Auf dieser Seite wird beschrieben, wie Sie Probleme mit dem Zugriff auf die Appliance nach dem Bootstrapping beheben können. Die folgenden Probleme können auftreten:
- Fehlermeldungen wie
Unable to connect to the server: dial tcp 198.18.0.64:443: i/o timeoutbeim Versuch, eine Abfrage mit kubectl auszuführen. Webpage not available-Fehler beim Versuch, auf die Benutzeroberfläche zuzugreifen.- Bereitgestellte Anwendungen auf der Appliance funktionieren nicht oder Sie können keine neuen Anwendungen bereitstellen.
Fehlerbehebung bei Problemen mit dem Zugriff auf die Benutzeroberfläche
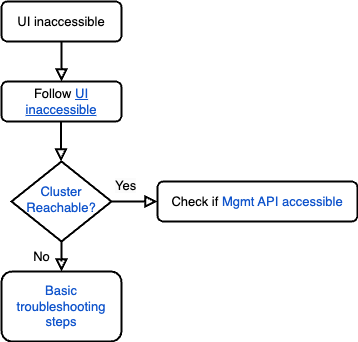
- Folgen Sie dem Runbook für den Fall, dass die Benutzeroberfläche nicht zugänglich ist, um das Problem zu beheben.
- Prüfen Sie anhand des Abschnitts Clustererreichbarkeit, ob der Cluster erreichbar ist.
- Wenn der Cluster reagiert, prüfen Sie, ob die Management API zugänglich ist. Folgen Sie dazu dem Abschnitt Management API accessible.
- Wenn der Cluster nicht erreichbar ist und Fehler wie
Connection timed outoderi/o timeout errorzurückgegeben werden, finden Sie in der Anleitung zur Fehlerbehebung weitere Schritte zur Fehlerbehebung.
Grundlegende Schritte zur Fehlerbehebung

Prüfen Sie die Stromversorgung des Gehäuses, indem Sie nachsehen, ob die Kontrollleuchten (grün) an einem der beiden Netzteile leuchten (siehe Pfeile im Bild).
LED-Status Beschreibung Durchgehend grün System eingeschaltet und normaler Betrieb Grün blinkend Standby-Strom vorhanden (Stromversorgung aus) Durchgehend gelb Netzteil ausgefallen (Überspannung/Unterspannung, Übertemperatur, Überstrom, Kurzschluss), Lüfter ausgefallen oder Überspannungsschutz am Eingang Blinkt gelb Fehler bei der Stromversorgung Aus Keine Stromversorgung oder Standby-Stromversorgung fehlgeschlagen (Überspannung/ Unterspannung, Übertemperatur, Überstrom, Kurzschluss, Lüfter blockiert) Wenn die Kontrollleuchten nicht leuchten, prüfen Sie zuerst, ob das Stromkabel mit Strom versorgt wird. Wenn das Stromkabel ordnungsgemäß funktioniert, sind die Netzteile wahrscheinlich defekt und müssen ersetzt werden. Eine Anleitung zum Austausch finden Sie im Leitfaden zum Austausch des Netzteils.
Wenn die Netzteile funktionieren, das Gerät aber immer noch nicht, prüfen Sie, ob Verbindungen locker oder beschädigt sind.
Prüfen Sie, ob die LEDs des Switches und der Server wie in der Abbildung durch die Pfeile angegeben leuchten.
Wenn die Link-LED des Switches durchgehend grün leuchtet, prüfen Sie, ob er betriebsbereit ist. Folgen Sie dazu dem Abschnitt Betriebsbereitschaft des Switches prüfen.
Wenn der Zustand und die Konfiguration des Switches korrekt sind, melden Sie sich mit den unter Schritte zum Anmelden bei iLO beschriebenen Schritten bei iLO an, um den Zustand des Geräts zu prüfen.
- Wenn einer der Lüfter kritisch ist, wenden Sie sich an das HPE-Supportteam, um einen Ersatz für den kritischen Lüfter zu erhalten, und folgen Sie der Anleitung zum Ersetzen von Lüftern, um ihn zu ersetzen.
- Wenn Klingen ausgeschaltet sind, schalten Sie sie ein, indem Sie zum Bereich „Klingen“ gehen, die Klinge auswählen und die Ein/Aus-Taste drücken.
- Wenn sich eine der Klingen in einem kritischen Zustand befindet, rufen Sie den Bereich „Klingen“ auf, wählen Sie die kritische Klinge aus, rufen Sie den Bereich „Stromversorgung“ auf und starten Sie ein erzwungenes Zurücksetzen des Systems.
