Depois de criar e preparar o modelo do Dataflow, execute o modelo com a Google Cloud consola, a API REST ou a Google Cloud CLI. Pode implementar tarefas de modelos do Dataflow a partir de muitos ambientes, incluindo o ambiente padrão do App Engine, as funções do Cloud Run e outros ambientes restritos.
Use a Google Cloud consola
Pode usar a Google Cloud consola para executar modelos do Dataflow fornecidos pela Google e personalizados.
Modelos fornecidos pela Google
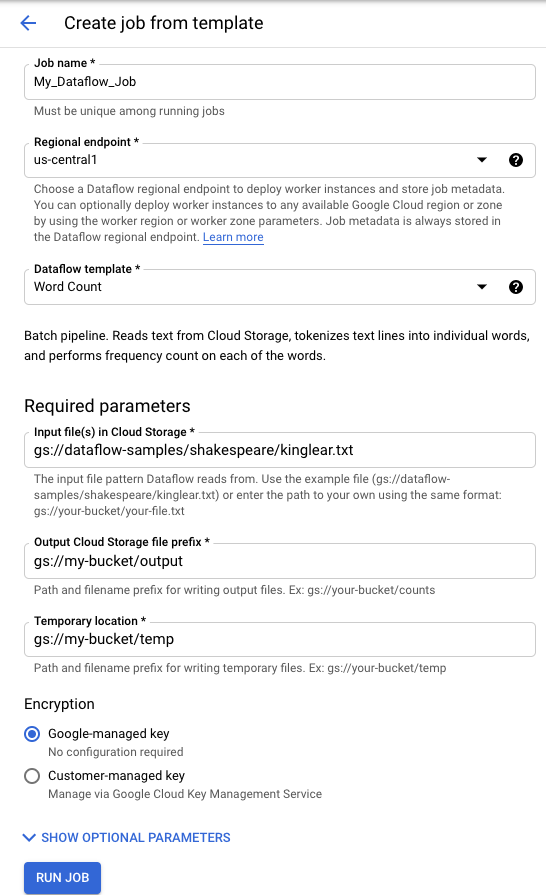
Para executar um modelo fornecido pela Google:
- Aceda à página Dataflow na Google Cloud consola. Aceda à página Fluxo de dados
- Clique em add_boxCRIAR TAREFA A PARTIR DE MODELO.
- Selecione o modelo fornecido pela Google que quer executar no menu pendente Modelo do Dataflow.
- Introduza um nome de tarefa no campo Nome da tarefa.
- Introduza os valores dos parâmetros nos campos de parâmetros fornecidos. Não precisa da secção Parâmetros adicionais quando usa um modelo fornecido pela Google.
- Clique em Executar tarefa.

Modelos personalizados
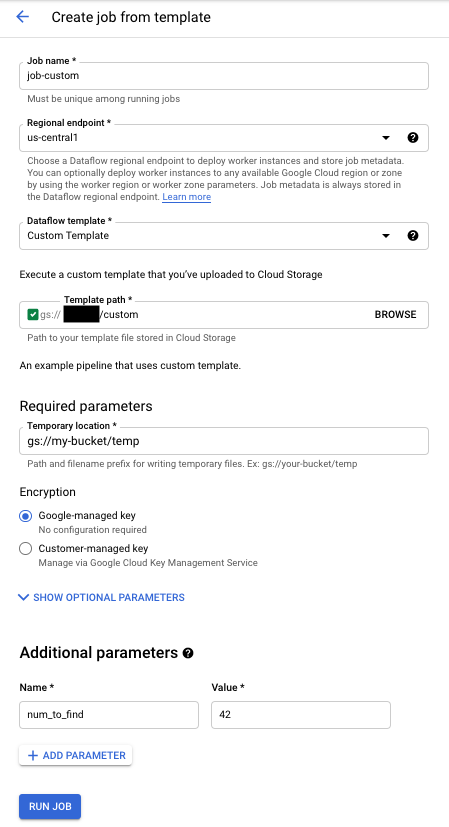
Para executar um modelo personalizado:
- Aceda à página Dataflow na Google Cloud consola. Aceda à página Fluxo de dados
- Clique em CRIAR TAREFA A PARTIR DE MODELO.
- Selecione Modelo personalizado no menu pendente Modelo de fluxo de dados.
- Introduza um nome de tarefa no campo Nome da tarefa.
- Introduza o caminho do Cloud Storage para o ficheiro de modelo no campo de caminho do Cloud Storage do modelo.
