Équilibrer la cohérence forte et la cohérence à terme avec Datastore
Assurer une expérience utilisateur stable et tirer parti du modèle de cohérence à terme pour évoluer vers des ensembles de données volumineux
Cet article explique comment obtenir une cohérence forte pour proposer une expérience utilisateur positive, tout en exploitant le modèle de cohérence à terme de Datastore pour gérer de grandes quantités de données et d'utilisateurs.
Cet article s'adresse aux ingénieurs et architectes logiciels désireux de développer des solutions sur Datastore. Pour aider les utilisateurs qui sont plus habitués aux bases de données relationnelles qu'aux systèmes non relationnels, tels que Datastore, il sera également fait allusion aux concepts analogues dans les bases de données relationnelles. Dans le présent document, nous partons du principe que vous connaissez les rudiments de Datastore. La façon la plus simple de se familiariser avec Datastore consiste à utiliser Google App Engine dans l'un des langages acceptés. Si vous n'avez encore jamais utilisé App Engine, nous vous recommandons de consulter au préalable le guide de démarrage et la section Stocker des données pour l'un de ces langages. Bien que le langage Python soit utilisé pour les exemples de fragments de code, aucune compétence spécialisée dans ce domaine n'est requise pour suivre ce document.
Remarque : Les extraits de code illustrés dans cet article utilisent la bibliothèque cliente DB Python pour Datastore, qui n'est plus recommandée. Les développeurs qui créent des applications sont vivement encouragés à utiliser la bibliothèque cliente NDB, qui présente plusieurs avantages par rapport à cette bibliothèque cliente, tels que la mise en cache automatique des entités via l'API Memcache. Si vous utilisez actuellement l'ancienne bibliothèque cliente DB, consultez le guide de migration de DB vers NDB.
Contenu
NoSQL et cohérence à terme
Cohérence à terme dans Datastore
Requête ascendante et groupe d'entités
Limitations des groupes d'entités et des requêtes ascendantes
Alternatives aux requêtes ascendantes
Obtention plus rapide d'une cohérence totale
Conclusion
Autres ressources
NoSQL et cohérence à terme
Depuis quelques années, les bases de données non relationnelles, connues également sous le nom de bases de données NoSQL, se posent comme une alternative crédible aux bases de données relationnelles. Datastore est l'une des bases de données non relationnelles les plus utilisées sur le marché. En 2013, Datastore a traité 4,5 milliers de milliards de transactions par mois (article de blog Google Cloud Platform). Cette solution permet aux développeurs de stocker des données et d'y accéder en toute simplicité. De par son caractère flexible, le schéma tend naturellement vers les langages de script et orientés objet. Datastore propose également plusieurs fonctionnalités que les bases de données relationnelles ne peuvent pas fournir de manière optimale, telles que des performances élevées à très grande échelle et une haute fiabilité.
Les développeurs davantage habitués aux bases de données relationnelles peuvent éprouver des difficultés à concevoir un système qui tire parti des bases de données non relationnelles, dans la mesure où certaines caractéristiques et pratiques inhérentes à ces dernières leur sont peut-être inconnues. Bien que Datastore propose un modèle de programmation simple, il est important de connaître ces caractéristiques. La cohérence à terme en fait partie et la programmation de cette cohérence est le thème central de cet article.
Qu'est-ce que la cohérence à terme ?
La cohérence à terme est une garantie théorique que, si aucune nouvelle mise à jour d'une entité n'est effectuée, toutes les lectures de l'entité renverront à la fin la dernière valeur mise à jour. Le service DNS (Domain Name System) Internet est un exemple bien connu de système présentant un modèle de cohérence à terme. Les serveurs DNS n'affichent pas nécessairement les valeurs les plus récentes, mais plutôt les valeurs mises en cache et répliquées dans de nombreux répertoires sur Internet. La réplication des valeurs modifiées sur l'ensemble des clients et serveurs DNS prend du temps Cependant, DNS est un système très populaire qui est devenu l'un des piliers du réseau Internet. Son évolutivité élevée et son extrême évolutivité permettent d'effectuer des recherches de noms sur des centaines de millions d'appareils connectés à Internet.
La figure 1 illustre le concept de réplication avec une cohérence à terme. Comme vous pouvez le voir sur le schéma, bien que des répliques soient toujours accessibles en lecture, il se peut que certaines d'entre elles soient incohérentes avec la dernière écriture sur le nœud d'origine, à un moment donné. Sur ce schéma, le nœud A est le nœud d'origine, tandis que les nœuds B et C sont des répliques.

Les bases de données relationnelles traditionnelles ont quant à elles été conçues sur la base du concept de cohérence forte, désigné également sous le nom de cohérence immédiate. Cela signifie que toutes les données consultées immédiatement après une mise à jour seront cohérentes pour l'ensemble des observateurs de l'entité. Cette caractéristique a constitué un postulat de base pour de nombreux développeurs qui utilisent des bases de données relationnelles. Cependant, pour bénéficier d'une cohérence forte, les développeurs doivent trouver un compromis au niveau de l'évolutivité et des performances de leur application. Autrement dit, les données doivent être verrouillées au cours de la mise à jour ou de la réplication afin de s'assurer qu'aucun autre processus ne traite les mêmes données.
