Equilibrar la coherencia inmediata y la retardada con Datastore
Ofrecer una experiencia de usuario coherente y aprovechar el modelo de coherencia final para escalar a grandes conjuntos de datos
En este documento se explica cómo conseguir una coherencia sólida para ofrecer una experiencia de usuario positiva, al tiempo que se adopta el modelo de coherencia final de Datastore para gestionar grandes cantidades de datos y usuarios.
Este documento está dirigido a arquitectos e ingenieros de software que quieran crear soluciones en Datastore. Para ayudar a los lectores que estén más familiarizados con las bases de datos relacionales que con los sistemas no relacionales, como Datastore, en este documento se señalan conceptos análogos en las bases de datos relacionales. En este documento se da por supuesto que tienes conocimientos básicos sobre Datastore. La forma más sencilla de empezar a usar Datastore es en Google App Engine con uno de los idiomas admitidos. Si aún no has usado App Engine, te recomendamos que leas primero la guía de introducción y la sección Almacenar datos de uno de esos lenguajes. Aunque se utiliza Python en los fragmentos de código de ejemplo, no es necesario tener experiencia en este lenguaje para poder seguir leyendo este documento.
Nota: Los fragmentos de código de este artículo usan la biblioteca de cliente de Python DB para Datastore, que ya no se recomienda. Recomendamos encarecidamente a los desarrolladores que creen aplicaciones nuevas que usen la biblioteca de cliente de NDB, que ofrece varias ventajas en comparación con esta biblioteca de cliente, como el almacenamiento automático en caché de entidades a través de la API Memcache. Si actualmente usas la biblioteca de cliente de DB antigua, consulta la guía de migración de DB a NDB.
Contenido
NoSQL y coherencia final
Coherencia final en Datastore
Consulta de ancestros y grupo de entidades
Limitaciones de los grupos de entidades y las consultas de ancestros
Alternativas a las consultas de ancestros
Minimizar el tiempo para lograr la coherencia total
Conclusión
Recursos adicionales
NoSQL y coherencia final
Las bases de datos no relacionales, también conocidas como bases de datos NoSQL, han surgido en los últimos años como una alternativa a las bases de datos relacionales. Datastore es una de las bases de datos no relacionales más utilizadas del sector. En el 2013, Datastore procesó 4,5 billones de transacciones al mes (entrada de blog de Google Cloud Platform). Proporciona un método simplificado para que los desarrolladores almacenen sus datos y accedan a ellos. El esquema flexible se asigna de manera natural a los lenguajes orientados a objetos y de secuencia de comandos. Datastore también ofrece una serie de funciones para las que las bases de datos relacionales no son las más adecuadas, como el alto rendimiento a gran escala y la alta fiabilidad.
En el caso de los desarrolladores más acostumbrados a las bases de datos relacionales, puede suponer un reto diseñar un sistema que aproveche las bases de datos no relacionales, ya que algunas características y algunas prácticas de las bases de datos no relacionales les pueden resultar relativamente desconocidas. Aunque el modelo de programación de Datastore es sencillo, es importante tener en cuenta estas características. La coherencia eventual es una de estas características y la programación para la coherencia eventual es el tema principal de este documento.
¿Qué es la coherencia final?
La consistencia final es una garantía teórica de que, siempre que no se hagan nuevas actualizaciones en una entidad, todas las lecturas de la entidad devolverán el último valor actualizado. El sistema de nombres de dominio (DNS) de Internet es un ejemplo muy conocido de un sistema con un modelo de coherencia eventual. Los servidores DNS no reflejan los valores más recientes por fuerza, sino que más bien los valores se almacenan en la memoria caché y se replican en muchos directorios por Internet. La replicación de los valores modificados a todos los clientes y servidores de DNS supone cierta dedicación de tiempo. Sin embargo, el sistema DNS es un sistema de gran popularidad que se ha convertido en uno de los pilares de Internet. Como su disponibilidad es muy alta y ha demostrado ser sumamente escalable, permite búsquedas de nombres a más de cien millones de dispositivos en toda la Internet.
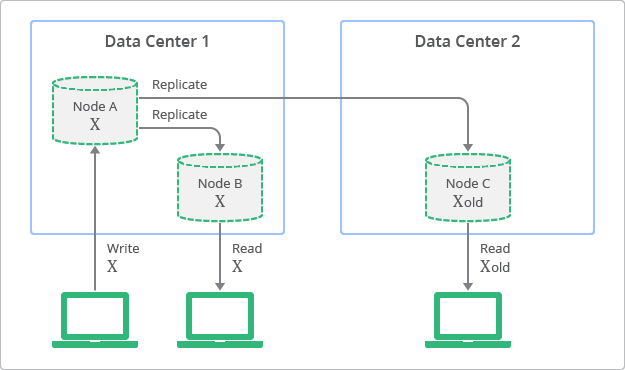
En la figura 1 se ilustra el concepto de la replicación con la coherencia eventual. El diagrama muestra que, aunque siempre hay réplicas disponibles para consultarlas, puede que en un momento concreto algunas no sean coherentes con la última modificación hecha en el nodo de origen. En el diagrama, el nodo A es el nodo de origen y los nodos B y C son las réplicas.
