Penyusunan Peringkat yang Cepat dan Andal di Datastore
Peringkat: Masalah yang sederhana, tetapi sangat sulit
Tomoaki Suzuki (Gambar 1), engineer utama App Engine di Applibot, telah mencoba memecahkan masalah yang sangat umum, tetapi sangat sulit dihadapi oleh setiap layanan game besar: Pemberian peringkat.

Applibot adalah salah satu penyedia aplikasi sosial utama di Jepang. Keunikan perusahaan ini adalah pengetahuan dan pengalaman mereka yang luas dalam membangun layanan game sosial yang sangat skalabel di Google App Engine, penawaran Platform as a Service (PaaS) dari Google. Dengan memanfaatkan kecanggihan platform ini, Applibot telah cukup berhasil dalam menangkap peluang bisnis di pasar game sosial, tidak hanya di Jepang, tetapi juga di Amerika Serikat. Applibot tentu dapat membuktikan kesuksesannya. Legend of the Cryptids (Gambar 2), salah satu judul terbesar mereka, mencapai posisi #1 di kategori game Apple AppStore Amerika Utara pada Oktober 2012. Seri The Legend mencatat 4,7 juta download. Judul lain, Gang Road, mencapai posisi #1 di peringkat total penjualan AppStore Jepang pada Desember 2012.

Judul ini dapat diskalakan dengan lancar dan menangani traffic yang tumbuh secara besar-besaran. Applibot tidak perlu bersusah payah untuk membuat cluster server virtual atau database yang terpecah yang kompleks. Mereka memanfaatkan kekuatan App Engine dan mencapai skalabilitas dan ketersediaan secara efisien.
Namun, peringkat pemain terbaru bukanlah masalah yang mudah dipecahkan, tidak bagi Tomoaki, dan mungkin tidak bagi developer mana pun, terutama dalam skala ini. Persyaratannya sederhana:
- Game Anda memiliki ratusan ribu (atau lebih) pemain.
- Setiap kali pemain bertarung dengan musuh (atau melakukan aktivitas lain), skornya akan berubah.
- Anda ingin menampilkan peringkat terbaru untuk pemain di halaman portal web.
Bagaimana cara menghitung peringkat?
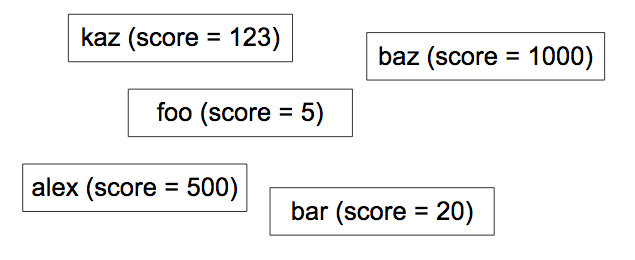
Mendapatkan peringkat itu mudah, jika tidak diharapkan juga skalabel dan cepat. Misalnya, Anda dapat menjalankan kueri berikut:
SELECT count(key) FROM Players WHERE Score > YourScore
Kueri ini menghitung semua pemain yang memiliki skor lebih tinggi dari Anda (Gambar 4). Namun, apakah Anda ingin menjalankan kueri ini untuk setiap permintaan dari halaman portal? Berapa lama waktu yang dibutuhkan jika Anda memiliki satu juta pemain?
Tomoaki awalnya menerapkan pendekatan ini, tetapi perlu waktu beberapa detik untuk mendapatkan setiap respons. Hal ini terlalu lambat, terlalu mahal, dan performanya semakin buruk seiring meningkatnya skala.
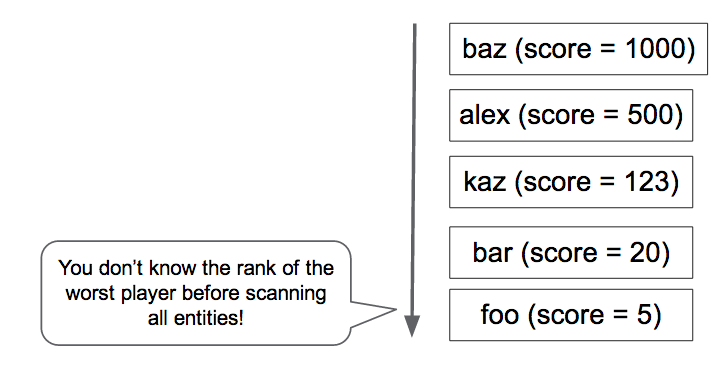
Selanjutnya, Tomoaki mencoba mempertahankan data peringkat di Memcache. Proses ini cepat, tetapi tidak andal. Entri Memcache dapat dihapus kapan saja, dan terkadang layanan Memcache itu sendiri tidak tersedia. Dengan layanan peringkat yang hanya bergantung pada nilai kunci dalam memori, sulit untuk mempertahankan konsistensi dan ketersediaan.
