Lorsqu'un système de type "Infrastructure as Code" dépasse le cadre de l'exemple "Hello World" sans planification, le code utilisé a tendance à se déstructurer. Les configurations non planifiées sont codées en dur. Elles deviennent beaucoup plus difficiles à gérer.
Utilisez ce document pour structurer vos déploiements plus efficacement et à grande échelle.
En outre, veillez à ce que toutes vos équipes respectent votre convention de nommage et vos bonnes pratiques internes. Ce document est destiné à un public techniquement averti. Il part du principe que vous maîtrisez les concepts élémentaires de Python, de l'infrastructure Google Cloud, de Deployment Manager et, plus généralement, de l'approche "Infrastructure as Code".
Avant de commencer
- Si vous voulez vous servir des exemples de ligne de commande de ce guide, installez l'outil de ligne de commande gcloud.
- Si vous voulez utiliser les exemples d'API de ce guide, configurez l'accès aux API.
Plusieurs environnements avec un seul codebase
Pour les déploiements de grande envergure comportant plus d'une dizaine de ressources, les bonnes pratiques courantes requièrent que vous utilisiez de nombreuses propriétés externes (paramètres de configuration) afin d'éviter de coder en dur les chaînes et la logique dans des modèles génériques. La plupart de ces propriétés sont partiellement dupliquées en raison de services et d'environnements similaires (tels que les environnements de développement, de test ou de production). Par exemple, tous les services standards s'exécutent sur une pile LAMP analogue. L'application de ces bonnes pratiques engendre de nombreuses propriétés de configuration très largement dupliquées qui peuvent s'avérer difficiles à gérer, ce qui augmente les risques d'erreur humaine.
Le tableau ci-dessous présente un exemple de code illustrant les différences qui existent entre une configuration hiérarchique et une configuration unique par déploiement. Il met en évidence une duplication couramment observée dans une configuration unique. Il montre en outre comment déplacer les sections répétitives vers un niveau supérieur de la hiérarchie au moyen d'une configuration hiérarchique, afin d'éviter la redondance et de limiter les risques d'erreur humaine.
| Modèle | Configuration hiérarchique sans redondance | Configuration unique avec redondance
|
|---|---|---|
|
|
N/A |
|
|
|
|
|
|
|
|
|
Pour mieux gérer un codebase volumineux, utilisez une configuration hiérarchique structurée avec une fusion en cascade des propriétés de configuration. Pour ce faire, vous utilisez plusieurs fichiers de configuration au lieu d'un seul. Par ailleurs, vous pouvez faire appel à des fonctions d'assistance et partager une partie du codebase au sein de votre organisation.
En structurant votre code selon une hiérarchie en cascade, vous bénéficiez de plusieurs avantages :
- Lorsque vous divisez la configuration en plusieurs fichiers, vous améliorez la structure et la lisibilité des propriétés. Vous évitez également de les dupliquer.
- Vous concevez la fusion hiérarchique de façon à disposer en cascade les valeurs de manière logique, créant ainsi des fichiers de configuration de premier niveau réutilisables par différents projets ou composants.
- Vous ne définissez chaque propriété qu'une seule fois (sauf en cas d'écrasement), ce qui évite de gérer des espaces de noms pour les propriétés.
- Vos modèles n'ont pas besoin de connaître l'environnement réel, car la configuration requise est chargée en fonction des variables appropriées.
Structurer votre codebase de manière hiérarchique
Un déploiement Deployment Manager contient une configuration YAML ou un fichier de schéma, ainsi que plusieurs fichiers Python. Tous ces fichiers constituent le codebase du déploiement. Les fichiers Python peuvent avoir divers usages. Vous pouvez les utiliser en tant que modèles de déploiement, en tant que fichiers de code générique (classes d'assistance) ou en tant que fichiers de code contenant les propriétés de configuration.
Pour structurer votre codebase de manière hiérarchique, vous devez utiliser certains fichiers Python en tant que fichiers de configuration à la place du fichier de configuration standard. En adoptant cette approche, vous bénéficiez d'une plus grande flexibilité que si vous associez le déploiement à un seul fichier YAML.
