Como equilibrar consistência forte e consistência posterior no Datastore
Como oferecer uma experiência do usuário consistente e aproveitar o modelo de consistência posterior para fazer o escalonamento para grandes conjuntos de dados
Neste documento, falamos sobre como atingir uma consistência forte para garantir uma experiência do usuário positiva e, ao mesmo tempo, adotar o modelo de consistência posterior do Datastore para processar grandes quantidades de dados e usuários.
Este documento é destinado a arquitetos e engenheiros de software que querem criar soluções no Datastore. Para ajudar os leitores mais acostumados com bancos de dados relacionais do que com sistemas não relacionais como o Datastore, este artigo destaca conceitos análogos em bancos de dados relacionais. Ele pressupõe que você tenha conhecimentos básicos do Datastore. O jeito fácil de começar a usar o Datastore está no Google App Engine, usando um dos idiomas compatíveis. Se você ainda não usou o App Engine, sugerimos que leia antes o Guia de primeiros passos e a seção Como armazenar dados em um desses idiomas. O Python é usado nos fragmentos de código de exemplo, mas não é necessário ter experiência com ele para acompanhar este documento.
Observação: os snippets de código neste artigo usam a biblioteca de cliente DB do Python para Datastore, que não é mais recomendada. É altamente recomendado que os desenvolvedores de novos aplicativos usem a biblioteca de cliente NDB. Ela oferece vários benefícios em comparação a esta biblioteca de cliente, como o armazenamento em cache automático de entidades por meio da API Memcache. Se você estiver usando a antiga biblioteca de cliente de DB, leia o Guia de migração de DB para NDB
Índice
NoSQL e consistência posterior
Consistência posterior no Datastore
Consulta de ancestral e grupo de entidades
Limitações do grupo de entidades e da consulta de ancestral
Alternativas às consultas de ancestral
Como minimizar o tempo para atingir a consistência completa
Conclusão
Recursos complementares
Consistência posterior e NoSQL
Os bancos de dados não relacionais, também conhecidos como bancos de dados NoSQL, surgiram nos últimos anos como uma alternativa aos bancos de dados relacionais. O Datastore é um dos bancos de dados não relacionais mais usados no setor. Em 2013, o Datastore processou 4,5 trilhões de transações por mês (postagem do blog do Google Cloud Platform). Ele oferece aos desenvolvedores uma maneira simplificada de armazenar e acessar dados. O esquema flexível gera naturalmente o mapeamento para linguagens de script e orientadas a objeto. O Datastore também fornece vários recursos que os bancos de dados relacionais não são adequados para fornecer, incluindo alto desempenho em uma escala muito grande e alta confiabilidade.
Para desenvolvedores mais habituados com os bancos de dados relacionais, talvez seja um desafio projetar um sistema que utilize bancos de dados não relacionais. Isso porque algumas características e práticas deles são relativamente desconhecidas para os desenvolvedores. Embora o modelo de programação do Datastore seja simples, é importante conhecer essas características. A consistência posterior é uma dessas características, e a programação dela é o principal assunto deste documento.
O que é a consistência posterior?
Consistência posterior é uma garantia teórica de que, desde que não sejam feitas novas atualizações em uma entidade, todas as leituras da entidade em algum momento retornarão o último valor atualizado. O Sistema de Nome de Domínio (DNS) da Internet é um exemplo bem conhecido de sistema com um modelo de consistência posterior. Os servidores DNS não necessariamente refletem os valores mais recentes, mas os valores são armazenados em cache e replicados em muitos diretórios na Internet. É necessário um certo tempo para replicar os valores modificados em todos os servidores e clientes DNS. No entanto, o sistema DNS é extremamente bem-sucedido e se tornou uma das bases da Internet. Ele é altamente disponível e provou ser extremamente escalonável, permitindo pesquisas de nome para mais cem milhões de dispositivos em toda a Internet.
A Figura 1 ilustra o conceito de replicação com consistência posterior. O diagrama ilustra que, embora as réplicas estejam sempre disponíveis para leitura, algumas delas podem estar inconsistentes com a última gravação no nó de origem, em um determinado momento. No diagrama, o nó A é o nó de origem e os nós B e C são as réplicas.