En contraste, las bases de datos relacionales tradicionales se han diseñado basándose en el concepto de coherencia fija, también llamado coherencia inmediata. Esto quiere decir que los datos consultados justo después de una actualización serán coherentes para todos los observadores de la entidad. Esta característica ha sido una premisa fundamental para muchos desarrolladores que utilizan bases de datos relacionales. Sin embargo, para tener una coherencia fija, los desarrolladores deben sacrificar la escalabilidad y el rendimiento de su aplicación. Dicho en pocas palabras, los datos se tienen que bloquear durante el periodo de actualización o durante el proceso de replicación para asegurarse de que ningún otro proceso esté actualizando los mismos datos.
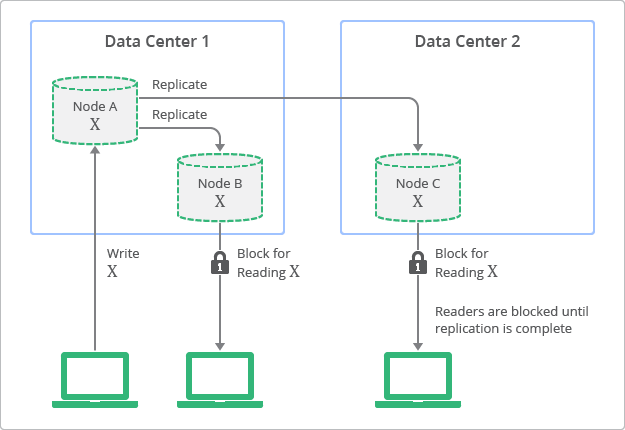
En la figura 2 se muestra una vista conceptual de la topología de implementación y del proceso de replicación con coherencia fija. En este diagrama, puedes ver que las réplicas siempre tienen valores coherentes con el nodo de origen, pero que no son accesibles hasta que finaliza la actualización.
Equilibrar la coherencia inmediata y la retardada
Las bases de datos no relacionales se han popularizado en los últimos tiempos, sobre todo para las aplicaciones web que necesitan alta escalabilidad y rendimiento con una alta disponibilidad. Las bases de datos no relacionales permiten a los desarrolladores elegir un equilibrio óptimo entre coherencia fija y eventual para cada aplicación. Esto les permite combinar las ventajas de ambos mundos. Por ejemplo, información como saber quién de tu lista de amigos está online en un momento dado o saber cuántos usuarios han hecho +1 en tu entrada son casos de uso en los que no se necesita la coherencia fija. Una forma de proporcionar escalabilidad y rendimiento para estos casos de uso es aprovechar la coherencia eventual. Los casos de uso que requieren coherencia fija incluyen información como si un usuario ha finalizado el proceso de facturación o no o el número de puntos que ha ganado un jugador durante una sesión de batalla.
Para generalizar los ejemplos que acabamos de dar, podemos decir que los casos de uso con un gran número de entidades suelen sugerir que la coherencia eventual es el modelo idóneo. Si una consulta devuelve un número muy elevado de resultados, la experiencia de usuario no se verá afectada por la inclusión o exclusión de entidades específicas. Por otro lado, los casos de uso con un pequeño número de entidades y con un contexto limitado sugieren que es necesario optar por la coherencia fija. La experiencia de usuario se verá afectada porque el contexto hará que los usuarios sean conscientes de las entidades que se deben incluir o excluir.
Por estos motivos, es importante que los desarrolladores conozcan las características no relacionales de Datastore. En las secciones siguientes se describe cómo combinar los modelos de coherencia fija y eventual para crear una aplicación escalable, de alta disponibilidad y de gran rendimiento. Si se hace así, también se cumplirán los requisitos de coherencia para lograr una experiencia de usuario positiva.
Coherencia final en Datastore
Cuando se requiere una vista de coherencia fija de los datos, se debe seleccionar la API correcta. En la tabla 1 se muestran las diferentes variedades de APIs de consulta de Datastore y sus modelos de coherencia correspondientes.
|
API del almacén de datos |
Lectura del valor de la entidad |
Lectura del índice |
|---|---|---|
|
Coherencia eventual |
Coherencia eventual |
|
|
N/A |
Coherencia eventual |
|
|
Coherencia inmediata |
Coherencia inmediata |
|
|
Coherencia inmediata |
N/A |
Las consultas de Datastore sin antecesor se conocen como consultas globales y están diseñadas para funcionar con un modelo de coherencia final. que no garantiza la coherencia fija. Una consulta global solo con claves es una consulta global que devuelve solo las claves de las entidades que coinciden con la consulta, no los valores de los atributos de las entidades. Una consulta de ancestro limita la consulta en función de una entidad de ancestro. En las siguientes secciones se analiza en más detalle cada comportamiento de coherencia.