Traiter votre infrastructure comme du vrai code
Il est important de suivre le principe Don't Repeat Yourself (DRY) (Ne vous répétez pas) pour obtenir du code "propre". Chaque élément ne doit être défini qu'une seule fois. Cette approche améliore la qualité du codebase, qui est plus facile à examiner, à valider et à gérer. Si une propriété doit être modifiée à un seul endroit, le risque d'erreur humaine diminue.
Pour alléger le codebase en réduisant la taille des fichiers de configuration et en limitant le plus possible la duplication, suivez ces consignes qui permettent de structurer vos configurations selon le principe DRY.
Organisations, services, environnements et modules
Les principes de base à respecter pour structurer correctement et de façon hiérarchique votre codebase consistent à utiliser différents niveaux : organisations, services, environnements et modules. Ces principes sont facultatifs et peuvent être étendus. Pour obtenir un schéma de la hiérarchie de l'exemple de codebase qui suit ces principes, consultez la section Hiérarchie de configuration.
Dans le schéma ci-dessous, un module est déployé dans un environnement. L'outil de fusion des configurations sélectionne les fichiers de configuration appropriés à chaque niveau en fonction du contexte d'utilisation. Par ailleurs, il définit automatiquement le système et le service.
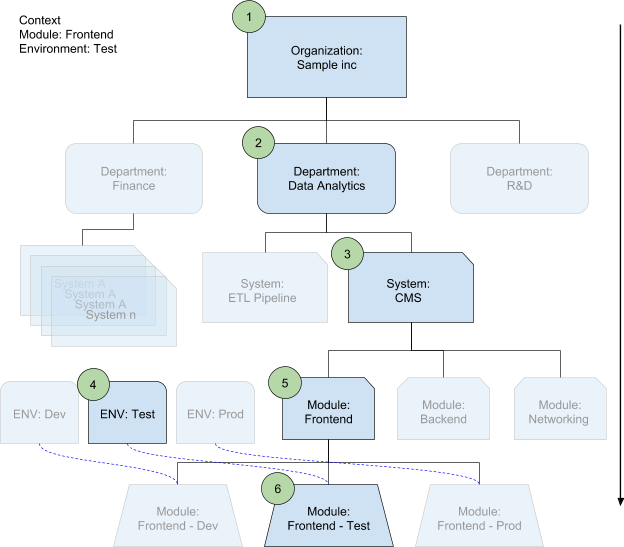
Dans la liste ci-dessous, les numéros représentent l'ordre d'écrasement.
Propriétés de l'organisation
Il s'agit du plus haut niveau de votre structure. Vous pouvez y stocker des propriétés de configuration, telles que
organization_nameouorganization_abbreviation, que vous utilisez dans votre convention de nommage, ainsi que des fonctions d'assistance que vous souhaitez partager avec toutes les équipes afin qu'elles les appliquent.Propriétés des services
Si votre structure inclut des services, votre organisation en comporte également. Dans le fichier de configuration de chaque service, partagez les propriétés qui ne sont pas utilisées par d'autres services, par exemple,
department_nameoucost_center.Propriétés des systèmes (projets)
Chaque service inclut des systèmes. Un système correspond à une pile logicielle bien définie, telle que votre plate-forme d'e-commerce. Il ne s'agit pas d'un projetGoogle Cloud , mais d'un écosystème de services fonctionnel.
