您可以使用 VPC 网络对等互连,让 Datastream 以非公开方式与虚拟私有云 (VPC) 网络中的资源通信。
VPC 网络对等互连是您的 VPC 网络与 Datastream 专用网络之间的连接,使 Datastream 能够使用内部 IP 地址与内部资源进行通信。使用专用连接会在 Datastream 网络上建立专用连接,这意味着其他客户无法共享此连接。
您的 VPC 网络与 Datastream VPC 网络之间的 VPC 网络对等互连连接可让 Datastream 连接到:
- VPC 网络中的虚拟机 (VM) 和内部负载平衡器等资源。
- 使用 Cloud VPN 隧道、专用互连 VLAN 连接、合作伙伴互连 VLAN 连接和 Network Connectivity Center Cloud Router 连接到您的 VPC 网络的其他网络中的资源。
您的 VPC 网络与 Datastream VPC 网络之间的 VPC 网络对等互连连接不允许 Datastream 连接到以下资源:
- 位于您的 VPC 网络中的 Private Service Connect 端点。
- 位于另一个与您的 VPC 网络对等互连但未与 Datastream VPC 网络对等互连的 VPC 网络中的资源。(这是因为 VPC 网络对等互连不提供传递性路由。)
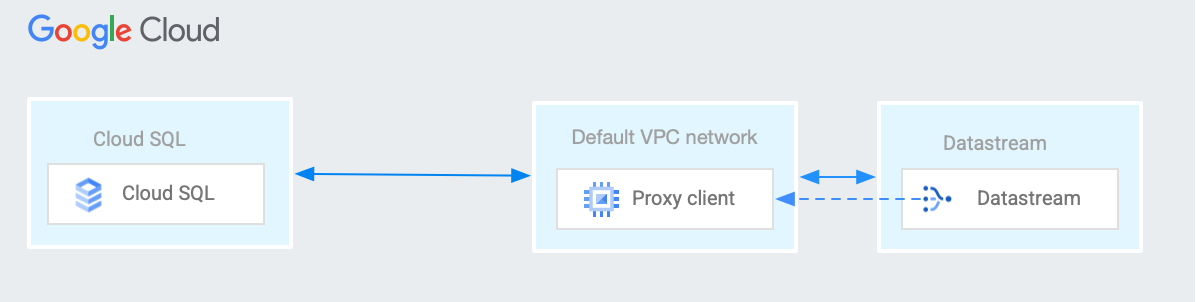
如需在 Datastream 与只能从 VPC 网络访问的资源之间建立连接,您可以在 VPC 网络中使用网络地址转换 (NAT) 虚拟机。NAT 虚拟机的常见用例是 Datastream 需要连接到 Cloud SQL 实例时。
本页介绍了一个 NAT 虚拟机配置示例,该配置可让 Datastream 私密地连接到 Cloud SQL 实例。
VPC 对等互连前提条件
在创建专用连接配置之前,您需要先按以下步骤操作,以便 Datastream 能够与您的项目建立 VPC 对等互连连接:
- 拥有一个可与 Datastream 的专用网络建立对等互连的 VPC 网络,并且该网络符合 VPC 网络对等互连页面中所述的要求。如需详细了解如何创建此网络,请参阅使用 VPC 网络对等互连。
- 确定 VPC 网络上可用的 IP 范围(CIDR 地址块为 /29)。此 IP 范围不能是已作为子网存在的 IP 范围、专用服务访问通道预先分配的 IP 范围,也不能是包含该 IP 范围的任何路由(默认 0.0.0.0 路由除外)。Datastream 使用此 IP 地址范围创建子网,以便它可以与来源数据库通信。下表介绍了有效的 IP 范围。
| 范围 | 说明 |
|---|---|
10.0.0.0/8172.16.0.0/12192.168.0.0/16
|
专用 IP 地址 RFC 1918 |
100.64.0.0/10 |
共享地址空间 RFC 6598 |
192.0.0.0/24 |
IETF 协议分配 RFC 6890 |
192.0.2.0/24 (TEST-NET-1)198.51.100.0/24 (TEST-NET-2)203.0.113.0/24 (TEST-NET-3) |
文档 RFC 5737 |
192.88.99.0/24 |
IPv6 到 IPv4 中继(已弃用)RFC 7526 |
198.18.0.0/15 |
基准测试 RFC 2544 |
验证 Google Cloud 和本地防火墙是否允许来自所选 IP 范围的流量。如果不是,请创建入站防火墙规则,以允许来源数据库端口上的流量,并确保防火墙规则中的 IPv4 地址范围与创建专用连接资源时分配的 IP 地址范围相同:
gcloud compute firewall-rules create FIREWALL-RULE-NAME \ --direction=INGRESS \ --priority=PRIORITY \ --network=PRIVATE_CONNECTIVITY_VPC \ --project=VPC_PROJECT \ --action=ALLOW \ --rules=FIREWALL_RULES \ --source-ranges=IP-RANGE
替换以下内容:
- FIREWALL-RULE-NAME:要创建的防火墙规则的名称。
- PRIORITY:规则的优先级,以介于 0 到 65535 之间的整数(含 0 和 65535)表示。该值需要低于为“禁止流量”规则设置的值(如果存在)。优先级值越低,优先级越高。
- PRIVATE_CONNECTIVITY_VPC:可以与 Datastream 专用网络建立对等互连,并且满足 VPC 网络对等互连页面中所述要求的 VPC 网络。这是您在创建专用连接配置时指定的 VPC。
