In dieser Anleitung wird eine Strategie für dualregionale Notfallwiederherstellung und Geschäftskontinuität mithilfe von Dataproc Metastore vorgeschlagen. In der Anleitung werden dualregionale Buckets zum Speichern von Hive-Datasets und Hive-Metadatenexporten verwendet.
Dataproc Metastore ist ein vollständig verwalteter, hochverfügbarer, automatisch skalierter, OSS-nativer Metastore-Dienst mit automatischer Reparatur, der die technische Metadatenverwaltung erheblich vereinfacht. Der verwaltete Dienst basiert auf Apache Hive Metastore und dient als wichtige Komponente für Data Lakes in Unternehmen.
Diese Anleitung richtet sich an Google Cloud Kunden, die eine hohe Verfügbarkeit für ihre Hive-Daten und -Metadaten benötigen. Dabei werden Cloud Storage für die Speicherung, Dataproc für die Berechnung und Dataproc Metastore (DPMS), ein vollständig verwalteter Hive Metastore-Dienst in Google Cloud, verwendet. Die Anleitung bietet außerdem zwei verschiedene Möglichkeiten zur Orchestrierung von Failovers: eine mit Cloud Run und Cloud Scheduler und eine mit Cloud Composer.
Der in dieser Anleitung verwendete dualregionale Ansatz hat Vor- und Nachteile:
Vorteile
- Dualregionale Buckets sind georedundant.
- Dualregionale Buckets haben ein SLA für eine Verfügbarkeit von 99,95 %, verglichen mit einer Verfügbarkeit von 99,9 % für Buckets mit nur einer Region.
- Dualregionale Buckets haben eine optimierte Leistung in zwei Regionen, während Einzelregion-Buckets bei der Arbeit mit Ressourcen in anderen Regionen nicht so gut funktionieren.
Nachteile
- Schreibvorgänge für dualregionale Buckets werden nicht sofort in beiden Regionen repliziert.
- Dualregionale Buckets haben höhere Speicherkosten als Buckets mit nur einer Region.
Referenzarchitektur
Die folgenden Architekturdiagramme zeigen die Komponenten, die Sie in dieser Anleitung verwenden. In beiden Diagrammen gibt das große rote X den Ausfall der primären Region an:
 Abbildung 1: Cloud Run und Cloud Scheduler verwenden
Abbildung 1: Cloud Run und Cloud Scheduler verwenden
 Abbildung 2: Cloud Composer verwenden
Abbildung 2: Cloud Composer verwenden
Die Komponenten der Lösung und ihre Beziehungen:
- Zwei dualregionale Cloud Storage-Buckets: Sie erstellen einen Bucket für die Hive-Daten und einen Bucket für die regelmäßigen Sicherungen der Hive-Metadaten. Erstellen Sie beide dualregionale Buckets so, dass sie dieselben Regionen verwenden wie die Hadoop-Cluster, die auf die Daten zugreifen.
- Ein Hive-Metastore mit DPMS: Sie erstellen diesen Hive-Metastore in Ihrer primären Region (Region A). Die Metastore-Konfiguration verweist auf Ihren Hive-Daten-Bucket. Ein Hadoop-Cluster, der Dataproc verwendet, muss sich in derselben Region befinden wie die DPMS-Instanz, an die er angehängt ist.
- Eine zweite DPMS-Instanz: Sie erstellen eine zweite DPMS-Instanz in Ihrer Standby-Region (Region B), um einen Ausfall in der gesamten Region vorzubereiten. Anschließend importieren Sie die neueste
hive.sql-Exportdatei aus Ihrem Export-Bucket in den Standby-DPMS. Außerdem erstellen Sie einen Dataproc-Cluster in Ihrer Standby-Region und hängen ihn an Ihre Standby-DPMS-Instanz an. Im Szenario einer Notfallwiederherstellung leiten Sie Ihre Clientanwendungen schließlich von Ihrem Dataproc-Cluster in Region A an Ihren Dataproc-Cluster in Region B weiter. Cloud Run-Bereitstellung: Sie erstellen eine Cloud Run-Bereitstellung in Region A, die die DPMS-Metadaten mit Cloud Scheduler regelmäßig in einen Metadaten-Sicherungs-Bucket exportiert (siehe Abbildung 1). Der Export erfolgt in Form einer SQL-Datei, die einen vollständigen Dump der DPMS-Metadaten enthält.
