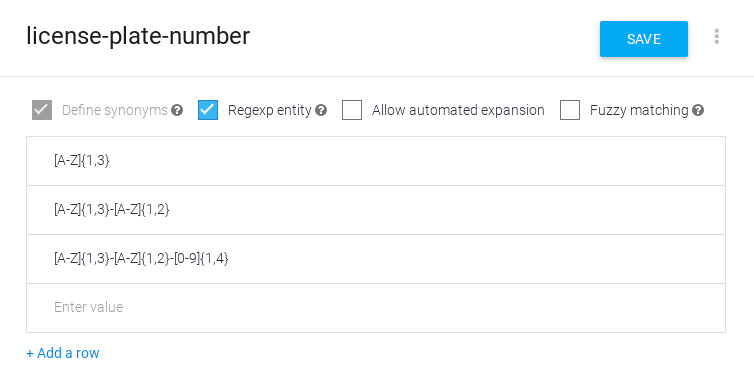
정규 표현식 순서는 중요합니다.
복합 정규 표현식의 각 정규 표현식은 순서대로 처리됩니다.
유효한 일치 항목이 발견되면 검색이 중지됩니다.
예를 들어 최종 사용자 표현이 'Seattle'인 경우에는 다음과 같이 일치합니다.
Sea|Seattle은 'Sea'와 일치합니다.
Seattle|Sea는 'Seattle'과 일치합니다.
음성 인식을 위한 특수 처리
에이전트가 음성 인식(오디오 입력, 음성 텍스트 변환, STT)을 사용하는 경우 정규 표현식에 문자와 숫자를 일치시킬 때 특별한 처리가 필요합니다.
최종 사용자의 음성 발화는 개체가 일치되기 전에 먼저 음성 인식기에 의해 처리됩니다.
발화에 일련의 문자 또는 숫자가 포함된 경우 인식기에서 각 글자 사이를 공백으로 채울 수 있습니다.
또한 인식기는 숫자를 단어 형태로 해석할 수 있습니다.
예를 들어 '내 ID는 123입니다'라는 최종 사용자의 발화는 다음과 같이 인식될 수 있습니다.
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-09-04(UTC)"],[[["\u003cp\u003eRegexp entities allow matching patterns like national IDs or license plates using regular expressions.\u003c/p\u003e\n"],["\u003cp\u003eMultiple regular expressions for a single entity are combined into a compound regular expression using the alternation operator (\u003ccode\u003e|\u003c/code\u003e).\u003c/p\u003e\n"],["\u003cp\u003eThe order of regular expressions within a compound expression matters, as matching stops after the first valid match is found.\u003c/p\u003e\n"],["\u003cp\u003eSpeech recognition requires special handling for regexp entities because the speech recognizer might add spaces between characters or interpret digits as words.\u003c/p\u003e\n"],["\u003cp\u003eThere are limitations to using regexp entities, including no fuzzy matching, a maximum of 50 regexp entities per agent, and a 2000-character limit for compound regular expressions.\u003c/p\u003e\n"]]],[],null,["# Regexp entities\n\nSome entities need to match patterns rather than specific terms.\nFor example, national identification numbers, IDs, license plates, and so on.\nWith *regexp entities* ,\nyou can provide\n[regular expressions](https://github.com/google/re2/wiki/Syntax)\nfor matching.\n\nWhere to find this data\n-----------------------\n\nWhen building an agent,\nit is most common to use the\nDialogflow ES console ([visit documentation](/dialogflow/docs/console), [open console](https://dialogflow.cloud.google.com)).\nThe instructions below focus on using the console.\nTo access entity data:\n\n1. Go to the [Dialogflow ES console](https://dialogflow.cloud.google.com).\n2. Select an agent.\n3. Select **Entities** in the left sidebar menu.\n\nIf you are building an agent using the API instead of the console, see the\n[EntityTypes reference](/dialogflow/docs/reference/common-types#entitytypes).\nThe API field names are similar to the console field names.\nThe instructions below highlight any important differences between the console and the API.\n\nCompound regular expressions\n----------------------------\n\nEach regexp entity corresponds to a single pattern,\nbut you can provide multiple regular expressions if they all represent variations of a single pattern.\nDuring agent training, all regular expressions of a single entity are combined\nwith the alternation operator (`|`) to form one *compound regular expression*.\n\nFor example, if you provide the following regular expressions for a phone number:\n\n- `^[2-9]\\d{2}-\\d{3}-\\d{4}$`\n- `^(1?(-?\\d{3})-?)?(\\d{3})(-?\\d{4})$`\n\nThe compound regular expression becomes:\n\n- `^[2-9]\\d{2}-\\d{3}-\\d{4}$|^(1?(-?\\d{3})-?)?(\\d{3})(-?\\d{4})$`\n\nThe ordering of regular expressions matters.\nEach of the regular expressions in the compound regular expression are processed in order.\nSearching stops once a valid match is found.\nFor example, for an end user expression of \"Seattle\":\n\n- `Sea|Seattle` matches \"Sea\"\n- `Seattle|Sea` matches \"Seattle\"\n\nSpecial handling for speech recognition\n---------------------------------------\n\n| **Note:** Enabling [auto speech adaptation](/dialogflow/es/docs/speech-adaptation) is recommended when using regexp entities. Also see the speech adaptation [regexp-specific guidelines](/dialogflow/es/docs/speech-adaptation#regexp-entities).\n\nIf your agent uses speech recognition\n(also known as audio input, speech-to-text, or STT),\nyour regular expressions will need special handling when matching letters and numbers.\nA spoken end-user utterance is first processed by the speech recognizer before entities are matched.\nWhen an utterance contains a series of letters or numbers,\nthe recognizer may pad each character with spaces.\nIn addition, the recognizer may interpret digits in word form.\nFor example, an end-user utterance of \"My ID is 123\"\nmay be recognized as any of the following:\n\n- \"My ID is 123\"\n- \"My ID is 1 2 3\"\n- \"My ID is one two three\"\n\nTo accommodate three digit numbers,\nyou could use the following regular expressions: \n\n```\n\\d{3}\n``` \n\n```\n\\d \\d \\d\n``` \n\n```\n(zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine)\n```\n\nCreate a regexp entity\n----------------------\n\nTo create a regexp entity:\n\n1. Open an existing entity or create a new one.\n2. Check **Regexp entity**.\n3. Enter one or more regular expressions in the entries table.\n4. Click **Save**.\n\nIf you are using the API to create or update entities,\nuse `KIND_REGEXP` for the entity kind field.\n\nLimitations\n-----------\n\nThe following limitations apply:\n\n- [Fuzzy matching](/dialogflow/docs/entities-fuzzy) cannot be enabled for regexp entities. These features are mutually exclusive.\n- Each agent can have a maximum of 50 regexp entities.\n- The [compound regular expression](#compound) for an entity has a maximum length of 2000 characters."]]