本文档介绍如何更新正在进行的流处理作业。 如有以下原因,建议您更新现有的 Dataflow 作业:
- 需要增强或改进流水线代码。
- 需要修复流水线代码中的错误。
- 需要通过更新流水线来处理数据格式的更改,或者处理数据源中的版本更改或其他更改。
- 您希望为所有 Dataflow 工作器修补与 Container-Optimized OS 相关的安全漏洞。
- 您希望对流处理 Apache Beam 流水线进行扩缩,以便使用不同数量的工作器。
您可以通过以下两种方式更新作业:
- 运行中作业更新:对于使用 Streaming Engine 的流处理作业,您可以更新
min-num-workers和max-num-workers作业选项,而无需停止作业或更改作业 ID。 - 替换作业:如需运行更新后的流水线代码或更新运行中作业更新不支持的作业选项,请启动一个新作业来替换现有作业。如需验证替换作业是否有效,请在启动新作业之前验证其作业图。
在更新作业时,Dataflow 服务会在当前运行的作业与潜在的替换作业之间执行兼容性检查。兼容性检查可确保中间状态信息和已缓冲数据等内容从原作业传输到替换作业中。
您还可以在更新作业时使用 Apache Beam SDK 的内置日志记录基础架构来记录信息。如需了解详情,请参阅使用流水线日志。
如需确定流水线代码的问题,请使用 DEBUG 日志记录级别。
- 如需了解如何更新使用经典模板的流处理作业,请参阅更新自定义模板流处理作业。
- 如需了解如何更新使用 Flex 模板的流处理作业,请按照此页面上的 gcloud CLI 说明操作,或参阅更新 Flex 模板作业。
运行中作业选项更新
对于使用 Streaming Engine 的流处理作业,您可以更新以下作业选项,且无需停止作业或更改作业 ID:
min-num-workers:Compute Engine 实例数下限。max-num-workers:Compute Engine 实例数上限。worker-utilization-hint:目标 CPU 利用率,范围为 [0.1, 0.9]
若要更新其他作业,您必须用更新后的作业替换当前作业。如需了解详情,请参阅启动替换作业。
执行运行中更新
如需执行运行中作业选项更新,请执行以下步骤。
gcloud
使用 gcloud dataflow jobs update-options 命令:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
替换以下内容:
- REGION:作业区域的 ID
- MINIMUM_WORKERS:Compute Engine 实例数下限
- MAXIMUM_WORKERS:Compute Engine 实例数上限
- TARGET_UTILIZATION:[0.1, 0.9] 范围内的值
- JOB_ID:要更新的作业的 ID
您还可以分别更新 --min-num-workers、--max-num-workers 和 worker-utilization-hint。
REST
使用 projects.locations.jobs.update 方法:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
替换以下内容:
- MASK:要更新的参数的英文逗号分隔列表,其中包括:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID:Dataflow 作业的 Google Cloud 项目 ID
- REGION:作业区域的 ID
- JOB_ID:要更新的作业的 ID
- MINIMUM_WORKERS:Compute Engine 实例数下限
- MAXIMUM_WORKERS:Compute Engine 实例数上限
- TARGET_UTILIZATION:[0.1, 0.9] 范围内的值
您还可以分别更新 min_num_workers、max_num_workers 和 worker_utilization_hint。在 updateMask 查询参数中指定要更新的参数,并在请求正文的 runtimeUpdatableParams 字段中添加更新后的值。以下示例会更新 min_num_workers:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
作业必须处于运行状态才有资格进行运行中更新。如果作业尚未开始或已取消,则会发生错误。同样,如果启动了替换作业,请等待其开始运行,然后再向新作业发送任何运行中更新。
提交一个更新请求后,建议您先等待该请求完成,然后再发送其他更新。您可以通过查看作业日志来了解请求是否已完成。
验证替换作业
如需验证替换作业是否有效,请在启动新作业之前验证其作业图。在 Dataflow 中,作业图是流水线的图形表示形式。通过验证作业图,您可以降低更新后流水线出现错误或流水线故障的风险。 此外,您可以验证更新,而无需停止原始作业,因此该作业不会出现任何停机时间。