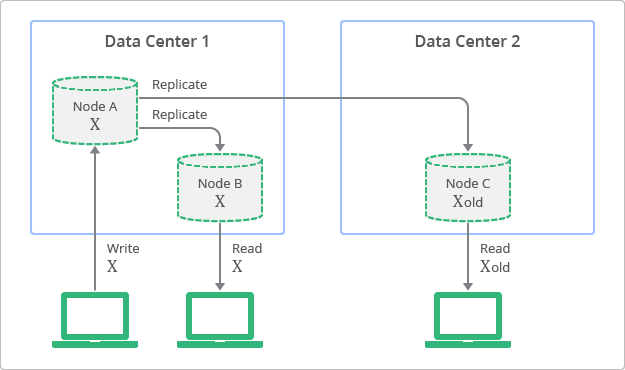
Em contraste, os bancos de dados relacionais tradicionais foram projetados com base no conceito de consistência forte, também chamado de consistência imediata. Isso significa que os dados visualizados imediatamente após a atualização serão consistentes para todos os observadores da entidade. Essa característica tem sido uma pressuposição fundamental para muitos desenvolvedores que usam bancos de dados relacionais. Porém, para atingir a consistência forte, os desenvolvedores precisam comprometer a escalonabilidade e o desempenho dos seus aplicativos. Em outras palavras, os dados precisam ser bloqueados durante o período de atualização ou processo de replicação para garantir que nenhum outro processo atualize os mesmos dados.
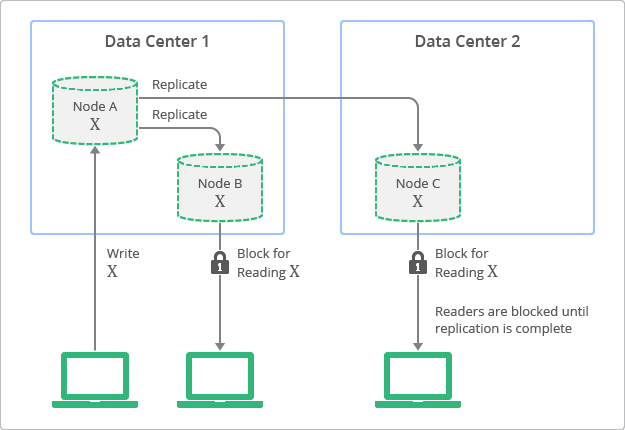
A Figura 2 mostra uma visualização conceitual da topologia de implantação e processo de replicação com consistência forte. Nesse diagrama, é possível ver como as réplicas sempre têm valores consistentes com o nó de origem, mas não podem ser acessadas até que a atualização seja concluída.
Como equilibrar consistência forte e posterior
Os bancos de dados não relacionais se tornaram populares recentemente, em especial para aplicativos da Web que exigem alta escalonabilidade e desempenho com alta disponibilidade. Os bancos de dados não relacionais permitem que os desenvolvedores selecionem um equilíbrio ideal entre a consistência forte e a ideal para cada aplicativo. Isso concede aos desenvolvedores a possibilidade de combinar os benefícios dos dois mundos. Por exemplo, informações como "saber quem na sua lista de amigos está on-line em um determinado momento" ou "saber quantos usuários marcaram sua postagem com +1" são casos de uso em que a consistência forte não é necessária. É possível fornecer escalonabilidade e desempenho para esses casos de uso utilizando a consistência posterior. Casos de uso que exigem consistência forte incluem informações como "se um usuário concluiu ou não o processo de faturamento" ou "o número de pontos que um jogador fez durante uma sessão de combate".
Para generalizar os exemplos dados, os casos de uso com números de entidades muito grandes geralmente sugerem que a consistência posterior é o melhor modelo. Se houver um número de resultados muito grande em uma consulta, a experiência do usuário talvez não seja afetada pela inclusão ou exclusão de entidades específicas. Por outro lado, casos de uso com um número de entidades pequeno e um contexto limitado sugerem que a consistência forte é necessária. A experiência do usuário será afetada, já que o contexto deixará os usuários cientes de quais entidades precisam ser incluídas ou excluídas.
Por esses motivos, é importante que os desenvolvedores entendam as características não relacionais do Datastore. As seções a seguir discutem como os modelos de consistência forte e posterior podem ser combinados para criar um aplicativo escalonável, de alta disponibilidade e alto desempenho. Com isso, os requisitos de consistência para uma experiência de usuário positiva ainda serão atendidos.
Consistência posterior no Datastore
É necessário selecionar a API correta quando uma visualização de dados fortemente consistente for exigida. As diferentes variedades de APIs de consulta do Datastore e seus modelos de consistência correspondentes são mostrados na Tabela 1.
|
API Datastore |
Leitura do valor de entidade |
Leitura de índice |
|---|---|---|
|
Consistência posterior |
Consistência eventual |
|
|
N/A |
Consistência eventual |
|
|
Consistência forte |
Consistência forte |
|
|
Pesquisa por chave (get()) |
Consistência forte |
N/A |
As consultas do Datastore sem um ancestral são conhecidas como consultas globais e são projetadas para funcionar com um modelo de consistência posterior. Isso não garante a consistência forte. Uma consulta global apenas de chaves retorna apenas as chaves das entidades que correspondem à consulta, e não os valores de atributo das entidades. Uma consulta de ancestral determina o âmbito da consulta com base em uma entidade de ancestral. As seções a seguir abordam cada comportamento de consistência mais detalhadamente.
