Cette page fournit des conseils de dépannage et des stratégies de débogage qui peuvent vous être utiles si vous avez des difficultés à créer ou exécuter votre pipeline Dataflow. Ces informations peuvent vous aider à détecter une défaillance dans un pipeline, à déterminer la raison de l'échec de son exécution et à identifier les mesures correctives possibles.
Le schéma suivant illustre le workflow de dépannage Dataflow décrit sur cette page.

Dans la mesure où Dataflow vous fournit des informations en temps réel sur votre tâche, les premières mesures de routine consisteront à vérifier les messages d'erreur, à examiner les journaux et à détecter des problèmes éventuels tels que le blocage de la progression de votre tâche.
Pour obtenir des conseils sur les erreurs courantes que vous pouvez rencontrer lors de l'exécution de votre tâche Dataflow, consultez la page Résoudre les erreurs Dataflow. Pour surveiller et résoudre les problèmes de performances du pipeline, consultez la page Surveiller les performances du pipeline.
Bonnes pratiques pour les pipelines
Voici les bonnes pratiques pour les pipelines Java, Python et Go.
Java
Pour les tâches par lots, nous vous recommandons de définir une valeur TTL (Time To Live) pour l'emplacement temporaire.
Avant de configurer la valeur TTL et comme bonne pratique générale, assurez-vous de définir l'emplacement de préproduction et l'emplacement temporaire sur des emplacements différents.
Ne supprimez pas les objets de l'emplacement de préproduction, car ils sont réutilisés.
Si une tâche se termine ou est arrêtée et que les objets temporaires ne sont pas supprimés, supprimez-les manuellement du bucket Cloud Storage utilisé comme emplacement temporaire.
Python
Le préfixe des emplacements temporaires et de préproduction est <job_name>.<time>.
Assurez-vous de définir l'emplacement de préproduction et l'emplacement temporaire sur des emplacements différents.
Si nécessaire, supprimez les objets de l'emplacement de préproduction une fois la tâche terminée ou arrêtée. En outre, les objets en préproduction ne sont pas réutilisés dans les pipelines Python.
Si une tâche se termine et que les objets temporaires ne sont pas supprimés, supprimez-les manuellement du bucket Cloud Storage utilisé comme emplacement temporaire.
Pour les tâches par lot, nous vous recommandons de définir une valeur TTL (Time To Live) pour les emplacements temporaires et de préproduction.
Go
Le préfixe des emplacements temporaires et de préproduction est
<job_name>.<time>.Assurez-vous de définir l'emplacement de préproduction et l'emplacement temporaire sur des emplacements différents.
Si nécessaire, supprimez les objets de l'emplacement de préproduction une fois la tâche terminée ou arrêtée. En outre, les objets en préproduction ne sont pas réutilisés dans les pipelines Go.
Si une tâche se termine et que les objets temporaires ne sont pas supprimés, supprimez-les manuellement du bucket Cloud Storage utilisé comme emplacement temporaire.
Pour les tâches par lot, nous vous recommandons de définir une valeur TTL (Time To Live) pour les emplacements temporaires et de préproduction.
Vérifier l'état de votre pipeline
Vous pouvez détecter les éventuelles erreurs dans vos exécutions de pipeline à l'aide de l'interface de surveillance Dataflow.
- Accédez à Google Cloud Console.
- Sélectionnez votre projet Google Cloud dans la liste des projets.
- Dans le menu de navigation, sous Big Data, cliquez sur Dataflow. La liste des tâches en cours apparaît dans le volet de droite.
- Sélectionnez la tâche de pipeline à afficher. La colonne Status (État) vous permet de voir l'état de chaque tâche d'un seul coup d'œil : "Running" (En cours d'exécution), "Succeeded" (Réussie) ou "Failed" (Échec).
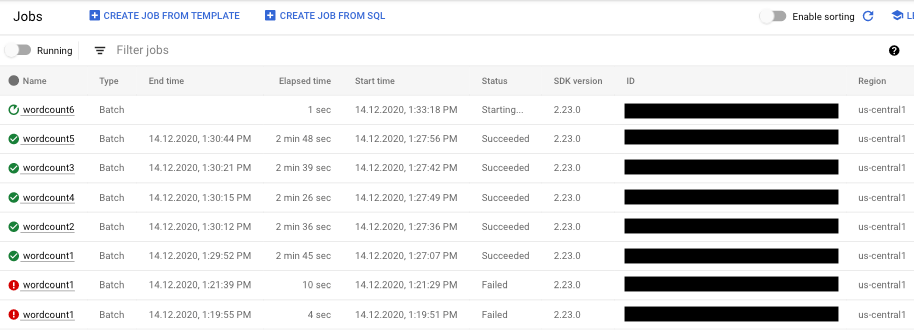
Trouver des informations sur les échecs de pipeline
Si l'une de vos tâches de pipeline échoue, vous pouvez sélectionner la tâche pour afficher des informations plus détaillées sur les erreurs et les résultats d'exécution. Lorsque vous sélectionnez une tâche, vous pouvez afficher les graphiques clés de votre pipeline, le graphique d'exécution, le panneau Informations sur la tâche et le panneau Journaux avec les onglets Journaux de la tâche, Journaux des nœuds de calcul, Diagnostic et Recommandations.
