Pour arrêter une tâche Dataflow, utilisez Google Cloud Console, Cloud Shell, un terminal local installé avec Google Cloud CLI ou l'API REST Dataflow.
Vous pouvez arrêter une tâche Dataflow de l'une des trois manières suivantes :
Annuler une tâche. Cette méthode s'applique à la fois aux pipelines de traitement par flux et par lot. L'annulation d'une tâche arrête le service Dataflow dans son traitement de toutes les données, y compris les données mises en mémoire tampon. Pour en savoir plus, consultez la section Annuler une tâche.
Drainer une tâche. Cette méthode ne s'applique qu'aux pipelines de traitement par flux. Le drainage d'une tâche permet au service Dataflow de terminer le traitement des données mises en mémoire tampon tout en interrompant simultanément l'ingestion de nouvelles données. Pour en savoir plus, consultez la section Drainer une tâche.
Forcer l'annulation d'une tâche. Cette méthode s'applique à la fois aux pipelines de traitement par flux et par lot. L'annulation forcée d'une tâche interrompt immédiatement tout traitement de données par le service Dataflow, y compris des données mises en mémoire tampon. Avant de forcer l'annulation, vous devez d'abord tenter d'effectuer une annulation standard. L'annulation forcée n'est destinée qu'aux tâches qui sont bloquées dans le processus d'annulation standard. Pour en savoir plus, consultez la section Forcer l'annulation d'une tâche.
Lorsque vous annulez un job, vous ne pouvez pas la redémarrer. Si vous n'utilisez pas de modèles Flex, vous pouvez cloner le pipeline annulé et démarrer un nouveau job à partir du pipeline cloné.
Avant d'arrêter un pipeline de traitement par flux, envisagez de créer un instantané du job. Les instantanés Dataflow enregistrent l'état d'un pipeline de traitement par flux afin que vous puissiez démarrer une nouvelle version de votre tâche Dataflow sans perdre l'état. Pour en savoir plus, consultez la section Utiliser des instantanés Dataflow.
Si vous avez un pipeline complexe, envisagez de créer un modèle et d'exécuter le job à partir de ce modèle.
Vous ne pouvez pas supprimer de jobs Dataflow, mais vous pouvez archiver les jobs terminés. Tous les jobs terminés, y compris ceux figurant dans la liste des jobs archivés, sont supprimés après une période de conservation de 30 jours.
Annuler une tâche Dataflow
Lorsque vous annulez une tâche, le service Dataflow l'arrête immédiatement.
Les actions suivantes se produisent lorsque vous annulez une tâche :
Le service Dataflow interrompt toute ingestion et traitement de données.
Le service Dataflow commence à nettoyer les ressources Google Cloud associées à votre tâche.
Cela peut inclure la fermeture des instances de nœuds de calcul Compute Engine et la fermeture des connexions actives aux sources ou récepteurs d'E/S.
Informations importantes sur l'annulation d'une tâche
L'annulation d'une tâche interrompt immédiatement le traitement du pipeline.
Vous risquez de perdre des données en cours de transfert lorsque vous annulez une tâche. Les données en cours de transfert désignent les données déjà lues mais qui sont toujours en cours de traitement par le pipeline.
Les données écrites à partir du pipeline vers un récepteur de sortie avant l'annulation de la tâche peuvent toujours être accessibles sur le récepteur de sortie.
Si la perte de données n'est pas un problème, l'annulation de votre tâche garantit que les ressources Google Cloud associées à cette tâche sont arrêtées le plus rapidement possible.
Drainer une tâche Dataflow
Lorsque vous drainez une tâche, le service Dataflow la termine dans son état actuel. Si vous souhaitez éviter les pertes de données lorsque vous désactivez les pipelines de streaming, la meilleure option consiste à drainer votre tâche.
Les actions suivantes se produisent lors du drainage d'une tâche :
Votre tâche arrête d'ingérer de nouvelles données à partir de sources d'entrée peu de temps après avoir reçu la requête Drain (généralement sous quelques minutes).
Le service Dataflow conserve toutes les ressources existantes, telles que les instances de nœuds de calcul, pour terminer le traitement et l'écriture des données mises en mémoire tampon dans le pipeline.
Une fois toutes les opérations de traitement et d'écriture en attente terminées, le service Dataflow arrête les ressources Google Cloud associées à la tâche.
Pour drainer votre tâche, Dataflow arrête la lecture des nouvelles entrées, marque la source avec un code temporel d'événement de valeur "infini", puis propage les codes temporels de valeur "infini" dans tout le pipeline. Par conséquent, les pipelines en cours de drainage peuvent avoir un filigrane d'infini.