Consistência posterior na leitura dos valores de entidade
Com exceção das consultas de ancestral, um valor de entidade atualizado talvez não apareça imediatamente em uma consulta. Para entender o impacto da consistência posterior ao ler os valores de entidade, considere um cenário em que uma entidade, Player, possui uma propriedade, Score. Considere, por exemplo, que a Score inicial tem o valor de 100. Após um tempo, o valor de Score é atualizado para 200. Se uma consulta global for feita com a mesma entidade Player no resultado, é possível que o valor da propriedade Score da entidade retornada apareça inalterado, em 100.
Esse comportamento é causado pela replicação entre os servidores do Datastore. A replicação é gerenciada pelo Bigtable e pelo Megastore, as tecnologias subjacentes do Datastore. Consulte Recursos adicionais para saber mais sobre o Bigtable e o Megastore. A replicação é executada com o algoritmo Paxos, que aguarda de forma síncrona até que a maioria das réplicas tenha confirmado a solicitação de atualização. A réplica é atualizada com os dados da solicitação após um período. Esse período normalmente é curto, mas não há garantias quanto à duração real. A consulta pode ler os dados desatualizados caso seja executada antes da conclusão da atualização.
Em muitos casos, a atualização atingirá todas as réplicas muito rapidamente. No entanto, há diversos fatores que, quando combinados, podem aumentar o tempo necessário para atingir a consistência. Esses fatores incluem quaisquer incidentes que afetem todo o datacenter que envolvam a comutação de uma grande quantidade de servidores entre datacenters. Considerando a variação desses fatores, é impossível fornecer quaisquer requisitos de tempo definitivos para o estabelecimento da consistência completa.
O tempo necessário para uma consulta retornar o valor mais recente normalmente é bastante curto. Porém, em raras situações em que a latência de replicação aumenta, o tempo pode ser muito maior. Os aplicativos que usam consultas globais do Datastore devem ser cuidadosamente projetados para lidar com esses casos adequadamente.
A consistência eventual ao ler os valores de entidade pode ser evitada com o uso de uma consulta apenas de chaves, uma de ancestral ou a pesquisa por chave (o método "get()"). Discutiremos sobre esses diferentes tipos de consulta mais detalhadamente a seguir.
Consistência posterior na leitura de um índice
É possível que um índice ainda não esteja atualizado no momento da realização de uma consulta global. Isso significa que, mesmo que seja possível ler os valores de propriedade mais recentes das entidades, a "lista de entidades" incluída no resultado da consulta talvez seja filtrada com base nos valores de índice antigos.
Para entender o impacto da consistência posterior na leitura de um índice, imagine um cenário em que uma nova entidade, Player, é inserida no Datastore. A entidade tem uma propriedade, Score, com o valor inicial de 300. Imediatamente após a inserção, você executa uma consulta apenas de chaves para buscar todas as entidades com um valor de Score maior que 0. Seria esperado que a entidade Player, recentemente inserida, fosse exibida nos resultados da consulta. Em vez disso, talvez inesperadamente, você pode descobrir que a entidade Player não aparece nos resultados. Essa situação pode ocorrer quando a tabela de índice da propriedade Score ainda não tiver sido atualizada com o valor recém-inserido no momento da consulta.
Lembre-se de que todas as consultas no Datastore são executadas em tabelas de índice, e as atualizações nas tabelas de índice são assíncronas. Essencialmente, todas as atualizações de entidade são compostas por duas fases. Na primeira fase, a fase de realização, é realizada uma gravação no registro de transação. Na segunda fase, os dados são gravados e os índices são atualizados. Se a fase de realização for realizada corretamente, o sucesso da fase de gravação é garantido, mas não deve ocorrer imediatamente. Se você consultar uma entidade antes da atualização dos índices, poderá visualizar dados que ainda não estão consistentes.
Como resultado desse processo de duas fases, há um tempo de espera antes que as últimas atualizações das entidades se tornem visíveis em consultas globais. Assim como para a consistência posterior do valor de entidade, o tempo de espera normalmente é pequeno, mas pode ser maior (até mesmo vários minutos, em circunstâncias excepcionais).