Sebagai solusi sementara, Tomoaki memutuskan untuk menurunkan tingkat layanan. Daripada menghitung peringkat untuk setiap permintaan, ia menyiapkan tugas terjadwal yang memindai dan memperbarui peringkat setiap pemain sekali dalam satu jam. Dengan cara ini, permintaan dari halaman portal dapat langsung mendapatkan peringkat pemain, tetapi mungkin sudah berusia hingga satu jam.
Pada akhirnya, Tomoaki mencari implementasi peringkat yang persisten, transaksional, cepat, dan skalabel yang dapat menerima 300 permintaan pembaruan skor per detik dan mendapatkan peringkat untuk setiap pemain dalam ratusan milidetik. Untuk menemukan solusi, Tomoaki menghubungi Kaz Sato, seorang Solutions Architect (SA) sekaligus Technical Account Manager (TAM) di tim Google Cloud Platform dan ditugaskan ke Applibot berdasarkan kontrak dukungan tingkat premium.
Cara Cepat untuk Memecahkan Masalah
Banyak pelanggan atau partner besar Google Cloud Platform, seperti Applibot, berlangganan kontrak dukungan tingkat premium. Dengan kontrak dukungan tersebut, selain dukungan 24x7 dari tim Dukungan Pelanggan Cloud dan dukungan bisnis dari tim Penjualan Cloud, Google akan menetapkan Technical Account Manager (TAM) untuk setiap pelanggan.
TAM mewakili pelanggan kepada Google Engineering, yang membangun infrastruktur cloud yang sebenarnya. TAM memahami sistem dan arsitektur pelanggan secara mendetail, dan setelah mereka melaporkan kasus kritis, mereka menggunakan pengetahuan dan jaringan mereka sebagai perwakilan Google Engineering di perusahaan untuk menyelesaikan masalah tersebut. TAM dapat mengeskalasikan masalah kepada Solutions Architect dalam tim atau kepada Software Engineer di tim Cloud Platform. Dukungan tingkat premium adalah jalur cepat untuk menemukan solusi dengan Google Cloud Platform.
Kaz, TAM yang mendukung Applibot, tahu bahwa peringkat adalah masalah klasik yang sulit dipecahkan untuk layanan terdistribusi yang skalabel. Ia mulai meninjau implementasi yang diketahui untuk peringkat di Google Cloud Datastore dan datastore NoSQL lainnya untuk menemukan solusi yang memenuhi persyaratan Applibot.
Mencari Algoritma O(log n)
Solusi kueri sederhana memerlukan pemindaian semua pemain dengan skor yang lebih tinggi untuk menghitung peringkat satu pemain. Kompleksitas waktu algoritma ini adalah O(n); yaitu, waktu yang diperlukan untuk eksekusi kueri meningkat secara proporsional dengan jumlah pemain. Dalam praktiknya, hal ini berarti algoritma tidak skalabel. Sebagai gantinya, kita memerlukan algoritma O(log n) atau yang lebih cepat, dengan waktu yang hanya akan meningkat secara logaritma seiring bertambahnya jumlah pemain.
Jika pernah mengikuti kursus ilmu komputer, Anda mungkin ingat bahwa algoritma hierarki, seperti hierarki biner, hierarki merah-hitam, atau B-Tree, dapat berperforma pada kompleksitas waktu O(log n) untuk menemukan elemen. Algoritma hierarki juga dapat digunakan untuk menghitung nilai gabungan dari rentang elemen, seperti jumlah, maks/min, dan rata-rata dengan menyimpan nilai gabungan di setiap node cabang. Dengan teknik ini, Anda dapat menerapkan algoritma peringkat dengan performa O(log n).
Kaz menemukan implementasi open source algoritma peringkat berbasis hierarki untuk Datastore, yang ditulis oleh engineer Google: Library Peringkat Google Code Jam.
Library berbasis Python ini mengekspos dua metode:
SetScoreuntuk menetapkan skor pemain.FindRankuntuk mendapatkan peringkat skor tertentu.