如需验证作业图,请按照启动替换作业中的步骤进行操作。在更新命令中添加 graph_validate_only Dataflow 服务选项。
Java
- 传递
--update选项。 - 将
PipelineOptions中的--jobName选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 添加
--dataflowServiceOptions=graph_validate_only服务选项。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transformNameMapping选项传递它。 - 如果您要提交使用较高版本 Apache Beam SDK 的替换作业,请将
--updateCompatibilityVersion设置为原始作业中使用的 Apache Beam SDK 版本。
Python
- 传递
--update选项。 - 将
PipelineOptions中的--job_name选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 添加
--dataflow_service_options=graph_validate_only服务选项。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform_name_mapping选项传递它。 - 如果您要提交使用较高版本 Apache Beam SDK 的替换作业,请将
--updateCompatibilityVersion设置为原始作业中使用的 Apache Beam SDK 版本。
Go
- 传递
--update选项。 - 将
--job_name选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 添加
--dataflow_service_options=graph_validate_only服务选项。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform_name_mapping选项传递它。
gcloud
如需验证 Flex 模板作业的作业图,请使用带有 additional-experiments 选项的 gcloud dataflow flex-template run 命令:
- 传递
--update选项。 - 将 JOB_NAME 设置为与您要更新的作业相同的名称。
- 将
--region选项设置为与待更新作业相同的区域。 - 添加
--additional-experiments=graph_validate_only选项。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform-name-mappings选项传递它。
例如:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
将 JOB_NAME 替换为您要更新的作业的名称。
REST
使用 FlexTemplateRuntimeEnvironment(Flex 模板)或 RuntimeEnvironment 对象中的 additionalExperiments 字段。
{
additionalExperiments : ["graph_validate_only"]
...
}
graph_validate_only 服务选项仅验证流水线更新。在创建或启动流水线时,请勿使用此选项。如需更新流水线,请启动替换作业,并且不指定 graph_validate_only 服务选项。
作业图验证成功后,作业状态和作业日志会显示以下状态:
- 作业状态为
JOB_STATE_DONE。 - 在 Google Cloud 控制台中,作业状态为
Succeeded。 作业日志中会显示以下消息:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
作业图验证失败时,作业状态和作业日志会显示以下状态:
启动替换作业
您可能出于以下原因需要替换现有作业:
- 要运行更新后的流水线代码。
- 要对不支持运行中更新的作业选项进行更新。
如需验证替换作业是否有效,请在启动新作业之前验证其作业图。
要执行更新过程,在启动替换作业时,除了设置作业的常规选项之外,您还需设置以下流水线选项:
Java
- 传递
--update选项。 - 将
PipelineOptions中的--jobName选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transformNameMapping选项传递它。 - 如果您要提交使用较高版本 Apache Beam SDK 的替换作业,请将