- Se o seu modelo precisar de parâmetros, clique em addADICIONAR PARÂMETRO na secção Parâmetros adicionais. Introduza o Nome e o Valor do parâmetro. Repita este passo para cada parâmetro necessário.
- Clique em Executar tarefa.
Use a API REST
Para executar um modelo com um pedido da API REST, envie um pedido HTTP POST com o ID do seu projeto. Este pedido requer autorização.
Consulte a referência da API REST para projects.locations.templates.launch para saber mais acerca dos parâmetros disponíveis.
Crie uma tarefa em lote de modelos personalizados
Este pedido projects.locations.templates.launch cria uma tarefa em lote a partir de um modelo que lê um ficheiro de texto e escreve um ficheiro de texto de saída. Se o pedido for bem-sucedido, o corpo da resposta contém uma instância de LaunchTemplateResponse.
Modifique os seguintes valores:
- Substitua
YOUR_PROJECT_IDpelo ID do seu projeto. - Substitua
LOCATIONpela região do fluxo de dados à sua escolha. - Substitua
JOB_NAMEpor um nome de trabalho à sua escolha. - Substitua
YOUR_BUCKET_NAMEpelo nome do seu contentor do Cloud Storage. - Defina
gcsPathpara a localização do Cloud Storage do ficheiro do modelo. - Defina
parameterspara a sua lista de pares de chave-valor. - Defina
tempLocationpara uma localização onde tenha autorização de escrita. Este valor é obrigatório para executar modelos fornecidos pela Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=gs://YOUR_BUCKET_NAME/templates/TemplateName
{
"jobName": "JOB_NAME",
"parameters": {
"inputFile" : "gs://YOUR_BUCKET_NAME/input/my_input.txt",
"output": "gs://YOUR_BUCKET_NAME/output/my_output"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Crie uma tarefa de streaming de modelo personalizado
Este exemplo projects.locations.templates.launch cria uma tarefa de streaming a partir de um modelo clássico que lê a partir de uma subscrição do Pub/Sub e escreve numa tabela do BigQuery. Se quiser iniciar um modelo flexível, use projects.locations.flexTemplates.launch em alternativa. O modelo de exemplo é um modelo fornecido pela Google. Pode modificar o caminho no modelo para apontar para um modelo personalizado. É usada a mesma lógica para iniciar modelos personalizados e fornecidos pela Google. Neste exemplo, a tabela do BigQuery já tem de existir com o esquema adequado. Se for bem-sucedido, o corpo da resposta contém uma instância de LaunchTemplateResponse.
Modifique os seguintes valores:
- Substitua
YOUR_PROJECT_IDpelo ID do seu projeto. - Substitua
LOCATIONpela região do fluxo de dados à sua escolha. - Substitua
JOB_NAMEpor um nome de trabalho à sua escolha. - Substitua
YOUR_BUCKET_NAMEpelo nome do seu contentor do Cloud Storage. - Substitua
GCS_PATHpela localização de armazenamento na nuvem do ficheiro de modelo. A localização deve começar com gs:// - Defina
parameterspara a sua lista de pares de chave-valor. Os parâmetros listados são específicos deste exemplo de modelo. Se estiver a usar um modelo personalizado, modifique os parâmetros conforme necessário. Se estiver a usar o modelo de exemplo, substitua as seguintes variáveis.- Substitua
YOUR_SUBSCRIPTION_NAMEpelo nome da sua subscrição do Pub/Sub. - Substitua
YOUR_DATASETpelo seu conjunto de dados do BigQuery e substituaYOUR_TABLE_NAMEpelo nome da sua tabela do BigQuery.
- Substitua
- Defina
tempLocationpara uma localização onde tenha autorização de escrita. Este valor é obrigatório para executar modelos fornecidos pela Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH
{
"jobName": "JOB_NAME",
"parameters": {
"inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_SUBSCRIPTION_NAME",
"outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Atualize uma tarefa de streaming de modelo personalizado
Este exemplo de pedido projects.locations.templates.launch mostra como atualizar uma tarefa de streaming de modelos. Se quiser atualizar um modelo flexível, use projects.locations.flexTemplates.launch em alternativa.
- Run Exemplo 2: criar uma tarefa de streaming de modelo personalizado para iniciar uma tarefa de modelo de streaming.
