Datastream para BigQuery
Replicación directa desde bases de datos relacionales directamente a BigQuery, lo que permite extraer información valiosa casi en tiempo real de los datos operativos.
Replicación de baja latencia para habilitar estadísticas casi en tiempo real en BigQuery
Acceso a datos de streaming desde bases de datos MySQL, PostgreSQL, AlloyDB, SQL Server y Oracle
Plataforma sin servidor que se escala automáticamente, sin recursos para aprovisionar ni gestionar
Configuración sencilla de los flujos de procesamiento de extracción, carga y transformación (ELT) con conectividad segura integrada
Miles de clientes lo usan para replicar sus datos operativos en BigQuery

Ventajas
Replica los datos operativos con una latencia mínima
Replica fácilmente datos de bases de datos de MySQL, PostgreSQL, AlloyDB y Oracle directamente en BigQuery, con baja latencia y sin que afecte al rendimiento de la fuente.
Escala o reduce verticalmente con una arquitectura sin servidor
Elimina la sobrecarga operativa gracias a una estrategia sin servidor que se escala automáticamente y sin infraestructura que puedas gestionar.
En cuestión de minutos
Una experiencia de configuración simplificada te permite empezar a replicar datos de tus bases de datos operativas en BigQuery en solo unos pocos pasos.
Características principales
Características principales
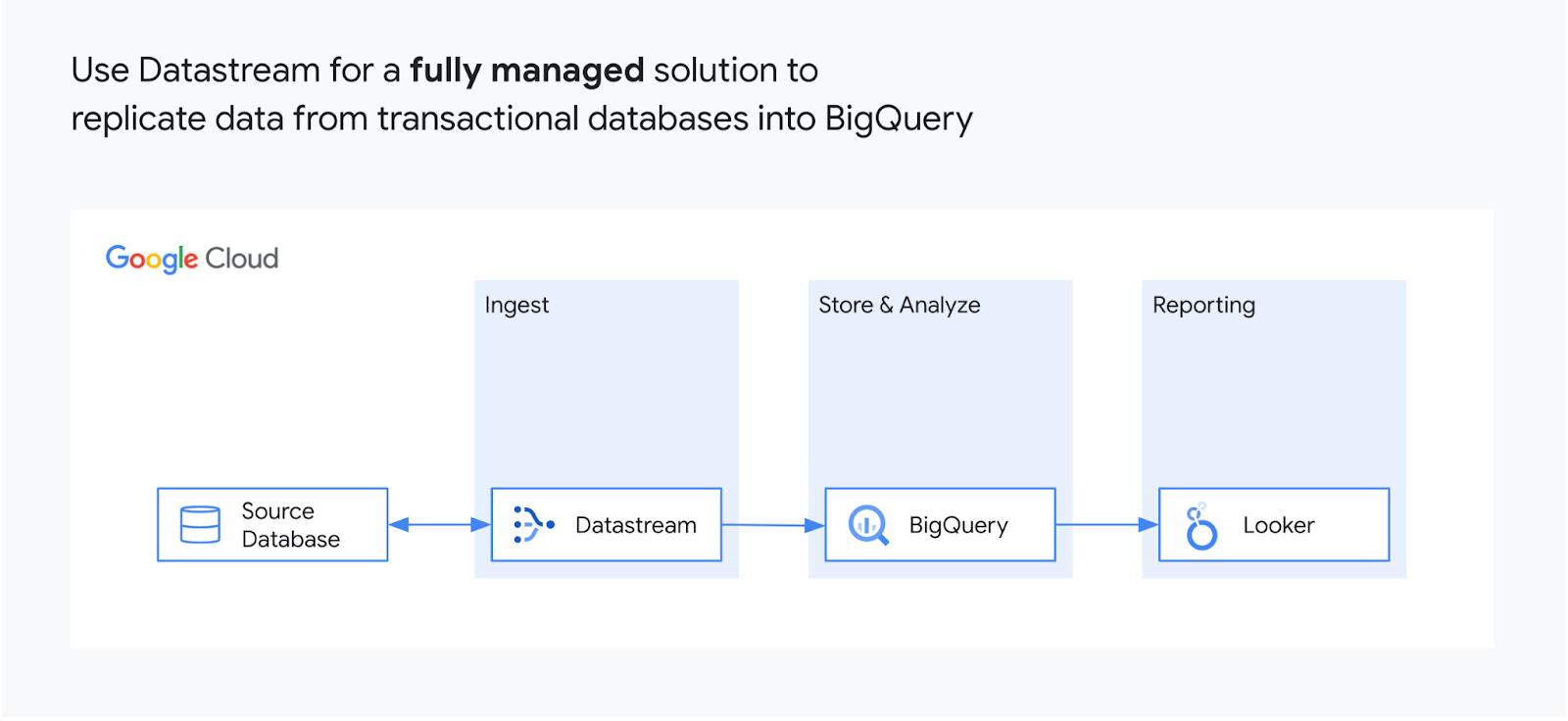
Replicación de datos operativos en BigQuery
Datastream utiliza la función Change Data Capture (CDC) y la API de escritura de Storage de BigQuery para replicar actualizaciones directamente desde los sistemas de origen prácticamente en tiempo real. Ya no necesitas soluciones de replicación que malgasten recursos valiosos en flujos de procesamiento de datos complejos, tablas de staging autogestionadas, lógica de combinación complicada o conversión manual de tipos de datos.
Configuración simplificada
Datastream te permite empezar a replicar datos en BigQuery en pocos pasos. Tan solo tienes que configurar la base de datos de origen, el tipo de conexión y el destino en BigQuery. Datastream para BigQuery rellenará el historial de datos y replicará los cambios nuevos continuamente.
Transmitir datos de bases de datos relacionales
Datastream lee y envía todos los cambios (insertar, actualizar y eliminar) de tus bases de datos de MySQL, PostgreSQL, AlloyDB y Oracle con BigQuery con una latencia mínima. La base de datos de origen puede estar alojada on‐premise en servicios de Google Cloud como Cloud SQL o Bare Metal Solution for Oracle. , o en cualquier otro lugar de la nube. Es un servicio nativo de Google y sin agentes diseñado específicamente para BigQuery, por lo que emite todos los eventos de forma fiable cuando se produce.
Resolución de desviaciones en los esquemas
A medida que cambian los esquemas de origen, Datastream gestiona sin problemas los cambios de esquema y replica automáticamente las nuevas columnas y tablas que se han añadido de origen en BigQuery.
Diseñado pensando en la seguridad
DataStream admite varios métodos de conectividad privados para proteger los datos en tránsito. Los datos también se cifran en reposo.