La figure 2 illustre une vue conceptuelle de la topologie de déploiement et du processus de réplication avec une cohérence forte. Comme vous pouvez le voir sur ce schéma, les valeurs des répliques sont toujours cohérentes avec le nœud d'origine, mais elles ne sont pas accessibles tant que la mise à jour n'est pas terminée.
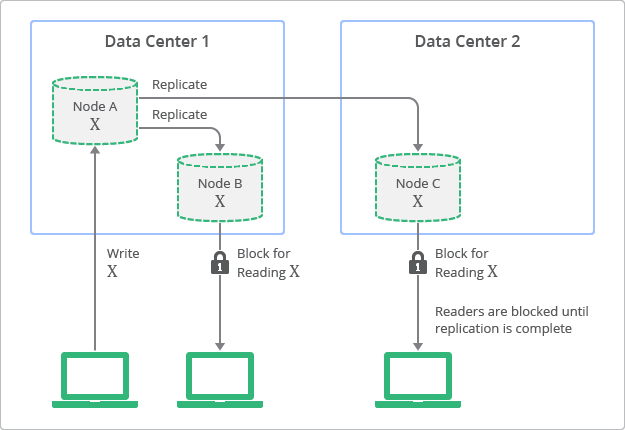
Équilibrer la cohérence forte et la cohérence à terme
Au cours des dernières années, les bases de données non relationnelles n'ont cessé de gagner en popularité, en particulier pour les applications Web qui nécessitent une évolutivité et des performances élevées avec une haute disponibilité. Ces bases de données permettent aux développeurs de choisir le parfait équilibre entre cohérence forte et cohérence à terme pour chaque application. Ils peuvent ainsi combiner les points forts de ces deux modèles. Par exemple, "savoir quels membres de votre liste d'amis sont en ligne à un moment donné" ou "savoir combien d'utilisateurs ont attribué +1 à votre message" sont des cas d'utilisation pour lesquels une cohérence forte n'est pas nécessaire. Vous pouvez alors tirer parti de la cohérence à terme pour garantir une évolutivité et des performances élevées. L'utilisation de la cohérence forte est nécessaire, par exemple, pour "déterminer si un utilisateur a terminé ou non le processus de facturation" ou pour connaître "le nombre de points empochés par un joueur au cours d'une bataille".
Pour généraliser les exemples ci-dessus, les scénarios dans lesquels de très nombreuses entités sont utilisées semblent généralement indiquer que la cohérence à terme est le modèle idéal. Si une requête renvoie un très grand nombre de résultats, il se peut que l'inclusion ou l'exclusion d'entités spécifiques n'ait aucune incidence sur l'expérience utilisateur. En revanche, les scénarios avec un petit nombre d'entités et un contexte étroit semblent indiquer qu'une cohérence forte est requise. Le confort d'utilisation s'en trouvera affecté, dans la mesure où le contexte indiquera aux utilisateurs les entités qui doivent être incluses ou exclues.
Pour toutes ces raisons, il est important que les développeurs comprennent les caractéristiques non relationnelles de Datastore. Dans les sections suivantes, nous examinerons comment combiner les modèles de cohérence à terme et de cohérence forte pour créer une application évolutive, à haute disponibilité et très performante, tout en conservant une expérience utilisateur stable.
Cohérence à terme dans Datastore
Il convient de sélectionner l'API appropriée lorsqu'une vue de données avec une cohérence forte est nécessaire. Le tableau 1 illustre les différentes variétés d'API de requête Datastore, ainsi que les modèles de cohérence correspondants.
|
API Datastore |
Lecture de la valeur d'entité |
Lecture de l'index |
|---|---|---|
|
Cohérence à terme |
Cohérence à terme |
|
|
ND |
Cohérence à terme |
|
|
Cohérence forte |
Cohérence forte |
|
|
Recherche par clé (get ()) |
Cohérence forte |
ND |
Les requêtes Datastore sans ascendant sont connues sous le nom de requêtes globales. Elles sont conçues pour fonctionner avec un modèle de cohérence à terme. Cela ne garantit pas une cohérence forte. Une requête globale keys-only est une requête globale qui ne renvoie que les clés d'entités correspondant à la requête, et non les valeurs d'attribut des entités. Une requête ascendante couvre la requête sur la base d'une entité ascendante. Les sections suivantes décrivent chaque modèle de cohérence de manière plus détaillée.
Cohérence à terme lors de la lecture de valeurs d'entité
À l'exception des requêtes ascendantes, il se peut qu'une valeur d'entité mise à jour ne soit pas visible immédiatement lors de l'exécution d'une requête. Pour bien comprendre l'incidence de la cohérence à terme lors de la lecture de valeurs d'entité, "Joueur" possède une propriété "Score". Supposons, par exemple, que la valeur de la propriété "Score" initiale soit égale à 100. Après quelque temps, la valeur "Score" passe à 200. Si une requête globale est exécutée et que le résultat inclut la même entité "Joueur", il est possible que la valeur de la propriété "Score" de l'entité renvoyée soit inchangée (100).