- Envie o seguinte pedido HTTP POST com os seguintes valores modificados:
- Substitua
YOUR_PROJECT_IDpelo ID do seu projeto. - Substitua
LOCATIONpela região do Dataflow da tarefa que está a atualizar. - Substitua
JOB_NAMEpelo nome exato da tarefa que quer atualizar. - Substitua
GCS_PATHpela localização de armazenamento na nuvem do ficheiro de modelo. A localização deve começar com gs:// - Defina
parameterspara a sua lista de pares de chave-valor. Os parâmetros listados são específicos deste exemplo de modelo. Se estiver a usar um modelo personalizado, modifique os parâmetros conforme necessário. Se estiver a usar o modelo de exemplo, substitua as seguintes variáveis.- Substitua
YOUR_SUBSCRIPTION_NAMEpelo nome da sua subscrição do Pub/Sub. - Substitua
YOUR_DATASETpelo seu conjunto de dados do BigQuery e substituaYOUR_TABLE_NAMEpelo nome da sua tabela do BigQuery.
- Substitua
- Use o parâmetro
environmentpara alterar as definições do ambiente, como o tipo de máquina. Este exemplo usa o tipo de máquina n2-highmem-2, que tem mais memória e CPU por trabalhador do que o tipo de máquina predefinido.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH { "jobName": "JOB_NAME", "parameters": { "inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_TOPIC_NAME", "outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME" }, "environment": { "machineType": "n2-highmem-2" }, "update": true } - Substitua
- Aceda à interface de monitorização do Dataflow e verifique se foi criada uma nova tarefa com o mesmo nome. Este trabalho tem o estado Atualizado.
Use as bibliotecas cliente de APIs Google
Considere usar as bibliotecas cliente de APIs Google para fazer chamadas facilmente para as APIs REST do Dataflow. Este script de exemplo usa a biblioteca cliente de APIs Google para Python.
Neste exemplo, tem de definir as seguintes variáveis:
project: definido como o ID do seu projeto.job: definido para um nome de tarefa exclusivo à sua escolha.template: definido para a localização do ficheiro de modelo no Cloud Storage.parameters: definido como um dicionário com os parâmetros do modelo.
Para definir a
região,
inclua o parâmetro
location.
Para mais informações sobre as opções disponíveis, consulte o método projects.locations.templates.launch na referência da API REST Dataflow.
Use a CLI gcloud
A CLI gcloud pode executar um modelo personalizado ou um modelo
fornecido pela Google
através do comando gcloud dataflow jobs run. Os exemplos de execução de modelos fornecidos pela Google estão documentados na página de modelos fornecidos pela Google.
Para os seguintes exemplos de modelos personalizados, defina os seguintes valores:
- Substitua
JOB_NAMEpor um nome de trabalho à sua escolha. - Substitua
YOUR_BUCKET_NAMEpelo nome do seu contentor do Cloud Storage. - Defina
--gcs-locationpara a localização do Cloud Storage do ficheiro de modelo. - Defina
--parameterspara a lista de parâmetros separados por vírgulas a transmitir à tarefa. Não são permitidos espaços entre vírgulas e valores. - Para impedir que as VMs aceitem chaves SSH armazenadas nos metadados do projeto, use a flag
additional-experimentscom a opção de serviçoblock_project_ssh_keys:--additional-experiments=block_project_ssh_keys.
Crie uma tarefa em lote de modelos personalizados
Este exemplo cria uma tarefa em lote a partir de um modelo que lê um ficheiro de texto e escreve um ficheiro de texto de saída.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters inputFile=gs://YOUR_BUCKET_NAME/input/my_input.txt,output=gs://YOUR_BUCKET_NAME/output/my_output
O pedido devolve uma resposta com o seguinte formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_BATCH
Crie uma tarefa de streaming de modelo personalizado
Este exemplo cria uma tarefa de streaming a partir de um modelo que lê a partir de um tópico do Pub/Sub e escreve numa tabela do BigQuery. A tabela do BigQuery já tem de existir com o esquema adequado.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters topic=projects/project-identifier/topics/resource-name,table=my_project:my_dataset.my_table_name
O pedido devolve uma resposta com o seguinte formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_STREAMING
Para ver uma lista completa de flags para o comando gcloud dataflow jobs run, consulte a referência da CLI gcloud.
Monitorização e resolução de problemas
A interface de monitorização do Dataflow permite-lhe monitorizar as suas tarefas do Dataflow. Se uma tarefa falhar, pode encontrar sugestões de resolução de problemas, estratégias de depuração e um catálogo de erros comuns no guia Resolução de problemas do pipeline.