Vérifier les messages d'erreur liés à la tâche
Pour afficher les Journaux des tâches générés par le code de votre pipeline et par le service Dataflow, dans le panneau Journaux, cliquez sur segmentAfficher.
Vous pouvez filtrer les messages qui s'affichent dans Job Logs en cliquant sur Infoarrow_drop_down et sur filter_listFilter (Filtre). Pour n'afficher que les messages d'erreur, cliquez sur Infoarrow_drop_down, puis sélectionnez Error (Erreur).
Pour développer un message d'erreur, cliquez sur la section extensible arrow_right.

Vous pouvez également cliquer sur l'onglet Diagnostic. Cet onglet indique où les erreurs se sont produites tout au long de la chronologie choisie, le nombre total d'erreurs consignées et les recommandations possibles pour votre pipeline.
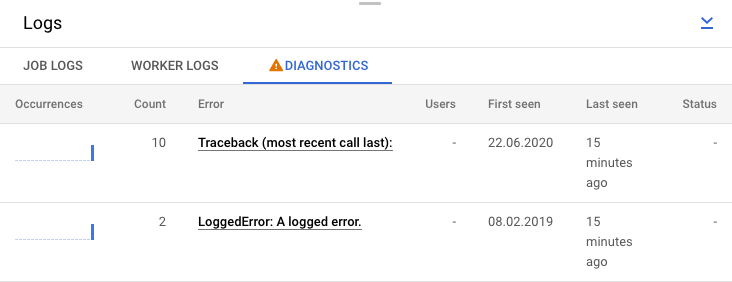
Afficher les journaux d'étape correspondant à votre tâche
Lorsque vous sélectionnez une étape dans le graphique de votre pipeline, le panneau des journaux passe de l'affichage des journaux de la tâche générés par le service Dataflow à l'affichage des journaux des instances Compute Engine exécutant l'étape sélectionnée du pipeline.
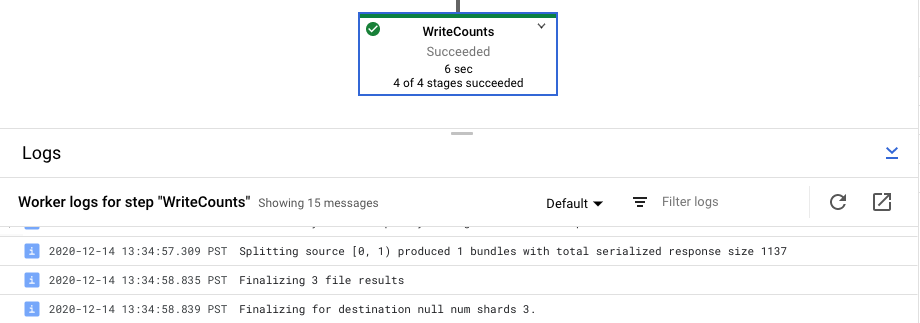
Cloud Logging regroupe tous les journaux collectés des instances Compute Engine de votre projet dans un seul emplacement. Pour plus d'informations sur l'utilisation des différentes fonctionnalités de journalisation de Dataflow, consultez la page Enregistrer les messages de pipeline.
Traiter un rejet de pipeline automatique
Dans certains cas, le service Dataflow détermine que votre pipeline est susceptible de provoquer des problèmes connus liés au SDK. Pour empêcher l'envoi de pipelines susceptibles de rencontrer des problèmes, Dataflow rejette automatiquement votre pipeline et affiche le message suivant :
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Si, après avoir pris connaissance des mises en garde formulées dans les détails du bug fournis en lien, vous souhaitez tout de même tenter d'exécuter votre pipeline, vous avez la possibilité d'annuler ce rejet automatique. Ajoutez l'indicateur --experiments=<override-flag> et soumettez à nouveau votre pipeline.
Déterminer la cause de l'échec d'un pipeline
L'échec de l'exécution d'un pipeline Apache Beam est généralement dû à l'une des causes suivantes :
- Erreurs liées à la construction du graphique ou du pipeline. De telles erreurs se produisent lorsque Dataflow rencontre un problème à la construction du graphique des étapes qui composent votre pipeline, comme décrit par votre pipeline Apache Beam.
- Erreurs liées à la validation de la tâche. Le service Dataflow valide toute tâche de pipeline que vous lancez. Des erreurs liées à ce processus de validation peuvent empêcher la création ou l'exécution de votre tâche. Les erreurs de validation peuvent résulter de problèmes liés au bucket Cloud Storage de votre projet Google Cloud ou aux autorisations accordées à ce projet.