Informations importantes sur le drainage d'une tâche
Le drainage d'une tâche n'est pas compatible avec les pipelines de traitement par lot.
Votre pipeline continue à subir les coûts de maintenance des ressources Google Cloud associées jusqu'à la fin des opérations de traitement et d'écriture.
Vous pouvez mettre à jour un pipeline en cours de drainage. Si votre pipeline est bloqué, la mise à jour du pipeline avec du code qui corrige l'erreur à l'origine du problème permet un drainage réussi sans perte de données.
Vous pouvez annuler une tâche en cours de drainage.
Le drainage d'une tâche peut prendre beaucoup de temps, par exemple lorsque le pipeline contient une grande quantité de données en mémoire tampon.
Si votre pipeline de traitement par flux inclut un Splittable DoFn, vous devez tronquer le résultat avant d'exécuter l'option de drainage. Pour en savoir plus sur la troncation des Splittable DoFns, consultez la documentation Apache Beam.
Dans certains cas, une tâche Dataflow peut ne pas être en mesure de terminer l'opération de drainage. Vous pouvez consulter les journaux de la tâche pour identifier la cause première et prendre les mesures appropriées.
Conservation des données
Le streaming Dataflow tolère le redémarrage des nœuds de calcul et ne fait pas échouer les tâches de traitement par flux en cas d'erreur. Au lieu de cela, le service Dataflow effectue de nouvelles tentatives jusqu'à ce que vous effectuiez une action, telle que l'annulation ou le redémarrage de la tâche. Lorsque vous drainez la tâche, Dataflow continue de relancer les tentatives, ce qui peut entraîner le blocage des pipelines. Dans ce cas, pour activer un drainage réussi sans perte de données, mettez à jour le pipeline avec du code qui corrige l'erreur à l'origine du problème.
Dataflow ne confirme pas les messages tant qu'ils ne sont pas validés par le service Dataflow de manière durable. Par exemple, Kafka vous permet de voir ce processus comme un transfert sécurisé de la propriété du message de Kafka à Dataflow, ce qui réduit les risques de perte de données.
Tâches bloquées
- Le drainage ne corrige pas les pipelines bloqués. Si le déplacement des données est bloqué, le pipeline reste bloqué après la commande de drainage. Pour résoudre un problème de pipeline bloqué, exécutez la commande update pour mettre à jour le pipeline avec du code qui résout l'erreur à l'origine du problème. Vous pouvez également annuler les tâches bloquées, mais cela peut entraîner une perte de données.
Minuteurs
Si le code de votre pipeline de traitement par flux inclut un minuteur en boucle, la tâche peut être lente ou impossible à drainer. Comme le drainage ne se termine que lorsque tous les minuteurs sont terminés, les pipelines avec des minuteurs en boucle infinie ne terminent jamais le drainage.
Dataflow attend que tous les minuteurs de temps de traitement soient terminés au lieu de les déclencher immédiatement, ce qui peut ralentir les drainages.
Effets liés au drainage d'une tâche
Lorsque vous drainez un pipeline de traitement par flux, Dataflow ferme immédiatement toutes les fenêtres en cours et actionne tous les déclencheurs.
Le système n'attend pas que les fenêtres temporelles en cours se terminent dans une opération de drainage.
Par exemple, si, au moment où vous effectuez le drainage de votre pipeline, 10 minutes d'une fenêtre de deux heures se sont déjà écoulées, Dataflow n'attend pas que le reste de la fenêtre se termine. Il ferme la fenêtre immédiatement, avec des résultats partiels. Dataflow provoque la fermeture des fenêtres ouvertes en faisant avancer le filigrane de données à l'infini. Cette fonctionnalité peut également être utilisée avec des sources de données personnalisées.
Lors du drainage d'un pipeline utilisant une classe de source de données personnalisée, Dataflow cesse d'émettre des requêtes pour obtenir de nouvelles données, fait avancer le filigrane de données à l'infini et appelle la méthode finalize() de votre source sur le dernier point de contrôle.
Le drainage peut entraîner des fenêtres partiellement remplies. Dans ce cas, si vous redémarrez le pipeline drainé, la même fenêtre peut se déclencher une seconde fois, ce qui peut poser des problèmes pour vos données. Par exemple, dans le scénario suivant, les fichiers peuvent avoir des noms en conflit et les données peuvent être écrasées :
Si vous drainez un pipeline avec un fenêtrage horaire à 12h34, la fenêtre de 12h00 à 13h00 se ferme avec seulement les données qui ont été déclenchées dans les 34 premières minutes de la fenêtre. Le pipeline ne lit pas de nouvelles données après 12h34.
