Equilibra la coherencia sólida y eventual con Datastore
Brinda una experiencia del usuario coherente y aprovecha el modelo de coherencia eventual para escalar a conjuntos de datos grandes
En este documento se describe cómo lograr una coherencia sólida a fin de brindar una experiencia del usuario positiva, mediante el modelo de coherencia eventual de Datastore para manejar grandes cantidades de datos y usuarios.
La información que se presenta está diseñada para ingenieros y arquitectos de software que deseen desarrollar soluciones en Datastore. Se incluyen conceptos análogos sobre las bases de datos relacionales, a fin de ayudar a los lectores que están más familiarizados con ese tipo de bases de datos que con sistemas no relacionales como es el caso de Datastore. El documento supone que tienes conocimientos básicos de Datastore. La forma más fácil de comenzar con Datastore es mediante Google App Engine, con uno de los lenguajes admitidos. Si todavía no usaste App Engine, sugerimos que leas la Guía de introducción y la sección sobre cómo almacenar datos correspondiente a uno de esos lenguajes. Si bien se usan fragmentos de código de Python como ejemplo, no es necesario que tengas experiencia en Python para entender este documento.
Nota: Para los fragmentos de código de este artículo, se usa la biblioteca cliente de DB de Python para Datastore, lo que ya no se recomienda. Recomendamos a los desarrolladores de aplicaciones nuevas que usen la biblioteca cliente NDB, que brinda varios beneficios que no están disponibles con esta biblioteca cliente, como el almacenamiento en caché automático de entidades mediante la API de Memcache. Si aún usas la biblioteca cliente DB anterior, lee la guía de migración de DB a NDB.
Contenido
NoSQL y coherencia eventual
Coherencia eventual en Datastore
Consulta principal y grupo de entidad
Limitaciones del grupo de entidades y la consulta principal
Alternativas a las consultas principales
Minimiza el tiempo para lograr la coherencia completa
Conclusión
Recursos adicionales
NoSQL y coherencia eventual
Las bases de datos no relacionales, también conocidas como bases de datos NoSQL, surgieron en los últimos años como una alternativa a las bases de datos relacionales. Datastore es una de las bases de datos no relacionales más utilizadas en el sector. En 2013, Datastore procesó 4,500 billones de transacciones por mes (entrada de blog de Google Cloud Platform). Cloud Datastore les ofrece a los desarrolladores una forma más simple de almacenar datos y acceder a ellos. Su esquema flexible se correlaciona de manera natural con los lenguajes de programación y los orientados a objetos. Datastore también ofrece una serie de funciones que las bases de datos relacionales no son adecuadas para proporcionar, como una alta confiabilidad y un alto rendimiento a gran escala.
Diseñar un sistema que aproveche las bases de datos no relacionales puede ser un desafío para los desarrolladores que están más acostumbrados a las bases de datos relacionales, ya que posiblemente no estén muy familiarizados con algunas de sus características y prácticas. Aunque el modelo de programación de Datastore es simple, es importante tener en cuenta estas características. El tema principal en este documento es cómo programar para una de esas características: la coherencia eventual.
¿Qué es la coherencia eventual?
La coherencia eventual es una garantía teórica de que, mientras no se realicen actualizaciones nuevas en una entidad, todas sus lecturas mostrarán el último valor actualizado finalmente. El sistema de nombres de dominio (DNS) de Internet es un buen ejemplo de un sistema con un modelo de coherencia eventual. Los servidores DNS no siempre reflejan los valores más recientes, que se almacenan en caché y se replican en muchos directorios de Internet. Replicar los valores modificados en todos los clientes y servidores DNS lleva cierto tiempo. Sin embargo, el sistema DNS es tan eficaz que se convirtió en una de las bases de Internet. Es un sistema con alta disponibilidad que demostró tener una escalabilidad extraordinaria, lo que permite realizar consultas en más de cien millones de dispositivos en toda la Internet.
En la figura 1, se ilustra el concepto de replicación con coherencia eventual. El diagrama muestra que, si bien siempre se pueden leer las réplicas, es posible que algunas no sean coherentes con la escritura más reciente en el nodo de origen en un momento determinado. En el diagrama, el Nodo A es el de origen y los nodos B y C son réplicas.
