Cloud Monitoring raccoglie metriche, eventi e metadati dai prodotti Google Cloud . Con Cloud Monitoring puoi anche configurare dashboard personalizzate e avvisi di utilizzo.
Questo documento ti guida nell'utilizzo delle metriche, nell'apprendimento della dashboard delle metriche personalizzate e nell'impostazione degli avvisi.
Risorse monitorate
Una risorsa monitorata in Cloud Monitoring rappresenta un'entità logica o fisica, come una macchina virtuale, un database o un'applicazione. Le risorse monitorate contengono un insieme unico di metriche che possono essere esplorate, riportate tramite una dashboard o utilizzate per creare avvisi. Ogni risorsa ha anche un insieme di etichette delle risorse, ovvero coppie chiave-valore che contengono informazioni aggiuntive sulla risorsa. Le etichette delle risorse sono disponibili per tutte le metriche associate alla risorsa.
Utilizzando l'API Cloud Monitoring, le prestazioni di Firestore in modalità Datastore vengono monitorate con le seguenti risorse:
| Risorse | Descrizione | Modalità di database supportata |
firestore.googleapis.com/Database (consigliata) | Tipo di risorsa
monitorata che fornisce suddivisioni per project,
location* e database_id . L'etichetta
database_id sarà (default) per i database creati
senza un nome specifico. |
Si applica a entrambe le modalità. |
datastore_request | Tipo di risorsa monitorata per progetti Datastore e non fornisce la suddivisione per database. |
Metriche
Firestore è disponibile in due modalità diverse: Firestore Native e Firestore in modalità Datastore. Per un confronto delle funzionalità tra queste due modalità, vedi Scegliere tra le modalità del database.
Per un elenco completo delle metriche per Firestore in modalità Datastore, consulta Metriche di Firestore in modalità Datastore.
Metriche di runtime del servizio
Le metriche serviceruntime
forniscono una panoramica generale del traffico di un progetto. Queste metriche sono
disponibili per la maggior parte delle API Google Cloud . Il tipo di risorsa monitorata
consumed_api
contiene queste metriche comuni. Queste metriche vengono campionate
ogni 30 minuti, il che comporta un livellamento dei dati.
Un'etichetta risorsa importante per le metriche serviceruntime è method. Questa etichetta
rappresenta il metodo RPC sottostante chiamato. Il metodo SDK che chiami potrebbe
non avere necessariamente lo stesso nome del metodo RPC sottostante. Il motivo è che l'SDK fornisce un'astrazione dell'API di alto livello. Tuttavia, quando cerchi di
capire come interagisce la tua applicazione con Firestore, è
importante comprendere le metriche in base al nome del metodo RPC.
Se hai bisogno di sapere qual è il metodo RPC sottostante per un determinato metodo SDK, consulta la documentazione dell'API.
api/request_count
Questa metrica fornisce il conteggio delle richieste completate, in base al protocollo(protocollo di richiesta, ad esempio HTTP, gRPC e così via),
al codice di risposta (codice di risposta HTTP), a response_code_class (classe del codice di risposta, ad esempio 2xx, 4xx e così via) e a grpc_status_code (codice di risposta gRPC numerico). Utilizza questa metrica per
osservare la richiesta API complessiva e calcolare il tasso di errore.
Nella figura 1 sono visibili le richieste che restituiscono un codice 2xx raggruppate per servizio e metodo. I codici 2xx sono codici di stato HTTP che indicano che la richiesta è andata a buon fine.