- VPC_PROJECT:VPC 网络的项目。
- FIREWALL_RULES:防火墙规则适用的协议和端口的列表,例如
tcp:80。该规则需要允许 TCP 流量流向源数据库或代理的 IP 地址和端口。由于专用连接可以支持多个数据库,因此规则需要考虑配置的实际使用情况。 IP-RANGE:Datastream 用于与源数据库通信的 IP 地址范围。此范围与您在创建专用连接配置时在分配 IP 范围字段中指定的范围相同。
您可能还需要创建相同的出站防火墙规则,以允许流量返回到 Datastream。
分配给包含
compute.networks.list权限的角色。此权限可让您获得在项目中列出 VPC 网络所需的 IAM 权限。您可以查看 IAM 权限参考文档,了解哪些角色包含此权限。
共享 VPC 前提条件
如果您使用的是共享 VPC,则除了VPC 前提条件部分中所述的步骤之外,还必须完成以下操作:
在服务项目上:
- 启用 Datastream API。
获取用于 Datastream 服务账号的电子邮件地址。当您执行以下操作之一时,系统会创建 Datastream 服务账号:
- 您创建 Datastream 资源,例如连接配置文件或数据流。
- 您需要创建专用连接配置,选择共享 VPC,然后点击创建 Datastream 服务账号。服务账号是在宿主项目中创建的。
如需获取 Datastream 服务账号所用的电子邮件地址,请在 Google Cloud 控制台首页中找到相应的项目编号。服务账号的电子邮件地址为
service-[project_number]@gcp-sa-datastream.iam.gserviceaccount.com。
在宿主项目上:
向 Datastream 服务账号授予
compute.networkAdminIdentity and Access Management (IAM) 角色的权限。只有在创建 VPC 对等互连时,才需要此角色。对等互连建立后,您不再需要该角色。如果贵组织不允许授予该权限,请创建具有以下最低权限的自定义角色,以创建和删除专用连接资源:
如需详细了解自定义角色,请参阅创建和管理自定义角色。
设置 NAT 虚拟机
确定 Datastream 需要连接到的 Cloud SQL 实例的 IP 地址。
确定您的 VPC 网络。这是使用 VPC 网络对等互连连接到 Datastream VPC 网络的 VPC 网络。
如果您尚未在 Datastream 中创建专用连接配置,请立即创建。这会创建 VPC 网络对等互连连接,用于连接您的 VPC 网络和 Datastream VPC 网络。记下 Datastream 专用连接配置使用的 IP 地址范围。
选择要在下一步中创建的 NAT 虚拟机的机器类型。Google Cloud 会根据虚拟机实例的机器类型,对 VPC 网络内下一个跃点路由的数据包强制执行每个实例的最大出站带宽限制。如需了解详情,请参阅出站流量到 VPC 网络中可路由到的目的地和每实例最大出站带宽。
在 VPC 网络中创建 NAT 虚拟机。如果您的 VPC 网络是共享 VPC 网络,则可以在宿主项目或任何服务项目中创建 NAT 虚拟机,前提是 NAT 虚拟机的网络接口位于共享 VPC 网络中。
- 为了尽可能缩短网络往返时间,请在与 Datastream 相同的区域中创建 NAT 虚拟机。
- 此示例假设 NAT 虚拟机只有一个网络接口。
- 在 Linux 发行版(例如 Debian 12)中运行脚本。
- 使用以下启动脚本。每次虚拟机启动时,启动脚本都会由 root 执行。此脚本包含注释,用于说明脚本中每一行的作用。在脚本中,将 CLOUD_SQL_INSTANCE_IP 替换为 Cloud SQL 实例的 IP 地址,并将 DATABASE_PORT 替换为数据库软件使用的目标端口。
#! /bin/bash export DB_ADDR=CLOUD_SQL_INSTANCE_IP export DB_PORT=DATABASE_PORT # Enable the VM to receive packets whose destinations do # not match any running process local to the VM echo 1 > /proc/sys/net/ipv4/ip_forward # Ask the Metadata server for the IP address of the VM nic0 # network interface: md_url_prefix="http://169.254.169.254/computeMetadata/v1/instance" vm_nic_ip="$(curl -H "Metadata-Flavor: Google" ${md_url_prefix}/network-interfaces/0/ip)" # Clear any existing iptables NAT table entries (all chains): iptables -t nat -F # Create a NAT table entry in the prerouting chain, matching # any packets with destination database port, changing the destination # IP address of the packet to the SQL instance IP address: iptables -t nat -A PREROUTING \ -p tcp --dport $DB_PORT \ -j DNAT \ --to-destination $DB_ADDR # Create a NAT table entry in the postrouting chain, matching # any packets with destination database port, changing the source IP # address of the packet to the NAT VM's primary internal IPv4 address: iptables -t nat -A POSTROUTING \ -p tcp --dport $DB_PORT \ -j SNAT \ --to-source $vm_nic_ip # Save iptables configuration: iptables-save
创建具有以下特征的入站流量允许防火墙规则(或全球网络防火墙政策、区域级网络防火墙政策或分层防火墙政策中的规则):
- 方向:入站
- 操作:允许
- 目标参数:至少是 NAT 虚拟机
- 来源参数:Datastream 私密连接配置使用的 IP 地址范围
- 协议:TCP
- 端口:必须至少包含 DATABASE_PORT
隐式允许出站防火墙规则允许 NAT 虚拟机将数据包发送到任何目的地。如果您的 VPC 网络使用出站流量拒绝防火墙规则,您可能必须创建出站流量允许防火墙规则,以允许 NAT 虚拟机向 Cloud SQL 实例发送数据包。如果需要出口允许规则,请使用以下参数:
- 方向:出站
- 操作:允许
- 目标参数:至少是 NAT 虚拟机
- 目标参数:Cloud SQL 实例 IP 地址
- 协议:TCP
- 端口:必须至少包含 DATABASE_PORT
确保您已将 Cloud SQL 实例配置为接受来自 NAT 虚拟机的网络接口所用主要内部 IPv4 地址的连接。如需查看相关说明,请参阅 Cloud SQL 文档中的使用授权网络进行授权。
在 Datastream 中创建连接配置文件。在配置文件的连接详细信息中,指定您创建的 NAT 虚拟机的内部主 IPv4 地址。在连接配置文件的端口字段中输入源数据库的端口。
设置一对 NAT 虚拟机和一个内部直通式网络负载平衡器
为了提高 NAT 虚拟机解决方案的可靠性,请考虑以下架构,该架构使用一对 NAT 虚拟机和一个内部直通式网络负载平衡器:
在同一区域的不同可用区中创建两个 NAT 虚拟机。按照设置 NAT 虚拟机 的说明创建每个虚拟机,并将每个虚拟机放置在各自的可用区非托管实例组中。
或者,您也可以创建区域托管实例组。 在代管式实例组模板中,添加一个启动脚本,例如设置 NAT 虚拟机说明中的示例启动脚本。
创建一个内部直通式网络负载平衡器,其后端服务使用上一步中的实例组作为后端。如需查看内部直通式网络负载平衡器示例,请参阅设置具有虚拟机实例组后端的内部直通式网络负载平衡器。
配置负载均衡器健康检查时,您可以使用目标 TCP 端口与 DATABASE_PORT 匹配的 TCP 健康检查。健康检查数据包会根据 NAT 虚拟机的配置路由到 CLOUD_SQL_INSTANCE_IP。或者,您可以在 NAT 虚拟机上运行一个本地进程,该进程可响应自定义端口上的 TCP 或 HTTP 健康检查。
创建防火墙规则并配置 Cloud SQL 授权网络,如设置 NAT 虚拟机说明中所述。 确保 Cloud SQL 授权网络包含两个 NAT 虚拟机的内部主要 IPv4 地址。
创建 Datastream 连接配置文件时,请在配置文件的连接详细信息中指定内部直通式网络负载平衡器的转发规则的 IP 地址。