Wenn Sie bereits eine Cloud Composer-Umgebung haben, können Sie Ihre DPMS-Metadatenexporte und -importe orchestrieren, indem Sie einen Airflow-DAG für diese Umgebung ausführen (siehe Abbildung 2). Diese Verwendung eines Airflow-DAG würde anstelle der zuvor erwähnten Cloud Run-Methode erfolgen.
Ziele
- Dualregionalen Speicher für Hive-Daten und Hive Metastore-Sicherungen einrichten
- Einen Dataproc Metastore- und einen Dataproc-Cluster in den Regionen A und B bereitstellen
- Failover der Bereitstellung in Region B ausführen
- Failback der Bereitstellung in Region A ausführen
- Automatisierte Hive-Metastore-Sicherungen erstellen
- Exporte und Importe von Metadaten über Cloud Run orchestrieren
- Metadatenexporte und -importe über Cloud Composer orchestrieren
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Starten Sie in Cloud Shell eine Cloud Shell-Instanz.
Klonen Sie das GitHub-Repository der Anleitung:
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.gitAktivieren Sie die folgenden Google Cloud APIs:
gcloud services enable dataproc.googleapis.com metastore.googleapis.comLegen Sie einige Umgebungsvariablen fest:
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Umgebung initialisieren
Speicher für Hive-Daten und Hive Metastore-Sicherungen erstellen
In diesem Abschnitt erstellen Sie Cloud Storage-Buckets zum Hosten der Hive-Daten und Hive Metastore-Sicherungen.
Hive-Datenspeicher erstellen
Erstellen Sie in Cloud Shell einen dualregionalen Bucket zum Hosten der Hive-Daten:
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4Kopieren Sie einige Beispieldaten in den Hive-Daten-Bucket:
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
Speicher für Metadatensicherungen erstellen
Erstellen Sie in Cloud Shell einen dualregionalen Bucket zum Hosten der DPMS-Metadatensicherungen:
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
Rechenressourcen in der primären Region bereitstellen
In diesem Abschnitt stellen Sie alle Compute-Ressourcen in der primären Region bereit, einschließlich der DPMS-Instanz und des Dataproc-Clusters. Sie füllen den Dataproc Metastore auch mit Beispielmetadaten.
DPMS-Instanz erstellen
Erstellen Sie in Cloud Shell die DPMS-Instanz:
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2Das Ausführen des Befehls kann einige Minuten dauern.
Legen Sie den Hive-Daten-Bucket als Standard-Warehouse-Verzeichnis fest:
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"Das Ausführen des Befehls kann einige Minuten dauern.
Dataproc-Cluster erstellen
Erstellen Sie in Cloud Shell einen Dataproc-Cluster und hängen Sie ihn an die DPMS-Instanz an:
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.0Geben Sie das Cluster-Image als Version 2.0 an. Dies ist die neueste Version ab Juni 2021. Es ist auch die erste Version, die DPMS unterstützt.
Metastore füllen
Aktualisieren Sie in Cloud Shell die im Repository dieser Anleitung bereitgestellte Beispieldatei
retail.hqlmit dem Namen des Hive-Daten-Buckets:sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hqlFühren Sie die in der Datei
retail.hqlenthaltenen Abfragen aus, um die Tabellendefinitionen im Metastore zu erstellen:gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hqlPrüfen Sie, ob die Tabellendefinitionen korrekt erstellt wurden:
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "Die Ausgabe sollte so aussehen:
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
Die Ausgabe enthält auch die Anzahl der Elemente in jeder Tabelle, zum Beispiel:
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
Failover zur Standby-Region ausführen
In diesem Abschnitt werden die Schritte für den Failover von der primären Region (Region A) zur Standby-Region (Region B) beschrieben.