Saat pasangan skor pemain dibuat dan diperbarui dengan metode SetScore, library peringkat Code Jam akan membuat hierarki N-ary1. Misalnya, mari kita pertimbangkan hierarki tersier yang dapat menghitung jumlah pemain dengan skor dalam rentang 0 hingga 80 (Gambar 5). Library ini menyimpan node root, yang menyimpan tiga angka, sebagai satu entity. Setiap angka sesuai dengan jumlah pemain dengan skor dalam sub-rentang 0 - 26, 27 - 53, dan 54 - 80. Node root memiliki node turunan untuk setiap rentang, yang menyimpan tiga nilai untuk pemain dalam sub-rentang sub-rentang. Hierarki memerlukan empat tingkat untuk menyimpan jumlah pemain untuk 81 nilai skor yang berbeda.

Untuk menentukan peringkat pemain yang memiliki skor 30, library hanya perlu membaca empat entity —node yang dilingkari oleh garis putus-putus dalam diagram—untuk menambahkan jumlah pemain yang memiliki skor lebih tinggi dari 30. Dengan 22 pemain di sebelah "kanan" dalam empat entity, peringkat pemain adalah 23.
Demikian pula, panggilan ke SetScore hanya perlu memperbarui empat entity. Meskipun Anda memiliki banyak skor yang berbeda, akses Datastore hanya akan meningkat pada O(log n) dan tidak terpengaruh oleh jumlah pemain. Dalam praktiknya, library peringkat Code Jam menggunakan 100 (bukan 3) sebagai jumlah nilai default per node, sehingga hanya dua (atau tiga, jika rentang skor lebih besar dari 100.000) entitas yang perlu diakses.
Kaz menggunakan alat pengujian beban populer Apache JMeter untuk melakukan pengujian beban pada library peringkat Code Jam dan mengonfirmasi bahwa library tersebut merespons dengan cepat. SetScore dan FindRank dapat menyelesaikan tugasnya dalam ratusan milidetik menggunakan algoritma hierarki N-ary yang bekerja pada kompleksitas waktu O(log n).
Skalabilitas Batas Update Serentak
Namun, selama pengujian beban, Kaz menemukan batasan kritis pada library peringkat Code Jam. Skalabilitasnya dalam hal throughput update cukup rendah. Saat dia meningkatkan beban menjadi tiga update per detik, library mulai menampilkan error percobaan ulang transaksi. Sudah jelas bahwa library tidak dapat memenuhi persyaratan Applibot untuk 300 update per detik. CPU hanya dapat menangani sekitar 1% throughput tersebut.
Mengapa demikian? Alasannya adalah biaya untuk mempertahankan konsistensi hierarki. Di Datastore, Anda harus menggunakan entity group untuk memastikan konsistensi yang kuat saat memperbarui beberapa entity dalam transaksi—lihat "Menyeimbangkan Konsistensi Kuat dan Konsistensi Akhir dengan Google Cloud Datastore". Library peringkat Code Jam menggunakan satu grup entity untuk menyimpan seluruh hierarki guna memastikan konsistensi jumlah dalam elemen hierarki.
Namun, grup entity di Datastore memiliki batasan performa. Datastore hanya mendukung sekitar satu transaksi per detik pada entity group. Selain itu, jika entity group yang sama diubah dalam transaksi serentak, transaksi tersebut kemungkinan akan gagal dan harus dicoba lagi. Library peringkat Code Jam sangat konsisten, transaksional, dan cukup cepat, tetapi tidak mendukung update serentak dalam volume tinggi.
Solusi Tim Datastore: Agregasi Tugas
Kaz ingat bahwa seorang engineer software di tim Datastore telah menyebutkan teknik untuk mendapatkan throughput yang jauh lebih tinggi daripada satu pembaruan per detik pada entity group. Hal ini dapat dicapai dengan menggabungkan batch update ke dalam satu transaksi, bukan menjalankan setiap update sebagai transaksi terpisah. Namun, karena transaksi mencakup banyak pembaruan, setiap transaksi memerlukan waktu lebih lama, sehingga meningkatkan kemungkinan konflik dari transaksi serentak.
Sebagai respons atas permintaan Kaz, tim Datastore mulai mendiskusikan masalah ini dan menyarankan kami untuk mempertimbangkan penggunaan Agregasi Tugas, salah satu pola desain yang digunakan dengan Megastore.
Megastore adalah lapisan penyimpanan yang mendasari Datastore, dan mengelola konsistensi serta transaksionalitas grup entity. Batas satu pembaruan per detik berasal dari lapisan tersebut. Karena Megastore digunakan secara luas oleh berbagai layanan Google, para engineer telah mengumpulkan dan membagikan praktik terbaik serta pola desain dalam perusahaan untuk membangun sistem yang skalabel dan konsisten dengan datastore NoSQL ini.