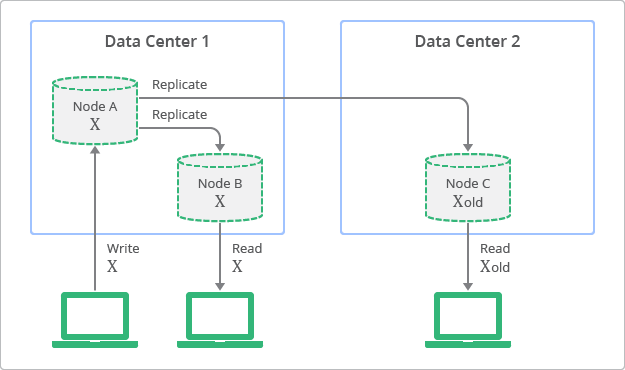
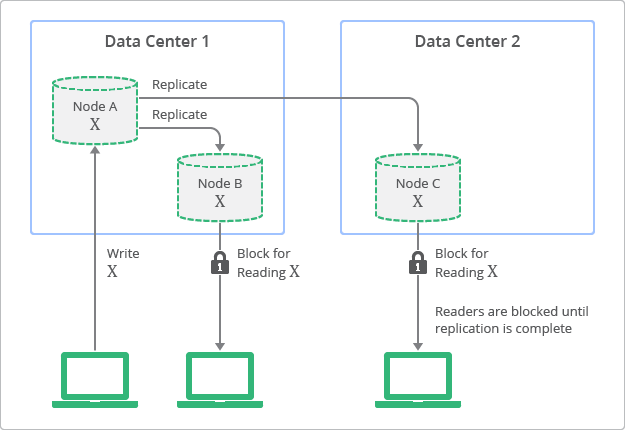
En cambio, las bases de datos relacionales tradicionales se diseñaron en función del concepto de coherencia sólida, que también se denomina coherencia inmediata. Esto significa que todos los observadores de una entidad verán los mismos datos inmediatamente después de una actualización. Esta característica fue una premisa fundamental para muchos desarrolladores que utilizan bases de datos relacionales. Sin embargo, los desarrolladores deben hacer concesiones en cuanto a la escalabilidad y el rendimiento de la aplicación para poder tener una coherencia sólida. Dicho simplemente, es necesario bloquear los datos durante el período de actualización o proceso de replicación para garantizar que ningún otro proceso actualice los mismos datos.
En la figura 2, se muestra una vista conceptual de la topología de implementación y el proceso de replicación con la coherencia sólida. En este diagrama, se observa que las réplicas siempre tienen valores coherentes con el nodo de origen, pero no se puede acceder a ellas antes de que termine la actualización.
Equilibra la coherencia sólida y eventual
Recientemente, las bases de datos no relacionales se volvieron populares, en particular para las aplicaciones web que requieren escalabilidad alta y un rendimiento con mucha disponibilidad. Con estas bases de datos, los desarrolladores pueden seleccionar un equilibrio óptimo entre coherencia sólida y eventual para cada aplicación. De esta manera, pueden combinar lo mejor de ambos modos. Por ejemplo, en casos prácticos como “saber cuáles de tus amigos están en línea en un momento específico” o “cuántos usuarios le pusieron +1 a tu publicación”, la información no requiere coherencia sólida. Por lo tanto, podemos aprovechar la coherencia eventual para maximizar la escalabilidad y el rendimiento. Hay otros casos prácticos en los que la información requiere coherencia sólida, como saber “si un usuario terminó o no el proceso de facturación” o “cuántos puntos obtuvo un jugador en una batalla”.
En términos generales, podemos decir que la coherencia eventual suele ser el mejor modelo en casos prácticos en los que hay una gran cantidad de entidades. Si una consulta tiene una gran cantidad de resultados, la experiencia del usuario no se verá afectada cuando se incluyan o excluyan entidades específicas. En contraposición, en los casos prácticos en los que hay una cantidad pequeña de entidades en un contexto más acotado, probablemente necesitemos coherencia sólida. Esto se debe a que los usuarios sabrán qué entidades deben incluirse o excluirse, lo cual puede afectar su experiencia.
Por estas razones, es importante que los desarrolladores comprendan las características no relacionales de Datastore. En las siguientes secciones, se explicará cómo combinar los modelos de coherencia sólida y eventual para compilar una aplicación escalable con alta disponibilidad y rendimiento. De esta manera, se cumplirán los requisitos de coherencia para brindar una experiencia del usuario positiva.
Coherencia eventual en Datastore
Debes seleccionar la API correcta cuando se requiere una vista de los datos con coherencia sólida. Las diferentes variedades de las API de consulta de Datastore y sus correspondientes modelos de coherencia se muestran en la Tabla 1.
|
API de Datastore |
Lectura del valor de la entidad |
Lectura de índice |
|---|---|---|
|
Coherencia eventual |
Coherencia eventual |
|
|
N/A |
Coherencia eventual |
|
|
Coherencia sólida |
Coherencia sólida |
|
|
Búsqueda por clave (get()) |
Coherencia sólida |
No disponible. |
Las consultas de Datastore sin principal se conocen como consultas globales y están diseñadas para funcionar con un modelo de coherencia eventual. Esto no garantiza la coherencia sólida. Una consulta global solo de clave es una consulta global que muestra solo las claves de entidades que coinciden con la consulta, pero no los valores de atributos de esas entidades. En una consulta principal, el alcance se determina en función de una entidad principal. En las siguientes secciones, se describe detalladamente el comportamiento de cada tipo de coherencia.