--updateCompatibilityVersion设置为原始作业中使用的 Apache Beam SDK 版本。
Python
- 传递
--update选项。 - 将
PipelineOptions中的--job_name选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform_name_mapping选项传递它。 - 如果您要提交使用较高版本 Apache Beam SDK 的替换作业,请将
--updateCompatibilityVersion设置为原始作业中使用的 Apache Beam SDK 版本。
Go
- 传递
--update选项。 - 将
--job_name选项设置为与待更新作业相同的名称。 - 将
--region选项设置为与待更新作业相同的区域。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform_name_mapping选项传递它。
gcloud
如需使用 gcloud CLI 更新 Flex 模板作业,请使用 gcloud dataflow flex-template run 命令。不支持使用 gcloud CLI 更新其他作业。
- 传递
--update选项。 - 将 JOB_NAME 设置为与您要更新的作业相同的名称。
- 将
--region选项设置为与待更新作业相同的区域。 - 如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
--transform-name-mappings选项传递它。
REST
以下说明介绍了如何使用 REST API 更新非模板作业。如需使用 REST API 更新经典模板作业,请参阅更新自定义模板流处理作业。如需使用 REST API 更新 Flex 模板作业,请参阅更新 Flex 模板作业。
使用
projects.locations.jobs.get方法提取要替换的作业的job资源。添加值为JOB_VIEW_DESCRIPTION的view查询参数。添加JOB_VIEW_DESCRIPTION会限制响应中的数据量,以使后续请求不超过大小限制。如果您需要更详细的作业信息,请使用值JOB_VIEW_ALL。GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTION替换以下值:
- PROJECT_ID:Dataflow 作业的 Google Cloud 项目 ID
- REGION:您要更新的作业的区域
- JOB_ID:您要更新的作业的 ID
如需更新作业,请使用
projects.locations.jobs.create方法。在请求正文中,使用您提取的job资源。POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }替换以下内容:
- JOB_ID:与要更新的作业的 ID 相同的作业 ID。
- JOB_NAME:与要更新的作业的名称相同的作业名称。
如果流水线中有任何转换名称已更改,则必须提供转换映射,并使用
transformNameMapping字段传递它。可选:如需使用 curl(Linux、macOS 或 Cloud Shell)发送请求,将请求保存到 JSON 文件,然后运行以下命令:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs将 FILE_PATH 替换为包含请求正文的 JSON 文件的路径。
指定替换作业名称
Java
启动替换作业时,您为 --jobName 选项传递的值必须与待替换作业的名称完全匹配。
Python
启动替换作业时,您为 --job_name 选项传递的值必须与待替换作业的名称完全匹配。
Go
启动替换作业时,您为 --job_name 选项传递的值必须与待替换作业的名称完全匹配。
gcloud
启动替换作业时,JOB_NAME 必须与待替换作业的名称完全相符。
REST
将 replaceJobId 字段的值设置为与待更新作业相同的作业 ID。如需查找正确的作业名称值,请在 Dataflow 监控界面中选择您的原作业。然后,在作业信息侧边栏中找到作业 ID 字段。
如需查找正确的作业名称值,请在 Dataflow 监控界面中选择您的原作业。然后,在作业信息侧边栏中找到作业名称字段:
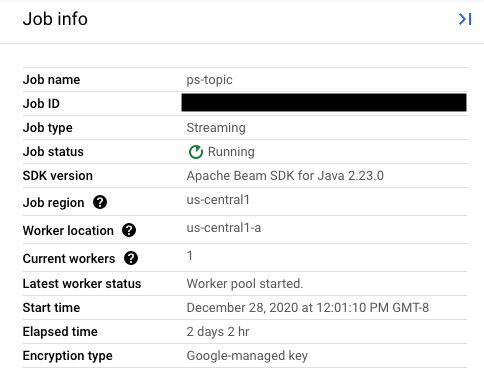
或者,使用 Dataflow 命令行界面查询现有作业的列表。在 Shell 或终端窗口输入 gcloud dataflow jobs list 命令以获取 Google Cloud 项目中的 Dataflow 作业列表,并找到要替换的作业的 NAME 字段:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
创建转换映射