Si vous redémarrez immédiatement le pipeline, la fenêtre de 12h00 à 13h00 est à nouveau déclenchée, avec seulement les données qui ont été lues de 12h35 à 13h00. Aucun doublon n'est envoyé, mais si un nom de fichier est répété, les données sont écrasées.
Dans Google Cloud Console, vous pouvez afficher les détails des transformations du pipeline. Le schéma suivant montre les effets d'une opération de drainage en cours de traitement. Notez que le filigrane est avancé à la valeur maximale.
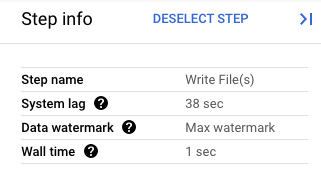
Figure 1 : Vue par étapes d'une opération de drainage.
Forcer l'annulation d'une tâche Dataflow
N'utilisez l'annulation forcée que lorsque vous ne pouvez pas annuler votre job à l'aide d'autres méthodes. L'annulation forcée met fin à votre job sans nettoyer toutes les ressources. Si vous utilisez l'annulation forcée de manière répétée, les fuites de ressources peuvent s'accumuler et utiliser votre quota.
Lorsque vous forcez l'annulation d'une tâche, le service Dataflow l'arrête immédiatement, ce qui entraîne la fuite des VM que la tâche Dataflow a créées. Vous devez tenter d'effectuer une annulation standard au moins 30 minutes avant l'annulation forcée.
Les actions suivantes se produisent lorsque vous annulez de force une tâche :
- Le service Dataflow interrompt toute ingestion et traitement de données.
Informations importantes sur l'annulation forcée d'une tâche
L'annulation forcée d'une tâche interrompt immédiatement le traitement du pipeline.
L'annulation forcée d'une tâche ne concerne que les tâches qui se sont bloquées au cours du processus d'annulation standard.
Les instances de nœuds de calcul créées par la tâche Dataflow ne sont pas nécessairement libérées, ce qui peut entraîner des fuites d'instances de nœuds de calcul. Les instances de nœuds de calcul divulguées ne contribuent pas aux coûts des jobs, mais elles peuvent utiliser votre quota. Une fois l'annulation du job terminée, vous pouvez supprimer ces ressources.
Pour les jobs Dataflow Prime, vous ne pouvez pas afficher ni supprimer les VM divulguées. Dans la plupart des cas, ces VM ne créent pas de problème. Toutefois, si les VM divulguées entraînent des problèmes, telles que la consommation de votre quota de VM, contactez l'assistance.
Arrêter une tâche Dataflow
Avant d'arrêter une tâche, vous devez comprendre les effets de l'annulation, du drainage ou de l'annulation forcée d'une tâche.
Console
Accédez à la page Tâches Dataflow.
Cliquez sur la tâche que vous souhaitez arrêter.
Pour arrêter une tâche, son état doit être en cours d'exécution.
Sur la page des détails de la tâche, cliquez sur Arrêter.
Effectuez l'une des opérations suivantes :
Pour un pipeline par lot, cliquez sur Annuler ou Forcer l'annulation.
Pour un pipeline de streaming, cliquez sur Annuler, Drainer ou Forcer l'annulation.
Pour confirmer votre choix, cliquez sur Arrêter la tâche.
gcloud
Pour drainer ou annuler une tâche Dataflow, vous pouvez utiliser la commande gcloud dataflow jobs dans Cloud Shell ou dans un terminal local installé avec gcloud CLI.
Connectez-vous à votre shell.
Répertoriez les ID des tâches Dataflow en cours d'exécution, puis notez l'ID de la tâche que vous souhaitez arrêter :
gcloud dataflow jobs listSi l'option
--regionn'est pas définie, les tâches Dataflow de toutes les régions disponibles s'affichent.Effectuez l'une des opérations suivantes :
Pour drainer une tâche de streaming, procédez comme suit :
gcloud dataflow jobs drain JOB_IDRemplacez
JOB_IDpar l'ID de la tâche que vous avez copiée précédemment.Pour annuler une tâche par lots ou par flux, procédez comme suit :
gcloud dataflow jobs cancel JOB_IDRemplacez
JOB_IDpar l'ID de la tâche que vous avez copiée précédemment.Pour forcer l'annulation d'un job par lots ou par flux, procédez comme suit :
gcloud dataflow jobs cancel JOB_ID --forceRemplacez
JOB_IDpar l'ID de la tâche que vous avez copiée précédemment.
API
Pour annuler ou drainer une tâche à l'aide de l'API REST Dataflow, vous pouvez choisir entre projects.locations.jobs.update et projects.jobs.update
Dans le corps de la requête, transmettez l'état de tâche requis dans le champ requestedState de l'instance de tâche de l'API choisie.