Exportieren Sie in Cloud Shell die Metadaten der primären DPMS-Instanz in den Sicherungs-Bucket:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}Die Ausgabe sollte so aussehen:
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDEDNotieren Sie sich den Wert im Attribut
destinationGcsUri. Mit diesem Attribut wird die von Ihnen erstellte Sicherung gespeichert.Erstellen Sie eine neue DPMS-Instanz in der Standby-Region:
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2Legen Sie den Hive-Daten-Bucket als Standard-Warehouse-Verzeichnis fest:
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"Rufen Sie den Pfad der letzten Metadatensicherung ab:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importieren Sie die gesicherten Metadaten in die neue Dataproc Metastore-Instanz:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Erstellen Sie einen Dataproc-Cluster in der Standby-Region (Region B):
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0Prüfen Sie, ob die Metadaten korrekt importiert wurden:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"Die
num_orders-Ausgabe ist für die Anleitung am wichtigsten. Sie sieht in etwa so aus:+-------------+ | num_orders | +-------------+ | 68883 | +-------------+Der primäre Dataproc Metastore wurde zum neuen Standby-Metastore und der Standby-Dataproc Metastore zum neuen primären Metastore.
Aktualisieren Sie die Umgebungsvariablen anhand der neuen Rollen:
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1Prüfen Sie, ob Sie in den neuen primären Dataproc Metastore in Region B schreiben können:
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"Die Ausgabe enthält Folgendes:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
Der Failover ist jetzt abgeschlossen. Sie sollten nun Ihre Clientanwendungen an den neuen primären Dataproc-Cluster in Region B weiterleiten, indem Sie Ihre Hadoop-Client-Konfigurationsdateien aktualisieren.
Failback zur ursprünglichen Region ausführen
In diesem Abschnitt wird beschrieben, wie Sie zur ursprünglichen Region (Region A) zurückkehren.
Exportieren Sie in Cloud Shell die Metadaten aus der DPMS-Instanz:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}Rufen Sie den Pfad der letzten Metadatensicherung ab:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importieren Sie die Metadaten in die Standby-DPMS-Instanz in der ursprünglichen Region (Region A):
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Prüfen Sie, ob die Metadaten korrekt importiert wurden:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"Die Ausgabe enthält die folgenden Informationen:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
Der primäre Dataproc Metastore und der Standby-Dataproc Metastore haben wieder ihre Rollen getauscht.
Aktualisieren Sie die Umgebungsvariablen für diese neuen Rollen:
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Der Failback ist jetzt abgeschlossen. Sie sollten Ihre Clientanwendungen jetzt an den neuen primären Dataproc-Cluster in Region A weiterleiten, indem Sie die Konfigurationsdateien für den Hadoop-Client aktualisieren.
Automatisierte Metadatensicherungen erstellen
In diesem Abschnitt werden zwei verschiedene Methoden zur Automatisierung von Exporten und Importen von Metadatensicherungen beschrieben. Die erste Methode, Option 1: Cloud Run und Cloud Scheduler, verwendet Cloud Run und Cloud Scheduler. Die zweite Methode, Option 2: Cloud Composer, verwendet Cloud Composer. In beiden Beispielen erstellt ein Exportjob eine Sicherung der Metadaten aus dem primären DPMS in Region A. Ein Importjob füllt den Standby-DPMS in Region B anhand der Sicherung.
Wenn Sie bereits einen Cloud Composer-Cluster haben, sollten Sie sich "Option 2: Cloud Composer" ansehen (vorausgesetzt, der Cluster hat genügend Rechenkapazität). Fahren Sie andernfalls mit "Option 1: Cloud Run und Cloud Scheduler" fort. Diese Option verwendet ein "Pay as you go"-Preismodell und ist kostengünstiger als Cloud Composer, für das nichtflüchtige Rechenressourcen erforderlich sind.