如果您的替换流水线更改了原流水线中的任何转换名称,则 Dataflow 服务需要使用转换映射。转换映射会将原流水线代码中已命名的转换映射到替换流水线代码中的名称。
Java
使用 --transformNameMapping 命令行选项按以下通用格式传递映射:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
对于在原流水线和替换流水线之间有改动的转换名称,您只需在 --transformNameMapping 中提供映射条目即可。
使用 --transformNameMapping 运行时,您可能需要视情况为 shell 转义英文引号。例如,在 Bash 中:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
使用 --transform_name_mapping 命令行选项按以下通用格式传递映射:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
对于在原流水线和替换流水线之间有改动的转换名称,您只需在 --transform_name_mapping 中提供映射条目即可。
使用 --transform_name_mapping 运行时,您可能需要视情况为 shell 转义英文引号。例如,在 Bash 中:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
使用 --transform_name_mapping 命令行选项按以下通用格式传递映射:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
对于在原流水线和替换流水线之间有改动的转换名称,您只需在 --transform_name_mapping 中提供映射条目即可。
使用 --transform_name_mapping 运行时,您可能需要视情况为 shell 转义英文引号。例如,在 Bash 中:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
使用 --transform-name-mappings 选项按以下通用格式传递映射:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
对于在原流水线和替换流水线之间有改动的转换名称,您只需在 --transform-name-mappings 中提供映射条目即可。
使用 --transform-name-mappings 运行时,您可能需要视情况为 shell 转义英文引号。例如,在 Bash 中:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
使用 transformNameMapping 字段按以下通用格式传递映射:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
对于在原流水线和替换流水线之间有改动的转换名称,您只需在 transformNameMapping 中提供映射条目即可。
确定转换名称
映射中每个实例的转换名称就是您在流水线中应用转换时提供的名称。例如:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
您还可以在 Dataflow 监控界面中检查作业的执行图,以获取原作业的转换名称:
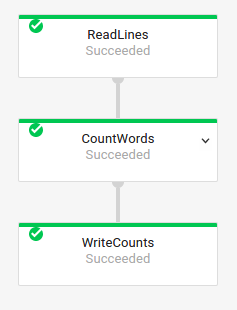
复合转换命名
流水线中的转换具有层次结构,相应地,转换名称也是分层的。如果您的流水线中包含复合转换,则嵌套转换将根据其外层的转换进行命名。例如,假设流水线包含名为 CountWidgets 的复合转换,此复合转换中包含一个名为 Parse 的内层转换,该内层转换的全名是 CountWidgets/Parse,并且您必须在转换映射中指定该全名。
如果新流水线将复合转换映射为其他名称,则所有嵌套转换也将自动重命名。您必须为转换映射中的内层转换指定更改后的名称。
重构转换层次结构
如果替换流水线使用与原流水线不同的转换层次结构,您必须明确声明映射。您可能具有不同的转换层次结构,因为您已重构复合转换,或者您的流水线依赖于来自某个库的复合转换,而该库已更改。
例如,原流水线应用了一个复合转换 CountWidgets,其中包含一个名为 Parse 的内层转换。替换流水线重构了 CountWidgets,并在另一个名为 Scan 的转换中嵌套了 Parse。要成功执行更新,您必须将原流水线中的完整转换名称 (CountWidgets/Parse) 明确映射到新流水线中的转换名称 (CountWidgets/Scan/Parse):
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