O mesmo também pode acontecer após as atualizações. Por exemplo, suponha que você atualize uma entidade existente, Player, com um novo valor de propriedade Score de 0 e execute a mesma consulta imediatamente após. Seria esperado que a entidade não aparecesse nos resultados da consulta porque o novo valor 0 de Score iria excluí-la. No entanto, devido ao mesmo comportamento de atualização de índice assíncrono, a entidade ainda pode ser incluída no resultado.
É possível evitar a consistência posterior na leitura de um índice apenas com o uso de uma consulta de ancestral ou do método de pesquisa por chave. Uma consulta apenas de chaves não pode evitar esse comportamento.
Consistência forte na leitura dos valores de entidade e índices
No Datastore, apenas duas APIs oferecem uma visualização fortemente consistente para a leitura de valores de entidade e índices: (1) o método de pesquisa por chave e (2) a consulta de ancestral. Se a lógica do aplicativo exigir consistência forte, o desenvolvedor deverá usar um desses métodos para ler as entidades do Datastore.
O Datastore foi projetado especificamente para fornecer consistência forte nessas APIs. Ao chamar uma delas, o Datastore enviará todas as atualizações pendentes em uma das tabelas de réplica e índice e executará a pesquisa ou consulta de ancestral. Dessa forma, o valor mais recente da entidade, baseado na tabela de índice atualizada, sempre será retornado com os valores baseados nas últimas atualizações.
A chamada da pesquisa por chave, em comparação com as consultas, retorna apenas uma entidade ou um conjunto de entidades especificado por uma chave ou conjunto de chaves. Isso significa que uma consulta de ancestral é a única maneira no Datastore de satisfazer o requisito de consistência forte junto com um requisito de filtragem. No entanto, as consultas de ancestral não funcionam sem a especificação de um grupo de entidades.
Consulta de ancestral e grupo de entidades
Conforme discutido no início deste documento, um dos benefícios do Datastore é que os desenvolvedores podem encontrar o equilíbrio ideal entre consistência forte e posterior. No Datastore, um grupo de entidades é uma unidade com consistência forte, transacionalidade e localidade. Ao utilizar os grupos de entidades, os desenvolvedores podem definir o escopo da consistência forte entre as entidades em um aplicativo. Dessa maneira, o aplicativo pode manter a consistência dentro do grupo de entidades, ao mesmo tempo que atinge alta escalabilidade, disponibilidade e desempenho como um sistema completo.
Um grupo de entidades é uma hierarquia composta por uma entidade raiz e as filhas ou sucessoras dessa entidade.[1] Para criar um grupo de entidades, o desenvolvedor especifica um caminho de ancestral, que é, basicamente, uma série de chaves mãe que atribuem prefixo à chave filha. O conceito do grupo de entidades é ilustrado na Figura 3. Nesse caso, a entidade raiz com a chave "ateam" tem duas filhas com as chaves "ateam/098745" e "ateam/098746".
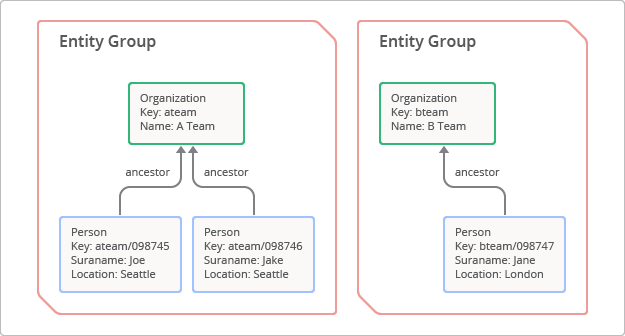
Dentro do grupo de entidades, estas características são garantidas:
-
Consistência forte
- Uma consulta de ancestral no grupo de entidades retornará um resultado fortemente consistente. Dessa forma, ela reflete os valores de entidade mais recentes filtrados pelo último estado de índice.
-
Transacionalidade
- Ao demarcar uma transação de maneira programática, o grupo de entidades fornece as características de ACID (atomicidade, consistência, isolamento e durabilidade) na transação.
-
Localidade
- As entidades de um grupo de entidades serão armazenadas em lugares fisicamente próximos nos servidores do Datastore, já que todas as entidades são classificadas e armazenadas pela ordem lexicográfica das chaves. Assim, uma consulta de ancestral pode analisar rapidamente o grupo de entidades com o mínimo de E/S.
Uma consulta de ancestral é uma forma especial de consulta executada apenas em relação a um grupo de entidades especificado. Ela é feita com consistência forte. Nos bastidores, o Datastore garante que todas as atualizações de índice e replicações pendentes sejam aplicadas antes da execução da consulta.