Ce comportement est dû à la réplication entre les serveurs Datastore. La réplication est gérée par Bigtable et Megastore, les technologies sous-jacentes de Datastore (pour en savoir plus sur Bigtable et Megastore, consultez la section Autres ressources). La réplication est exécutée avec l'algorithme Paxos, lequel attend, de manière asynchrone, qu'une majorité des instances dupliquées aient accusé réception de la requête de mise à jour. L'instance dupliquée est ensuite mise à jour avec les données de la requête après une certaine période. Il s'agit généralement d'une période assez courte, mais il n'y a aucune garantie quant à sa durée réelle. Il se peut qu'une requête lise les données non actualisées si elle est exécutée avant la fin de la mise à jour.
Dans la majorité des cas, la mise à jour atteint toutes les répliques très rapidement. Cependant, plusieurs facteurs, lorsqu'ils sont combinés, sont susceptibles d'allonger la période nécessaire pour obtenir une cohérence. Il s'agit notamment d'incidents à l'échelle d'un centre de données qui impliquent le basculement d'un grand nombre de serveurs entre les centres de données. Ces facteurs étant variables, il est impossible de spécifier formellement le temps nécessaire à l'établissement d'une cohérence complète.
En règle générale, une requête renvoie la dernière valeur dans un délai très court. Cependant, ce délai peut s'avérer beaucoup plus long dans les rares cas où la latence de réplication augmente. Les applications qui utilisent des requêtes Datastore globales doivent faire l'objet d'une conception soignée afin de tenir compte de ces cas de figure.
Il est possible d'éviter la cohérence à terme lors de la lecture de valeurs d'entité en utilisant une requête de type "keys-only", une requête ascendante ou une recherche par clé (méthode get()). Les différents types de requêtes feront l'objet d'une description plus détaillée ci-après.
Cohérence à terme lors de la lecture d'un index
Il se peut qu'un index n'ait pas encore été mis à jour lorsqu'une requête globale est exécutée. En d'autres termes, bien que vous soyez peut-être en mesure de lire les valeurs de propriété les plus récentes des entités, il se peut que la "liste des entités" incluse dans les résultats de la requête soit filtrée sur la base d'anciennes valeurs d'index.
Pour bien comprendre l'incidence de la cohérence à terme lors de la lecture d'un index, imaginez un scénario dans lequel une nouvelle entité "Joueur" est insérée dans Datastore. L'entité possède une propriété "Score" dont la valeur initiale est définie sur 300. Immédiatement après l'insertion, vous exécutez une requête "keys-only" pour récupérer toutes les entités dont la valeur "Score" est supérieure à 0. Vous vous attendez alors à ce que l'entité "Joueur" récemment insérée apparaisse dans les résultats de la requête. Cependant, elle n'apparaît pas. Cela peut se produire lorsque la table d'index de la propriété "Score" n'est pas mise à jour avec la nouvelle valeur insérée au moment de l'exécution de la requête.
Pour rappel, toutes les requêtes de Datastore sont exécutées par rapport à des tables d'index et, pourtant, les mises à jour de ces tables sont asynchrones. Chaque mise à jour d'entité se compose essentiellement de deux phases. Au cours de la première phase, qui est celle de validation, une écriture est effectuée dans le journal des transactions. Au cours de la deuxième phase, les données sont écrites et les index sont mis à jour. Si la phase de validation aboutit, la réussite de la phase d'écriture est également garantie, même si cela peut prendre un certain temps. Si vous interrogez une entité avant la mise à jour des index, il se peut que les données consultées ne soient pas encore cohérentes.
Compte tenu de ce processus en deux phases, les mises à jour les plus récentes des entités ne sont pas immédiatement visibles dans les requêtes globales. Comme c'est le cas pour la cohérence à terme de la valeur d'entité, le délai est généralement faible. Cependant, il peut atteindre quelques minutes, voire davantage, dans des circonstances exceptionnelles.
Cela peut également se produire après des mises à jour. Supposons, par exemple, que vous mettiez à jour une entité "Joueur" avec une nouvelle valeur de propriété "Score" de 0, et que vous exécutiez la même requête immédiatement après. Vous vous attendez, dans ce cas, à ce que l'entité n'apparaisse pas dans les résultats de la requête, car elle est exclue par la nouvelle valeur "Score" de 0. Cependant, compte tenu du comportement de mise à jour asynchrone identique à celui des index, il est possible que l'entité soit reprise dans les résultats.
Lors de la lecture d'un index, il n'est possible d'éviter la cohérence à terme qu'en utilisant une requête ascendante ou la méthode de recherche par clé. Ce comportement ne peut pas être évité avec une requête de type "keys-only".