Clientes
Los clientes usan Datastream y BigQuery para habilitar estadísticas en tiempo real


Con Datastream, contamos con una sola herramienta para replicar nuestros datos operativos en BigQuery sin interrupciones y de forma casi en tiempo real. Nos permite obtener estadísticas mucho más rápidas de nuestros datos operativos, ofrecer productos de datos más estables y abordar mejor las necesidades de nuestra empresa.
René Delgado, director de Soluciones de Datos de Falabella

Casos prácticos
Casos prácticos
Replicación sin servidor a BigQuery
Datastream lee los eventos de cambio (inserta, actualiza y elimina) de las bases de datos de origen y las escribe en las tablas de BigQuery prácticamente en tiempo real. Esto permite enriquecer los almacenes de datos y los modelos de aprendizaje automático que ya tengas con datos de transacciones, como las compras, para obtener una visión más completa de los datos. Datastream rellenará el historial de datos, replicará continuamente los nuevos cambios a medida que se vayan produciendo y gestionará fácilmente los cambios de esquema.
Compara opciones de transmisión de datos desde bases de datos operativas en BigQuery
Datastream para BigQuery
Flujo de datos y Dataflow
Datastream y Data Fusion
Principales ventajas
Principales ventajas
La opción más sencilla para replicar datos operativos en BigQuery
Arquitectura sin servidor que escala automáticamente verticalmente
Interfaz única para ver y monitorizar de forma integral los flujos de procesamiento de replicación
Solución personalizable con más flexibilidad
Plantillas predefinidas compatibles con Google en diferentes destinos
Integración de funciones adicionales, como la calidad de datos y el enmascaramiento de datos
Interfaz sencilla para desarrolladores y analistas de datos de procesos de extracción, transformación y carga (ETL)
Identificación con antelación de posibles problemas y lagunas en la replicación
Estadísticas casi en tiempo real sobre el rendimiento de las réplicas
Datastream para BigQuery
Principales ventajas
La opción más sencilla para replicar datos operativos en BigQuery
Arquitectura sin servidor que escala automáticamente verticalmente
Interfaz única para ver y monitorizar de forma integral los flujos de procesamiento de replicación
Flujo de datos y Dataflow
Principales ventajas
Solución personalizable con más flexibilidad
Plantillas predefinidas compatibles con Google en diferentes destinos
Integración de funciones adicionales, como la calidad de datos y el enmascaramiento de datos
Datastream y Data Fusion
Principales ventajas
Interfaz sencilla para desarrolladores y analistas de datos de procesos de extracción, transformación y carga (ETL)
Identificación con antelación de posibles problemas y lagunas en la replicación
Estadísticas casi en tiempo real sobre el rendimiento de las réplicas
Precios
Precios de Datastream
Los precios de los flujos de datos se basan en los datos reales que se han procesado. Están disponibles los precios por niveles según el volumen, lo que hace que sea más asequible si transfieres volúmenes de datos de mayor volumen. Puedes consultar más información sobre los precios en la página de precios de DataStream.
Los recursos adicionales, como BigQuery, Cloud Storage y Dataflow, se facturan según el precio de dichos servicios.
Ve un paso más allá
Empieza a crear en Google Cloud con 300 USD en crédito gratis y más de 20 productos Always Free.
¿Necesitas ayuda para empezar?
Contactar con VentasTrabaja con un partner de confianza
Buscar un partnerSigue explorando
Ver todos los productos