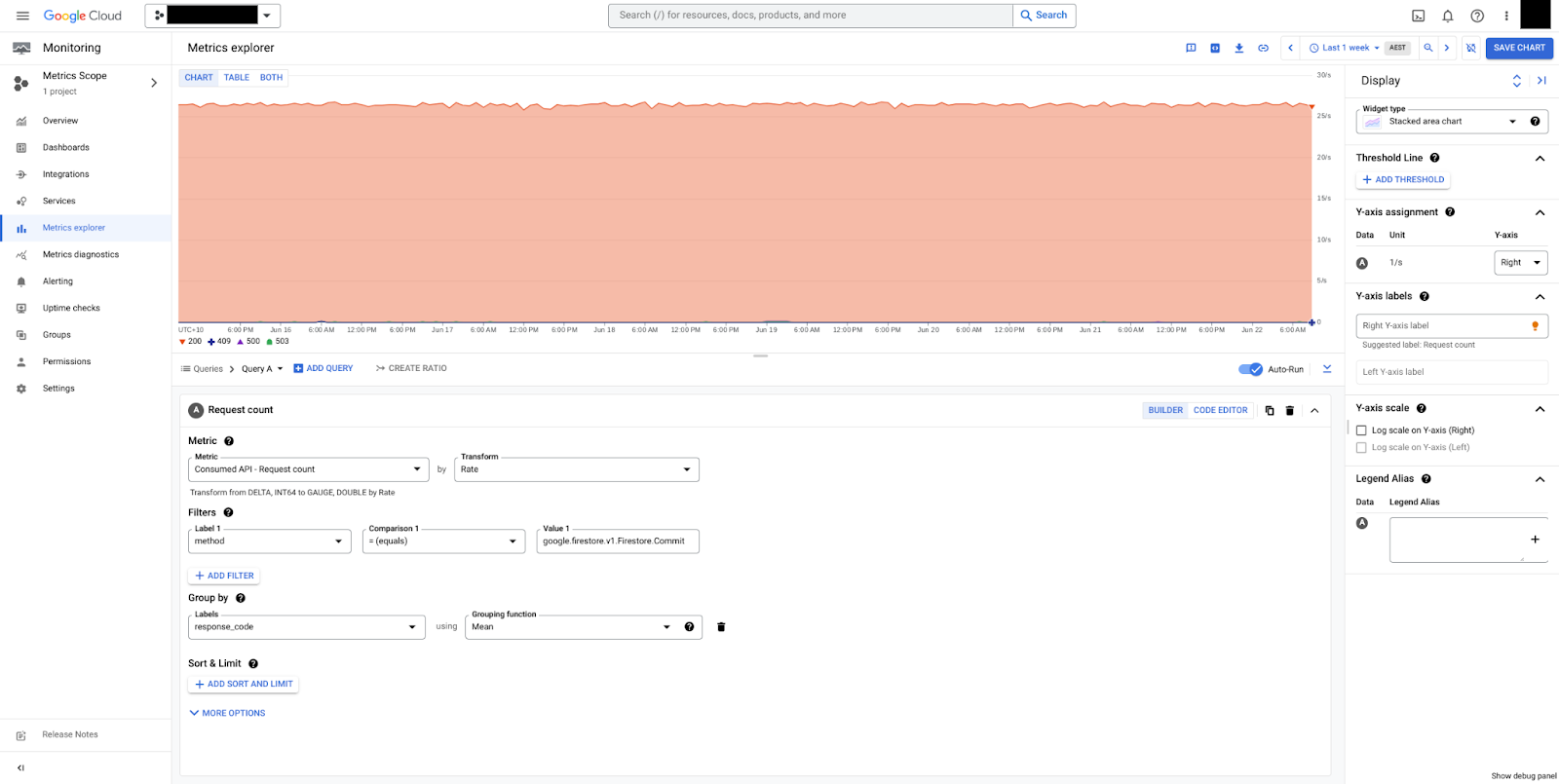
Nella figura 2, sono visibili i commit raggruppati per response_code. In questo esempio, vediamo solo risposte HTTP 200, il che implica che il database è integro.