Cohérence forte lors de la lecture d'index et de valeurs d'entité
Dans Datastore, deux API seulement fournissent une vue fortement cohérente pour la lecture d'index et de valeurs d'entité : (1) la méthode de recherche par clé et (2) la requête ascendante. Si la logique d'application exige une cohérence forte, le développeur doit utiliser l'une de ces méthodes pour lire des entités à partir de Datastore.
Datastore est un service conçu spécialement pour fournir une cohérence forte sur ces API. Lorsque l'une d'elles est appelée, Datastore efface toutes les mises à jour en attente sur l'une des instances dupliquées et des tables d'index, puis exécute la recherche ou la requête ascendante. Par conséquent, la dernière valeur d'entité, sur la base de la table d'index mise à jour, est toujours renvoyée avec des valeurs basées sur les mises à jour les plus récentes.
Contrairement aux requêtes, l'appel de recherche par clé ne renvoie qu'une seule entité ou un ensemble d'entités spécifié par une clé ou un jeu de clés. Cela signifie que la requête ascendante est le seul moyen disponible dans Datastore pour satisfaire aux exigences en matière de cohérence forte et de filtrage. Cependant, les requêtes ascendantes ne fonctionnent pas si aucun groupe d'entités n'est spécifié.
Requête ascendante et groupe d'entités
Comme indiqué au début de cet article, l'un des avantages de Datastore est de permettre aux développeurs de trouver un équilibre optimal entre une cohérence forte et une cohérence à terme. Dans Datastore, un groupe d'entités est une unité qui se caractérise par une cohérence forte, par sa nature transactionnelle et par sa localité. En utilisant des groupes d'entités, les développeurs peuvent définir le champ d'application de la cohérence forte entre les entités d'une application. L'application peut ainsi maintenir la cohérence au sein du groupe d'entités, tout en garantissant une évolutivité, une disponibilité et des performances élevées en tant que système complet.
Un groupe d'entités est une hiérarchie formée par une entité racine et ses enfants ou descendants.[1] Pour créer un groupe d'entités, un développeur définit un chemin ascendant qui se compose essentiellement d'une série de clés parentes qui préfixent la clé enfant. La notion de groupe d'entités est illustrée à la figure 3. Dans ce cas, l'entité racine avec la clé "ateam" a deux enfants, avec les touches "ateam/098745" et "ateam/098746".
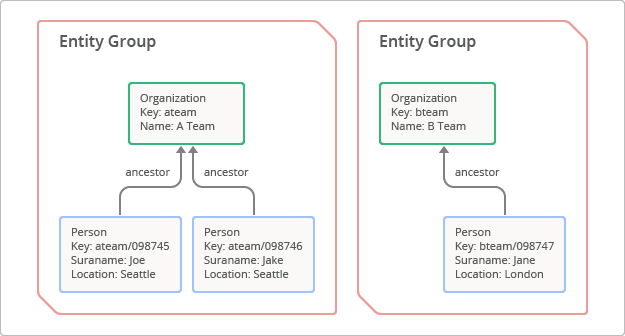
Les caractéristiques suivantes sont garanties à l'intérieur du groupe d'entités :
- Cohérence forte
- Une requête ascendante exécutée sur le groupe d'entités renverra un résultat fortement cohérent. De cette manière, il affiche les valeurs d'entité les plus récentes, filtrées selon l'état d'index le plus récent.
- Transactionnalité
- En délimitant une transaction de manière automatisée, le groupe fournit des caractéristiques ACID (atomicité, cohérence, isolation et durabilité) dans la transaction.
- Localité
- Les entités d'un groupe sont stockées à des emplacements physiquement proches sur des serveurs Datastore, dans la mesure où toutes les entités sont triées et stockées selon l'ordre lexicographique des clés. Cela permet à une requête ascendante d'analyser plus rapidement le groupe d'entités avec un nombre minimum d'E/S.
Une requête ascendante est une forme particulière de requête qui s'exécute seulement par rapport à un groupe d'entités spécifié, avec une cohérence forte. En arrière-plan, Datastore vérifie que toutes les réplications et mises à jour d'index en attente sont appliquées avant d'exécuter la requête.
Exemple de requête ascendante
Cette section décrit l'utilisation pratique des groupes d'entités et des requêtes ascendantes. Dans l'exemple suivant, nous examinerons le problème de gestion des enregistrements de données pour des personnes. Supposons que vous ayez rédigé du code qui ajoute une entité d'un type spécifique, suivi immédiatement d'une requête réalisée sur ce type. Ce concept est illustré par l'exemple du code Python ci-dessous.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
Le problème avec ce code est que, dans la plupart des cas, la requête ne renvoie pas l'entité ajoutée dans la déclaration qui la précède. Puisque la requête figure dans la ligne qui vient immédiatement après l'insertion, l'index n'est pas mis à jour lors de l'exécution de la requête. Il existe également un problème avec la validité de ce scénario d'utilisation : Est-il vraiment nécessaire de renvoyer la liste de toutes les personnes sur une page sans contexte ? Que faire s'il y a un million de personnes ? Le renvoi de la page prendra bien trop de temps.