Coherencia eventual en la lectura de valores de entidades
A excepción de las consultas principales, es posible que el valor de una entidad actualizada no se muestre inmediatamente cuando se ejecuta una consulta. Para comprender el impacto de la coherencia eventual en la lectura de valores de entidades, imaginemos una situación en la que tenemos una entidad (Jugador) con una propiedad (Puntuación). Supongamos que la Puntuación inicial tiene un valor de 100. Después de un tiempo, este valor se actualiza a 200. Si se ejecuta una consulta global que incluye la misma entidad Jugador en el resultado, es posible que el valor de la propiedad Puntuación de la entidad mostrada siga siendo 100.
Este comportamiento se debe a la replicación entre los servidores de Datastore. Bigtable y Megastore, las tecnologías subyacentes de Datastore, administran la replicación (consulta Recursos adicionales para obtener más información sobre Bigtable y Megastore). La replicación se ejecuta con el algoritmo Paxos, que espera de forma síncrona hasta que la mayoría de las réplicas reconozcan la solicitud de actualización. La réplica se actualiza con los datos de la solicitud después de un período. Este período suele ser corto, pero no se puede saber con certeza cuánto durará. Es posible que una consulta lea los datos obsoletos si se la ejecuta antes de que finalice la actualización.
En muchos casos, esta actualización habrá llegado a todas las réplicas rápidamente. Sin embargo, existen varios factores, que en conjunto, podrían aumentar el tiempo necesario para lograr la coherencia. Estos factores incluyen cualquier incidente que afecte a todo un centro de datos y requiera el cambio de una gran cantidad de servidores a otro centro de datos. Debido a la variabilidad de estos factores, no es posible establecer con certeza cuánto tiempo debe transcurrir para que se establezca la coherencia completa.
Generalmente, el tiempo necesario para que una consulta muestre el valor más reciente es muy corto. Sin embargo, el tiempo puede ser más prolongado en determinadas situaciones en las que aumenta la latencia de la replicación. Las aplicaciones que usan consultas globales de Datastore deben diseñarse con cuidado para manejar estos casos apropiadamente.
Se puede evitar la coherencia eventual para leer valores de entidades mediante una consulta de solo clave, una consulta principal o una búsqueda por clave (el método get()). A continuación, analizaremos con más detalle estos tipos de consulta diferentes.
Coherencia eventual para leer un índice
Es posible que un índice no esté actualizado al momento de ejecutar una consulta global. Esto significa que, aunque puedas leer los últimos valores de propiedad de las entidades, tal vez no sea posible filtrar la "lista de entidades" incluida en el resultado de la consulta en función de los valores de índice anteriores.
Para comprender el impacto de la coherencia eventual en la lectura de un índice, imagina una situación en la que se inserta una nueva entidad (Jugador) en Datastore. La entidad tiene una propiedad (Puntuación), cuyo valor inicial es 300. Inmediatamente después de ingresar la entidad, ejecutas una consulta de solo clave para obtener todas las entidades con un valor mayor que 0 en Puntuación. Cabría esperar que la entidad Jugador, que se acaba de ingresar, aparezca en los resultados de la consulta. Pero es posible que, inesperadamente, esta entidad no aparezca en los resultados. Esto puede suceder cuando la tabla de índice de la propiedad Puntuación no está actualizada con el valor nuevo ingresado en el momento en que se ejecuta la consulta.
Recuerda que todas las consultas en Datastore se ejecutan con tablas de índice y, sin embargo, las actualizaciones de las tablas de índice son asíncronas. En esencia, cada actualización de entidad consta de dos fases. En la primera, la fase de confirmación, se realiza una escritura en el registro de transacciones. En la segunda fase, se escriben los datos y se actualizan los índices. Si la fase de confirmación se realiza de forma correcta, la fase de escritura también tendrá éxito, aunque es posible que esto no suceda de inmediato. Si realizas una consulta en una entidad antes de que se actualicen los índices, es posible que veas datos que aún no son coherentes.
Como resultado de este proceso de dos fases, existe una demora antes de que se puedan ver las últimas actualizaciones de las entidades en las consultas globales. Al igual que en la coherencia eventual de los valores de entidades, la demora suele ser breve, pero podría prolongarse (en casos excepcionales, puede tardar minutos o más).