- Wenn der Status des Gehäuses kritisch ist, können Sie es auch zurücksetzen, indem Sie den Tab Power and Thermal (Stromversorgung und Wärme) aufrufen. Wählen Sie den Bereich Management Power (Stromversorgung für die Verwaltung) aus und klicken Sie auf Reset EL8000CM Button (EL8000CM-Schaltfläche zurücksetzen). Dadurch wird die Firmware des Chassis-Managers zurückgesetzt. Das kann einige Minuten dauern. Während dieser Zeit ist das Chassis nicht verfügbar.
- Wenn das Problem weiterhin besteht, rufen Sie den Tab Informationen auf, wählen Sie Protokolle aus, wählen Sie im Drop-down-Menü Systemdiagnoseprotokolle aus und laden Sie sie als CSV-Datei herunter. Erstellen Sie ein Ticket bei Google und hängen Sie die Logs an, um einen Hardware-Ersatz anzufordern.
Wenn die Betriebsanzeigen auf den Blades leuchten, führen Sie von einem mit der Appliance verbundenen Computer einen Ping-Test für die folgenden Blade-IP-Adressen durch:
ping 198.18.0.7 //BM01 ping 198.18.0.8 //BM02 ping 198.18.0.9 //BM03Wenn der Ping-Test erfolgreich ist, bedeutet das, dass die Knoten betriebsbereit sind.
Wenn alle Knoten den Ping-Test nicht bestehen, eskalieren Sie das Problem an den Google-Support.
Wenn das Problem nach Ausführung aller Schritte in diesem Abschnitt weiterhin besteht, eskalieren Sie es an den Google-Support, um weitere Unterstützung zu erhalten.
Lose oder beschädigte Verbindungen
Prüfen Sie, ob alle Verbindungen sicher und richtig eingesetzt sind. Eine Anleitung zum Prüfen und Sichern von Kabelverbindungen in der Appliance finden Sie unter Kabel prüfen.
Prüfe die Kabel auf sichtbare Schäden. Wenn Kabel beschädigt sind, ersetzen Sie sie.
Schalter auf Funktionsfähigkeit prüfen
Melden Sie sich in der seriellen Konsole des Switches an. Wenn die Anmeldung erfolgreich ist, führen Sie den folgenden Befehl aus, um den Status des Switches zu prüfen. Dieser Befehl zeigt die Betriebszeit und den Ressourcenverbrauch des Switches an.
show versionWenn die serielle Konsole reagiert, prüfen Sie die BGP-Konfiguration auf dem Switch anhand von BGP-Zusammenfassung prüfen.
Wenn die Link-LED aus ist oder die serielle Konsole nicht reagiert, ist der Switch möglicherweise defekt. Eskaliere das Problem an den Google-Support, um ein Ersatzgerät zu erhalten.
Clustererreichbarkeit prüfen
Melden Sie sich mit IO-Anmeldedaten in der gcloud-Sitzung an:
gdcloud auth loginWenn Sie sich nicht anmelden können, suchen Sie die während der Gerätekonfiguration gesicherten Notfallanmeldedaten, die mit dem Befehl „-: root-admin-kubeconfig“ verwendet werden sollen.
Prüfen Sie, ob der Cluster erreichbar ist:
kubectl --kubeconfig root-admin-kubeconfig get servers -A
Verfügbarkeit der Management API prüfen
Melden Sie sich mit IO-Anmeldedaten in der gcloud-Sitzung an:
gdcloud auth loginWenn die Anmeldung fehlschlägt, melden Sie sich mit den Anmeldedaten der Verwaltungsebene an.
Die AIS-Datenbank kann manchmal nicht richtig funktionieren oder falsch konfiguriert sein, was zu einem Anmeldefehler führt. Weitere Informationen finden Sie unter IAM-R0009 – AIS-Datenbank.
Wenn Sie Probleme mit der Anmeldung nicht beheben können, suchen Sie nach den Anmeldedaten für den Notfall, die während der Einrichtung der Appliance gesichert wurden, um sie mit dem Befehl „root-admin-kubeconfig“ zu verwenden.
Rufen Sie die kubeconfig-Datei der Steuerungsebene ab:
kubectl --kubeconfig root-admin-kubeconfig -n management-kube-system get secret kube-admin-remote-kubeconfig -ojsonpath='{.data.value}' | base64 -d > kube-admin-remote-kubeconfigRufen Sie den Systemstatus des Clusters ab:
kubectl --kubeconfig kube-admin-remote-kubeconfig get --raw='/readyz?verbose'