Coherencia final al leer valores de entidades
A excepción de las consultas de antecedentes, puede que el valor actualizado de una entidad no se pueda ver de inmediato al ejecutar una consulta. Para entender el efecto de la coherencia eventual al leer los valores de entidad, imagina una situación en la que una entidad, Jugador, tiene una propiedad, Puntuación. Imagina, por ejemplo, que la Puntuación inicial tenga un valor de 100. Pasado un tiempo, el valor de Puntuación cambia a 200. Si se ejecuta una consulta global y se incluye la misma entidad Jugador en el resultado, es posible que el valor de la propiedad Puntuación de la entidad ofrecida como resultado aparezca sin cambios, en 100.
Este comportamiento se debe a la replicación entre los servidores de Datastore. Bigtable y Megastore, las tecnologías subyacentes de Datastore, gestionan la replicación (consulta Recursos adicionales para obtener más información sobre Bigtable y Megastore). La replicación se ejecuta con el algoritmo Paxos, que espera de forma síncrona hasta que la mayoría de las réplicas hayan confirmado la solicitud de actualización. La réplica se actualiza con los datos de la solicitud después de un periodo. Este periodo suele ser breve, pero no se puede garantizar su duración real. Puede que una consulta lea los datos obsoletos si se ejecuta antes de que finalice la actualización.
En muchos casos, la actualización alcanzará todas las réplicas muy rápidamente. Sin embargo, hay varios factores que, combinados, pueden prolongar el tiempo que se tarda en lograr la coherencia. Estos factores incluyen las incidencias en todo el centro de datos que impliquen cambiar una gran cantidad de servidores entre centros de datos. Teniendo en cuenta la variación de estos factores, es imposible proporcionar un requisito de tiempo definitivo para establecer la plena coherencia.
El tiempo necesario para que una consulta ofrezca el último valor suele ser muy breve. Sin embargo, en situaciones excepcionales en las que la latencia de replicación aumenta, puede ser mucho más largo. Las aplicaciones que usan consultas globales de Datastore deben diseñarse cuidadosamente para gestionar estos casos correctamente.
La coherencia eventual al leer valores de entidad se puede evitar si se usa una consulta de solo claves, una consulta de antecedente o una búsqueda por clave (método get()). Más adelante analizaremos más a fondo los diferentes tipos de consulta.
Coherencia final al leer un índice
Puede que un índice aún no esté actualizado cuando se ejecute una consulta global. Esto quiere decir que, aunque es posible que puedas leer los valores de propiedad más recientes de las entidades, la "lista de entidades" incluida en el resultado de la consulta puede estar filtrada en función de valores de índice antigu.
Para entender el impacto de la coherencia final en la lectura de un índice, imagina una situación en la que se inserta una nueva entidad, Player, en Datastore. La entidad tiene una propiedad, Puntuación, que tiene un valor inicial de 300. Inmediatamente después de la inserción, ejecutas una consulta de solo claves para obtener todas las entidades con un valor de Puntuación superior a 0. Lo previsible a continuación es que la entidad Jugador, recién insertada, aparezca en los resultados de la consulta. Sin embargo puede que, de manera imprevista, la entidad Jugador no aparezca en los resultados. Esta situación puede ocurrir cuando la tabla de índice de la propiedad Puntuación no se actualiza con el valor que se acaba de insertar en el momento de ejecución de la consulta.
Recuerda que todas las consultas de Datastore se ejecutan en tablas de índice, pero las actualizaciones de las tablas de índice son asíncronas. Cada cambio hecho en la entidad se compone, fundamentalmente, de dos fases. En la primera fase, confirmación, se realiza una modificación en el registro de transacciones. En la segunda fase, se crean datos y se actualizan los índices. Si la fase de confirmación es satisfactoria, la fase de modificación tiene garantía de éxito, aunque puede que no se produzca de inmediato. Si envías una consulta a una entidad antes de que se actualicen los índices, puede que acabes viendo datos que aún no son coherentes.
Como resultado de este proceso en dos fases, hay un retraso antes de que los últimos cambios realizados en las entidades estén visibles en las consultas globales. Al igual que con la coherencia eventual de un valor de entidad, el retraso suele ser breve, pero se puede alargar (hasta minutos o más en circunstancias excepcionales).