La nature de ce scénario d'utilisation suggère que vous deviez fournir un contexte pour affiner la requête. Dans cet exemple, le contexte utilisé sera l'organisation. De ce fait, vous pourrez utiliser l'organisation comme un groupe d'entités et exécuter une requête ascendante, et remédier ainsi au problème de cohérence. Cela est illustré par le code Python ci-dessous.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Cette fois, avec l'ancêtre "org" spécifié dans GqlQuery, la requête renvoie l'entité qui vient d'être insérée. L'exemple peut être étendu pour afficher le détail d'une seule personne en exécutant, sur son nom, une requête contenant l'ancêtre. Une autre méthode consiste à enregistrer la clé d'entité et à l'utiliser ensuite pour afficher le détail avec une méthode de recherche par clé.
Maintenir la cohérence entre Memcache et Datastore
Les groupes d'entités peuvent également être utilisés pour maintenir la cohérence entre des entrées Memcache et des entités Datastore. Supposons, par exemple, que vous deviez compter le nombre de personnes dans chaque équipe et les stocker dans Memcache. Pour vous assurer que les données mises en cache sont cohérentes avec les valeurs les plus récentes de Datastore, vous pouvez utiliser les métadonnées de groupe d'entités. Ces métadonnées renvoient le dernier numéro de version du groupe d'entités spécifié. Vous pouvez comparer le numéro de version avec celui stocké dans Memcache. Cette méthode vous permet de détecter un changement dans l'une des entités du groupe en effectuant une lecture dans un ensemble de métadonnées, au lieu d'analyser toutes les entités individuelles du groupe.
Limitations des groupes d'entités et des requêtes ascendantes
L'utilisation de groupes d'entités et de requêtes ascendantes n'est pas la solution miracle. Dans la pratique, deux éléments rendent l'application de cette technique assez difficile :
- Une seule mise à jour par seconde d'écriture est autorisée pour chaque groupe d'entités.
- La relation du groupe d'entités ne peut pas être modifiée après la création de l'entité.
Limite d'écriture
Le fait que le système doive être conçu pour contenir le nombre de mises à jour (ou de transactions) dans chaque groupe d'entités constitue une difficulté majeure. La limite est fixée à une mise à jour par seconde et par groupe d'entités.[2] Si le nombre de mises à jour doit dépasser cette limite, il se peut que le groupe d'entités bride les performances.
Dans l'exemple ci-dessus, il se peut que chaque organisation doive mettre à jour le dossier de l'un de ses membres. Imaginons un scénario dans lequel l'organisation "ateam" compte 1 000 personnes et où chacune d'elles peut faire l'objet d'une mise à jour par seconde sur n'importe quelle propriété. Par conséquent, il peut y avoir jusqu'à 1 000 mises à jour par seconde dans le groupe d'entités, un résultat qui ne serait pas réalisable en raison de la limite de mises à jour. Cela illustre à quel point il est important de choisir une conception de groupe d'entités appropriée, qui tienne compte des exigences en termes de performances. Il s'agit là de l'une des difficultés pour trouver l'équilibre optimal entre la cohérence à terme et la cohérence forte.
Immuabilité des relations de groupes d'entités
Une deuxième difficulté réside dans l'immuabilité des relations de groupes d'entités. Une relation de ce type est formée de manière statique sur la base du nommage des clés. Une fois l'entité créée, la relation ne peut plus être modifiée. La seule option disponible pour la modifier consiste à supprimer les entités d'un groupe, puis à les recréer. Cette difficulté nous empêche d'utiliser des groupes d'entités pour définir, de manière dynamique, des étendues ad hoc à des fins de cohérence ou de transactionnalité. Au contraire, le champ d'application de la transactionnalité et la cohérence sont étroitement liés au groupe d'entités statique défini au moment de la conception.
Prenons, comme exemple, un scénario dans lequel vous souhaitez établir un virement électronique entre deux comptes bancaires. Ce scénario commercial nécessite une cohérence forte et une transactionnalité. Cependant, les deux comptes ne peuvent pas être rassemblés en un seul groupe d'entités en dernière minute ni être basés sur un parent global. Ce groupe d'entités créerait, en effet, un goulot d'étranglement pour l'ensemble du système, empêchant de ce fait l'exécution d'autres demandes de virement. Les groupes d'entités ne peuvent donc pas être utilisés de cette façon.
Il existe une autre solution permettant de mettre en œuvre un virement électronique en bénéficiant d'une évolutivité et d'une disponibilité élevées. Au lieu de placer tous les comptes dans un seul groupe d'entités, vous pouvez créer un groupe d'entités pour chaque compte. Ainsi, vous pouvez utiliser les transactions pour vous assurer des mises à jour ACID sur les deux comptes bancaires. Les transactions sont une fonctionnalité Datastore permettant de créer des ensembles d'opérations avec des caractéristiques ACID pour 25 groupes d'entités au maximum. Veuillez prendre en compte le fait que, dans une transaction, vous devez utiliser des requêtes fortement cohérentes, telles que des requêtes de recherche par clé et des requêtes ascendantes. Pour en savoir plus sur les restrictions propres aux transactions, consultez la section Transactions et groupes d'entités.