- Exceptions dans le code destiné aux nœuds de calcul. Ces erreurs résultent de la présence d'anomalies ou de bugs dans le code qui est fourni par l'utilisateur et que Dataflow distribue aux nœuds de calcul en parallèle (par exemple, dans les instances
DoFnd'une transformationParDo). - Erreurs provoquées par des défaillances transitoires dans d'autres services Google Cloud. Votre pipeline peut échouer en raison d'une panne ou d'un autre problème temporaire survenant dans l'un des services Google Cloud dont dépend Dataflow, tels que Compute Engine ou Cloud Storage.
Détecter les erreurs de construction d'un graphique ou d'un pipeline
Une erreur de construction de graphique peut survenir lorsque Dataflow crée le graphique d'exécution de votre pipeline à partir du code de votre programme Dataflow. Durant la construction du graphique, Dataflow vérifie la validité des opérations spécifiées.
Si Dataflow détecte une erreur dans la construction du graphique, gardez à l'esprit qu'aucune tâche ne sera créée sur le service Dataflow. Par conséquent, vous ne verrez aucun retour dans l'interface de surveillance de Dataflow. Au lieu de cela, un message d'erreur semblable au suivant apparaît dans la console ou la fenêtre de terminal sur laquelle vous avez exécuté votre pipeline Apache Beam :
Java
Par exemple, si votre pipeline tente d'effectuer une opération d'agrégation comme GroupByKey sur une PCollection illimitée soumise à un fenêtrage global et dépourvue de déclencheur, un message d'erreur semblable au suivant s'affiche :
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Par exemple, si votre pipeline utilise des indicateurs de type et qu'un argument de l'une des transformations n'est pas du type attendu, un message d'erreur semblable au suivant s'affiche :
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
Par exemple, si votre pipeline utilise un argument "DoFn" qui n'accepte aucune entrée, un message d'erreur semblable à celui-ci se produit :
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Si vous rencontrez une telle erreur, vérifiez le code de votre pipeline pour vous assurer que les opérations qu'il contient sont valides.
Détecter des erreurs dans la validation d'une tâche Dataflow
Une fois que le service Dataflow a reçu le graphique de votre pipeline, il tente de valider votre tâche. Cette validation comprend les éléments suivants :
- Vérification de l'accès par le service aux buckets Cloud Storage associés à votre tâche pour les fichiers temporaires et les sorties intermédiaires
- Vérification des autorisations requises dans votre projet Google Cloud
- Vérification de l'accès par le service aux sources d'entrée et de sortie (telles que les fichiers)
Si votre tâche échoue au processus de validation, un message d'erreur apparaît dans l'interface de surveillance de Dataflow, ainsi que dans la console ou la fenêtre de terminal, si vous avez opté pour une exécution en mode blocage. Le message d'erreur ressemble à ceci :
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
La validation de tâche décrite dans cette section n'est actuellement pas disponible pour Go. Les erreurs causées par ces problèmes apparaissent en tant qu'exceptions de nœuds de calcul.
Détecter une exception dans le code distribué aux nœuds de calcul
Durant l'exécution de votre tâche, vous pouvez rencontrer des erreurs ou des exceptions liées au code distribué aux nœuds de calcul. Ces erreurs signifient généralement que les DoFn du code de votre pipeline ont généré des exceptions non gérées, ce qui entraîne l'échec de sous-tâches dans votre tâche Dataflow.
Les exceptions détectées dans le code utilisateur (par exemple, dans vos instances DoFn) sont signalées dans l'interface de surveillance de Dataflow.
Si vous avez spécifié l'exécution en mode blocage pour votre pipeline, des messages d'erreur tels que ceux-ci s'affichent dans la console ou la fenêtre de terminal :
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Envisagez d'ajouter des gestionnaires d'exceptions pour éviter toute erreur dans votre code. Par exemple, si vous souhaitez supprimer les éléments qui font échouer une validation d'entrée personnalisée effectuée dans une transformation ParDo, traitez l'exception au sein de votre fonction DoFn et supprimez l'élément.
Vous pouvez également suivre les éléments défaillants de différentes manières :
- Vous pouvez journaliser les éléments défaillants et vérifier la sortie à l'aide de Cloud Logging.
- Vous pouvez consulter les avertissements ou les erreurs dans les journaux des nœuds de calcul et de démarrage des nœuds de calcul de Dataflow en suivant les instructions figurant dans la section Afficher les journaux.
- Vous pouvez utiliser votre transformation
ParDopour écrire les éléments défaillants dans une sortie supplémentaire pour inspection ultérieure.
Pour suivre les propriétés d'un pipeline en cours d'exécution, vous pouvez utiliser la classe Metrics comme illustré dans l'exemple suivant :
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Résoudre un problème de pipeline ralenti ou d'absence de sortie
Consultez la section Résoudre les problèmes liés aux jobs lents et bloqués.
Erreurs courantes et mesures correctives
Lorsque vous connaissez l'erreur à l'origine de l'échec du pipeline, consultez la page Résoudre les erreurs Dataflow pour obtenir des conseils sur la résolution des erreurs.