Lo mismo puede suceder también después de cambios. Por ejemplo, si modificas una entidad existente, Jugador, con un nuevo valor para la propiedad Puntuación de 0 y ejecutas la misma consulta justo después. Lo previsible es que la entidad no aparezca en los resultados de la consulta porque el nuevo valor de Puntuación, 0, la excluiría. Sin embargo, debido al mismo comportamiento en la modificación de índice asíncrona, es posible que la entidad se siga incluyendo en el resultado.
La coherencia eventual en la lectura de un índice solo se puede evitar si se usa un método de consulta de antecedente o de búsqueda por clave. Una consulta de solo claves no puede evitar este comportamiento.
Coherencia sólida al leer valores e índices de entidades
En Datastore, solo hay dos APIs que proporcionan una vista coherente para leer valores de entidades e índices: (1) el método de búsqueda por clave y (2) la consulta de ancestros. Si la lógica de la aplicación requiere una coherencia sólida, el desarrollador debe usar uno de estos métodos para leer entidades de Datastore.
Datastore se ha diseñado específicamente para ofrecer una coherencia inmediata en estas APIs. Cuando se llama a cualquiera de ellos, Datastore vacía todas las actualizaciones pendientes en una de las réplicas y en las tablas de índice, y, a continuación, ejecuta la consulta de búsqueda o de ancestro. Por lo tanto, el valor de entidad más reciente, basado en la tabla de índices modificada, siempre se ofrece con valores basados en las modificaciones más recientes.
La llamada de búsqueda por clave, a diferencia de las consultas, solo ofrece como resultado una entidad o un conjunto de entidades especificadas por una clave o por un conjunto de claves. Esto significa que una consulta de ancestro es la única forma de cumplir el requisito de coherencia fuerte junto con un requisito de filtrado en Datastore. Sin embargo, las consultas de ancestros no funcionan si no se especifica un grupo de entidades.
Consulta de ancestros y grupo de entidades
Como se ha explicado al principio de este documento, una de las ventajas de Datastore es que los desarrolladores pueden encontrar un equilibrio óptimo entre la coherencia fuerte y la coherencia final. En Datastore, un grupo de entidades es una unidad con coherencia inmediata, transaccionalidad y localidad. Si utilizan grupos de entidades, los desarrolladores pueden definir el ámbito de la coherencia fija entre las entidades de una aplicación. De esta manera, la aplicación puede mantener la coherencia dentro del grupo de entidades a la vez que consigue alta escalabilidad, alta disponibilidad y alto rendimiento como un sistema completo.
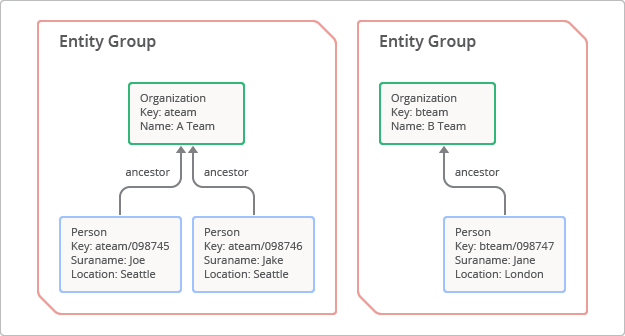
Un grupo de entidades es una jerarquía formada por una entidad raíz y sus elementos secundarios o sucesores.[1] Para crear un grupo de entidades, un desarrollador especifica una ruta de ancestro, que es, esencialmente, una serie de claves superiores que preceden a la clave secundaria. El concepto "grupo de entidades" se ilustra en la figura 3. En este caso, la entidad raíz con la clave "ateam" tiene dos elementos secundarios con las claves "ateam/098745" y "ateam/098746".
Dentro del grupo de entidades, las siguientes características están garantizadas:
-
Coherencia inmediata
- Una consulta de antecedente en el grupo de entidades ofrecerá un resultado de coherencia fija. De esta manera, se reflejan los valores de entidad más recientes filtrados por el estado de índice más reciente.
-
Transaccionalidad
- Al demarcar una transacción mediante programación, el grupo de entidades proporciona las características ACAD (atomicidad, coherencia, aislamiento y durabilidad) de la transacción.
-
Localidad
- Las entidades de un grupo de entidades se almacenarán en lugares físicamente cercanos de los servidores de Datastore, ya que todas las entidades se ordenan y almacenan según el orden lexicográfico de las claves. Esto permite que una consulta de antecedente escanee rápidamente el grupo de entidades con un número mínimo de E/S.
Una consulta de antecedente es una forma especial de consulta que solo se ejecuta tomando un grupo de entidades especificado como referencia. Se ejecuta con coherencia fija. En segundo plano, Datastore se asegura de que se apliquen todas las réplicas y actualizaciones de índices pendientes antes de ejecutar la consulta.