Exemplo de consulta de ancestral
Nesta seção, descrevemos como usar os grupos de entidades e as consultas de ancestral na prática. No exemplo a seguir, examinamos o problema do gerenciamento de registros de dados para pessoas. Suponha que temos um código que adiciona uma entidade de um tipo específico seguido imediatamente por uma consulta sobre aquele tipo. Esse conceito é demonstrado pelo código Python de exemplo a seguir.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
O problema com esse código é que, na maioria dos casos, a consulta não retornará a entidade adicionada na instrução acima dele. Visto que a consulta está na linha imediatamente após a inserção, o índice não estará atualizado quando a consulta for executada. No entanto, há também um problema com a validade desse caso de uso: realmente existe a necessidade de retornar uma lista de todas as pessoas em uma página sem nenhum contexto? E se houver um milhão de pessoas? A página demoraria muito para retornar.
A natureza do caso de uso sugere que devemos fornecer contexto para restringir a consulta. Neste exemplo, o contexto que usaremos será a organização. Com isso, poderemos usar a organização como o grupo de entidades e executar uma consulta de ancestral, que resolve nosso problema de consistência. Isso é demonstrado pelo código Python abaixo.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Dessa vez, com o ancestral org especificado em GqlQuery, a consulta retorna a entidade recém-inserida. O exemplo poderia ser estendido para detalhar uma pessoa específica consultando o nome dela com o ancestral como parte da consulta. Ou isso também poderia ter sido feito salvando a chave da entidade e usando-a para o detalhamento com uma pesquisa por chave.
Como manter a consistência entre o Memcache e o Datastore
Os grupos de entidades também podem ser usados como uma unidade para manter a consistência entre as entradas do Memcache e as entidades do Datastore. Por exemplo, considere um cenário em que você conta o número de pessoas em cada equipe e armazena no Memcache. Para garantir que os dados em cache sejam consistentes com os valores mais recentes no Datastore, você pode usar metadados do grupo de entidades. Os metadados retornam o número da versão mais recente do grupo de entidades especificado. É possível comparar o número da versão com o número armazenado no Memcache. Ao usar esse método, você detecta uma alteração em qualquer uma das entidades em todo o grupo de entidades fazendo a leitura de um conjunto de metadados, em vez de verificar todas as entidades individuais no grupo.
Limitações do grupo de entidades e da consulta de ancestral
A abordagem do uso de grupos de entidades e consultas de ancestral não é uma solução milagrosa. Há dois desafios na prática que dificultam a aplicação da técnica em geral, conforme indicado a seguir.
- Há um limite de uma atualização por segundo de gravação para cada grupo de entidades.
- A relação do grupo de entidades não pode ser alterada após a criação da entidade.
Limite de gravação
Um desafio considerável é projetar o sistema para conter o número de atualizações ou transações em cada grupo de entidades. O limite aceito é de uma atualização por segundo, por grupo de entidades.[2] Se o número de atualizações precisar ultrapassar esse limite, o grupo de entidades talvez represente um gargalo de desempenho.
No exemplo acima, é possível que cada organização precise atualizar o registro de uma pessoa da organização. Considere um cenário em que há 1.000 pessoas em "ateam" e cada uma delas pode realizar uma atualização por segundo em qualquer uma das propriedades. Como resultado, podem haver até 1.000 atualizações por segundo em todo o grupo de entidades, algo que não seria possível em virtude do limite de atualizações. Isso ilustra que é importante escolher um design de grupo de entidades adequado que considere os requisitos de desempenho. Esse é um dos desafios de encontrar o equilíbrio ideal entre a consistência forte e a posterior,
Imutabilidade das relações do grupo de entidades
O segundo desafio é a imutabilidade das relações do grupo de entidades. A relação do grupo de entidades é criada estaticamente com base na nomenclatura da chave. Ela não pode ser alterada após a criação da entidade. A única opção disponível para alterar a relação é excluir as entidades em um grupo de entidades e criá-las novamente. Esse desafio impede o uso de grupos de entidades para definir escopos ad hoc para consistência ou transacionalidade de maneira dinâmica. Em vez disso, o escopo de consistência e transacionalidade são intimamente ligados ao grupo de entidades estático definido no momento do design.
Por exemplo, considere um cenário em que você quer implementar uma transferência eletrônica entre duas contas bancárias. Esse cenário de negócios requer consistência forte e transacionalidade. Porém, não é possível reunir as duas contas em um grupo de entidades de última hora ou se basear em uma mãe global. Esse grupo de entidades criaria um afunilamento para todo o sistema que impediria a execução de outras solicitações de transferência eletrônica. Portanto, não é possível usar os grupos de entidades dessa maneira.
