
Stabil | Die wichtigsten Verbesserungen bei Version 2.1 sind: bessere Erkennung von gedrucktem Text, präzisere Kästchenerkennung und genauere Lesereihenfolge. |
pretrained-ocr-v2.1.1-2025-01-31 |
Release-Kandidat | Version 2.1.1 ähnelt Version 2.1 und ist in allen Regionen verfügbar, mit Ausnahme von US, EU und asia-southeast1. |
Dokumente mit Enterprise Document OCR verarbeiten
In dieser Kurzanleitung wird die OCR für Enterprise-Dokumente vorgestellt. Dort erfahren Sie, wie Sie die OCR-Ergebnisse für Ihr Dokument für Ihren Workflow optimieren, indem Sie eine der verfügbaren OCR-Konfigurationen aktivieren oder deaktivieren.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Enterprise Document OCR-Prozessor erstellen
Erstellen Sie zuerst einen Enterprise Document OCR-Prozessor. Weitere Informationen finden Sie unter Prozessoren erstellen und verwalten.
OCR-Konfigurationen
Alle OCR-Konfigurationen können aktiviert werden, indem Sie die entsprechenden Felder in ProcessOptions.ocrConfig in ProcessDocumentRequest oder BatchProcessDocumentsRequest festlegen.
Weitere Informationen finden Sie unter Antrag auf Verarbeitung senden.
Analyse der Bildqualität
Bei der intelligenten Analyse der Dokumentqualität wird maschinelles Lernen verwendet, um die Qualität eines Dokuments anhand der Lesbarkeit des Inhalts zu bewerten.
Diese Qualitätsbewertung wird als Qualitätsfaktor [0, 1] zurückgegeben, wobei 1 für eine perfekte Qualität steht.
Wenn der erkannte Qualitätsfaktor unter 0.5 liegt, wird auch eine Liste mit Gründen für die schlechte Qualität zurückgegeben, sortiert nach Wahrscheinlichkeit.
Eine Wahrscheinlichkeit von über 0.5 gilt als positive Erkennung.
Wenn das Dokument als fehlerhaft eingestuft wird, gibt die API die folgenden acht Arten von Dokumentfehlern zurück:
quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare
Die aktuelle Analyse der Dokumentqualität hat einige Einschränkungen:
- Es kann fälschlicherweise Fehler in digitalen Dokumenten erkennen, die keine Mängel aufweisen. Die Funktion eignet sich am besten für gescannte oder fotografierte Dokumente.
Blendeffekte sind lokal. Ihre Anwesenheit beeinträchtigt möglicherweise nicht die Lesbarkeit des Dokuments insgesamt.
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.enableImageQualityScores auf true setzen.
Diese zusätzliche Funktion erhöht die Latenz des Prozessaufrufs im Vergleich zur OCR-Verarbeitung.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Die Ergebnisse der Mängelerkennung werden in Document.pages[].imageQualityScores[] angezeigt.
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Vollständige Ausgabebeispiele finden Sie unter Beispiel für Prozessorausgabe.
Sprachhinweise
Der OCR-Prozessor unterstützt Sprachhinweise, die Sie definieren, um die Leistung der OCR-Engine zu verbessern. Wenn Sie einen Sprachhinweis anwenden, kann die OCR für eine ausgewählte Sprache statt für eine abgeleitete Sprache optimiert werden.
Aktivieren Sie diese Funktion, indem Sie ProcessOptions.ocrConfig.hints[].languageHints[] mit einer Liste von BCP-47-Sprachcodes festlegen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Vollständige Ausgabebeispiele finden Sie unter Beispiel für Prozessorausgabe.
Symbolerkennung
Fügen Sie Daten auf Symbol- oder Buchstabenebene in die Antwort des Dokuments ein.
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.enableSymbol auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Wenn diese Funktion aktiviert ist, wird das Feld Document.pages[].symbols[] ausgefüllt.
Vollständige Ausgabebeispiele finden Sie unter Beispiel für Prozessorausgabe.
Integriertes PDF-Parsen
Eingebetteten Text aus digitalen PDF-Dateien extrahieren Wenn diese Option aktiviert ist und digitaler Text vorhanden ist, wird automatisch das integrierte digitale PDF-Modell verwendet. Wenn es sich um nicht digitalen Text handelt, wird automatisch das optische OCR-Modell verwendet. Der Nutzer erhält beide Textergebnisse zusammengeführt.
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.enableNativePdfParsing auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Erkennung von Personen im Feld
Standardmäßig ist bei Enterprise Document OCR ein Detektor aktiviert, um die Qualität der Textextraktion von Zeichen in einem Feld zu verbessern. Hier ein Beispiel:

Wenn bei der OCR-Qualität Probleme mit Zeichen in Kästen auftreten, können Sie diese Option deaktivieren.
Deaktivieren Sie die Funktion, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.disableCharacterBoxesDetection auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Altes Layout
Wenn Sie einen heuristischen Algorithmus zur Layouterkennung benötigen, können Sie das alte Layout aktivieren. Es dient als Alternative zum aktuellen ML-basierten Algorithmus zur Layouterkennung. Dies ist nicht die empfohlene Konfiguration. Kunden können den am besten geeigneten Layoutalgorithmus basierend auf ihrem Dokumentenworkflow auswählen.