Puede suceder lo mismo luego de las actualizaciones. Por ejemplo, supongamos que actualizas una entidad existente (Jugador) con un valor nuevo (0) para la propiedad Puntuación, y ejecutas la misma consulta inmediatamente después. Cabría esperar que la entidad no aparezca en los resultados de la consulta, ya que el nuevo valor de Puntuación (0) la excluiría. Sin embargo, debido al mismo comportamiento de actualización de índice asíncrono, todavía es posible que se incluya la entidad en el resultado.
La única forma de evitar la coherencia eventual en la lectura de un índice es usar una consulta principal o el método de búsqueda por clave. Una consulta de solo clave no puede evitar este comportamiento.
Coherencia sólida en la lectura de índices y valores de entidades
En Datastore, solo hay dos API que proporcionan coherencia sólida para leer índices y valores de entidades: (1) la búsqueda por método de clave y (2) la consulta principal. Si la lógica de la aplicación requiere una coherencia sólida, el desarrollador debe usar uno de estos métodos para leer entidades de Datastore.
Datastore está diseñado específicamente para proporcionar una coherencia sólida en estas API. Cuando se invoca cualquiera de ellas, Datastore limpia todas las actualizaciones pendientes en una de las réplicas y en las tablas de índices, y, luego, ejecuta la búsqueda o la consulta principal. De este modo, se mostrará el valor más reciente de la entidad, según la tabla de índice actualizada, con los valores correspondientes a las actualizaciones más recientes.
A diferencia de las consultas, la llamada de búsqueda por clave solo muestra una entidad o un conjunto de entidades especificadas por una clave o un conjunto de claves. Esto significa que una consulta principal es la única forma en que Datastore cumple con el requisito de coherencia sólida, además de un requisito de filtrado. Sin embargo, las consultas principales no funcionan si no se especifica un grupo de entidad.
Consulta principal y grupo de entidades
Como se explicó al comienzo de este documento, uno de los beneficios de Datastore es que los desarrolladores pueden encontrar un equilibrio óptimo entre la coherencia sólida y la coherencia eventual. En Datastore, un grupo de entidades es una unidad con coherencia sólida, transaccionalidad y localidad. Con los grupos de entidad, los desarrolladores pueden definir el alcance de la coherencia sólida entre las entidades en una aplicación. De esta forma, la aplicación puede mantener la coherencia dentro del grupo de entidad y ofrecer a la vez alta escalabilidad, disponibilidad y rendimiento como un sistema completo.
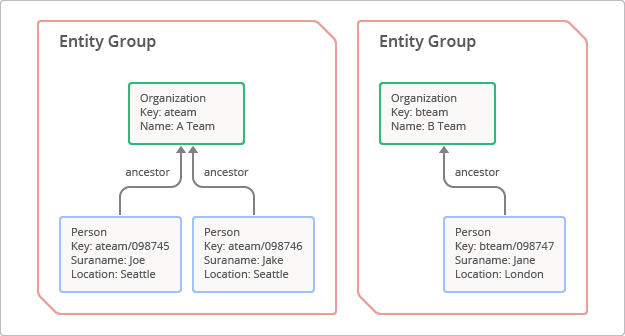
Un grupo de entidades es una jerarquía formada por una entidad raíz y entidades secundarias o sucesoras.[1] Para crear un grupo de entidad, un desarrollador especifica una ruta principal, que es una serie de claves principales que preceden a la clave secundaria. En la figura 3, se ilustra el concepto de grupo de entidad. En este caso, la entidad raíz con la clave “ateam” tiene dos entidades secundarias con las claves “ateam/098745” y “ateam/098746”.
Dentro del grupo de entidad, se garantizan las siguientes características:
- Coherencia sólida
- Una consulta principal sobre el grupo de entidad mostrará un resultado con coherencia sólida. De esta manera, refleja los valores más recientes de la entidad filtrados según el último estado del índice.
- Transaccionalidad
- Cuando se delimita una transacción de manera programática, el grupo de entidad proporciona características ACID (atomicidad, coherencia, aislamiento y durabilidad) en la transacción.
- Localidad
- Las entidades de un grupo de entidad se almacenarán de forma física en lugares cercanos en los servidores de Datastore, ya que todas las entidades se ordenan y almacenan según el orden lexicográfico de las claves. Esto permite que una consulta principal analice con rapidez el grupo de entidad con un mínimo de E/S.
Una consulta principal es una forma especial de consulta que solo se ejecuta en un grupo de entidad especificado. Se ejecuta con coherencia sólida. Entre bambalinas, Datastore garantiza que todas las replicaciones y actualizaciones de índice pendientes se apliquen antes de ejecutar la consulta.