Option 1: Cloud Run und Cloud Scheduler
In diesem Abschnitt wird gezeigt, wie Sie mit Cloud Run und Cloud Scheduler die Exporte von Importen von DPMS-Metadaten automatisieren.
Cloud Run-Dienste
In diesem Abschnitt wird gezeigt, wie Sie zwei Cloud Run-Dienste erstellen, um die Metadaten-Export- und -Importjobs auszuführen.
Aktivieren Sie in Cloud Shell die Cloud Run-, Cloud Scheduler-, Cloud Build- und App Engine-APIs:
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.comSie aktivieren die App Engine API, da der Cloud Scheduler-Dienst App Engine erfordert.
Erstellen Sie das Docker-Image mit dem bereitgestellten Dockerfile:
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_drStellen Sie das Container-Image für einen Cloud Run-Dienst in der primären Region (Region A) bereit. Diese Bereitstellung ist für das Erstellen der Metadatensicherungen aus dem primären Metastore zuständig:
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10mBei einer Cloud Run-Dienstanfrage ist standardmäßig nach 5 Minuten das Zeitlimit überschritten. Damit alle Anfragen genügend Zeit haben, um erfolgreich abzuschließen, wird das Zeitlimit im vorherigen Codebeispiel auf mindestens zehn Minuten verlängert.
Rufen Sie die Bereitstellungs-URL für den Cloud Run-Dienst ab:
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}Erstellen Sie einen zweiten Cloud Run-Dienst in der Standby-Region (Region B). Dieser Dienst ist für den Import der Metadatensicherungen aus
BACKUP_BUCKETin den Standby-Metastore zuständig:gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10mRufen Sie die Bereitstellungs-URL für den zweiten Cloud Run-Dienst ab:
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
Jobs planen
In diesem Abschnitt wird gezeigt, wie Sie mit Cloud Scheduler die beiden Cloud Run-Dienste auslösen.
Erstellen Sie in Cloud Shell eine App Engine-Anwendung, die von Cloud Scheduler benötigt wird:
gcloud app create --region=${REGION_A}Erstellen Sie einen Cloud Scheduler-Job, um die Metadatenexporte aus dem primären Metastore zu planen:
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
Der Cloud Scheduler-Job sendet alle 15 Minuten eine http-Anfrage an den Cloud Run-Dienst. Der Cloud Run-Dienst führt eine containerisierte Flask-Anwendung mit einer Export- und Importfunktion aus. Wenn die Exportfunktion ausgelöst wird, exportiert sie die Metadaten mit dem Befehl gcloud metastore services export in Cloud Storage.
Wenn Ihre Hadoop-Jobs häufig in den Hive Metastore schreiben, empfehlen wir im Allgemeinen, Ihren Metastore häufig zu sichern. Ein guter Zeitplan für die Sicherung liegt im Bereich von 15 Minuten bis 60 Minuten.
Lösen Sie einen Testlauf des Cloud Run-Dienstes aus:
gcloud scheduler jobs run dpms-exportPrüfen Sie, ob Cloud Scheduler den DPMS-Exportvorgang korrekt ausgelöst hat:
gcloud metastore operations list --location ${REGION_A}Die Ausgabe sollte so aussehen:
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
Wenn der Wert für
DONEFalselautet, wird der Export noch ausgeführt. Um zu bestätigen, dass Vorgang abgeschlossen ist, führen Sie den Befehlgcloud metastore operations list --location ${REGION_A}so lange aus, bis der WertTrueist.Weitere Informationen zu
gcloud metastore operations-Befehlen finden Sie in der Referenzdokumentation.(Optional) Erstellen Sie einen Cloud Scheduler-Job, um die Importe in den Standby-Metastore zu planen:
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
Dieser Schritt hängt von Ihren RTO-Anforderungen (Recovery Time Objective) ab.