Au niveau des systèmes, votre équipe dispose de beaucoup plus d'autonomie qu'aux niveaux supérieurs. Ici, vous pouvez définir des fonctions auxiliaires (telles que
project_name_generator(),instance_name_generator()ouinstance_label_generator()) pour les paramètres au niveau de l'équipe et du système (par exemplesystem_name,default_instance_sizeounaming_prefix).Propriétés des environnements
Votre système peut comporter plusieurs environnements, tels que
Dev,TestouProd, et éventuellementQAetStaging, qui sont relativement similaires. Idéalement, ils utilisent le même codebase et ne diffèrent qu'au niveau de leur configuration. Au niveau des environnements, vous pouvez écraser des propriétés telles quedefault_instance_sizepour les configurationsProdetQA.Propriétés des modules
Si vous disposez d'un système volumineux, divisez-le en plusieurs modules au lieu de conserver un grand bloc monolithique. Vous pouvez, par exemple, transférer les principaux dispositifs de mise en réseau et de sécurité dans des blocs indépendants. Vous avez également la possibilité de séparer les couches de backend, de frontend et de base de données dans des modules distincts. Les modules correspondent à des modèles qui ont été développés par des tiers et dans lesquels vous vous contentez d'ajouter la configuration appropriée. Au niveau des modules, vous pouvez définir des propriétés qui ne concernent que certains modules, y compris celles conçues pour écraser les propriétés héritées du système. Les environnements et les modules sont des divisions parallèles d'un système. Toutefois, les modules viennent après les environnements dans le processus de fusion.
Propriétés des modules propres à l'environnement
Certaines de vos propriétés de modules (telles que les tailles d'instance, les images ou les points de terminaison) peuvent également dépendre de l'environnement. Les propriétés des modules propres à l'environnement représentent le niveau le plus spécifique et la dernière étape du processus de fusion en cascade qui permet d'écraser les valeurs précédemment définies.
Classe d'assistance pour la fusion des configurations
config_merger est une classe d'assistance qui charge automatiquement les fichiers de configuration appropriés et fusionne leur contenu dans un dictionnaire unique.
Pour utiliser la classe config_merger, vous devez fournir les informations suivantes :
- Le nom du module
- Le contexte global, qui contient le nom de l'environnement
L'appel de la fonction statique ConfigContext renvoie le dictionnaire de configuration fusionné.
Le code ci-dessous montre comment utiliser cette classe.
module = "frontend"spécifie le contexte dans lequel les fichiers de propriétés sont chargés.- L'environnement est automatiquement sélectionné dans
context.properties["envName"]. La configuration globale s'affiche.
cc = config_merger.ConfigContext(context.properties, module) print cc.configs['ServiceName']
En arrière-plan, cette classe d'assistance doit s'adapter à vos structures de configuration, charger tous les niveaux dans l'ordre requis et écraser les valeurs de configuration appropriées. Pour changer les niveaux ou l'ordre d'écrasement, vous devez modifier la classe de fusion des configurations.
Dans le cadre d'une utilisation quotidienne et régulière, il n'est normalement pas nécessaire de modifier cette classe. Vous pouvez généralement modifier les modèles et les fichiers de configuration appropriés, puis utiliser le dictionnaire de sortie contenant toutes les configurations.
L'exemple de codebase contient les trois fichiers de configuration suivants qui sont codés en dur :
org_config.pydepartment_config.pysystem_config.py
Vous pouvez créer les fichiers de configuration de l'organisation et des services sous forme de liens symboliques lors du lancement du dépôt. Ces fichiers peuvent résider dans un dépôt de code distinct, car ils ne font pas logiquement partie du codebase d'une équipe de projet, mais sont partagés par l'ensemble de l'organisation et des services.
L'outil de fusion des configurations recherche également les fichiers correspondant aux autres niveaux de votre structure :
envs/[environment name].py[environment name]/[module name].pymodules/[module name].py
Fichier de configuration
Deployment Manager utilise un fichier de configuration unique pour un déploiement spécifique. Ce fichier ne peut pas être partagé entre plusieurs déploiements.
Lorsque vous utilisez la classe config-merger, les propriétés de configuration sont complètement dissociées de ce fichier, car vous ne vous en servez pas.
Vous utilisez à la place une collection de fichiers Python, ce qui rend le processus de déploiement beaucoup plus flexible. Ces fichiers peuvent par ailleurs être partagés entre plusieurs déploiements.
Tout fichier Python peut contenir des variables, ce qui vous permet de stocker votre configuration de manière structurée et distribuée. La meilleure approche consiste à utiliser des dictionnaires organisés selon la structure choisie. L'outil de fusion des configurations recherche un dictionnaire appelé configs dans chaque fichier de la chaîne de fusion. Ces éléments configs distincts sont fusionnés en une seule configuration.