Alternatives aux requêtes ascendantes
Si vous avez déjà créé une application avec un grand nombre d'entités stockées dans Datastore, il peut s'avérer difficile d'intégrer, par la suite, des groupes d'entités au cours d'une opération de refactorisation. Vous devriez, en effet, supprimer toutes les entités et les ajouter au sein d'une relation de groupe d'entités. C'est pourquoi, s'agissant de la modélisation des données pour Datastore, il est important de prendre une décision quant à la conception du groupe d'entités dès le début du processus de conception de l'application. Dans le cas contraire, vous risquez d'être limité au niveau de la prise en compte d'autres solutions pour obtenir un certain niveau de cohérence, comme une requête "keys-only" ("clés uniquement") suivie d'une requête de recherche par clé, ou l'utilisation de Memcache.
Requête globale "keys-only" suivie d'une recherche par clé
Une requête globale "keys-only" est un type de requête spécial qui renvoie seulement des clés, sans les valeurs de propriété des entités. Étant donné que les valeurs renvoyées sont exclusivement des clés, la requête ne porte pas sur une valeur d'entité susceptible de comporter un problème de cohérence. La combinaison formée d'une requête globale "keys-only" et de la méthode de recherche lira les valeurs d'entité les plus récentes. Il convient toutefois de noter que l'utilisation d'une requête "keys-only" n'exclut pas une éventuelle incohérence d'un index au moment de la requête, ce qui peut se traduire par la non-récupération d'une entité. Le résultat de la requête peut éventuellement être généré sur la base de l'exclusion des anciennes valeurs d'index. En résumé, un développeur ne peut utiliser une requête globale "keys-only", suivie d'une recherche par clé, que si l'application accepte que la valeur d'index ne soit pas encore cohérente au moment de l'exécution d'une requête.
Utiliser Memcache
Le service Memcache est volatil, mais offre une cohérence très forte. Ainsi, en associant des recherches Memcache à des requêtes Datastore, il est possible de développer un système qui atténuera dans la majorité des cas les problèmes de cohérence.
Prenons l'exemple d'un jeu qui gère une liste dans laquelle chaque entité "Joueur" a un score supérieur à zéro.
- Dans le cas des requêtes d'insertion ou de mise à jour, appliquez-les à la liste d'entités "Joueur" dans Memcache, ainsi qu'à Datastore.
- Dans le cas des requêtes de recherche, lisez la liste d'entités "Joueur" depuis Memcache et exécutez une requête "keys-only" sur Datastore si la liste n'est pas présente dans Memcache.
La liste renvoyée est cohérente dès lors que la liste mise en cache est présente dans Memcache. Si l'entrée a été expulsée, ou si le service Memcache est temporairement indisponible, il se peut que le système doive lire la valeur d'une requête Datastore susceptible de renvoyer un résultat incohérent. Cette technique peut être appliquée à toute application qui tolère un faible degré d'incohérence.
Plusieurs bonnes pratiques peuvent être suivies lorsque vous utilisez Memcache comme couche de mise en cache pour Datastore :
- Identifiez les exceptions et les erreurs Memcache afin de maintenir la cohérence entre la valeur Memcache et la valeur Datastore. Si une exception est renvoyée lors de la mise à jour de l'entrée sur Memcache, prenez soin d'invalider l'ancienne entrée dans Memcache. Autrement, il risque d'y avoir des valeurs différentes pour une même entité (une ancienne valeur dans Memcache et une nouvelle dans Datastore).
- Définissez une période d'expiration sur les entrées Memcache. Il est conseillé de définir des périodes courtes pour l'expiration de chaque entrée, afin de réduire le risque d'incohérence dans le cas des exceptions Memcache.
- Utilisez la fonctionnalité compare-and-set lors de la mise à jour des entrées pour un contrôle de simultanéité. Vous éviterez ainsi tout risque de perturbation entre les mises à jour simultanées portant sur la même entrée.
Migration progressive vers les groupes d'entités
Les suggestions énoncées dans la section précédente n'éliminent pas complètement la possibilité d'un comportement incohérent. Il est préférable de concevoir l'application sur la base de groupes d'entités et de requêtes ascendantes lorsqu'une cohérence forte est nécessaire. Cependant, il peut s'avérer impossible de faire migrer une application, ce qui peut signifier l'adoption d'une logique d'application et de requêtes ascendantes au détriment de requêtes globales pour un modèle de données. Pour y parvenir, une solution consiste à mettre en place un processus de transition progressif, tel que celui exposé ci-dessous :
- Identifiez et classez par priorité les fonctions de l'application qui nécessitent une cohérence forte.