Ide dasar Agregasi Tugas adalah menggunakan satu thread untuk memproses batch update. Karena hanya ada satu thread dan hanya satu transaksi yang terbuka di entity group, tidak ada kegagalan transaksi karena update serentak. Anda dapat menemukan ide serupa di produk penyimpanan lainnya seperti VoltDb dan Redis.
Namun, ada kelemahan pada pola Agregasi Tugas: pola ini hanya menggunakan satu thread untuk menggabungkan semua update, dan hal ini membatasi seberapa cepat update dapat dikirim ke Datastore. Oleh karena itu, penting untuk menentukan apakah Agregasi Tugas dapat memenuhi persyaratan throughput Applibot sebesar 300 pembaruan per detik.
Agregasi Tugas menurut Task Queue Pull
Berdasarkan saran dari tim Datastore, Kaz menulis kode Proof of Concept (PoC) yang menggabungkan pola Agregasi Tugas dengan library peringkat Code Jam. PoC memiliki komponen berikut:
- Frontend: Menerima permintaan
SetScoredari pengguna dan menambahkannya sebagai tugas ke antrean pull. - Antrean Pull: Menerima dan menyimpan permintaan pembaruan
SetScoredari frontend. - Backend: Menjalankan loop tanpa batas dengan satu thread yang mengambil permintaan update dari antrean dan menjalankannya dengan library peringkat Code Jam.
PoC membuat antrean pull, yang merupakan jenis Antrean Tugas di App Engine yang memungkinkan developer menerapkan satu atau beberapa pekerja yang menggunakan tugas yang ditambahkan ke antrean. Instance backend memiliki satu thread dalam loop tanpa batas yang terus menarik tugas sebanyak mungkin (hingga 1.000) dari antrean. Thread meneruskan setiap permintaan pembaruan ke library peringkat Code Jam, yang mengeksekusinya sebagai batch dalam satu transaksi. Transaksi mungkin terbuka selama satu detik atau lebih, tetapi karena ada satu thread yang mendorong library dan Datastore, tidak ada pertentangan dan tidak ada masalah modifikasi serentak.
Instance backend ditentukan sebagai modul, fitur App Engine yang memungkinkan developer menentukan Instance Aplikasi dengan berbagai karakteristik. Dalam PoC ini, instance backend ditentukan sebagai instance penskalaan manual. Hanya satu instance tersebut yang berjalan pada waktu tertentu.
Kaz melakukan pengujian beban PoC menggunakan JMeter. Dia mengonfirmasi bahwa PoC dapat memproses 200 permintaan SetScore per detik, dengan batch 500 hingga 600 pembaruan per transaksi. Aggregator Lowongan berfungsi.
Pembagian Antrian untuk Performa Stabil
Namun, Kaz segera menemukan masalah lain. Saat terus menjalankan pengujian selama beberapa menit, ia melihat throughput antrean pull berfluktuasi dari waktu ke waktu (Gambar 6). Secara khusus, saat ia terus menambahkan permintaan ke antrean dengan 200 tugas per detik selama beberapa menit, antrean tiba-tiba berhenti meneruskan tugas ke backend, dan latensi untuk setiap tugas meningkat secara dramatis.
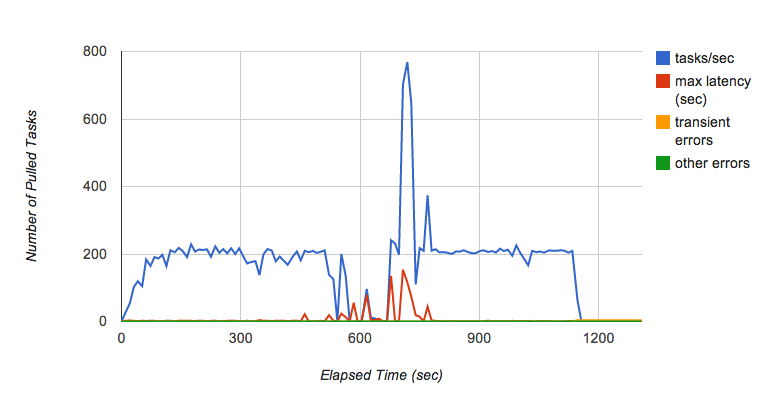
Kaz berkonsultasi dengan tim Task Queue untuk mengetahui penyebabnya. Menurut tim Task Queue, ini adalah perilaku yang diketahui untuk implementasi antrean pull saat ini yang bergantung pada Bigtable sebagai lapisan persistensinya. Jika tablet Bigtable tumbuh terlalu besar, tablet tersebut akan dibagi menjadi beberapa tablet. Saat tablet dipisah, tugas tidak dikirim, dan hal itu menyebabkan fluktuasi performa saat antrean menerima tugas dengan kecepatan tinggi. Tim Task Queue sedang berupaya meningkatkan karakteristik performa ini.