Ejemplo de consulta de ancestro
En esta sección se describe cómo poner en práctica los grupos de entidades y las consultas de antecedente. En el siguiente ejemplo, tenemos en cuenta el problema que supone administrar los registros de datos de personas. Supongamos que tenemos código que añade una entidad de un tipo específico seguida de inmediato de una consulta de ese tipo. Este concepto se demuestra con el código Python de ejemplo que hay a continuación.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
El problema de este código es que, en la mayoría de los casos, la consulta no ofrecerá la entidad añadida en la declaración anterior. Como la consulta sigue en la línea que va justo después de la inserción, el índice no se actualizará cuando se ejecute la consulta. Sin embargo, también hay un problema con la validez de este caso de uso, que es si de verdad hay necesidad de ofrecer una lista de todas las persona de una página sin contexto. ¿Qué ocurre si hay un millón de personas? La página tardaría demasiado en ofrecer resultados.
La naturaleza del caso de uso sugiere que debemos proporcionar algún tipo de contexto para reducir la consulta. En este ejemplo, el contexto que vamos a utilizar será la organización. En ese caso, podemos utilizar la organización como un grupo de entidades y ejecutar una consulta de antecedente, que resuelve el problema de coherencia. Esta situación se demuestra con el código Python que hay a continuación.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Esta vez, con el antecedente org especificado en GqlQuery, la consulta ofrece como resultado la entidad que se acaba de insertar. El ejemplo se podría ampliar para profundizar en una persona concreta mediante la consulta del nombre de la persona con el antecedente como parte de la consulta. De manera alternativa, esto también se podría haber hecho reservando la clave de entidad y después utilizándola para profundizar con una búsqueda por clave.
Mantener la coherencia entre Memcache y Datastore
Los grupos de entidades también se pueden usar como unidad para mantener la coherencia entre las entradas de Memcache y las entidades de Datastore. Por ejemplo, en una situación en la que se cuente el número de personas en cada equipo y se almacene en Memcache. Para asegurarse de que los datos almacenados en caché sean coherentes con los valores más recientes de Datastore, puede usar metadatos de grupo de entidades. Los metadatos ofrecen el número de la versión más reciente del grupo de entidades especificado. Puedes comparar el número de versión con el número almacenado en Memcache. Con este método, puedes detectar un cambio en cualquiera de las entidades de todo el grupo de entidades con tan solo leer un conjunto de metadatos, en vez de escanear las entidades del grupo una a una.
Limitaciones de las consultas de grupos de entidades y ancestros
El método que consiste en utilizar grupos de entidades y consultas de antecedente no es la panacea. En la práctica hay dos dificultades que hacen que sea difícil aplicar la técnica en general, como se indica a continuación.
- Las actualizaciones están limitadas a una por segundo para cada grupo de entidades.
- La relación del grupo de entidades no se puede cambiar después de crear una entidad.
Límite de escritura
Un problema importante es que el sistema tiene que estar diseñado para contener el número de modificaciones (o transacciones) de cada grupo de entidades. El límite admitido es de una actualización por segundo por grupo de entidades.[2] Si el número de actualizaciones debe superar ese límite, el grupo de entidades puede convertirse en un cuello de botella del rendimiento.
En el ejemplo anterior, cada organización podría tener que modificar el registro de cualquier persona de la organización. Imagina una situación en la que haya 1.000 personas en el "ateam" y que cada persona tuviera una modificación por segundo en cualquiera de las propiedades. Como resultado, podría haber hasta 1.000 modificaciones por segundo en el grupo de entidades, un resultado que no se podría lograr debido al límite de modificaciones. Esto pone de manifiesto la importancia de elegir un diseño adecuado para los grupos de entidades que tenga en cuenta los requisitos de rendimiento. Esta es una de las dificultades a la hora de encontrar el equilibrio idóneo entre la coherencia eventual y la coherencia fija.
Inmutabilidad de las relaciones de grupos de entidades
Una segunda dificultad es la inmutabilidad de las relaciones del grupo de entidades. La relación del grupo de entidades se forma de manera estática en función de los nombres clave. No se puede cambiar después de crear la entidad. La única opción disponible para cambiar la relación es eliminar las entidades de un grupo de entidades y volver a crearlas. Esta dificultad nos impide usar los grupos de entidades para definir de manera dinámica ámbitos a medida para la coherencia o para la transaccionalidad. En cambio, el ámbito de la coherencia o de la transaccionalidad está estrechamente vinculado al grupo de entidades estático que se define en el momento de diseñar.
Pongamos como ejemplo una situación en la que quieras realizar una transferencia bancaria entre dos cuentas. Esta situación empresarial exige coherencia fija y transaccionalidad. Sin embargo, las dos cuentas no se pueden agrupar en un grupo de entidades en el último momento ni basarse en un elemento superior global. Ese grupo de entidades crearía un cuello de botella en todo el sistema que entorpecería la ejecución de otras solicitudes de transferencias bancarias. Por lo tanto, los grupos de entidades no se pueden utilizar en este modo.