- Élaborez une nouvelle logique pour les fonctions "insert()" ou "update()" à l'aide de groupes d'entités, en plus (plutôt qu'en remplacement) de la logique en place. De cette manière, toute nouvelle insertion ou mise à jour sur des nouveaux groupes d'entités et d'anciennes entités pourra être traitée par une fonction appropriée.
- Modifiez la logique déjà créée pour les fonctions de lecture ou de requête. Les requêtes ascendantes sont exécutées en premier s'il existe un nouveau groupe d'entités pour la demande. Exécutez l'ancienne requête globale comme logique de secours si le groupe d'entités n'existe pas.
Cette stratégie permet de migrer progressivement d'un modèle de données déjà créé vers un nouveau modèle basé sur des groupes d'entités, ce qui réduit le risque de problèmes causés par une cohérence à terme. Dans la pratique, cette méthode dépend de scénarios d'utilisation et d'exigences spécifiques pour être appliquée à un système réel.
Repli sur le mode dégradé
Pour l'heure, il est difficile de détecter, de manière automatisée, une situation dans laquelle la cohérence d'une application s'est dégradée. Toutefois, si vous parvenez à indiquer que la cohérence d'une application s'est dégradée par d'autres moyens, vous pouvez alors mettre en œuvre un mode dégradé pouvant être activé ou désactivé afin de désactiver certaines zones de la logique d'application qui nécessitent une cohérence forte. Par exemple, plutôt que présenter un résultat de requête incohérent sur un écran de rapport de facturation, un message de maintenance peut être affiché pour cet écran. Ce faisant, les autres services de l'application peuvent continuer à diffuser, atténuant ainsi l'impact sur le confort d'utilisation.
Obtention plus rapide d'une cohérence totale
Dans une application de grande envergure qui compte des millions d'utilisateurs ou plusieurs téraoctets d'entités Datastore, il est possible qu'une utilisation inadaptée de Datastore conduise à une dégradation de la cohérence. Voici quelques exemples :
- Numérotation séquentielle des clés d'entité
- Trop d'index
Ces pratiques n'affectent pas les petites applications. Cependant, plus la taille de l'application augmente, plus ces pratiques risquent d'allonger le temps nécessaire pour mettre en place la cohérence. Il est donc préférable de les éviter au cours des premières étapes de la conception de l'application.
Anti-modèle n° 1 : Numérotation séquentielle des clés d'entité
Avant la sortie du SDK App Engine 1.8.1, Datastore utilisait une suite de petits identifiants entiers avec des modèles généralement consécutifs comme noms de clé par défaut générés automatiquement. Dans certains articles, cette technique est désignée sous le nom de "règle héritée" pour créer des entités pour lesquelles aucun nom de clé n'est spécifié par l'application. Cette règle générait des noms de clés d'entité avec une numérotation séquentielle comme 1000, 1001, 1002, etc. Cependant, comme nous l'avons vu plus haut, Datastore stocke les entités par ordre lexicographique des noms de clés. Il y a donc de fortes chances que ces entités soient stockées sur les mêmes serveurs Datastore. Si une application attire un très large public, cette numérotation séquentielle peut entraîner une concentration d'opérations sur un serveur spécifique, ce qui peut se traduire par une latence plus importante pour la cohérence.
Avec le SDK App Engine 1.8.1, Datastore s'enrichit d'une nouvelle méthode de numérotation des identifiants avec une règle par défaut qui utilise des identifiants "dispersés" (voir la documentation de référence). Cette règle génère une séquence aléatoire d'identifiants pouvant comporter jusqu'à 16 chiffres répartis de manière approximativement uniforme. L'utilisation de cette règle devrait améliorer la répartition du trafic d'une l'application de grande envergure entre divers serveurs Datastore, permettant ainsi de parvenir plus rapidement à la cohérence. La règle par défaut est recommandée, sauf si votre application nécessite expressément une compatibilité avec la règle héritée.
Si vous définissez explicitement des noms de clés sur les entités, il convient de concevoir le schéma de nommage de façon à accéder aux entités de manière uniforme sur l'ensemble de l'espace de nommage des clés. En d'autres termes, ne concentrez pas l'accès dans une plage spécifique, car les entités sont classées selon l'ordre lexicographique des noms de clés. Dans le cas contraire, il se peut que vous soyez confronté au même problème qu'avec la numérotation séquentielle.
Pour illustrer la répartition inégale de l'accès sur l'espace de clés, prenons un exemple dans lequel des entités sont créées avec des noms de clés séquentiels, comme indiqué dans le code suivant :
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
Le format d'accès de l'application risque de créer un "point chaud" sur une certaine plage des noms de clés, comme si l'accès avait été concentré sur les entités "Personne" récemment créées. Dans ce cas, les clés fréquemment utilisées auront toutes des identifiants plus élevés. Il se peut alors que la charge soit concentrée sur un serveur Datastore spécifique.
