Kurzanleitung zu SQL
In dieser Kurzanleitung erfahren Sie, wie Sie eine SQL-Syntax schreiben, um ein öffentlich verfügbares Pub/Sub-Thema abzufragen. Die SQL-Abfrage führt eine Dataflow-Pipeline aus und die Ergebnisse der Pipeline werden in eine BigQuery-Tabelle geschrieben.
Zum Ausführen eines Dataflow SQL-Jobs können Sie die Google Cloud Console, die auf einem lokalen Computer installierte Google Cloud-CLI oder Cloud Shell verwenden. Zusätzlich zur Cloud Console müssen Sie in diesem Beispiel entweder einen lokalen Computer oder Cloud Shell verwenden.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, und Google Cloud Data Catalog APIs aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, und Google Cloud Data Catalog APIs aktivieren.
gcloud-CLI installieren und initialisieren
Laden Sie das
gcloud-Befehlszeilen-Paket für Ihr Betriebssystem herunter und installieren und konfigurieren Sie diegcloud-Befehlszeile.Je nach Internetverbindung kann der Download eine Weile dauern.
BigQuery-Dataset erstellen
In dieser Kurzanleitung veröffentlicht die Dataflow SQL-Pipeline ein BigQuery-Dataset in einer BigQuery-Tabelle, die Sie im nächsten Abschnitt erstellen.
BigQuery-Dataset mit dem Namen
taxirideserstellen:bq mk taxirides
Pipeline ausführen
Führen Sie eine Dataflow-SQL-Pipeline aus, die die Anzahl der Fahrgäste pro Minute berechnet. Dazu werden Daten aus einem öffentlich verfügbaren Pub/Sub-Thema zu Taxifahrten verwendet. Mit diesem Befehl wird auch eine BigQuery-Tabelle mit dem Namen
passengers_per_minutezum Speichern der Datenausgabe erstellt.gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Es kann eine Weile dauern, bis der Dataflow SQL-Job ausgeführt wird.
Im Folgenden werden die in der Dataflow SQL-Pipeline verwendeten Werte beschrieben:
dataflow-sql-quickstart: der Name des Dataflow-Jobsus-central1: die Region, in der der Job ausgeführt wirdtaxirides: der Name des BigQuery-Datasets, das als Senke verwendet wirdpassengers_per_minute: der Name der BigQuery-Tabelletaxirides-realtime: der Name des Pub/Sub-Themas, das als Quelle verwendet wird
Der SQL-Befehl fragt das Pub/Sub-Thema taxirides-realtime nach der Gesamtzahl der Fahrgäste ab, die alle 60 Sekunden mitgenommen werden. Dieses öffentliche Thema basiert auf dem öffentlichen Dataset "NYC Taxi & Limousine Commission".
Ergebnisse aufrufen
Prüfen Sie, ob die Pipeline ausgeführt wird.
Console
Rufen Sie in der Cloud Console die Seite Jobs von Dataflow auf.
Klicken Sie in der Liste der Jobs auf dataflow-sql-quickstart.
Achten Sie im Bereich Jobinfo darauf, dass das Feld Jobstatus auf Wird ausgeführt gesetzt ist.
Der Start des Jobs kann einige Minuten dauern. Der Jobstatus ist auf In Warteschlange gesetzt, bis der Job gestartet wird.