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.advancedOcrOptions auf ["legacy_layout"] setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Seitenbereich angeben
Standardmäßig werden mit der OCR-Technologie Text und Layoutinformationen aus allen Seiten der Dokumente extrahiert. Sie können bestimmte Seitenzahlen oder Seitenbereiche auswählen und nur Text von diesen Seiten extrahieren.
In ProcessOptions gibt es drei Möglichkeiten, dies zu konfigurieren:
- So verarbeiten Sie nur die zweite und fünfte Seite:
{
"individualPageSelector": {"pages": [2, 5]}
}
- So verarbeiten Sie nur die ersten drei Seiten:
{
"fromStart": 3
}
- So verarbeiten Sie nur die letzten vier Seiten:
{
"fromEnd": 4
}
In der Antwort entspricht jedes Document.pages[].pageNumber den in der Anfrage angegebenen Seiten.
Verwendung von OCR-Add-ons
Diese optionalen Analysefunktionen der Enterprise Document OCR können bei Bedarf für einzelne Verarbeitungsanfragen aktiviert werden.
Mathematik-OCR
Die mathematische OCR erkennt und extrahiert Formeln wie mathematische Gleichungen, die als LaTeX dargestellt sind, zusammen mit Begrenzungsrahmenkoordinaten.
Hier ein Beispiel für die LaTeX-Darstellung:
Bild erkannt
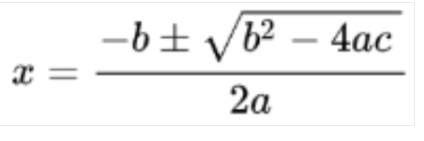
In LaTeX konvertieren
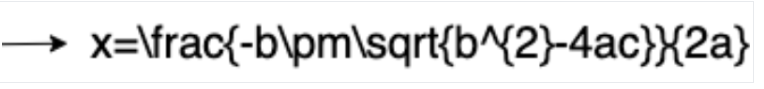
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Die OCR-Ausgabe für Mathematik wird in Document.pages[].visualElements[] mit "type": "math_formula" angezeigt.
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Die vollständige Document-JSON-Ausgabe findest du unter diesem Link .
Extraktion von Auswahlmarkierungen
Wenn diese Option aktiviert ist, versucht das Modell, alle Kästchen und Optionsfelder im Dokument zusammen mit den Begrenzungsrahmenkoordinaten zu extrahieren.
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Die Kästchenausgabe wird in Document.pages[].visualElements[] mit "type": "unfilled_checkbox" oder "type": "filled_checkbox" angezeigt.

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Die vollständige Document-JSON-Ausgabe findest du unter diesem Link .
Erkennung von Schriftarten
Wenn die Schriftstilerkennung aktiviert ist, extrahiert Enterprise Document OCR Schriftattribute, die für eine bessere Nachbearbeitung verwendet werden können.
Auf Tokenebene (Wortebene) werden die folgenden Attribute erkannt:
- Handschrifterkennung
- Schriftstil
- Schriftgröße
- Schriftart
- Schriftfarbe
- Schriftstärke
- Zeichenabstand
- Fett
- Kursiv
- Unterstreichen
- Textfarbe (RGBa)
Hintergrundfarbe (RGBa)
Aktivieren Sie diese Option, indem Sie in der Verarbeitungsanfrage ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Die Ausgabe des Schriftstils wird in Document.pages[].tokens[].styleInfo mit dem Typ StyleInfo angezeigt.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Die vollständige Document-JSON-Ausgabe findest du unter diesem Link .
Dokumentobjekte in das Vision AI API-Format konvertieren
Die Document AI Toolbox enthält ein Tool, mit dem das Format der Document AI API Document in das Vision AI-Format AnnotateFileResponse konvertiert wird. So können Nutzer die Antworten des Dokument-OCR-Prozessors mit denen der Vision AI API vergleichen. Hier ist ein Beispielcode.
Bekannte Abweichungen zwischen der Vision AI API-Antwort und der Document AI API-Antwort und dem Converter:
- In der Antwort der Vision AI API wird bei Bildanfragen nur
verticesund bei PDF-Anfragen nurnormalized_verticeseingefügt. Die Document AI-Antwort und der Konverter füllen sowohlverticesals auchnormalized_verticesaus. - In der Vision AI API-Antwort wird das
detected_breakim letzten Symbol des Wortes eingefügt. In der Antwort der Document AI API und im Konverter wirddetected_breakin das Wort und das letzte Symbol des Wortes eingefügt. - In der Antwort der Vision AI API werden immer Symbolfelder eingefügt. Standardmäßig werden in der Antwort der Dokument-KI keine Symbolfelder ausgefüllt. Damit die Symbolfelder in der Document AI-Antwort und im Konverter ausgefüllt werden, müssen Sie die
enable_symbol-Funktion so einstellen, wie unten beschrieben.