Wenn Sie ein Hot-Standby möchten, um die Failover-Zeit zu minimieren, sollten Sie diesen Importjob planen. Er aktualisiert den Standby-DPMS alle 15 Minuten.
Wenn ein Cold-Standby für Ihre RTO-Anforderungen ausreichend ist, können Sie diesen Schritt überspringen und außerdem Ihren Standby-DPMS und Ihren Dataproc-Cluster löschen, um die monatliche Gesamtrechnung weiter zu reduzieren. Stellen Sie bei einem Failover zur Standby-Region (Region B) den Standby-DPMS und den Dataproc-Cluster bereit und führen Sie auch einen Importjob aus. Da die Sicherungsdateien in einem dualregionalen Bucket gespeichert sind, sind sie auch dann zugänglich, wenn Ihre primäre Region (Region A) ausfällt.
Failovers ausführen
Nach dem Failover zu Region B müssen Sie die folgenden Schritte ausführen, um Ihre Notfallwiederherstellungsanforderungen und die Infrastruktur vor einem möglichen Ausfall in Region B zu schützen:
- Pausieren Sie Ihre vorhandenen Cloud Scheduler-Jobs.
- Aktualisieren Sie die DPMS-Region der primären Instanz auf Region B (
us-east1). - Aktualisieren Sie die DPMS-Region der Standby-Instanz auf Region A (
us-central1). - Aktualisieren Sie die primäre DPMS-Instanz auf
dpms2. - Aktualisieren Sie die DPMS-Standby-Instanz auf
dpms1. - Stellen Sie die Cloud Run-Dienste anhand der aktualisierten Variablen noch einmal bereit.
- Erstellen Sie neue Cloud Scheduler-Jobs, die auf Ihre neuen Cloud Run-Dienste verweisen.
Die in der vorherigen Liste erforderlichen Schritte wiederholen viele Schritte aus den vorherigen Abschnitten, nur mit geringfügigen Anpassungen (z. B. dem Austausch der Regionsnamen). Verwenden Sie die Informationen in "Option 1: Cloud Run und Cloud Scheduler", um diese erforderliche Arbeit auszuführen.
Option 2: Cloud Composer
In diesem Abschnitt erfahren Sie, wie Sie mit Cloud Composer die Export- und Importjobs in einem einzigen gerichteten azyklischen Graphen (Directed Acyclic Graph, DAG) in Airflow ausführen.
Aktivieren Sie die Cloud Scheduler API in Cloud Shell:
gcloud services enable composer.googleapis.comErstellen Sie eine Cloud Composer-Umgebung:
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3- Das Composer-Image
composer-1.17.0-preview.1-airflow-2.0.1ist die neueste Version zum Zeitpunkt der Veröffentlichung. - Composer-Umgebungen können nur eine Hauptversion von Python verwenden. Python 3 wurde ausgewählt, da Python 2 Unterstützungsprobleme hat.
- Das Composer-Image
Konfigurieren Sie die Cloud Composer-Umgebung mit den folgenden Umgebungsvariablen:
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}Laden Sie die DAG-Datei in Ihre Composer-Umgebung hoch:
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.pyRufen Sie die Airflow-URL ab:
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"Öffnen Sie in Ihrem Browser die URL, die vom vorherigen Befehl zurückgegeben wurde.