Au cours de la fusion, lorsqu'une propriété ayant le même chemin d'accès et le même nom apparaît plusieurs fois dans les dictionnaires, l'outil de fusion des configurations l'écrase. Ce comportement s'avère parfois utile, comme dans le cas où une valeur par défaut est écrasée par une valeur propre au contexte. Toutefois, dans de nombreux autres cas, vous souhaiterez empêcher que cette propriété soit écrasée. Pour cela, vous pouvez lui ajouter un espace de noms distinct afin de la rendre unique. Dans l'exemple ci-dessous, on ajoute un espace de noms en créant un niveau supplémentaire dans le dictionnaire de configuration, ce qui génère un sous-dictionnaire.
config = {
'Zip_code': '1234'
'Count': '3'
'project_module': {
'admin': 'Joe',
}
}
config = {
'Zip_code': '5555'
'Count': '5'
'project_module_prod': {
'admin': 'Steve',
}
}
Classes d'assistance et conventions de nommage
Les conventions d'attribution de noms représentent le meilleur moyen de garder sous contrôle votre infrastructure Deployment Manager. Nous vous recommandons de ne pas utiliser de noms vagues ou génériques, tels que my project ou test instance.
L'exemple ci-dessous illustre une convention de nommage appliquée à l'échelle de l'organisation pour les instances :
def getInstanceName(self, name):
return '-'.join(self.configs['Org_level_configs']['Org_Short_Name'],
self.configs['Department_level_configs']['Department_Short_Name'],
self.configs['System_short_name'],
name,
self.configs["envName"])
L'utilisation d'une fonction d'assistance facilite le nommage de chaque instance selon la convention choisie. Étant donné que les noms d'instances sont nécessairement issus de cette fonction, celle-ci permet également de vérifier plus aisément le code. La fonction récupère automatiquement les noms à partir des configurations de niveau supérieur. Cette approche permet d'éviter les entrées inutiles.
Vous pouvez appliquer ces conventions de dénomination à la plupart des ressources Google Cloud et aux libellés. Des fonctions plus complexes peuvent même générer un ensemble de libellés par défaut.
Structure des dossiers de l'exemple de codebase
La structure des dossiers de l'exemple de codebase est flexible et personnalisable. Toutefois, elle est partiellement codée en dur dans l'outil de fusion des configurations et dans le fichier de schéma Deployment Manager. Ainsi, si vous apportez une modification, vous devez la répercuter dans cet outil et dans ces fichiers.
├── global
│ ├── configs
│ └── helper
└── systems
└── my_ecom_system
├── configs
│ ├── dev
│ ├── envs
│ ├── modules
│ ├── prod
│ └── test
├── helper
└── templates
Le dossier global contient des fichiers partagés par différentes équipes de projet. Pour plus de simplicité, le dossier de configuration inclut la configuration de l'organisation et les fichiers de configuration de tous les services. Dans cet exemple, il n'existe pas de classe d'assistance distincte pour les services. Vous pouvez ajouter n'importe quelle classe d'assistance au niveau de l'organisation ou du système.
Le dossier global peut résider dans un dépôt Git distinct. Vous pouvez référencer ses fichiers à partir des différents systèmes. Vous avez également la possibilité d'utiliser des liens symboliques. Toutefois, ils peuvent être source de confusion ou provoquer des interruptions dans certains systèmes d'exploitation.
├── configs
│ ├── Department_Data_config.py
│ ├── Department_Finance_config.py
│ ├── Department_RandD_config.py
│ └── org_config.py
└── helper
├── config_merger.py
└── naming_helper.py
Le dossier des systèmes contient un ou plusieurs systèmes distincts. Les systèmes sont séparés et ne partagent pas les configurations.
├── configs │ ├── dev │ ├── envs │ ├── modules │ ├── prod │ └── test ├── helper └── templates
Le dossier de configuration contient tous les fichiers de configuration propres à ce système et référence les configurations globales par le biais de liens symboliques.