如果您在替换流水线中彻底删除了某个转换,则必须提供一个 null 映射。假设替换流水线彻底移除了 CountWidgets/Parse 转换,则应使用以下命令:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
如果您在替换流水线中彻底删除了某个转换,则必须提供一个 null 映射。假设替换流水线彻底移除了 CountWidgets/Parse 转换,则应使用以下命令:
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
如果您在替换流水线中彻底删除了某个转换,则必须提供一个 null 映射。假设替换流水线彻底移除了 CountWidgets/Parse 转换,则应使用以下命令:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
如果您在替换流水线中彻底删除了某个转换,则必须提供一个 null 映射。假设替换流水线彻底移除了 CountWidgets/Parse 转换,则应使用以下命令:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
如果您在替换流水线中彻底删除了某个转换,则必须提供一个 null 映射。假设替换流水线彻底移除了 CountWidgets/Parse 转换,则应使用以下命令:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
替换作业有哪些影响
替换现有作业后,新作业将运行更新后的流水线代码。Dataflow 服务将保留作业名称,不过会使用更新后的作业 ID 运行替换作业。此过程可能会在现有作业停止、兼容性检查运行以及新作业启动时导致停机。
替换作业会保留以下各项:
- 来自原作业的中间状态数据。不会保存内存缓存。
- 来自原作业的已缓冲数据记录或当前“运行中”的元数据。例如,流水线中的某些记录在等待数据选取功能解析的过程中可能已进行了缓冲。
- 应用于原作业的运行中作业选项更新。
中间状态数据
来自原作业的中间状态数据将被保留。状态数据不包括内存缓存。如果您要在更新流水线时保留内存缓存数据,作为一种变通方法,您可以重构流水线以将缓存转换为状态数据或旁路输入。如需详细了解如何使用旁路输入,请参阅 Apache Beam 文档中的旁路输入模式。
流处理流水线对于 ValueState 和旁路输入有大小限制。因此,如果您要保留大量缓存,可能需要使用外部存储空间,例如 Memorystore 或 Bigtable。
运行中数据
“运行中”数据仍由新流水线中的转换进行处理。不过,您添加到替换流水线代码中的其他转换可能会生效,也可能不会生效,具体取决于记录的缓冲位置。在此示例中,您的现有流水线具有以下转换:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
您可以将您的作业替换为新的流水线代码,如下所示:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
即使您添加了一个转换来过滤掉以字母“A”开头的字符串,下一个转换 (FormatStrings) 可能仍会看到从原作业传输过来的以“A”开头的已缓冲字符串或运行中字符串。
更改窗口化功能
您可以为替换流水线中的 PCollection 元素更改数据选取和触发器策略,但务必谨慎。更改数据选取或触发器策略不会影响已缓冲数据或其他运行中数据。
建议您仅尝试对流水线的数据选取策略进行少量更改,例如更改固定时间窗口或滑动时间窗口的持续时间。如果对数据选取或触发器进行重大更改(例如更改数据选取算法),则可能会对流水线输出造成不可预测的结果。
作业兼容性检查
在启动替换作业时,Dataflow 服务会在替换作业和原作业之间执行兼容性检查。如果兼容性检查通过,则原作业将停止。然后,替换作业将在 Dataflow 服务上启动,同时沿用同一作业名称。如果兼容性检查失败,原作业将继续在 Dataflow 服务上运行,而替换作业将返回错误。
Java
由于存在限制,您必须使用阻止执行在控制台或终端中查看失败的更新尝试错误。当前的解决方法包括下列步骤:
- 在流水线代码中使用 pipeline.run().waitUntilFinish()。
- 使用
--update选项运行替换流水线程序。 - 等待替换作业成功通过兼容性检查。
- 按
Ctrl+C键以退出阻止运行程序进程。
或者,您可以在 Dataflow 监控界面中监控替换作业的状态。 如果作业已成功启动,它也会通过兼容性检查。
Python
由于存在限制,您必须使用阻止执行在控制台或终端中查看失败的更新尝试错误。当前的解决方法包括下列步骤:
- 在流水线代码中使用 pipeline.run().wait_until_finish()。
- 使用
--update选项运行替换流水线程序。 - 等待替换作业成功通过兼容性检查。
- 按
Ctrl+C键以退出阻止运行程序进程。
或者,您可以在 Dataflow 监控界面中监控替换作业的状态。 如果作业已成功启动,它也会通过兼容性检查。