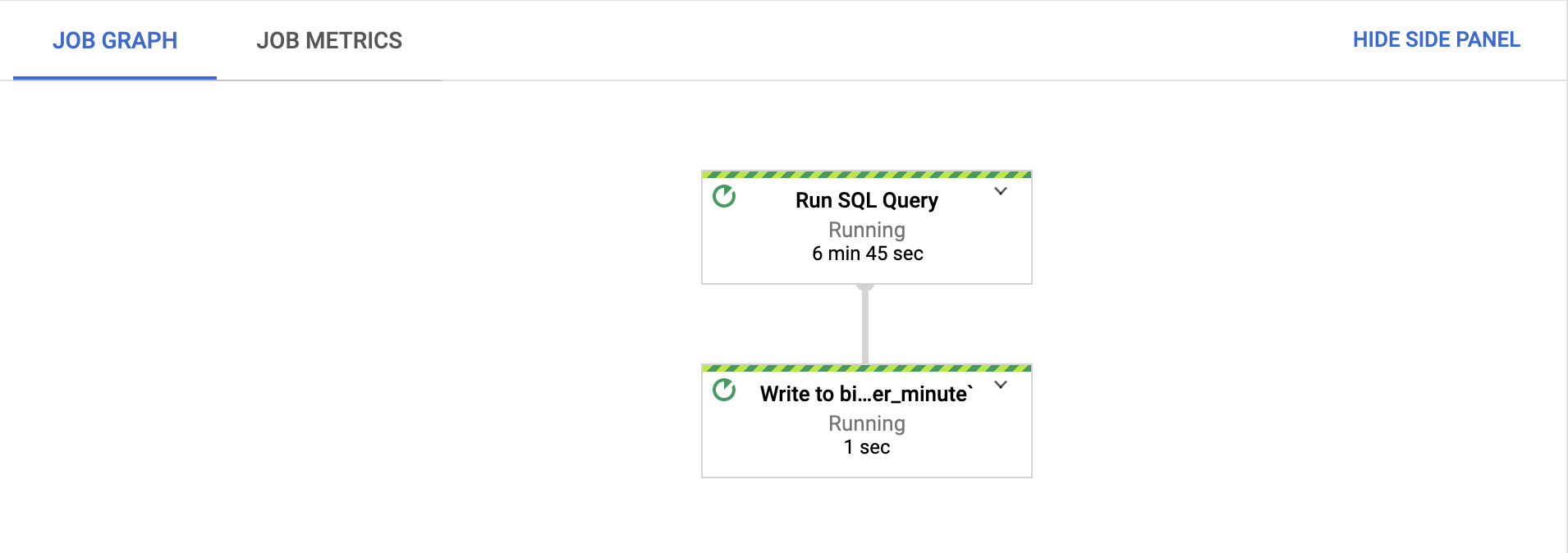
Prüfen Sie auf dem Tab Jobgrafik, ob jeder Schritt ausgeführt wird.
Nach dem Start des Jobs kann es einige Minuten dauern, bis die Schritte ausgeführt werden.
Rufen Sie in der Cloud Console die Seite BigQuery auf.
Fügen Sie im Editor die folgende SQL-Abfrage ein und klicken Sie auf Ausführen:
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'Diese Abfrage gibt die größten Aktivität-Intervalle aus der Tabelle
passengers_per_minutezurück.
gcloud
Rufen Sie die Liste der Dataflow-Jobs ab, die in Ihrem Projekt ausgeführt werden:
gcloud dataflow jobs listWeitere Informationen zum Job
dataflow-sql-quickstartabrufen:gcloud dataflow jobs describe JOB_IDErsetzen Sie
JOB_IDdurch die Job-ID desdataflow-sql-quickstart-Jobs aus Ihrem Projekt.Geben Sie die Intervalle mit der größten Aktivität aus der Tabelle
passengers_per_minutezurück.bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
Rufen Sie zum Abbrechen des Dataflow-Jobs die Seite Jobs auf.
Klicken Sie in der Liste der Jobs auf dataflow-sql-quickstart.
Klicken Sie auf Beenden > Abbrechen > Job anhalten.
Löschen Sie das Dataset
taxirides.bq rm taxiridesGeben Sie
yein, um den Löschvorgang zu bestätigen.
Nächste Schritte
- Weitere Informationen zur Verwendung von Dataflow SQL.
- Lesen Sie mehr zur Verwendung von Datenquellen und -zielen in Dataflow-SQL-Abfragen.
gcloud-Befehlszeile für Dataflow SQL ansehen.