Ejemplo de una consulta principal
En esta sección, se describe cómo utilizar grupos de entidad y consultas principales en la práctica. En el siguiente ejemplo, analizaremos el problema de la administración de registros de datos de personas. Supongamos que tenemos un código que agrega una entidad de un tipo específico seguida inmediatamente de una consulta sobre ese tipo. A continuación, este concepto se demuestra con el código de Python de ejemplo.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
El problema con este código es que, en la mayoría de los casos, no mostrará la entidad que se agregó en la instrucción anterior. Dado que la consulta continúa en la línea que sigue inmediatamente después de la inserción, el índice no se habrá actualizado cuando se ejecute la consulta. Sin embargo, también existe un problema con la validez de este caso práctico: ¿Existe realmente la necesidad de mostrar una lista de todas las personas en una página sin contexto? ¿Y si hay un millón de personas? Se demorará mucho tiempo para mostrar la página.
La naturaleza del caso práctico sugiere que debemos proporcionar contexto para acotar la consulta. En este ejemplo, usaremos el contexto de la organización. De esta forma, podemos usar la organización como un grupo de entidad y ejecutar una consulta principal, que resuelve nuestro problema de coherencia. Esto se demuestra en el siguiente código de Python.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Ahora que especificamos la organización principal en GqlQuery, la consulta muestra la entidad ingresada. El ejemplo se podría extender para concentrarnos en una persona individual mediante una consulta del nombre de la persona que incluya el valor principal. Como alternativa, esto también se podría haber hecho guardando la clave de entidad y usándola para el desglose con una búsqueda por clave.
Mantén la coherencia entre Memcache y Datastore
Los grupos de entidades también se pueden usar como una unidad para mantener la coherencia entre las entradas de Memcache y las de Datastore. Como ejemplo, consideremos una situación en la que cuentas la cantidad de personas de cada equipo y almacenas los valores resultantes en Memcache. Para asegurarte de que los datos almacenados en caché sean coherentes con los valores más recientes de Datastore, puedes usar los metadatos del grupo de entidades. Estos metadatos muestran la última versión del grupo de entidad especificado. Puedes comparar el número de versión con el número almacenado en Memcache. Este método te permite detectar un cambio en cualquiera de las entidades del grupo mediante la lectura de un conjunto de metadatos, en vez de analizar todas las entidades del grupo de forma individual.
Limitaciones del grupo de entidad y la consulta principal
El enfoque en el que se usan los grupos de entidad y las consultas principales no es una solución mágica. A continuación, se detallan los dos desafíos que dificultan la aplicación de esta técnica en la práctica.
- Existe un límite de escritura de una actualización por segundo por cada grupo de entidad.
- No se puede cambiar la relación del grupo de entidad luego de su creación.
Límite de escrituras
Un desafío importante es que el sistema debe estar diseñado para contener la cantidad de actualizaciones (o transacciones) de cada grupo de entidad. El límite admitido es de una actualización por segundo por grupo de entidad.[2] En caso de que se necesite una cantidad de actualizaciones superior a ese límite, podría generarse un cuello de botella en el rendimiento del grupo de entidad.
En el ejemplo anterior, es posible que cada organización deba actualizar el registro de cualquier persona de la organización. Imaginemos la situación en la que “ateam” contiene 1,000 personas y cada una tiene una actualización por segundo de alguna de sus propiedades. Como resultado, puede haber hasta 1,000 actualizaciones por segundo en el grupo de entidad, lo cual sería imposible debido al límite de actualizaciones. Esto indica que es importante seleccionar un diseño de grupo de entidad adecuado que tenga en cuenta los requisitos de rendimiento. Este es uno de los desafíos para encontrar el equilibrio óptimo entre los modelos de coherencia eventual y sólida.
Inmutabilidad de las relaciones del grupo de entidad
El segundo desafío es la inmutabilidad de las relaciones del grupo de entidad. Esta relación se constituye de manera estática en función del nombre de la clave. No se puede cambiar después de crear la entidad. La única opción disponible para cambiar la relación es borrar las entidades del grupo y volver a crearlas. Este problema nos impide usar grupos de entidad con el fin de definir alcances ad-hoc para la coherencia o la transaccionalidad de forma dinámica. En cambio, estos alcances están estrechamente relacionados con el grupo de entidad estático definido al momento del diseño.
Imaginemos, por ejemplo, una situación en la que se desea implementar una transferencia bancaria entre dos cuentas. Se trata de una situación de tipo comercial que requiere coherencia sólida y transaccionalidad. Sin embargo, no es posible crear un grupo de entidad a último minuto con estas dos cuentas ni usar un elemento superior global. Ese grupo de entidad generaría un cuello de botella para todo el sistema, lo cual dificultaría la ejecución de otras solicitudes de transferencia bancaria. En conclusión, los grupos de entidad no se pueden utilizar de esta forma.
