本頁說明如何排解啟動後無法存取設備的問題。你可能會遇到下列問題:
- 嘗試使用 kubectl 查詢時,出現
Unable to connect to the server: dial tcp 198.18.0.64:443: i/o timeout等錯誤訊息。 - 嘗試存取 UI 時發生
Webpage not available錯誤。 - 設備上部署的應用程式無法運作,或無法部署任何新應用程式。
排解無法存取使用者介面的問題
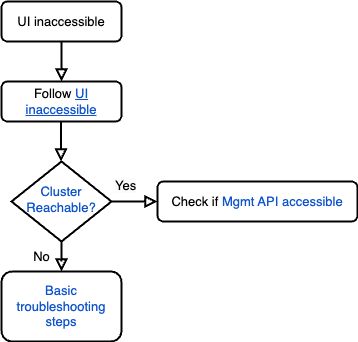
- 請按照「無法存取使用者介面」執行手冊排解問題。
- 按照「叢集可連線性」一節的說明,檢查叢集是否可連線。
- 如果叢集有回應,請按照「管理 API 可存取」一節的說明,確認管理 API 是否可存取。
- 如果叢集無法連線並傳回
Connection timed out或i/o timeout error等錯誤,請參閱疑難排解指南,瞭解後續的疑難排解步驟。
基本疑難排解步驟

檢查兩個電源供應器上的指示燈 (綠色) 是否亮起,如圖片中的箭頭所示,確認機殼的電源供應器是否正常運作。
LED 燈狀態 說明 恆亮綠燈 系統開啟並正常運作 閃爍綠燈 有待機電源 (電源供應器關閉) 恆亮琥珀色燈 電源供應器故障 (過電壓/低電壓、過熱、過電流、短路)、風扇故障或輸入過電壓保護 閃爍琥珀色 電源供應器錯誤 關閉 沒有電源或待機電源故障 (電壓過高/ 過低、過熱、過電流、短路、風扇鎖定) 如果指示燈未亮起,請先確認電源線已通電。如果電源線正常運作,則電源供應器可能故障,需要更換。如需更換說明,請參閱電源供應器更換指南。
如果電源供應器運作正常,但裝置仍無法運作,請檢查是否有鬆脫或損壞的連接線。
確認交換器和伺服器的 LED 燈號是否如圖片箭頭所示亮起。
如果交換器的 Link LED 燈恆亮綠燈,請按照「確認交換器運作正常」一節的說明,確認交換器運作正常。
如果交換器健康狀態和設定正確無誤,請按照「登入 iLO 的步驟」一節所述步驟登入 iLO,檢查裝置健康狀態。
- 如有任何風扇故障,請與 HPE 支援團隊聯絡,更換故障風扇,並按照《風扇更換指南》更換風扇。
- 如果刀片已關機,請前往「刀片」部分,選取刀片並按下電源按鈕,即可開啟刀片。
- 如果刀鋒伺服器處於嚴重狀態,請前往「刀鋒伺服器」部分,選取嚴重刀鋒伺服器,前往「電源」部分,然後啟動「強制系統重設」。
- 如果機殼健康狀態為嚴重,您也可以前往「Power and Thermal」(電源和散熱) 分頁,嘗試重設機殼。選取「管理電源」部分,然後按一下「重設 EL8000CM 按鈕」。這項程序會重設機箱管理員韌體,可能需要幾分鐘才能完成,期間機箱無法使用。
- 如果問題仍未解決,請前往「資訊」分頁,選取「記錄」,從下拉式選單中選擇「健康記錄」,然後下載為 CSV 檔案。向 Google 提交支援票證並附上記錄,要求更換硬體。
如果刀鋒伺服器上的電源 LED 亮起,請從連線至設備的電腦,對下列刀鋒伺服器 IP 位址執行 Ping 測試:
ping 198.18.0.7 //BM01 ping 198.18.0.8 //BM02 ping 198.18.0.9 //BM03如果連線偵測 (ping) 測試成功,表示節點運作正常。
如果所有節點都無法通過 Ping 測試,請向 Google 支援團隊回報。
如果按照本節所有步驟操作後,問題仍未解決,請將問題提報給 Google 支援團隊,尋求進一步協助。
連接線鬆脫或損壞
確認所有連接線都已接妥,如需檢查及固定設備內連接線的指引,請參閱檢查連接線。
檢查電線是否有任何可見的損傷。如果任何電線損壞,請更換電線。
確認交換器運作正常
登入交換器的序列控制台。登入成功後,請執行下列指令來檢查交換器的健康狀態。這項指令會顯示交換器的運作時間和資源耗用量。
show version如果序列埠控制台有回應,請參閱「驗證 BGP 摘要」,驗證交換器上的 BGP 設定。
如果 Link LED 燈未亮起或序列主控台沒有回應,交換器可能發生故障。將問題提報給 Google 支援團隊,要求換貨。
確認叢集可連線
使用 IO 憑證登入 gdcloud 工作階段:
gdcloud auth login如果無法登入,請找出在設備設定期間備份的緊急憑證,並搭配指令 -: root-admin-kubeconfig 使用。
檢查叢集是否可連線:
kubectl --kubeconfig root-admin-kubeconfig get servers -A
確認 Management API 可存取
使用 IO 憑證登入 gdcloud 工作階段:
gdcloud auth login如果登入失敗,請使用管理平面憑證登入。
有時 AIS 資料庫可能會故障或設定有誤,導致登入失敗。請參閱 IAM-R0009 - AIS 資料庫。
如果無法解決登入問題,請找出在設備設定期間備份的緊急憑證,並搭配使用「root-admin-kubeconfig」指令。
擷取管理平面 kubeconfig:
kubectl --kubeconfig root-admin-kubeconfig -n management-kube-system get secret kube-admin-remote-kubeconfig -ojsonpath='{.data.value}' | base64 -d > kube-admin-remote-kubeconfig取得叢集的健康狀態:
kubectl --kubeconfig kube-admin-remote-kubeconfig get --raw='/readyz?verbose'