Sie sollten einen neuen DAG-Eintrag namens
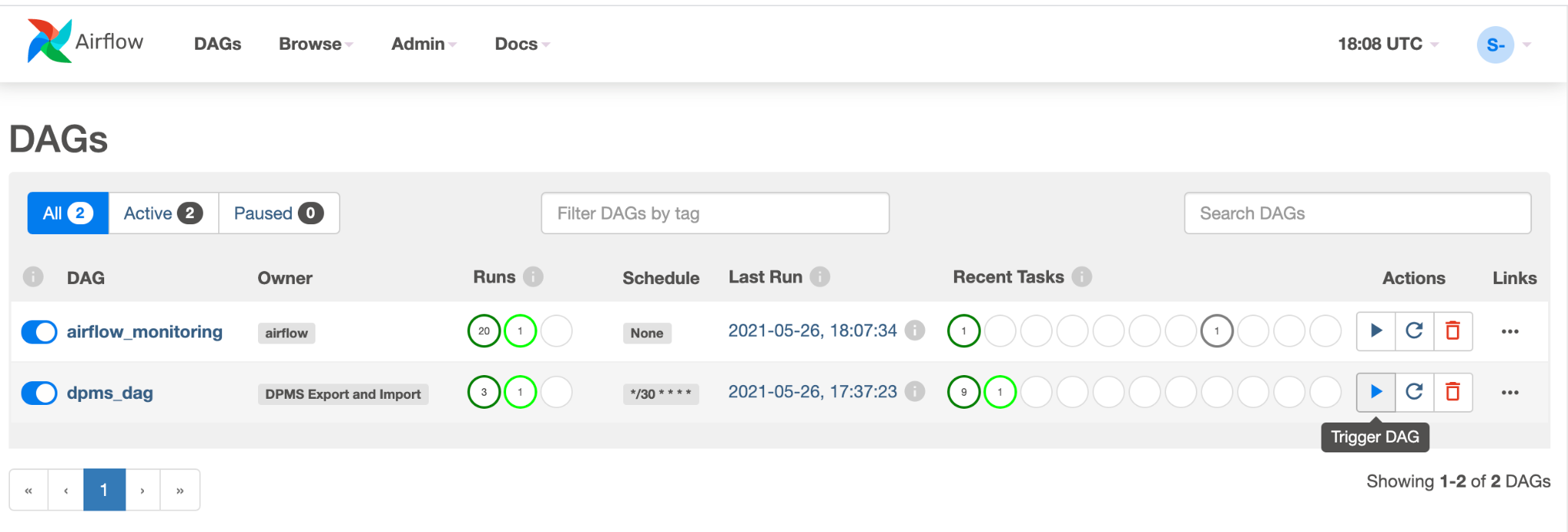
dpms_dagsehen. Innerhalb einer einzelnen Ausführung führt der DAG einen Export gefolgt von einem Import aus. Der DAG geht davon aus, dass der Standby-DPMS immer aktiv ist. Wenn Sie keinen Hot-Standby benötigen und nur die Exportaufgabe ausführen möchten, sollten Sie alle Importaufgaben im Code auskommentieren (find_backup, wait_for_ready_status, current_ts,dpms_import).Klicken Sie auf das Pfeilsymbol, um den DAG für einen Testlauf auszulösen:
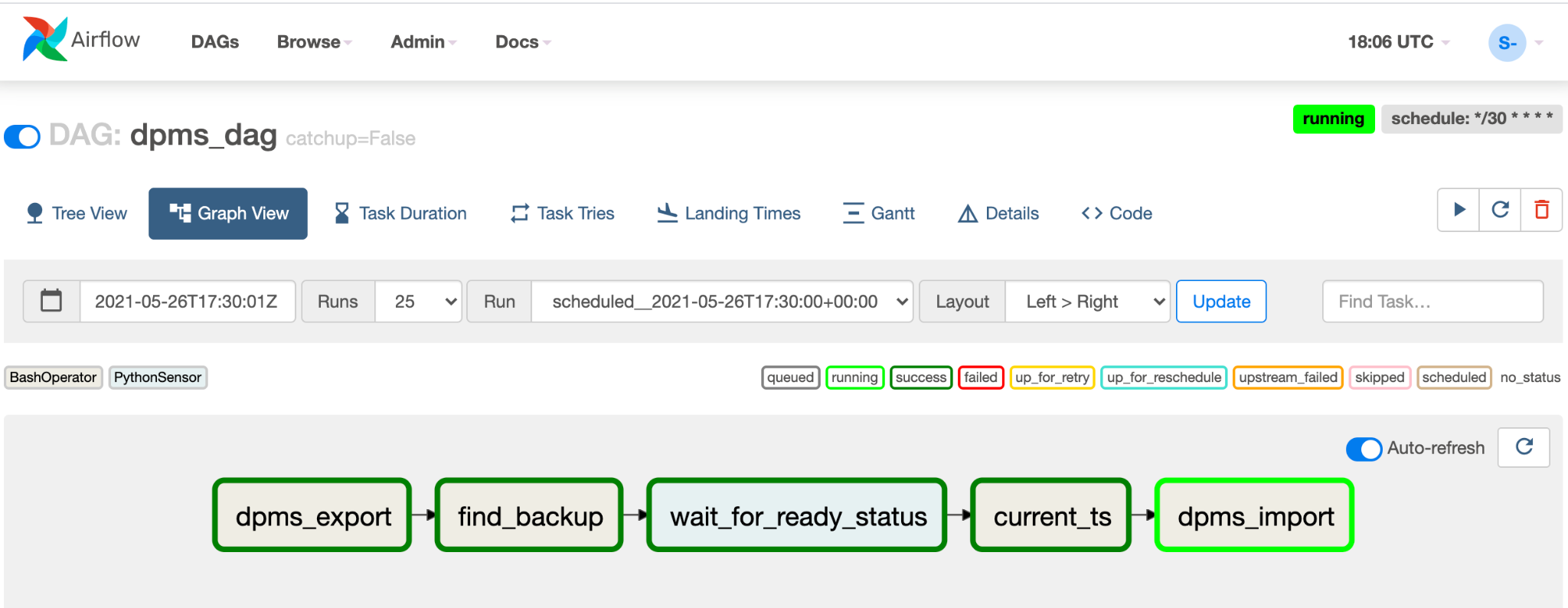
Klicken Sie auf Diagrammansicht des ausgeführten DAG, um den Status der einzelnen Aufgaben zu prüfen:
Nachdem Sie den DAG geprüft haben, lassen Sie ihn von Airflow nach einem regelmäßigen Zeitplan ausführen. Der Zeitplan ist auf ein 30-Minuten-Intervall festgelegt, kann aber angepasst werden. Dazu müssen Sie den Parameter
schedule_intervalim Code so ändern, dass Ihre Zeitplananforderungen erfüllt werden.
Failovers ausführen
Nach dem Failover zu Region B müssen Sie die folgenden Schritte ausführen, um Ihre Notfallwiederherstellungsanforderungen und die Infrastruktur vor einem möglichen Ausfall in Region B zu schützen:
- Aktualisieren Sie die DPMS-Region der primären Instanz auf Region B (
us-east1). - Aktualisieren Sie die DPMS-Region der Standby-Instanz auf Region A (
us-central1). - Aktualisieren Sie die primäre DPMS-Instanz auf
dpms2. - Aktualisieren Sie die DPMS-Standby-Instanz auf
dpms1. - Erstellen Sie eine neue Cloud Composer-Umgebung in Region B (
us-east1). - Konfigurieren Sie die Cloud Composer-Umgebung mit den aktualisierten Umgebungsvariablen.
- Importieren Sie denselben
dpms_dag-Airflow-DAG wie zuvor in Ihre neue Cloud Composer-Umgebung.
Die in der vorherigen Liste erforderlichen Schritte wiederholen viele Schritte aus den vorherigen Abschnitten, nur mit geringfügigen Anpassungen (z. B. dem Austausch der Regionsnamen). Verwenden Sie die Informationen in "Option 2: Cloud Composer", um die erforderliche Arbeit abzuschließen.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Weitere Informationen zum Monitoring Ihrer Dataproc Metastore-Instanz
- Hive-Metastore mit Data Catalog synchronisieren
- Weitere Informationen zur Entwicklung von Cloud Run-Diensten
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.