Existe una forma alternativa para implementar una transferencia bancaria de manera altamente escalable y disponible. En vez de colocar todas las cuentas en un solo grupo de entidad, puedes crear un grupo para cada cuenta. Esto te permite usar transacciones para garantizar las actualizaciones ACID en ambas cuentas bancarias. Las transacciones son una función de Datastore que te permite crear conjuntos de operaciones con características de ACID para un máximo de veinticinco grupos de entidades. Ten en cuenta que debes usar las consultas de coherencia sólida, como búsquedas por clave y consultas principales, en una transacción. Para obtener más información sobre las restricciones de las transacciones, consulta Transacciones y grupos de entidad.
Alternativas a las consultas principales
Si ya tienes una aplicación existente con una gran cantidad de entidades almacenadas en Datastore, puede ser difícil incorporar grupos de entidades después en un ejercicio de refactorización. Sería necesario borrar todas las entidades y agregarlas en una relación de grupo de entidad. Por lo tanto, en el modelado de datos para Datastore, es importante tomar una decisión sobre el diseño del grupo de entidades en la fase inicial del diseño de la aplicación. De lo contrario, es posible que estés limitado para lograr un determinado nivel de coherencia durante una refactorización, como realizar una consulta de solo clave seguida de una búsqueda por clave o usar Memcache.
Consulta global de solo clave seguida de una búsqueda por clave
Una consulta global de solo clave es un tipo especial de consulta global que muestra únicamente las claves, sin los valores de las propiedades de las entidades. Como los valores que se muestran son solo claves, la consulta no involucra los valores de una entidad, que podrían tener problemas de coherencia. La combinación de una consulta global de solo clave con el método de búsqueda permite leer los valores de entidades recientes. Debemos señalar que una consulta global de solo clave no puede excluir la posibilidad de un índice no coherente al momento de la consulta, lo que puede dar lugar a que la entidad no se recupere. El resultado de la consulta podría generarse potencialmente en función del filtro de los valores de índice anteriores. En conclusión, un desarrollador puede usar una consulta global de solo clave seguida de una búsqueda por clave solo cuando el requisito de la aplicación permite que el valor del índice no sea coherente al momento de la consulta.
Cómo usar Memcache
El servicio Memcache es volátil, pero tiene coherencia sólida. Por lo tanto, si se combinan las búsquedas de Memcache con las consultas de Datastore, es posible crear un sistema que minimice los problemas de coherencia la mayor parte del tiempo.
Como ejemplo, imaginemos la situación de una aplicación de juego que mantiene una lista de entidades Jugador, cada una de las cuales tiene una puntuación mayor que cero.
- Para las solicitudes de inserción o actualización, aplícalas a la lista de entidades de Jugador en Memcache y en Datastore.
- Para las solicitudes de consulta, lee la lista de entidades de Jugador de Memcache y ejecuta una consulta de solo claves en Datastore cuando la lista no esté presente en Memcache.
La lista que se muestra será coherente siempre que la lista en caché esté presente en Memcache. Si se desalojó la entrada o si el servicio Memcache no está disponible temporalmente, es posible que el sistema tenga que leer el valor de una consulta de Datastore que podría mostrar un resultado incoherente. Esta técnica se puede usar para cualquier aplicación que admita un poco de incoherencia.
Existen algunas prácticas recomendadas para usar Memcache como una capa de almacenamiento en caché de Datastore:
- Captura excepciones y errores de Memcache para mantener la coherencia entre el valor de Memcache y el valor de Datastore. Si recibes una excepción cuando actualizadas la entrada en Memcache, asegúrate de invalidar la entrada anterior en Memcache. De lo contrario, podría haber valores diferentes para una entidad (un valor antiguo en Memcache y un valor nuevo en Datastore).
- Establece un período de vencimiento en las entradas de Memcache. Recomendamos establecer períodos cortos de vencimiento para minimizar la posibilidad de que se produzca una incoherencia en caso de excepciones de Memcache.
- Utiliza la función de comparar y establecer cuando actualices las entradas para el control de simultaneidad. Esto ayudará a evitar la interferencia entre actualizaciones simultáneas de la misma entrada.
Migración gradual a grupos de entidad
Las sugerencias detalladas en la sección anterior solo disminuyen la posibilidad de un comportamiento incoherente. Cuando se requiere coherencia sólida, lo ideal es diseñar la aplicación en función de grupos de entidad y consultas principales. Sin embargo, en algunos casos no es factible migrar una aplicación existente, lo que puede implicar cambiar el modelo de datos y la lógica de aplicación existentes para usar consultas principales en lugar de consultas globales. Una forma de lograrlo es realizar un proceso de transición gradual como el siguiente:
- Identifica y prioriza las funciones de la aplicación que necesitan coherencia sólida.