Michael Tang, seorang Solutions Architect, merekomendasikan solusi menggunakan Pembagian Antrean. Alih-alih hanya menggunakan satu antrean, ia menyarankan untuk mendistribusikan beban ke beberapa antrean. Setiap antrean dapat disimpan di server tablet Bigtable yang berbeda untuk meminimalkan efek pemisahan tablet dan mempertahankan kecepatan pemrosesan tugas yang tinggi. Saat satu antrean memproses pemisahan, antrean lain akan terus berfungsi, dan sharding mengurangi beban pada setiap antrean, sehingga pemisahan tablet akan lebih jarang terjadi.
Loop instance backend yang ditingkatkan menjalankan algoritma berikut:
- Menyewa tugas
SetScoredari 10 antrean. - Panggil metode
SetScoresdengan tugas. - Hapus tugas yang disewa dari antrean.
Pada langkah 1, setiap antrean menyediakan hingga 1.000 tugas, dengan setiap tugas menyimpan nama pemain dan skor. Setelah menggabungkan semua pasangan skor pemain ke dalam kamus, langkah 2 meneruskan batch pembaruan ke metode SetScores dari library peringkat Code Jam, yang membuka transaksi untuk menyimpannya di Datastore. Jika tidak ada error saat menjalankan metode, langkah 3 akan menghapus tugas yang dibeli dari antrean.
Jika terjadi error atau penonaktifan loop atau instance backend yang tidak terduga, tugas update akan tetap berada dalam antrean tugas, sehingga dapat diproses saat instance dimulai ulang. Dalam sistem produksi, Anda mungkin memiliki backend lain yang bertindak sebagai watchdog dalam mode standby, siap mengambil alih jika instance pertama gagal.
Solusi yang Diusulkan: Berjalan dengan 300 Pembaruan per Detik yang Bertahan2
Gambar 7 menunjukkan hasil pengujian beban dari penerapan PoC akhir dengan Pembagian Antrean. Hal ini secara efektif meminimalkan fluktuasi performa dalam antrean dan dapat mempertahankan 300 pembaruan per detik selama beberapa jam. Pada beban biasa, setiap pembaruan diterapkan ke Datastore dalam beberapa detik setelah menerima permintaan.

Solusi ini memenuhi semua persyaratan asli Applibot:
- Dapat diskalakan untuk menangani puluhan ribu pemain.
- Persisten dan konsisten karena semua pembaruan dijalankan dalam transaksi Datastore.
- Cukup cepat untuk menangani 300 pembaruan per detik.
Dengan hasil pengujian beban dan kode PoC, Kaz mempresentasikan solusi tersebut kepada Tomoaki dan engineer Applibot lainnya. Tomoaki berencana untuk menerapkan solusi ini di sistem produksinya, berharap dapat mengurangi latensi pembaruan info peringkat dari satu jam menjadi beberapa detik, dan berharap dapat meningkatkan pengalaman pengguna secara drastis.
Ringkasan Hierarki Peringkat dengan Agregasi Lowongan
Solusi yang diusulkan memiliki beberapa keunggulan dan satu kelemahan:
Kelebihan:
- Cepat: Panggilan
FindRankmemerlukan waktu beberapa ratus milidetik atau kurang. - Cepat:
SetScorehanya mengirimkan tugas, yang diproses oleh backend dalam beberapa detik. - Sangat konsisten dan dipertahankan di Datastore.
- Peringkat akurat.
- Dapat diskalakan ke berapa pun jumlah pemain.
Kekurangan:
- Throughput memiliki batasan (sekitar 300 update/detik dengan penerapan saat ini).
Karena solusi ini menggunakan pola Agregasi Tugas, solusi ini mengandalkan satu thread untuk menggabungkan semua update. Diperlukan pekerjaan atau kompleksitas tambahan untuk mencapai throughput yang lebih tinggi dari 300 pembaruan/detik dengan daya CPU saat ini dari instance App Engine dan performa Datastore.
Solusi yang Lebih Skalabel dengan Pohon Shard
Jika memerlukan kecepatan update yang lebih besar, Anda mungkin perlu melakukan sharding pada hierarki peringkat. Anda akan membuat beberapa implementasi sistem di atas—serangkaian antrean yang masing-masing mendorong modul backend yang memperbarui hierarki peringkatnya sendiri.