Important : L'utilisation de projects.locations.jobs.update est recommandée, car projects.jobs.update permet uniquement de mettre à jour l'état des tâches exécutées dans la région us-central1.
Pour annuler la tâche, définissez son état sur
JOB_STATE_CANCELLED.Pour drainer la tâche, définissez son état sur
JOB_STATE_DRAINED.Pour forcer l'annulation du job, définissez son état sur
JOB_STATE_CANCELLEDavec l'étiquette"force_cancel_job": "true". Le corps de la requête est le suivant :{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Détecter la fin d'une tâche Dataflow
Pour détecter la fin de l'annulation ou du drainage de la tâche, utilisez l'une des méthodes suivantes :
- Utilisez un service d'orchestration de workflows tel que Cloud Composer pour surveiller votre tâche Dataflow.
- Exécutez le pipeline de manière synchrone afin que les tâches soient bloquées jusqu'à ce que le pipeline soit terminé. Pour en savoir plus, consultez la section Contrôler les modes d'exécution de la page "Définir les options de pipeline".
Interrogez l'état de la tâche à l'aide de l'outil de ligne de commande de Google Cloud CLI. Pour obtenir la liste de toutes les jobs Dataflow de votre projet, exécutez la commande suivante dans votre shell ou votre terminal :
gcloud dataflow jobs listLa sortie affiche l'ID, le nom et l'état (
STATE) de chaque tâche, ainsi que d'autres informations les concernant. Pour en savoir plus, consultez la page Utiliser l'interface de ligne de commande Dataflow.
Archiver des jobs Dataflow
Lorsque vous archivez un job Dataflow, il est supprimé de la liste des jobs de la page Jobs Dataflow dans la console. Le job est déplacé vers une liste de jobs archivés. Vous ne pouvez archiver que les jobs terminés, ce qui inclut les jobs dans les états suivants :
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Pour plus d'informations, consultez la section Détecter l'achèvement d'un job Dataflow du présent document. Pour obtenir des informations de dépannage, consultez la section Erreurs d'archivage des jobs dans "Résoudre les erreurs Dataflow".
Tous les jobs archivés sont supprimés après une période de conservation de 30 jours.
Archiver un job
Suivez ces étapes pour supprimer un job terminé de la liste principale des jobs sur la page Jobs de Dataflow.
Console
Dans la console Google Cloud, accédez à la page Tâches de Dataflow.
Une liste des tâches Dataflow ainsi que leur état respectif apparaissent.
Sélectionnez une tâche.
Sur la page Informations sur le job, cliquez sur Archiver. Si le job n'est pas terminé, l'option Archiver n'est pas disponible.
API
Pour archiver des jobs à l'aide de l'API, utilisez le champ JobMetadata. Dans le champ JobMetadata, pour userDisplayProperties, utilisez la paire clé-valeur "archived":"true".
Votre requête API doit également inclure le paramètre de requête updateMask.
curl --request PUT \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
--data
'{"job_metadata":{"userDisplayProperties":{"archived":"true"}}}' \
--compressed
Remplacez les éléments suivants :
PROJECT_ID: ID de votre projetREGION: région DataflowJOB_ID: ID de votre job Dataflow
Afficher et restaurer des jobs archivés
Procédez comme suit pour afficher les jobs archivés ou pour restaurer les jobs archivés dans la liste des jobs principaux de la page Jobs Dataflow.
Console
Dans la console Google Cloud, accédez à la page Tâches de Dataflow.
Cliquez sur le bouton Archivé. La liste des jobs Dataflow archivés s'affiche.
Sélectionnez une tâche.
Pour restaurer le job dans la liste principale des jobs de la page Jobs Dataflow, sur la page Informations sur le job, cliquez sur Restaurer.
API
Pour restaurer des jobs à l'aide de l'API, utilisez le champ JobMetadata. Dans le champ JobMetadata, pour userDisplayProperties, utilisez la paire clé-valeur "archived":"false".
Votre requête API doit également inclure le paramètre de requête updateMask.
curl --request PUT \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
--data
'{"job_metadata":{"userDisplayProperties":{"archived":"false"}}}' \
--compressed
Remplacez les éléments suivants :
PROJECT_ID: ID de votre projetREGION: région DataflowJOB_ID: ID de votre job Dataflow
Étapes suivantes
- Explorez la ligne de commande Dataflow.
- Découvrez l'API REST Dataflow.
- Découvrez l'interface de surveillance de Dataflow dans la console Google Cloud.
- Découvrez comment mettre à jour un pipeline.