Codebeispiele
In den folgenden Codebeispielen wird gezeigt, wie Sie eine Verarbeitungsanfrage senden, mit der OCR-Konfigurationen und Add-ons aktiviert werden, und dann die Felder lesen und im Terminal ausdrucken:
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION: Standort des Prozessors, z. B.:
us– USAeu– Europäische Union
- PROJECT_ID: Ihre Google Cloud Projekt-ID.
- PROCESSOR_ID: Die ID des benutzerdefinierten Prozessors.
- PROCESSOR_VERSION: die Prozessorversion. Weitere Informationen finden Sie unter Prozessorversion auswählen. Beispiel:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: Boolescher Wert, um die manuelle Überprüfung zu deaktivieren. Wird nur von Human-in-the-Loop-Prozessoren unterstützt.
true– manuelle Überprüfung wird übersprungenfalse– Aktiviert die manuelle Überprüfung (Standard)
- MIME_TYPE†: Eine der gültigen Optionen für den MIME-Typ.
- IMAGE_CONTENT†: Einer der gültigen Inline-Dokumentinhalte, dargestellt als Bytestream. Bei JSON-Darstellungen die Base64-Codierung (ASCII-String) Ihrer Binärbilddaten. Dieser String sollte in etwa so aussehen:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: Gibt an, welche Felder in die
Document-Ausgabe eingeschlossen werden sollen. Dies ist eine durch Kommas getrennte Liste vollständig qualifizierter Feldnamen imFieldMask-Format.- Beispiel:
text,entities,pages.pageNumber
- Beispiel:
- OCR-Konfigurationen
- ENABLE_NATIVE_PDF_PARSING: (Boolescher Wert) Gibt an, ob eingebetteter Text aus PDFs extrahiert werden soll, sofern verfügbar.
- ENABLE_IMAGE_QUALITY_SCORES: (Boolescher Wert) Aktiviert intelligente Bewertungen der Dokumentqualität.
- ENABLE_SYMBOL: (Boolescher Wert) Enthält OCR-Informationen zu Symbolen (Buchstaben).
- DISABLE_CHARACTER_BOXES_DETECTION: (Boolescher Wert) Deaktiviert die Erkennung von Textfeldern in der OCR-Engine.
- LANGUAGE_HINTS: Liste der BCP-47-Sprachcodes, die für die OCR verwendet werden sollen.
- ADVANCED_OCR_OPTIONS: Eine Liste erweiterter OCR-Optionen, mit denen sich das OCR-Verhalten weiter optimieren lässt. Derzeit sind folgende Werte zulässig:
legacy_layout: Ein heuristischer Algorithmus zur Layouterkennung, der als Alternative zum aktuellen ML-basierten Algorithmus zur Layouterkennung dient.
- Premium-OCR-Add-ons
- ENABLE_SELECTION_MARK_DETECTION: (Boolescher Wert) Aktivieren Sie die Erkennung von Auswahlmarkierungen in der OCR-Engine.
- COMPUTE_STYLE_INFO (boolescher Wert) Aktivieren Sie das Modell zur Schriftarterkennung, um Informationen zur Schriftart zurückzugeben.
- ENABLE_MATH_OCR: (boolescher Wert) Aktivieren Sie das Modell, das mathematische Formeln aus LaTeX extrahieren kann.
- INDIVIDUAL_PAGES: Eine Liste der einzelnen Seiten, die verarbeitet werden sollen.
† Dieser Inhalt kann auch im Objekt inlineDocument mit Base64-codierten Inhalten angegeben werden.
HTTP-Methode und URL:
POST https://LOCATION -documentai.googleapis.com/v1/projects/PROJECT_ID /locations/LOCATION /processors/PROCESSOR_ID /processorVersions/PROCESSOR_VERSION :process
JSON-Text der Anfrage:
{
"skipHumanReview": skipHumanReview ,
"rawDocument": {
"mimeType": "MIME_TYPE ",
"content": "IMAGE_CONTENT "
},
"fieldMask": "FIELD_MASK ",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING ,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES ,
"enableSymbol": ENABLE_SYMBOL ,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION ,
"hints": {
"languageHints": [
"LANGUAGE_HINTS "
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS "],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION ,
"computeStyleInfo": COMPUTE_STYLE_INFO ,
"enableMathOcr": ENABLE_MATH_OCR ,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES ]
}
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION -documentai.googleapis.com/v1/projects/PROJECT_ID /locations/LOCATION /processors/PROCESSOR_ID /processorVersions/PROCESSOR_VERSION :process"
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION -documentai.googleapis.com/v1/projects/PROJECT_ID /locations/LOCATION /processors/PROCESSOR_ID /processorVersions/PROCESSOR_VERSION :process" | Select-Object -Expand Content
Wenn die Anfrage erfolgreich ist, gibt der Server den HTTP-Statuscode 200 OK und die Antwort im JSON-Format zurück. Der Antworttext enthält eine Instanz von Document.
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Nächste Schritte
- Sehen Sie sich die Liste der Prozessoren an.
- Mit dem Layout-Parser können Sie Dokumente in lesbare Blöcke unterteilen.
- Erstellen Sie einen benutzerdefinierten Klassifikator.