Secara umum, mengoordinasikan hierarki tidak diperlukan atau diharapkan. Dalam kasus yang paling sederhana, setiap update SetScore dikirim secara acak ke antrean. Dengan tiga hierarki tersebut, masing-masing dengan grup entity Datastore dan server backend-nya sendiri, throughput update yang diharapkan akan tiga kali lebih besar. Namun, FindRank harus membuat kueri untuk setiap hierarki peringkat guna mendapatkan peringkat skor, lalu menjumlahkan peringkat dari setiap hierarki untuk menemukan peringkat sebenarnya, yang akan memerlukan waktu sedikit lebih lama. Waktu kueri untuk FindRank dapat dikurangi secara substansial dengan menyimpan entity di Memcache.
Hal ini mirip dengan pendekatan yang dikenal luas menggunakan penghitung sharding: setiap penghitung bertambah secara independen, dan jumlah total hanya dihitung saat diperlukan oleh klien.
Misalnya, dengan tiga hierarki, FindRank(865) mungkin menemukan tiga peringkat 124, 183, dan 156, yang menunjukkan bahwa setiap hierarki memiliki jumlah skor masing-masing yang lebih tinggi dari 865. Jumlah total skor yang dihitung lebih tinggi dari 865 adalah 124 + 183 + 156 = 463.
Pendekatan ini tidak berfungsi untuk semua jenis algoritma terdistribusi, tetapi karena peringkat pada dasarnya adalah masalah penghitungan komutatif, pendekatan ini akan berfungsi untuk masalah peringkat bervolume besar.
Solusi yang Lebih Dapat Diskalakan dengan Pendekatan Perkiraan
Jika aplikasi Anda memerlukan skalabilitas lebih dari akurasi peringkat, dan dapat menoleransi tingkat ketidakakuratan atau perkiraan tertentu, Anda dapat memilih pendekatan stokastik seperti:
- Bucket dengan Kueri Global
- Metode Penghitungan Lossy
- Streaming Hemat
Semua pendekatan perkiraan ini adalah varian dari satu ide: Bagaimana cara mengompresi penyimpanan untuk informasi peringkat dengan mengizinkan penurunan akurasi peringkat tertentu?
Bucket dengan Kueri Global adalah solusi alternatif yang diusulkan oleh tim Datastore dan Alex Amies, seorang TAM. Alex menerapkan PoC berdasarkan ide tim Datastore dan melakukan analisis performa yang ekstensif. Ia membuktikan bahwa Bucket dengan Kueri Global adalah solusi peringkat yang skalabel dengan degradasi minimal pada akurasi peringkat dan dapat cocok untuk aplikasi yang memerlukan throughput lebih tinggi daripada library peringkat Code Jam. Lihat Lampiran untuk mengetahui deskripsi mendetail dan hasil pengujian.
Metode Penghitungan Lossy dan Streaming Hemat disebut sebagai algoritma online dan algoritma streaming tempat Anda dapat menggunakan penyimpanan dalam memori yang sangat kecil untuk menghitung estimasi stokastik peringkat teratas dari streaming pasangan skor pemain. Algoritma ini akan cocok untuk aplikasi yang memerlukan latensi sangat rendah dan bandwidth super tinggi, seperti ribuan pembaruan per detik, dengan akurasi dan cakupan hasil peringkat yang lebih terbatas. Misalnya, jika Anda ingin memiliki dasbor real-time yang menampilkan 100 kata kunci teratas yang diketik ke dalam feed jejaring sosial, algoritma ini akan membantu.
Kesimpulan
Peringkat adalah masalah klasik, tetapi sulit dipecahkan jika Anda mewajibkan algoritma untuk skalabel, konsisten, dan cepat. Dalam artikel ini, kami menjelaskan cara TAM Google bekerja sama dengan pelanggan dan tim Engineering Google untuk mengatasi tantangan dan memberikan solusi yang dapat mengurangi latensi pembaruan peringkat dari satu jam menjadi beberapa detik. Pola desain yang ditemukan dalam proses ini—Penggabungan Tugas dan Pembagian Shard Antrean—juga dapat diterapkan pada masalah umum dalam desain sistem berbasis Datastore lainnya yang memerlukan ratusan pembaruan per detik dengan konsistensi yang kuat.
Catatan
- Library peringkat Code Jam menggunakan parameter yang disebut “faktor percabangan” yang menentukan jumlah skor yang akan dimiliki setiap entitas. Secara default, library menggunakan 100 sebagai parameter. Dalam hal ini, skor yang berkisar dari 0 hingga 9999 akan disimpan di 100 entitas sebagai turunan dari node root. Jika perlu menangani rentang skor yang lebih luas, Anda dapat mengubah faktor percabangan ke nilai yang lebih tinggi untuk mengoptimalkan jumlah akses entity.