Utilizza le seguenti metriche di runtime del servizio per monitorare il database.
api/request_count nel tipo di risorsa datastore_request
La metrica api/request_count è disponibile anche nel tipo di risorsa datastore_request
con suddivisioni api_method e response_code. Utilizza questa metrica
per sfruttare il periodo di campionamento più preciso, che consente di rilevare
i picchi.
api/request_latencies
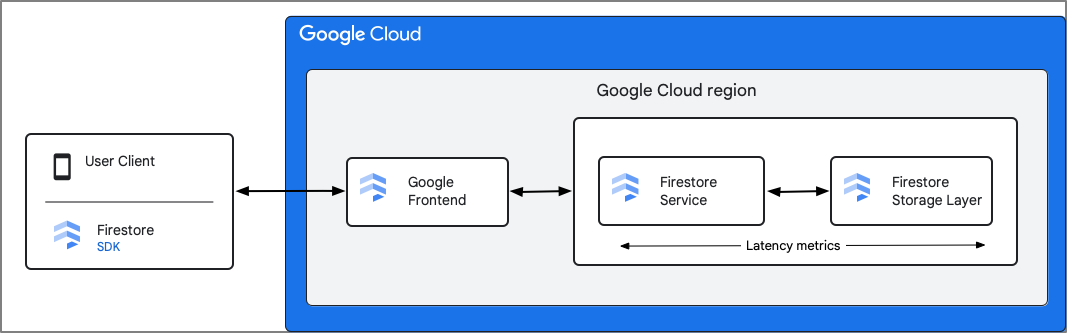
La metrica api/request_latencies fornisce le distribuzioni della latenza per tutte le richieste completate.
Firestore registra le metriche del componente Firestore Service. Le metriche di latenza includono il tempo che intercorre tra il momento in cui Firestore riceve la richiesta e il momento in cui termina l'invio della risposta, incluse le interazioni con il livello di archiviazione. Per questo motivo, la latenza di andata e ritorno (rtt) tra il client e il servizio Firestore non è inclusa in queste metriche.