Go
由于存在限制,您必须使用阻止执行在控制台或终端中查看失败的更新尝试错误。具体而言,您必须使用 --execute_async 或 --async 标志来指定非阻止执行。当前的解决方法包括下列步骤:
- 在指定
--update选项且不指定--execute_async或--async标志的情况下运行替换流水线程序。 - 等待替换作业成功通过兼容性检查。
- 按
Ctrl+C键以退出阻止运行程序进程。
gcloud
由于存在限制,您必须使用阻止执行在控制台或终端中查看失败的更新尝试错误。当前的解决方法包括下列步骤:
- 对于 Java 流水线,请在流水线代码中使用 pipeline.run().waitUntilFinish()。对于 Python 流水线,请在流水线代码中使用 pipeline.run().wait_until_finish()。对于 Go 流水线,请按照 Go 标签页中的步骤操作。
- 使用
--update选项运行替换流水线程序。 - 等待替换作业成功通过兼容性检查。
- 按
Ctrl+C键以退出阻止运行程序进程。
REST
由于存在限制,您必须使用阻止执行在控制台或终端中查看失败的更新尝试错误。当前的解决方法包括下列步骤:
- 对于 Java 流水线,请在流水线代码中使用 pipeline.run().waitUntilFinish()。对于 Python 流水线,请在流水线代码中使用 pipeline.run().wait_until_finish()。 对于 Go 流水线,请按照 Go 标签页中的步骤操作。
- 使用
replaceJobId字段运行替换流水线程序。 - 等待替换作业成功通过兼容性检查。
- 按
Ctrl+C键以退出阻止运行程序进程。
兼容性检查使用提供的转换映射来确保 Dataflow 可以将原作业步骤中的中间状态数据传输到替换作业。兼容性检查还可确保流水线中的 PCollection 使用相同的编码器。更改 Coder 可能会导致兼容性检查失败,这是因为任何运行中数据或已缓冲记录可能无法在替换流水线中正确序列化。
防止兼容性中断问题
原流水线与替换流水线之间的某些差异可能导致兼容性检查失败。这些差异包括:
- 更改流水线图但未提供映射。在更新作业时,Dataflow 会尝试将原作业中的转换与替换作业中的转换进行匹配。此匹配过程可帮助 Dataflow 传输每个步骤的中间状态数据。如果您要重命名或移除任何步骤,则必须提供转换映射,以便 Dataflow 能够相应地匹配状态数据。
- 更改某个步骤的侧边输入。如果向替换流水线中的转换添加侧边输入,或从转换中移除侧边输入,则将导致兼容性检查失败。
- 更改某个步骤的编码器。在更新作业时,Dataflow 会保留当前缓冲的任何数据记录,并在替换作业中处理这些记录。例如,在解析数据选取功能时,可能会产生缓冲数据。如果替换作业使用不同或不兼容的数据编码方式,则 Dataflow 将无法对这些记录进行序列化或反序列化。
从流水线中移除“有状态”操作。如果从流水线中移除有状态操作,则替换作业可能无法通过兼容性检查。Dataflow 可将多个步骤组合在一起,以提升效率。如果您从某个组合步骤中移除了与状态相关的操作,则检查将失败。有状态操作包括:
- 产生或使用辅助输入的转换。
- I/O 读取。
- 使用有键状态 (keyed state) 的转换。
- 具有窗口合并功能的转换。
更改有状态的
DoFn变量。对于正在运行的流式作业,如果流水线包含有状态DoFn,则更改有状态DoFn变量可能会导致流水线失败。尝试在不同的地理可用区中运行替换作业。 在运行原作业的可用区中运行替换作业。
更新架构
Apache Beam 允许 PCollection 具有包含命名字段的架构,在这种情况下,不需要显式编码器。如果给定架构的字段名称和类型(包括嵌套字段)未发生更改,则该架构不会导致更新检查失败。但是,如果新流水线的其他部分不兼容,更新可能仍会受阻。
改进架构
通常,由于业务需求变化,必须改进 PCollection 的架构。Dataflow 服务允许您在更新流水线时对架构进行以下更改:
- 向架构添加一个或多个新字段,包括嵌套字段。
- 将必需(不可为 null)字段类型设为可选字段类型(可以为 null)。
在更新过程中,不允许移除字段、更改字段名称或更改字段类型。
将其他数据传递到现有 ParDo 操作
您可以使用以下方法之一将附加(带外)数据传递到现有 ParDo 操作中,具体取决于您的应用场景:
- 将信息序列化为
DoFn子类中的字段。 - 匿名
DoFn中的方法所引用的任何变量都将自动序列化。 - 在
DoFn.startBundle()内计算数据。 - 使用
ParDo.withSideInputs传入数据。
如需了解详情,请参阅以下页面:
- Apache Beam 编程指南:ParDo,特别是专门针对创建 DoFn 和辅助输入的部分。
- Java 版 Apache Beam SDK 参考:ParDo