- Complementa (no reemplaces) la lógica existente de las funciones insert() o update() con una lógica nueva que use grupos de entidad. De esta manera, las inserciones o actualizaciones posteriores en grupos de entidades nuevos y entidades antiguas podrán manejarse con la función correspondiente.
- Modifica la lógica existente de las funciones de lectura o consulta. Las consultas principales se ejecutan primero si existe un grupo de entidad nuevo para la solicitud. Ejecuta la consulta global del modelo anterior como lógica de resguardo si no hay un grupo de entidad.
Esta estrategia permite realizar una migración gradual de un modelo de datos existente a uno nuevo que use grupos de entidad, con lo que se reduce el riesgo de problemas causados por la coherencia eventual. En la práctica, la aplicación de este enfoque en un sistema real depende de casos prácticos y requisitos específicos.
Plan de resguardo para modo degradado
Actualmente, es difícil detectar de manera programática una situación en la que se deterioró la coherencia de una aplicación. Sin embargo, en caso de que determines por otros medios que se deterioró la coherencia de una aplicación, tal vez puedas implementar un modo degradado que se puede activar y desactivar para inhabilitar algunas áreas en la lógica de la aplicación que requieren coherencia sólida. Por ejemplo, en vez de mostrar un resultado de consulta incoherente en una pantalla de informe de facturación, se puede mostrar un mensaje de mantenimiento para esa pantalla específica. De esta manera, los otros servicios de la aplicación pueden funcionar sin interrupciones y, a su vez, se reduce el impacto en la experiencia del usuario.
Reduce el tiempo para lograr una coherencia completa
En una aplicación de gran tamaño, con millones de usuarios o terabytes de entidades de Datastore, es posible que el uso inadecuado de Datastore ocasione el deterioro de la coherencia. Estos son algunos ejemplos de prácticas incorrectas:
- Numeración secuencial en las claves de entidad
- Cantidad excesiva de índices
Estas prácticas no afectan a las aplicaciones pequeñas. Sin embargo, una vez que la aplicación crece mucho, estas prácticas aumentan la posibilidad de que se necesite más tiempo para lograr la coherencia. Por lo tanto, es mejor evitarlas en las primeras etapas del diseño de la aplicación.
Antipatrón 1: Numeración secuencial de las claves de entidad
Antes del lanzamiento del SDK de App Engine 1.8.1, Datastore usaba una secuencia de ID de números enteros pequeños con patrones, por lo general, consecutivos como los nombres de clave predeterminados y generados automáticamente. En algunos documentos, esto se denomina una "política heredada" para crear entidades que no tengan un nombre de clave especificado en la aplicación. Esta política generaba nombres de clave para entidades con una numeración secuencial (por ejemplo 1000, 1001, 1002). Sin embargo, como ya dijimos, Datastore almacena entidades según el orden lexicográfico de los nombres de clave, de modo que es muy probable que esas entidades se almacenen en los mismos servidores de Datastore. Si una aplicación genera mucho tráfico, esa numeración secuencial podría causar una concentración de operaciones en un servidor específico, lo que puede provocar una latencia más larga hasta que se alcance la coherencia.
En el SDK de App Engine 1.8.1, Datastore incluyó un nuevo método de numeración de ID con una política predeterminada que utiliza ID dispersos (consulta la documentación de referencia). Esta política predeterminada genera una secuencia aleatoria de ID de hasta 16 dígitos con una distribución aproximadamente uniforme. Con esta política, es probable que el tráfico de la aplicación de gran tamaño se distribuya mejor en un conjunto de servidores de Datastore con un tiempo reducido para garantizar la coherencia. Se recomienda utilizar la política predeterminada, a menos que tu aplicación requiera específicamente la política heredada.
Si estableces nombres de clave explícitamente para las entidades, el esquema de nombres debe diseñarse de manera tal que se pueda obtener acceso a las entidades de manera uniforme en todo el espacio de nombres de clave. En otras palabras, no concentres el acceso en un rango particular, ya que se organizan según el orden lexicográfico de los nombres de clave. De lo contrario, surgirá el mismo problema que con la numeración secuencial.
Para entender la distribución no uniforme del acceso a través del espacio de claves, considera un ejemplo en el que se crean entidades con nombres de clave secuenciales como los siguientes:
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
El patrón de acceso de la aplicación podría crear un punto de mucha actividad en un rango determinado de nombres de clave (por ejemplo, si se concentra el acceso en las entidades Person creadas recientemente). En este caso, se accederá con más frecuencia a las claves con un ID más alto. Luego, la carga se puede concentrar en un servidor de Datastore específico.