api/request_sizes e api/response_sizes
Le metriche api/request_sizes e api/response_sizes forniscono rispettivamente
informazioni sulle dimensioni del payload (in byte). Questi possono essere utili per comprendere i carichi di lavoro di scrittura che inviano grandi quantità di dati o le query troppo ampie e restituiscono payload di grandi dimensioni.
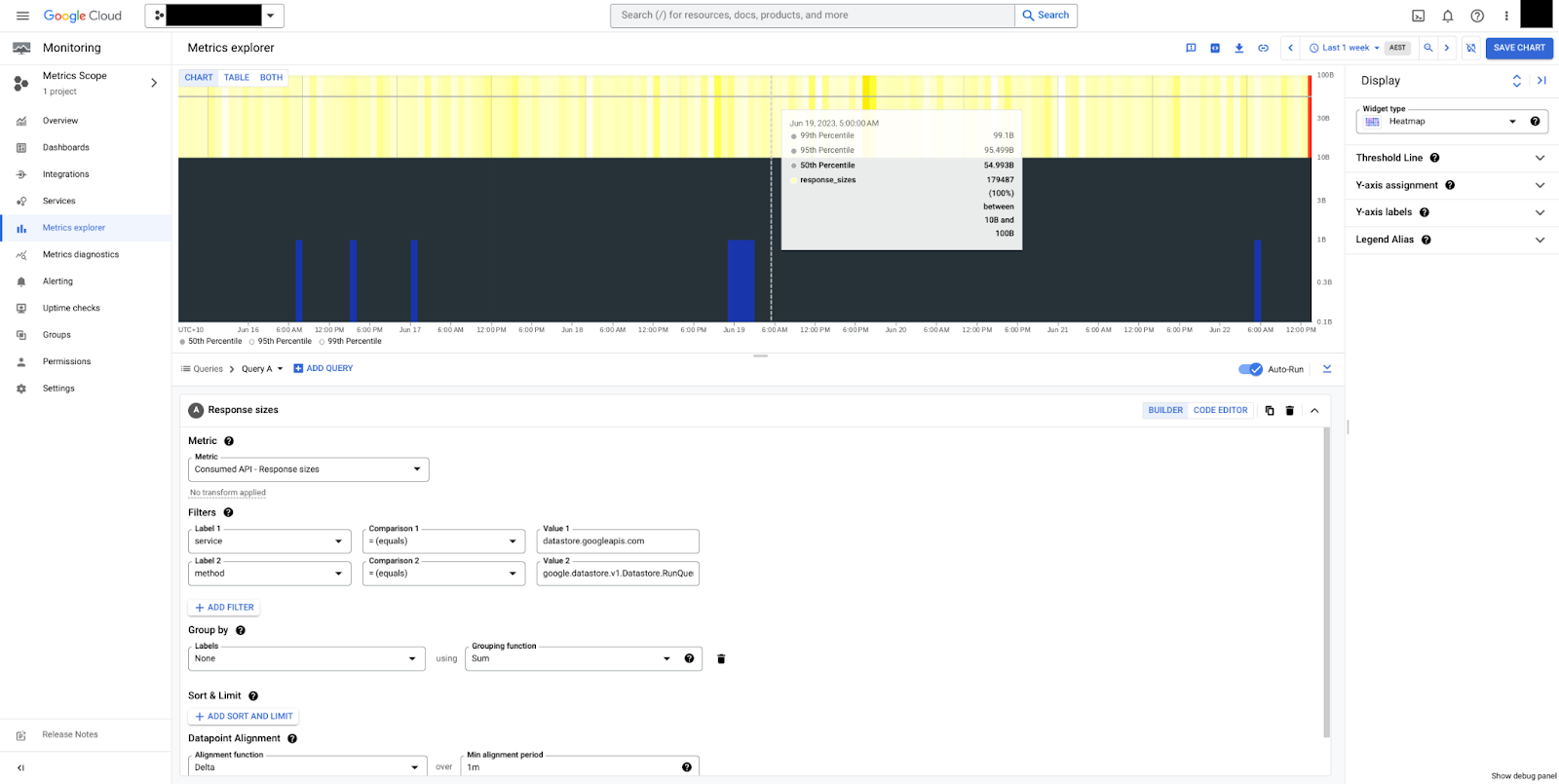
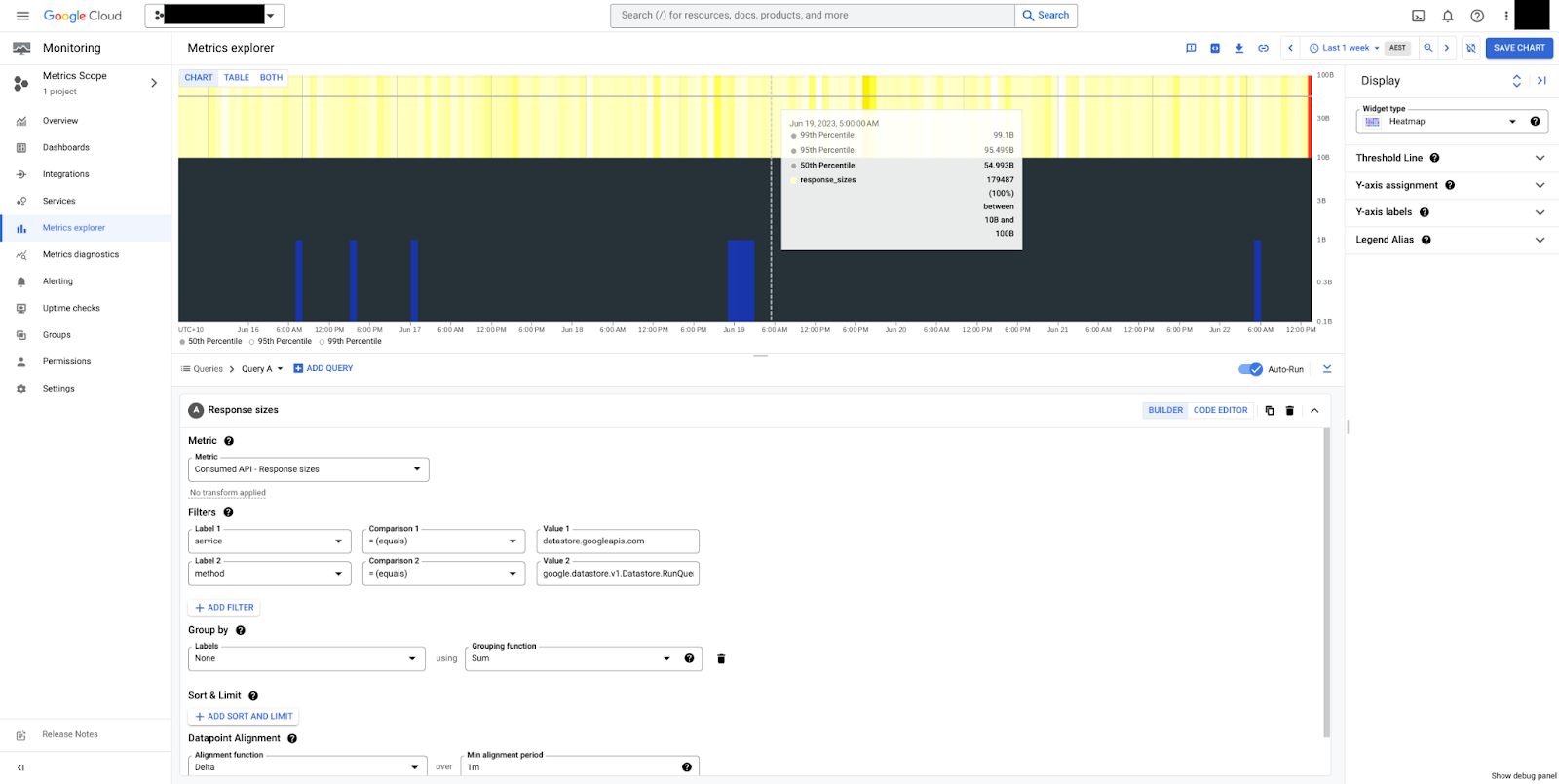
Nella figura 5 è visibile una mappa termica delle dimensioni delle risposte per il metodo RunQuery.
Possiamo vedere che le dimensioni sono stabili, con una mediana di 50 byte e un intervallo complessivo compreso tra 10 byte
e 100 byte. Tieni presente che le dimensioni del payload sono sempre misurate in byte non compressi, esclusi gli overhead di controllo della trasmissione.
Metriche delle operazioni sulle entità
Queste metriche forniscono distribuzioni in byte delle dimensioni del payload per le letture (ricerche e query) e le scritture in un database Firestore. I valori rappresentano
la dimensione totale del payload. Ad esempio, tutti i risultati restituiti da una query.
Queste metriche sono simili a quelle api/request_sizes e api/response_sizes, ma la differenza principale è che le metriche delle operazioni sulle entità forniscono un campionamento più granulare, ma suddivisioni meno granulari.
Ad esempio, le metriche delle operazioni sulle entità utilizzano la risorsa datastore_request monitorata, quindi non è presente una suddivisione per servizio o metodo.
entity/read_sizes: Distribuzione delle dimensioni delle entità lette, raggruppate per tipo.entity/write_sizes: Distribuzione delle dimensioni delle entità scritte, raggruppate per operazioni.
Metriche dell'indice
I tassi di scrittura dell'indice possono essere confrontati con la metrica document/write_ops_count
per comprendere il rapporto di fanout dell'indice.
index/write_count: Conteggio delle scritture dell'indice.