├── department_config.py -> ../../../global/configs/Department_Data_config.py
├── org_config.py -> ../../../global/configs/org_config.py
├── system_config.py
├── dev
│ ├── frontend.py
│ └── project.py
├── prod
│ ├── frontend.py
│ └── project.py
├── test
│ ├── frontend.py
│ └── project.py
├── envs
│ ├── dev.py
│ ├── prod.py
│ └── test.py
└── modules
├── frontend.py
└── project.py
Org_config.py:
config = {
'Org_level_configs': {
'Org_Name': 'Sample Inc.',
'Org_Short_Name': 'sampl',
'HQ_Address': {
'City': 'London',
'Country': 'UK'
}
}
}
Dans le dossier d'assistance, vous pouvez ajouter d'autres classes d'assistance et référencer les classes globales.
├── config_merger.py -> ../../../global/helper/config_merger.py └── naming_helper.py -> ../../../global/helper/naming_helper.py
Dans le dossier contenant les modèles, vous pouvez stocker ou référencer les modèles Deployment Manager. Les liens symboliques peuvent également être utilisés pour ce dossier.
├── project_creation -> ../../../../../../examples/v2/project_creation └── simple_frontend.py
Bonnes pratiques
Suivez ces bonnes pratiques pour structurer votre code de manière hiérarchique.
Fichiers de schéma
Deployment Manager requiert que chaque fichier utilisé pendant le déploiement soit répertorié dans le fichier de schéma. L'ajout d'un dossier complet permet de raccourcir le code et de le rendre plus générique.
- Classes d'assistance :
- path: helper/*.py
- Fichiers de configuration :
- path: configs/*.py - path: configs/*/*.py
- Importations groupées (style glob)
gcloud config set deployment_manager/glob_imports True
Déploiements multiples