Como alternativa, para comprender la distribución uniforme en el espacio de claves, puedes usar strings aleatorias largas en los nombres de clave. Esto se muestra en el siguiente ejemplo:
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
De esta forma, las entidades Person creadas recientemente estarán distribuidas por todo el espacio de claves y se alojarán en varios servidores. Este ejemplo da por sentado que existe una cantidad suficientemente grande de entidades Person.
Antipatrón 2: cantidad excesiva de índices
En Datastore, una actualización de una entidad generará actualizaciones en todos los índices definidos para ese tipo de entidad. Si una aplicación utiliza muchos índices personalizados, una actualización puede implicar decenas, cientos o incluso miles de actualizaciones de las tablas de índice. En una aplicación de gran envergadura, el uso excesivo de índices personalizados puede aumentar la carga en el servidor y, en consecuencia, aumentar la latencia para lograr la coherencia.
En la mayoría de los casos, los índices personalizados se agregan para cumplir con requisitos de atención al cliente, solución de problemas o tareas de análisis de datos. BigQuery es un motor de consultas altamente escalable, capaz de ejecutar consultas ad-hoc en grandes conjuntos de datos sin índices preconfigurados. Es más adecuado para casos prácticos que requieren consultas más complejas que las que hacen en Datastore, como asistencia al cliente, solución de problemas o análisis de datos.
Una práctica es combinar Datastore y BigQuery para cumplir con los diferentes requisitos empresariales. Usa Datastore para el procesamiento transaccional en línea (OLTP) necesario para la lógica de la aplicación principal y BigQuery para el procesamiento analítico en línea (OLAP) de las operaciones de backend. Es posible que sea necesario implementar un flujo continuo de exportación de datos de Datastore en BigQuery a fin de mover los datos necesarios para esas consultas.
Además de la implementación alternativa para índices personalizados, también se recomienda especificar explícitamente las propiedades no indexadas (consulta Propiedades y tipos de valores). De forma predeterminada, Datastore creará una tabla de índice diferente para cada propiedad indexable de un tipo de entidad. Si tienes 100 propiedades en un tipo, habrá 100 tablas de índice en ese tipo y 100 actualizaciones adicionales cada vez que se actualice una entidad. Por lo tanto, se recomienda establecer propiedades no indexadas cuando sea posible, si no se necesitan para una condición de consulta.
Además de reducir la posibilidad de aumentar los tiempos de coherencia, estas optimizaciones de índices pueden dar lugar a una reducción bastante grande de los costos de almacenamiento de Datastore en una aplicación de gran tamaño que utiliza índices con mucha frecuencia.
Conclusión
La coherencia eventual es un elemento fundamental en las bases de datos no relacionales, que permite a los desarrolladores alcanzar un equilibrio óptimo entre escalabilidad, rendimiento y coherencia. Es importante comprender cómo manejar el equilibrio entre la coherencia eventual y sólida para diseñar un modelo de datos óptimo para tu aplicación. En Datastore, el uso de grupos de entidades y consultas principales es la mejor manera de garantizar una coherencia sólida en un alcance de entidades. Si no puedes incorporar grupos de entidad en tu aplicación debido a las limitaciones mencionadas anteriormente, puedes utilizar las opciones de consultas de solo clave o Memcache. Para aplicaciones de gran envergadura, sigue las prácticas recomendadas, como usar ID no seriales y minimizar la indexación a fin de disminuir el tiempo necesario para lograr la coherencia. También puede ser importante combinar Datastore con BigQuery para cumplir con los requisitos empresariales de consultas complejas y reducir el uso de los índices de Datastore en la medida de lo posible.
Recursos adicionales
Los siguientes recursos proporcionan más información sobre los temas que analizamos en este documento:
- Google App Engine: cómo almacenar datos
- Descripción general de Datastore
- Blog de Google Cloud Platform
- Cloud SQL
- Usa Python para App Engine con Cloud SQL
- Bigtable: un sistema de almacenamiento de datos distribuido para datos estructurados
- Lanzamiento de la versión 1.5.2 del SDK de App Engine
- Megastore: proporciona almacenamiento escalable y con alta disponibilidad para servicios interactivos
[1] Un grupo de entidad se puede formar si se especifica solo una clave de la entidad principal o raíz, sin almacenar las entidades reales para la principal o raíz, ya que las funciones de grupo de entidades se implementan según las relaciones entre claves.
[2] El límite admitido es de una actualización por segundo por grupo de entidades fuera de las transacciones o de una transacción por segundo por grupo de entidad. Si agregas varias actualizaciones en una transacción, tendrás un límite de tamaño máximo de 10 MB para la transacción y la tasa máxima de escritura del servidor de Datastore.