Existe uma alternativa para implementar uma transferência eletrônica com escalabilidade eficiente e boa disponibilidade. Em vez de colocar todas as contas em um único grupo de entidades, você pode criar um grupo de entidades para cada conta. Ao fazer isso, você pode usar transações para garantir atualizações ACID para as duas contas bancárias. As transações são um recurso do Datastore que permite criar conjuntos de operações com características de ACID para até vinte e cinco grupos de entidades. Observe que, em uma transação, você precisa usar consultas fortemente consistentes, como pesquisas por consultas de chave e de ancestral. Para saber mais sobre restrições de transações, veja Transações e grupos de entidades.
Alternativas às consultas de ancestral
Se você já tiver um aplicativo com um grande número de entidades armazenadas no Datastore, pode ser difícil incorporar grupos de entidades depois em um exercício de refatoração. Seria necessário excluir todas as entidades e adicioná-las a uma relação de grupo de entidades. Portanto, na modelagem de dados do Datastore, é importante tomar uma decisão sobre o design do grupo de entidades na fase inicial do design do aplicativo. Caso contrário, é possível que você fique limitado na refatoração a outras alternativas para atingir um determinado nível de consistência, como uma consulta apenas de chaves seguida por uma pesquisa por chave ou usando o Memcache.
Consulta global apenas de chaves seguida pela pesquisa por chave
Uma consulta global apenas de chaves é um tipo especial de consulta global que retorna apenas chaves, sem os valores de propriedade das entidades. Como os valores retornados são apenas chaves, a consulta não envolve um valor de entidade com um possível problema de consistência. A combinação da consulta global apenas de chaves com o método de pesquisa lê os valores de entidade mais recentes. Porém, a consulta global apenas de chaves não é capaz de excluir a possibilidade do índice ainda não estar consistente no momento da consulta, o que pode fazer com que a entidade não seja recuperada de nenhuma forma. O resultado da consulta poderia ser gerado com base na filtragem de valores de índice antigos. Em resumo, o desenvolvedor pode usar a consulta global apenas de chaves seguida pela pesquisa por chave quando o requisito de um aplicativo permitir que o valor de índice ainda não seja consistente no momento da pesquisa.
Como usar o Memcache
O serviço do Memcache é volátil, mas fortemente consistente. Portanto, ao combinar as pesquisas do Memcache e as consultas do Datastore, é possível criar um sistema que minimizará os problemas de consistência na maioria das vezes.
Por exemplo, considere o cenário de um aplicativo de jogo que mantém uma lista de entidades Player, cada uma com a pontuação maior que zero.
- Para solicitações de inserção ou atualização, aplique-as à lista de entidades Player no Memcache e no Datastore.
- Para solicitações de consulta, leia a lista de entidades Player do Memcache e execute uma consulta apenas de chaves no Datastore quando a lista não estiver presente no Memcache.
A lista retornada será consistente sempre que a armazenada em cache estiver presente no Memcache. Se a entrada tiver sido removida ou o serviço de Memcache estiver temporariamente indisponível, talvez o sistema precise ler o valor de uma consulta do Datastore que poderia retornar um resultado inconsistente. Essa técnica pode ser usada em qualquer aplicativo com tolerância a um pouco de inconsistência.
Existem algumas práticas recomendadas para uso do Memcache, como uma camada de armazenamento em cache para o Datastore:
- Detectar exceções e erros do Memcache para manter a consistência entre o valor do Memcache e do Datastore. Se você receber uma exceção ao atualizar a entrada no Memcache, invalide a entrada antiga nele. Caso contrário, pode haver valores diferentes para uma entidade (um valor antigo no Memcache e um valor novo no Datastore).
- Definir um período de validade nas entradas do Memcache. É recomendável definir períodos curtos para a validade de cada entrada para minimizar a possibilidade de inconsistência no caso de exceções do Memcache.
- Usar o recurso de comparar e definir ao atualizar as entradas para o controle de simultaneidade. Isso ajudará a garantir que atualizações simultâneas na mesma entrada não interfiram umas nas outras.
Migração gradual para grupos de entidades
As sugestões apresentadas na seção anterior apenas diminuem a possibilidade do comportamento inconsistente. Quando a consistência forte for necessária, é melhor projetar o aplicativo com base em grupos de entidades e consultas de ancestral. No entanto, pode não ser possível migrar um aplicativo existente, o que pode incluir a mudança da lógica do aplicativo e do modelo de dados existente de consultas globais para consultas de ancestral. Uma maneira de conseguir isso é adotar um processo de transição gradual, como este:
- Identificar e priorizar as funções do aplicativo que exijam consistência forte.