Pour comprendre le concept de répartition uniforme sur l'espace de clés, vous pouvez également envisager d'utiliser de longues chaînes aléatoires pour les noms de clés. Vous en trouverez l'illustration dans l'exemple suivant :
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
Désormais, les entités "Personne" récemment créées seront dispersées sur l'espace de clés et sur plusieurs serveurs. Cela suppose qu'il y ait suffisamment d'entités "Personne".
Anti-modèle n° 2 : Trop d'index
Dans Datastore, une mise à jour effectuée sur une entité entraînera la mise à jour de tous les index définis pour le type d'entité correspondant. Si de nombreux index personnalisés sont utilisés dans une application, une mise à jour peut impliquer des dizaines, des centaines, voire des milliers de mises à jour sur les tables d'index. Dans une application de grande envergure, une utilisation excessive d'index personnalisés peut entraîner une charge accrue sur le serveur et risque d'allonger le délai nécessaire pour appliquer la cohérence.
Dans la plupart des cas, les index personnalisés sont ajoutés pour répondre à des besoins tels que des tâches d'analyse des données, de dépannage ou d'assistance clientèle. BigQuery est un moteur de requête massivement évolutif, capable d'exécuter des requêtes ad hoc sur de vastes ensembles de données sans index prédéfinis. Cet outil est mieux adapté que Datastore aux scénarios de service client, de dépannage ou d'analyse de données qui nécessitent des requêtes complexes.
Une méthode consiste à combiner Datastore et BigQuery afin de répondre à différentes exigences métier. Vous pouvez utiliser Datastore pour le traitement transactionnel en ligne (OLTP, Online transaction processing) requis pour la logique d'application de base et BigQuery pour le traitement analytique en ligne (OLAP, Online analytical processing) nécessaire aux opérations de backend. Il peut s'avérer nécessaire de mettre en œuvre un flux d'exportation des données en continu de Datastore vers BigQuery afin de déplacer les données nécessaires pour ces requêtes.
Outre une mise en œuvre différente pour ces index personnalisés, une autre recommandation concerne la définition explicite de propriétés non indexées (reportez-vous à la section Propriétés et types de valeurs). Par défaut, Datastore permet de créer une table d'index différente pour chaque propriété indexable d'un type d'entité. S'il existe 100 propriétés pour un type, il y aura 100 tables d'index pour ce type, et 100 autres mises à jour pour chaque mise à jour d'une entité. Une bonne pratique consiste alors à définir des propriétés non indexées, lorsque cela s'avère possible, si elles ne sont pas nécessaires pour une condition de requête.
Outre le fait qu'elles réduisent les risques de latence accrue pour parvenir à la cohérence, ces optimisations d'index peuvent entraîner une réduction sensible des coûts de stockage Datastore dans une application de grande envergure qui s'accompagne d'une utilisation intensive d'index.
Conclusion
La cohérence à terme est une composante essentielle des bases de données non relationnelles. Elle permet aux développeurs de trouver l'équilibre idéal entre l'évolutivité, les performances et la cohérence. Il est essentiel de comprendre comment gérer l'équilibre entre la cohérence à terme et la cohérence forte pour concevoir un modèle de données optimal pour votre application. Dans Datastore, l'utilisation de groupes d'entités et de requêtes ascendantes constitue le meilleur moyen de garantir une cohérence forte sur un périmètre d'entités. Si l'intégration de groupes d'entités s'avère impossible dans votre application en raison des limitations décrites précédemment, vous pouvez envisager d'autres options, telles que l'aide des requêtes "keys-only" ou encore Memcache. Dans le cas des applications de grande envergure, il est conseillé d'adopter des bonnes pratiques, telles que l'utilisation d'identifiants dispersés et l'indexation réduite, afin d'accélérer la mise en œuvre de la cohérence. Il peut également s'avérer judicieux d'associer Datastore à BigQuery pour répondre aux exigences commerciales portant sur des requêtes complexes et réduire, dans la mesure du possible, l'utilisation d'index Datastore.
Autres ressources
Vous trouverez, dans les sources d'information ci-dessous, davantage de renseignements sur les sujets traités dans cet article :
- Google App Engine : Stockage de données
- Présentation de Datastore
- Blog de Google Cloud Platform
- Cloud SQL
- Utiliser Python App Engine avec Cloud SQL
- Bigtable : Système de stockage distribué pour les données structurées
- SDK App Engine 1.5.2 disponible
- Megastore : Stockage évolutif et à haute disponibilité pour les services interactifs
[1] Il est même possible de former un groupe d'entités en n'indiquant qu'une seule clé de l'entité racine ou parente, sans stocker les entités proprement dites de la racine ou du parent, car les fonctions du groupe d'entités sont toutes mises en œuvre sur la base des relations entre les clés.
[2] La limite est fixée à une mise à jour par seconde et par groupe d'entités, en dehors des transactions, ou à une transaction par seconde et par groupe d'entités. Si vous regroupez plusieurs mises à jour dans une même transaction, vous êtes limité à une taille de transaction maximale de 10 Mo et à la vitesse d'écriture maximale du serveur Datastore.