- Angka performa apa pun yang dijelaskan dalam artikel ini adalah nilai sampel untuk referensi dan tidak menjamin performa absolut App Engine, Datastore, atau layanan lainnya.
Lampiran: Bucket dengan Solusi Kueri Global
Seperti yang disebutkan di bagian Cara Mendapatkan Peringkat, membuat kueri database untuk setiap permintaan peringkat akan memakan biaya yang mahal. Pendekatan alternatif ini secara berkala mendapatkan jumlah semua skor, menghitung peringkat skor yang dipilih, dan menyediakan titik data tersebut untuk digunakan dalam menghitung peringkat pemain tertentu. Total rentang skor dibagi menjadi 'bucket'. Setiap bucket dicirikan oleh sub-rentang skor dan jumlah pemain dengan skor dalam rentang tersebut. Dari data tersebut, peringkat skor apa pun dapat ditemukan dengan perkiraan yang mendekati. Bucket ini mirip dengan node tingkat atas dalam hierarki peringkat, tetapi alih-alih turun ke node yang lebih mendetail, algoritma ini hanya melakukan interpolasi dalam bucket.
Pengambilan peringkat oleh pengguna dari frontend dipisahkan dari komputasi peringkat pada bucket di backend untuk meminimalkan waktu untuk menemukan peringkat. Saat peringkat pemain diminta, bucket yang sesuai akan ditemukan berdasarkan skor pemain. Bucket mencakup batas peringkat atas dan jumlah pemain dalam bucket. Interpolasi linear dalam bucket digunakan untuk memperkirakan peringkat pemain dalam bucket. Dalam pengujian, kami dapat mendapatkan peringkat pemain secara konsisten dalam waktu kurang dari 400 milidetik untuk perjalanan bolak-balik HTTP penuh. Biaya metode FindRank tidak bergantung pada jumlah pemain dalam populasi.
Menghitung peringkat untuk skor tertentu
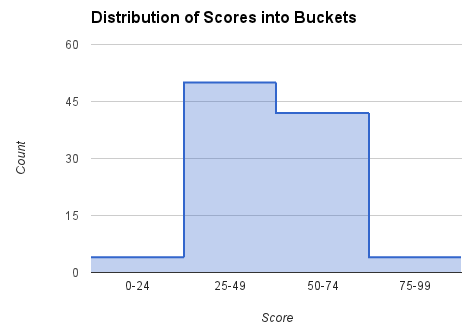
Jumlah dan peringkat teratas (yaitu peringkat tertinggi yang mungkin dalam bucket ini) dicatat untuk setiap bucket. Untuk skor antara batas skor rendah dan tinggi dalam bucket, kami menggunakan interpolasi linear untuk memperkirakan peringkat. Misalnya, jika pemain memiliki skor 60, kita akan melihat bucket [50, 74], menggunakan jumlah (jumlah pemain/skor dalam bucket) (42) dan peringkat teratas (5) untuk menghitung peringkat pemain dengan formula ini:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Menghitung jumlah dan rentang untuk setiap bucket
Di latar belakang, menggunakan tugas cron atau antrean tugas, jumlah untuk setiap bucket dihitung dan disimpan dengan melakukan iterasi pada semua bucket. Kami menyebutnya kueri global, karena kueri ini menghitung parameter yang diperlukan untuk memperkirakan peringkat dengan memeriksa skor semua pemain. Contoh kode Python untuk melakukannya berdasarkan skor dalam rentang [low_score, high_score] untuk setiap bucket ditampilkan di bawah.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
Metode GetCountInRange() menghitung setiap pemain dengan skor dalam rentang yang dicakup oleh bucket. Karena Datastore mempertahankan indeks yang diurutkan pada skor pemain, jumlah ini dapat dihitung secara efisien.
Jika perlu menemukan peringkat pemain tertentu, kita dapat menggunakan kode seperti yang ditunjukkan di bawah ini.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
Metode GetBucketByScore(score) mengambil bucket yang berisi skor yang diberikan. Metode RankInBucket() melakukan estimasi peringkat dalam bucket. Peringkat pemain adalah jumlah peringkat teratas bucket, dan peringkat dalam bucket tertentu yang mengapit skor pemain. Kita perlu mengurangi 1 dari hasilnya karena peringkat teratas bucket teratas akan menjadi 1, dan peringkat pemain teratas dalam bucket tertentu juga akan menjadi 1.
Bucket disimpan ke Datastore dan Memcache. Untuk menghitung peringkat, baca bucket dari Memcache (atau Datastore, jika Memcache tidak memiliki data). Dalam implementasi algoritma ini, kami menggunakan Library Klien NDB Python yang menggunakan Memcache untuk menyimpan data dalam cache yang disimpan di Datastore.