- Escrever a nova lógica para as funções insert() ou update() usando grupos de entidades juntamente com a lógica existente, em vez de substitui-la. Dessa forma, todas as novas inserções ou atualizações nos novos grupos de entidades e nas entidades antigas podem ser tratadas pela função adequada.
- Modificar a lógica existente para as funções de consulta ou leitura. As consultas de ancestral são executadas primeiro se houver um novo grupo de entidades para a solicitação. Executar a consulta global antiga como a lógica substitua se o grupo de entidades não existir.
Essa estratégia permite a migração gradual de um modelo de dados existente para um novo modelo com base em grupos de entidades que minimiza o risco de problemas causados pela consistência eventual. Na prática, essa abordagem depende dos requisitos e casos de uso específicos para sua aplicação a um sistema real.
Substituição pelo modo degradado
Atualmente, é difícil detectar uma situação de maneira programática quando um aplicativo apresenta consistência deteriorada. No entanto, se você usar outros meios para determinar quando um aplicativo apresenta consistência deteriorada, será possível implementar um modo degradado que pode ser ativado e desativado para acionar algumas áreas da lógica do aplicativo que exijam consistência forte. Por exemplo, em vez de mostrar um resultado de consulta inconsistente em uma tela de relatório de faturamento, é possível mostrar uma mensagem de manutenção nessa tela específica. Dessa forma, os outros serviços do aplicativo podem continuar em funcionamento e, assim, reduzir o impacto na experiência do usuário.
Como minimizar o tempo para atingir a consistência completa
Em um aplicativo grande com milhões de usuários ou terabytes de entidades do Datastore, o uso inadequado do Datastore pode levar a uma consistência deteriorada. Essas práticas incluem:
- numeração sequencial em chaves de entidade;
- muitos índices.
Essas práticas não afetam aplicativos pequenos. Porém, uma vez que o aplicativo fique muito grande, essas práticas aumentam a possibilidade de tempos maiores necessários para a consistência. Portanto, é melhor evitá-las nos estágios iniciais do design do aplicativo.
Antipadrão 1: numeração sequencial de chaves de entidade
Antes do lançamento do SDK 1.8.1 do App Engine, o Datastore usava uma sequência de códigos inteiros pequenos com padrões geralmente consecutivos como os nomes de chaves padrão gerados automaticamente. Em alguns documentos, isso é chamado de "política legada" para a criação de quaisquer entidades sem um aplicativo especificado no nome da chave. Essa política legada gera nomes de chave de entidade com numeração sequencial, como 1000, 1001, 1002, por exemplo. No entanto, conforme discutimos anteriormente, o Datastore armazena entidades pela ordem lexicográfica dos nomes das chaves, de modo que essas entidades estarão muito provavelmente armazenadas nos mesmos servidores do Datastore. Se um aplicativo atrair um tráfego muito alto, essa numeração sequencial poderá gerar uma concentração de operações em um servidor específico, o que talvez resulte em uma latência maior para a consistência.
No SDK 1.8.1 do App Engine, o Datastore introduziu um novo método de numeração de ID com uma política padrão que usa IDs dispersos (veja a documentação de referência). Essa política padrão gera uma sequência aleatória de IDs com até 16 dígitos que são distribuídas de maneira quase uniforme. Ao usar essa política, é provável que o tráfego do aplicativo grande seja mais bem distribuído entre um conjunto de servidores do Datastore com tempo reduzido para consistência. A menos que seu aplicativo exija especificamente a compatibilidade com a política legada, a política padrão é recomendada.
Se você definir explicitamente nomes de chave nas entidades, deverá projetar o esquema de nomenclatura para acessar as entidades de maneira uniforme em todo intervalo de nomes de chave. Em outras palavras, não concentre o acesso em um intervalo específico, uma vez que a classificação é feita de acordo com a ordem lexicográfica dos nomes das chaves. Caso contrário, pode ocorrer o mesmo problema apresentado pela numeração sequencial.
Para entender a distribuição irregular do acesso no keyspace, considere um exemplo em que as entidades são criadas com nomes de chave sequenciais, conforme mostrado neste código:
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
O padrão de acesso do aplicativo pode criar um "hot spot" em um determinado intervalo de nomes de chave, como no caso da concentração do acesso nas entidades "Person" recém-criadas. Nesse caso, todas as chaves acessadas com frequência terão IDs maiores. A carga poderá, então, ser concentrada em um servidor específico do Datastore.