Hay una forma alternativa de implementar una transferencia bancaria de forma altamente escalable y disponible. En lugar de colocar todas las cuentas en un solo grupo de entidades, puedes crear un grupo de entidades para cada cuenta. De esta forma, puedes usar transacciones para asegurarte de que las actualizaciones ACID se apliquen a ambas cuentas bancarias. Las transacciones son una función de Datastore que te permite crear conjuntos de operaciones con características ACID para un máximo de 25 grupos de entidades. Ten en cuenta que, en una transacción, debes usar consultas con coherencia fuerte, como las búsquedas por clave y las consultas de ancestros. Para obtener más información sobre las restricciones de las transacciones, consulta Transacciones y grupos de entidades.
Alternativas a las consultas de ancestros
Si ya tienes una aplicación con un gran número de entidades almacenadas en Datastore, puede que te resulte difícil incorporar grupos de entidades más adelante en una refactorización. Haría falta eliminar todas las entidades y añadirlas dentro de una relación del grupo de entidades. Por lo tanto, en el modelado de datos de Datastore, es importante tomar una decisión sobre el diseño del grupo de entidades en la fase inicial del diseño de la aplicación. De lo contrario, puede que en la refactorización te veas limitado a otras alternativas para lograr un cierto nivel de coherencia, como puede ser una consulta de solo claves seguida de una búsqueda por clave o seguida del uso de Memcache.
Consulta global para obtener solo las claves seguida de una búsqueda por clave
Una consulta global de solo claves es un tipo especial de consulta global que solo ofrece como resultado las claves sin los valores de propiedad de las entidades. Como los valores ofrecidos son solo claves, la consulta no implica un valor de entidad con un posible problema de coherencia. Una combinación de la consulta global de solo claves con un método de búsqueda leerá los valores de entidad más recientes. De cualquier modo, se debe señalar que una consulta global de solo claves no puede excluir la posibilidad de que un índice aún no sea coherente en el momento de la consulta, que podría provocar que una entidad no se obtuviera en absoluto. Habría probabilidades de que el resultado de la consulta se generara basándose en un filtrado para excluir los valores de índice antiguos. En resumen, un desarrollador solo puede utilizar consultas globales de solo claves seguidas de una búsqueda por clave cuando un requisito de la aplicación permita que el valor de índice aún no sea coherente en el momento de realizar una consulta.
Usar Memcache
El servicio de Memcache es volátil, pero muy coherente. Por lo tanto, si combinas las búsquedas de Memcache y las consultas de Datastore, puedes crear un sistema que minimice los problemas de coherencia la mayoría de las veces.
Utilizaremos como ejemplo una aplicación de juego que mantiene una lista de entidades Jugador, cada una con una puntuación superior a cero.
- En el caso de las solicitudes de inserción o actualización, aplícalas a la lista de entidades Player en Memcache y en Datastore.
- En el caso de las solicitudes de consulta, lee la lista de entidades Player de Memcache y ejecuta una consulta de solo claves en Datastore cuando la lista no esté en Memcache.
La lista ofrecida será coherente siempre que la lista almacenada en la memoria caché esté presente en Memcache. Si la entrada se ha expulsado o el servicio Memcache no está disponible temporalmente, es posible que el sistema tenga que leer el valor de una consulta de Datastore que podría devolver un resultado incoherente. Esta técnica se puede aplicar a cualquier aplicación que tolere una pequeña cantidad de incoherencia.
A continuación, se indican algunas prácticas recomendadas para usar Memcache como capa de almacenamiento en caché de Datastore:
- Captura las excepciones y los errores de Memcache para mantener la coherencia entre el valor de Memcache y el valor de Datastore. Si recibes una excepción al actualizar la entrada en Memcache, asegúrate de invalidar la entrada anterior en Memcache. De lo contrario, puede haber valores diferentes para una entidad (un valor antiguo en Memcache y un valor nuevo en Datastore).
- Define un periodo de vencimiento en las entradas de Memcache. Se recomienda establecer periodos cortos para la caducidad de cada entrada para minimizar la posibilidad de que haya incoherencias en el caso de las excepciones de Memcache.
- Usa la función comparar y definir al actualizar las entradas para controlar la simultaneidad. Así ayudarás a garantizar que las modificaciones simultáneas hechas en la misma entrada no interfieran entre sí.