Il est préférable qu'un système contienne plusieurs déploiements, ce qui signifie qu'ils utilisent les mêmes ensembles de configurations, même s'ils correspondent à des modules différents (par exemple, mise en réseau, pare-feu, backend et frontend). Vous devrez peut-être accéder au résultat de ces déploiements à partir d'un autre déploiement. Vous pouvez consulter le résultat du déploiement lorsqu'il est prêt et l'enregistrer dans le dossier de configuration. Il est possible d'ajouter ces fichiers de configuration lors du processus de fusion.
Liens symboliques
Les liens symboliques sont acceptés par les commandes gcloud deployment-manager. Par ailleurs, les fichiers associés sont correctement chargés. Toutefois, les liens symboliques ne sont pas acceptés par tous les systèmes d'exploitation.
Hiérarchie de configuration
Le schéma ci-dessous présente les différents niveaux et leurs relations. Chaque rectangle correspond à un fichier de propriétés, comme l'indique le nom de fichier affiché en rouge.
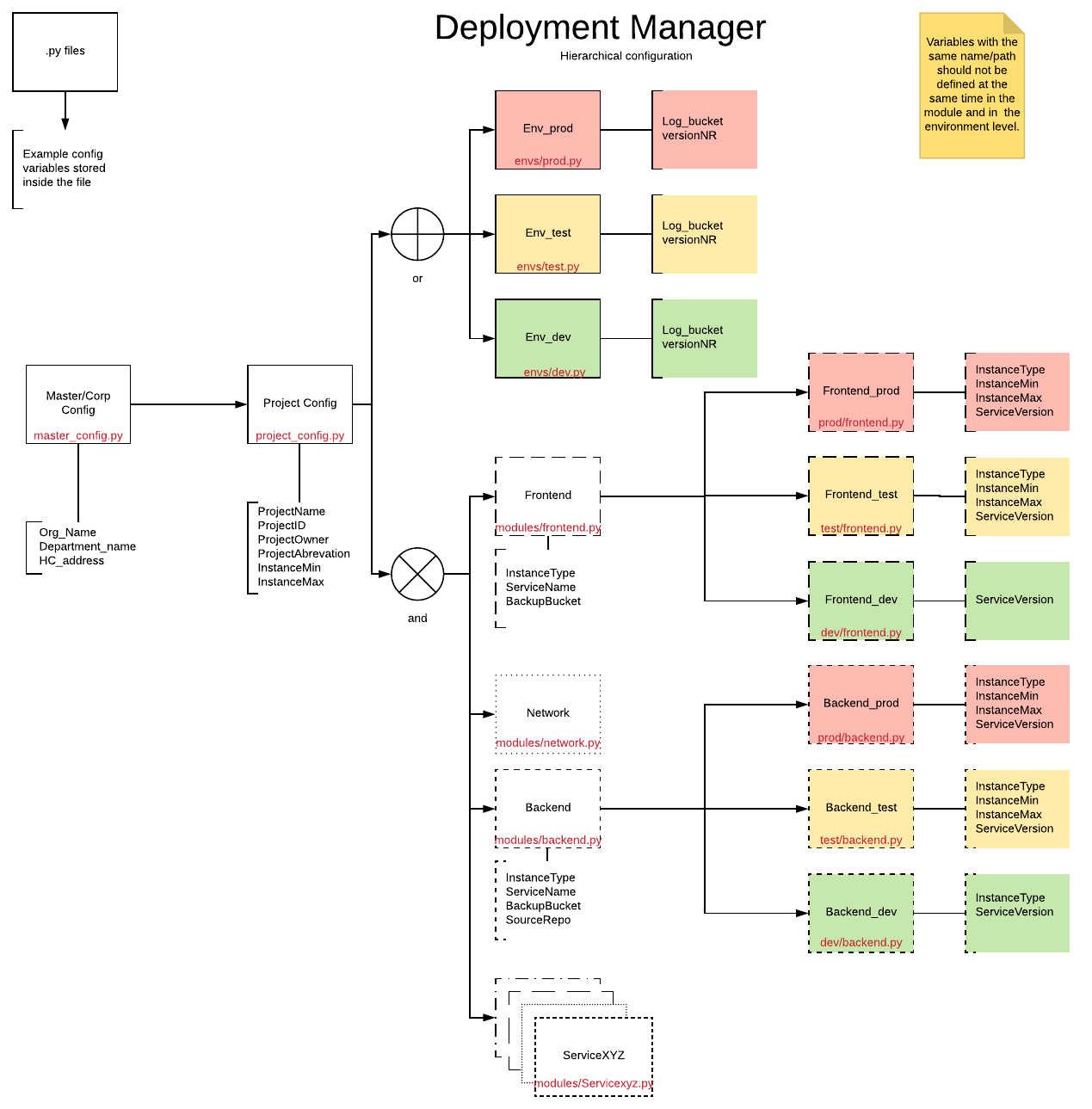
Ordre de fusion contextuel
L'outil de fusion des configurations sélectionne les fichiers de configuration appropriés à chaque niveau en fonction du contexte dans lequel chaque fichier est utilisé. Le contexte correspond à un module que vous déployez dans un environnement. Il définit automatiquement le système et le service.
Dans le schéma ci-dessous, les numéros représentent l'ordre d'écrasement dans la hiérarchie :
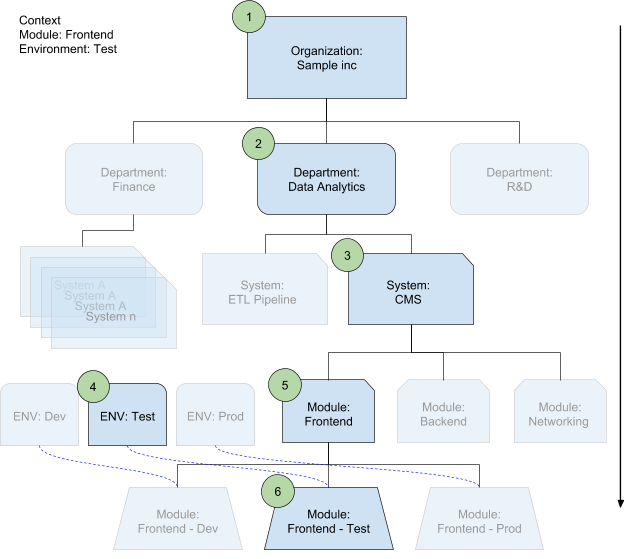
Étape suivante
- Consultez d'autres exemples de déploiements dans le dépôt GitHub de Deployment Manager.
- En savoir plus sur les modèles et les déploiements