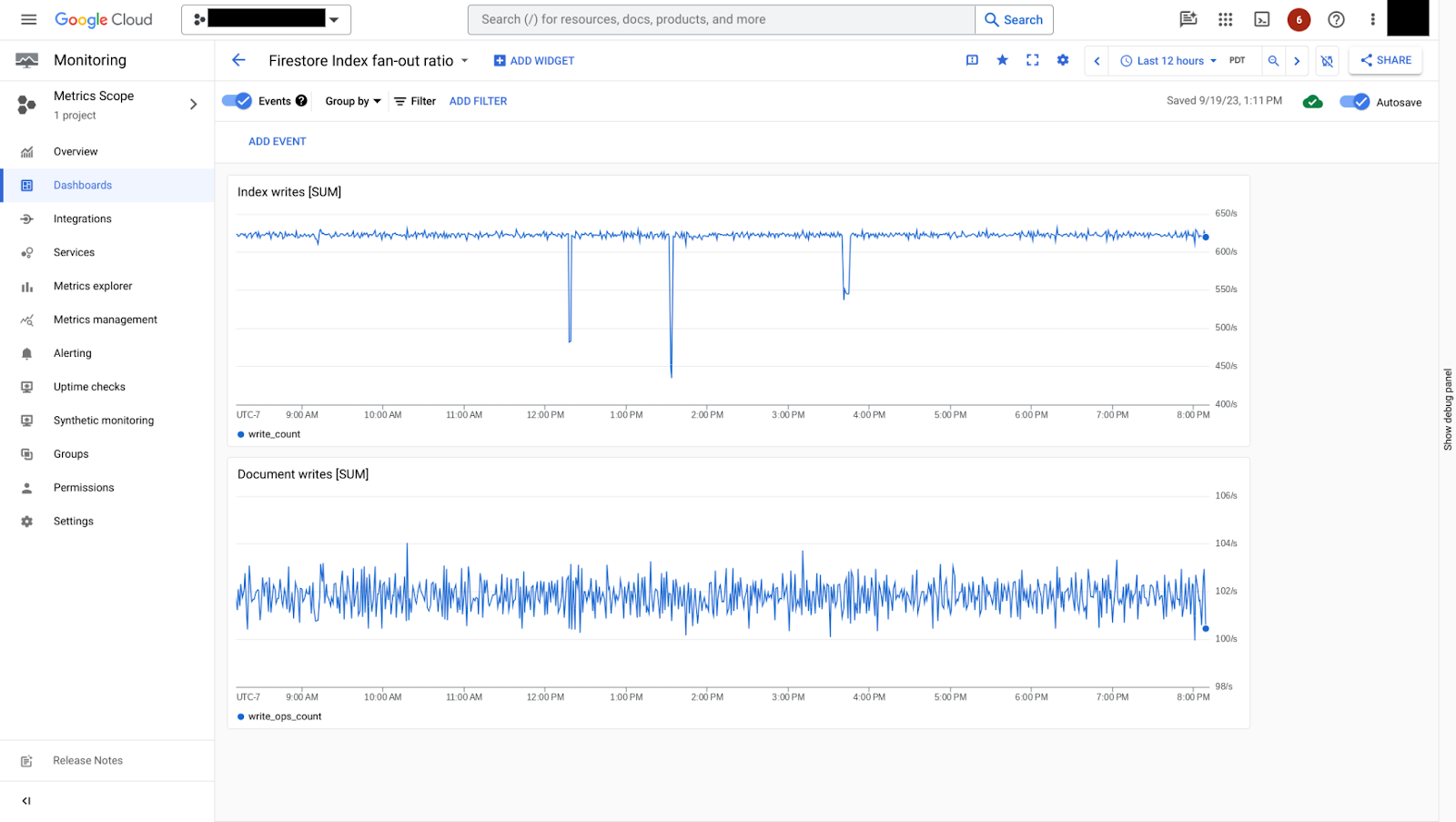
Nella figura 7 puoi vedere come il tasso di scrittura dell'indice può essere confrontato con il tasso di scrittura dei documenti. In questo esempio, per ogni scrittura di documenti, ci sono circa 6 scritture di indice, che è un tasso di fanout dell'indice relativamente basso.
Metriche TTL
Le metriche TTL sono disponibili sia per Firestore Native che per i database Firestore in modalità Datastore. Utilizza queste metriche per monitorare l'effetto del criterio TTL applicato.
entity/ttl_deletion_count: conteggio totale delle entità eliminate dai servizi TTL.entity/ttl_expiration_to_deletion_delays: tempo trascorso tra la scadenza di un'entità con un TTL e la sua effettiva eliminazione.Se noti che i ritardi nell'eliminazione del TTL richiedono più di 24 ore, contatta l'assistenza.
Passaggi successivi
- Scopri di più su come utilizzare la dashboard di Cloud Monitoring per visualizzare le metriche.