Karena bucket (atau metode lainnya) digunakan untuk merepresentasikan data secara ringkas, peringkat yang dihasilkan tidak tepat. Peringkat dalam bucket diperkirakan dengan interpolasi linear. Metode interpolasi lain yang lebih akurat dapat digunakan untuk mendapatkan perkiraan yang lebih baik dalam bucket, seperti formula regresi.
Biaya
Biaya untuk menemukan peringkat dan memperbarui skor pemain adalah O(1); yaitu, tidak bergantung pada jumlah pemain.
Biaya tugas kueri global adalah O(Pemain) * frekuensi pembaruan cache.
Biaya komputasi data bucket dalam tugas backend juga terkait dengan jumlah bucket karena kueri jumlah dilakukan untuk setiap bucket. Kueri count dioptimalkan untuk menggunakan kueri khusus kunci, tetapi meskipun demikian, daftar kunci lengkap harus diambil.
Kelebihan
Metode ini sangat cepat untuk memperbarui skor pemain serta menemukan peringkat skor. Meskipun hasilnya didasarkan pada tugas latar belakang, jika skor pemain berubah, peringkat akan segera menunjukkan perubahan ke arah yang sesuai. Hal ini karena interpolasi yang digunakan dalam bucket.
Karena komputasi peringkat teratas bucket dilakukan di latar belakang dengan tugas terjadwal, skor pemain dapat diperbarui tanpa perlu menyinkronkan data bucket. Jadi, throughput pembaruan skor pemain tidak dibatasi oleh pendekatan ini.
Kekurangan
Waktu untuk menghitung semua skor pemain, menghitung peringkat global, dan memperbarui bucket perlu dipertimbangkan. Dalam pengujian kami, dengan populasi sepuluh juta pemain, waktunya adalah 8 menit 34 detik untuk sistem pengujian kami di App Engine. Proses ini lebih cepat daripada waktu yang diperlukan untuk menghitung peringkat setiap pemain, tetapi konsekuensinya adalah perkiraan skor dalam setiap bucket. Sebaliknya, algoritma hierarki menghitung 'rentang bucket' (node atas hierarki) secara bertahap setiap beberapa detik, tetapi memiliki kompleksitas implementasi yang lebih besar dan throughput terbatas.
Dalam semua kasus, waktu untuk FindRank juga bergantung pada pengambilan data yang cepat (bucket atau node hierarki) dari Memcache. Jika data dihapus dari Memcache, data tersebut harus diambil kembali dari Datastore dan di-cache ulang untuk permintaan FindRank berikutnya.
Akurasi
Akurasi metode bucket bergantung pada jumlah bucket yang ada, peringkat pemain, dan distribusi skor. Gambar 9 menunjukkan hasil dari studi kami tentang akurasi estimasi peringkat dengan jumlah bucket yang berbeda.

Pengujian dilakukan untuk populasi 10.000 pemain dengan skor yang didistribusikan secara merata dalam rentang [0-9999]. Error relatifnya sekitar 1% bahkan untuk hanya 5 bucket.
Akurasi menurun untuk pemain dengan peringkat tinggi, terutama karena hukum bilangan besar tidak berlaku jika hanya melihat skor teratas. Dalam banyak kasus, sebaiknya gunakan algoritma yang lebih akurat untuk mempertahankan peringkat satu atau dua ribu pemain dengan skor tertinggi. Masalah ini berkurang secara signifikan, karena ada lebih sedikit pemain yang harus dilacak, dan tingkat agregat update juga lebih rendah.
Dalam pengujian di atas, penggunaan angka acak yang didistribusikan secara merata, dengan fungsi distribusi kumulatif yang linear, lebih mendukung penggunaan interpolasi linear dalam bucket, tetapi interpolasi dalam bucket berfungsi dengan baik untuk distribusi skor yang padat. Gambar 10 menunjukkan perkiraan dan peringkat sebenarnya untuk distribusi skor yang kira-kira normal.

Dalam eksperimen ini, populasi 100 pemain digunakan untuk menguji akurasi dengan set data kecil. Setiap skor dihasilkan dengan mengambil rata-rata 4 angka acak antara 0 dan 100, yang kira-kira mendekati distribusi skor normal. Perkiraan peringkat dihitung menggunakan metode kueri global dengan interpolasi linear pada 10 bucket. Dapat dilihat bahwa bahkan untuk set data yang sangat kecil dan distribusi yang tidak seragam, hasilnya sangat baik.