De maneira alternativa, para entender a distribuição uniforme no keyspace, considere o uso de strings longas e aleatórias para os nomes de chave. Isso é ilustrado no exemplo abaixo:
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
Agora as entidades "Person" recém-criadas estão dispersas no keyspace e em diversos servidores. Isso pressupõe que há um número suficientemente grande de entidades "Person".
Antipadrão 2: muitos índices
No Datastore, uma atualização em uma entidade levará a atualizações em todos os índices definidos para esse tipo de entidade. Se um aplicativo usar diversos índices personalizados, uma atualização poderá envolver dezenas, centenas ou até mesmo milhares de atualizações nas tabelas de índice. Em um aplicativo grande, o uso excessivo de índices personalizados pode resultar em uma carga maior no servidor, além de aumentar a latência para atingir a consistência.
Na maioria dos casos, os índices personalizados são adicionados para permitir a compatibilidade com requisitos, como tarefas de análise de dados, solução de problemas e suporte ao cliente. O BigQuery é um mecanismo de consulta imensamente escalonável que pode fazer consultas específicas em grandes conjuntos de dados sem os índices criados previamente. Ele é mais adequado para casos de uso como suporte ao cliente, solução de problemas ou análises de dados que exigem consultas complexas do que o Datastore.
Uma prática é combinar o Datastore e o BigQuery para atender a diferentes requisitos comerciais. Use o Datastore no processamento transacional on-line (OLTP, na sigla em inglês) necessário para a lógica central do aplicativo e o BigQuery no processamento analítico on-line (OLAP, na sigla em inglês) para operações de back-end. Pode ser necessário implementar um fluxo contínuo de exportação de dados do Datastore para o BigQuery para mover os dados necessários para essas consultas.
Além de uma implementação alternativa para os índices personalizados, outra recomendação é especificar explicitamente as propriedades não indexadas. Consulte Tipos de valor e propriedades. Por padrão, o Datastore criará uma tabela de índice diferente para cada propriedade indexável de um tipo de entidade. Se você tiver 100 propriedades de um tipo, haverá 100 tabelas de índice para ele, além de 100 atualizações adicionais em cada atualização de uma entidade. Dessa forma, é uma prática recomendada definir as propriedades não indexadas onde for possível, caso elas não sejam necessárias para uma condição de consulta.
Além de reduzir a possibilidade de aumentar os tempos de consistência, essas otimizações de índice podem resultar em uma grande redução dos custos de armazenamento do Datastore em um aplicativo grande que use os índices com frequência.
Conclusão
A consistência eventual é um elemento essencial dos bancos de dados não relacionais que permite que os desenvolvedores encontrem o equilíbrio ideal entre a escalonabilidade, o desempenho e a consistência. É importante entender como lidar com o equilíbrio entre a consistência forte e a posterior para projetar um modelo de dados ideal para seu aplicativo. No Datastore, o uso de grupos de entidades e consultas de ancestral é a melhor maneira de garantir consistência forte em um escopo de entidades. Caso não seja possível incorporar grupos de entidades com seu aplicativo em virtude das limitações descritas anteriormente, considere outras opções, como o uso de consultas apenas de chaves ou do Memcache. Para aplicativos grandes, aplique as práticas recomendadas, como o uso de códigos dispersos e indexação reduzida, para diminuir o tempo necessário para atingir a consistência. Também pode ser importante combinar o Datastore com o BigQuery para atender aos requisitos comerciais em consultas complexas e reduzir ao máximo o uso de índices do Datastore.
Outros recursos
Estes recursos oferecem mais informações sobre os tópicos discutidos neste documento:
- Google App Engine: armazenamento de dados
- Visão geral do Datastore
- Blog do Google Cloud Platform
- Cloud SQL
- Como usar o App Engine em Python com o Cloud SQL
- Bigtable: um sistema de armazenamento distribuído para dados estruturados
- Lançamento do SDK do App Engine 1.5.2
- Megastore: oferta de armazenamento escalonável e altamente disponível para serviços interativos
[1] Um grupo de entidades pode ser formado até mesmo especificando apenas uma chave da entidade pai ou raiz, sem armazenar as entidades pai ou raiz reais, porque todas as funções do grupo de entidades são implementadas com base nas relações entre as chaves.
[2] O limite aceito é uma atualização por segundo por grupo de entidades fora das transações ou uma transação por segundo por grupo de entidades. Ao agregar várias atualizações a uma transação, você ficará limitado ao tamanho máximo de transação de 10 MB e à taxa máxima de gravação do servidor do Datastore.