Migración gradual a grupos de entidades
Las sugerencias hechas en la sección anterior solo disminuyen la posibilidad de que se produzca un comportamiento incoherente. La mejor opción cuando se necesite coherencia fija es diseñar la aplicación basándose en grupos de entidades y en consultas de antecedente. Sin embargo, puede que no sea factible migrar una aplicación existente, que podría incluir el cambio de un modelo de datos existente y la lógica de la aplicación para pasar de consultas globales a consultas de antecedente. Una forma de lograr este objetivo es llevar a cabo un proceso de transición gradual, como podría ser el siguiente:
- Identificar y priorizar las funciones de la aplicación que necesitan coherencia fija.
- Escribir lógica nueva para las funciones insert() o update() mediante grupos de entidades además de la lógica existente (en vez de sustituirla). De esta manera, todas las inserciones o las modificaciones nuevas que se hagan tanto en los nuevos grupos de entidades como en las entidades antiguas se pueden gestionar con una función adecuada.
- Modificar la lógica existente para las funciones de lectura o de consulta. Las consultas de antecedente se realizan en primer lugar si existe un nuevo grupo de entidades para la solicitud. Ejecuta la consulta global antigua como lógica de respaldo si el grupo de entidades no existe.
Esta estrategia permite una migración gradual desde un modelo de datos existente a un nuevo modelo de datos basado en grupos de entidades. Esta migración minimiza el riesgo de problemas causados por la coherencia eventual. En la práctica, este método depende de casos de uso y de requisitos específicos para su aplicación a un sistema real.
Cambiar al modo Degradado
En la actualidad, es difícil detectar una situación con programación si una aplicación tiene la coherencia deteriorada. Sin embargo, si determina por otros medios que una aplicación ha deteriorado la coherencia, puede implementar un modo degradado que se pueda activar o desactivar para inhabilitar algunas áreas de la lógica de la aplicación que requieran una coherencia sólida. Por ejemplo, en vez de mostrar un resultado de consulta incoherente en una pantalla de informes de facturación, se podría mostrar un mensaje de mantenimiento para esa pantalla en concreto. De esta manera, el resto de servicios de la aplicación puede seguir funcionando y, a su vez, se reducen los efectos negativosen la experiencia de usuario.
Minimizar el tiempo necesario para lograr una coherencia total
En una aplicación grande con millones de usuarios o terabytes de entidades de Datastore, es posible que un uso inadecuado de Datastore provoque una coherencia deteriorada. Estas son algunas de esas prácticas:
- numeración secuencial en claves de entidad,
- demasiados índices.
Estas prácticas no afectan a las pequeñas aplicaciones. Sin embargo, cuando la aplicación crece hasta hacerse muy grande, estas prácticas aumentan la posibilidad de que hagan falta tiempos más largos para lograr la coherencia. Por eso es mejor evitarlas en las primeras fases del diseño de la aplicación.
Antipatrón 1: numeración secuencial de claves de entidad
Antes del lanzamiento del SDK de App Engine 1.8.1, Datastore usaba una secuencia de IDs de números enteros pequeños con patrones generalmente consecutivos como nombres de clave predeterminados generados automáticamente. En algunos documentos esto se llama "política heredada" para crear entidades que no tienen nombre de clave especificado para la aplicación. Esta política heredada generaba nombres de clave de entidad con numeración secuencial, como, por ejemplo, 1.000, 1.001, 1.002. Sin embargo, como hemos comentado anteriormente, Datastore almacena las entidades por el orden lexicográfico de los nombres de las claves, por lo que es muy probable que esas entidades se almacenen en los mismos servidores de Datastore. Si una aplicación atrae mucho tráfico, esta numeración secuencial podría provocar una concentración de operaciones en un servidor específico, que, a su vez, puede provocar una latencia más larga para la coherencia.
En el SDK de App Engine 1.8.1, Datastore introdujo un nuevo método de numeración de IDs con una política predeterminada que usa IDs dispersos (consulta la documentación de referencia). Esta política predeterminada genera una secuencia aleatoria de ID de hasta 16 dígitos que se distribuyen de manera más o menos uniforme. Con esta política, es probable que el tráfico de la aplicación grande se distribuya mejor entre un conjunto de servidores de Datastore, lo que reducirá el tiempo necesario para lograr la coherencia. Se recomienda utilizar la política predeterminada a menos que tu aplicación requiera específicamente compatibilidad con la política heredada.
Si estableces explícitamente nombres de clave en entidades, el esquema de nombres se debe diseñar para acceder a las entidades de manera uniforme en todo el espacio de nombres de clave. Dicho de otro modo, no concentres el acceso en un intervalo determinado, ya que se ordenan según el orden lexicográfico de los nombres clave. De lo contrario, podría surgir el mismo problema que con la numeración secuencial.
Para entender la distribución no uniforme del acceso en el espacio de claves, imagina un ejemplo en el que las entidades se creen con los nombres de clave secuenciales que se muestran en el siguiente código:
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
El patrón de acceso de la aplicación puede crear una "zona activa" en un intervalo determinado de los nombres de clave, como tener el acceso concentrado en las entidades Person de reciente creación. En este caso, todas las claves a las que se acceda a menudo tendrán ID más altos. La carga puede concentrarse en un servidor de Datastore específico.
De manera alternativa, para entender la distribución uniforme en el espacio de claves, imagina que se utilizan largas cadenas aleatorias para los nombres de clave. Esto se ilustra en el siguiente ejemplo:
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
Ahora las entidades Person recién creadas se dispersarán en el espacio de claves y en varios servidores. En este caso se da por supuesto que hay un número de entidades Person lo bastante alto.
Antipatrón 2: demasiados índices
En Datastore, una actualización de una entidad provocará la actualización de todos los índices definidos para ese tipo de entidad. Si una aplicación utiliza muchos índices personalizados, una modificación podría implicar decenas, centenares o incluso miles de modificaciones en las tablas de índices. En una aplicación grande, un uso excesivo de índices personalizados podría resultar en un aumento de la carga en el servidor y podría aumentar la latencia para lograr la coherencia.
En la mayoría de los casos, se añaden índices personalizados para cumplir requisitos tales como las tareas de asistencia al cliente, de solución de problemas o de análisis de datos. BigQuery es un motor de consultas masivamente escalable capaz de ejecutar consultas ad hoc en grandes conjuntos de datos sin índices precompilados. Es más adecuada para casos prácticos como la asistencia al cliente, la resolución de problemas o el análisis de datos que requieren consultas complejas que Datastore.
Una práctica recomendada es combinar Datastore y BigQuery para satisfacer diferentes requisitos empresariales. Usa Datastore para el procesamiento de transacciones online (OLTP) que requiere la lógica principal de la aplicación y BigQuery para el procesamiento analítico online (OLAP) de las operaciones de backend. Puede que sea necesario implementar un flujo de exportación de datos continuo de Datastore a BigQuery para mover los datos necesarios para esas consultas.
Además de una implementación alternativa para los índices personalizados, otra recomendación es especificar las propiedades sin indexar de forma explícita (consulta Propiedades y tipos de valor). De forma predeterminada, Datastore creará una tabla de índice diferente para cada propiedad indexable de un tipo de entidad. Si tienes 100 propiedades de una clase, habrá 100 tablas de índices de ese tipo y 100 modificaciones adicionales por cada modificación que se haga en una entidad. Por lo tanto, una práctica recomendada es establecer propiedades no indexadas siempre que sea posible y si no son necesarias para una condición de consulta.
Además de reducir la posibilidad de que aumenten los tiempos de coherencia, estas optimizaciones de índices pueden suponer una reducción considerable de los costes de almacenamiento de Datastore en una aplicación grande que utilice muchos índices.
Conclusión
La coherencia eventual es un elemento esencial de las bases de datos no relacionales que permite a los desarrolladores encontrar un equilibrio óptimo entre la escalabilidad, el rendimiento y la coherencia. Es importante entender cómo se gestiona el equilibrio entre la coherencia eventual y la coherencia fija para diseñar un modelo de datos que sea idóneo para tu aplicación. En Datastore, el uso de grupos de entidades y consultas de ancestros es la mejor forma de garantizar una coherencia sólida en un ámbito de entidades. Si la aplicación no puede incluir grupos de entidades debido a las limitaciones descritas antes, puedes plantearte otras opciones como el uso de consultas de solo claves o de Memcache. En el caso de las aplicaciones de gran tamaño, sigue prácticas recomendadas como, por ejemplo, el uso de ID dispersos y la indexación reducida para disminuir el tiempo necesario para lograr la coherencia. También puede ser importante combinar Datastore con BigQuery para cumplir los requisitos empresariales de consultas complejas y reducir el uso de índices de Datastore en la medida de lo posible.
Recursos adicionales
Los siguientes recursos proporcionan más información sobre los temas tratados en este documento:
- Google App Engine: almacenar datos
- Información general sobre Datastore
- Blog de Google Cloud Platform
- Cloud SQL
- Usar Python App Engine con Cloud SQL
- Bigtable: un sistema de almacenamiento distribuido para datos estructurados
- Lanzamiento del SDK de App Engine 1.5.2
- Megastore: almacenamiento escalable y de alta disponibilidad para servicios interactivos
[1] Un grupo de entidades se puede formar especificando solo una clave de la entidad raíz o principal, sin almacenar las entidades reales de la raíz o del elemento principal, ya que todas las funciones del grupo de entidades se implementan en función de las relaciones entre las claves.
[2] El límite admitido es una actualización por segundo por grupo de entidades fuera de las transacciones o una transacción por segundo por grupo de entidades. Si unes varias modificaciones en una transacción, estás limitado a un tamaño máximo de transacción de 10 MB y a la velocidad máxima de escritura del servidor del almacén de datos.