Auf dieser Seite wird erläutert, wie Sie Daten abfragen und Abfrageergebnisse mithilfe von Dataflow SQL schreiben.
Dataflow SQL kann die folgenden Quellen abfragen:
- Daten aus Pub/Sub-Themen streamen
- Streaming- und Batchdaten aus Cloud Storage-Dateisätzen
- Batch-Daten aus BigQuery-Tabellen
Dataflow SQL kann Abfrageergebnisse in die folgenden Ziele schreiben:
Pub/Sub
Pub/Sub-Themen abfragen
Führen Sie die folgenden Schritte aus, um mithilfe von Dataflow SQL ein Pub/Sub-Thema abzufragen:
Verwenden Sie das Pub/Sub-Thema in einer Dataflow SQL-Abfrage.
Pub/Sub-Thema hinzufügen
Mithilfe der BigQuery-Web-UI können Sie ein Pub/Sub-Thema als Dataflow-Quelle hinzufügen.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf, auf der Sie Dataflow SQL verwenden können.
Klicken Sie im Navigationsbereich auf die Drop-down-Liste Daten hinzufügen und wählen Sie Cloud Dataflow-Quellen aus.

Wählen Sie im Bereich Cloud Dataflow-Quelle hinzufügen die Option Cloud Pub/Sub-Themen aus und suchen Sie nach dem Thema.
Der folgende Screenshot zeigt eine Suche nach dem Pub/Sub-Thema
transactions: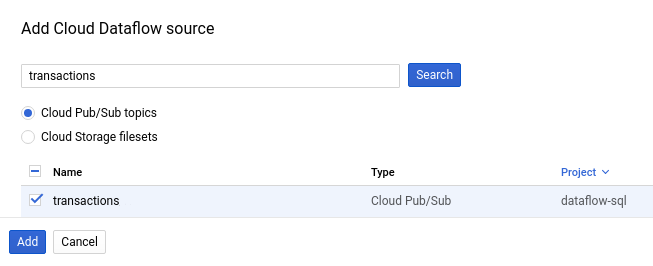
Klicken Sie auf Hinzufügen.
Nachdem Sie das Pub/Sub-Thema als Dataflow-Quelle hinzugefügt haben, wird das Pub/Sub-Thema im Navigationsmenü im Abschnitt Ressourcen angezeigt.
Erweitern Sie Cloud Dataflow-Quellen > Cloud Pub/Sub-Themen, um das Thema zu finden.
Schema für ein Pub/Sub-Thema zuweisen
Schemas für Pub/Sub-Themen bestehen aus den folgenden Feldern:
Einem
event_timestamp-Feld.Zeitstempel für Pub/Sub-Ereignisse geben an, wann die Nachrichten veröffentlicht werden. Die Zeitstempel werden Pub/Sub-Nachrichten automatisch hinzugefügt.
Einem Feld für jedes Schlüssel/Wert-Paar in den Pub/Sub-Nachrichten.
Das Schema für die Nachricht
{"k1":"v1", "k2":"v2"}enthält beispielsweise zweiSTRING-Felder mit den Namenk1undk2.
Sie können einem Pub/Sub-Thema über die Cloud Console oder die Google Cloud CLI ein Schema zuweisen.
Console
Führen Sie die folgenden Schritte aus, um einem Pub/Sub-Thema ein Schema zuzuweisen:
Wählen Sie das Thema im Feld Ressourcen aus.
Klicken Sie auf dem Tab Schema auf Schema bearbeiten, um die Seitenleiste Schema mit den Schemafeldern zu öffnen.
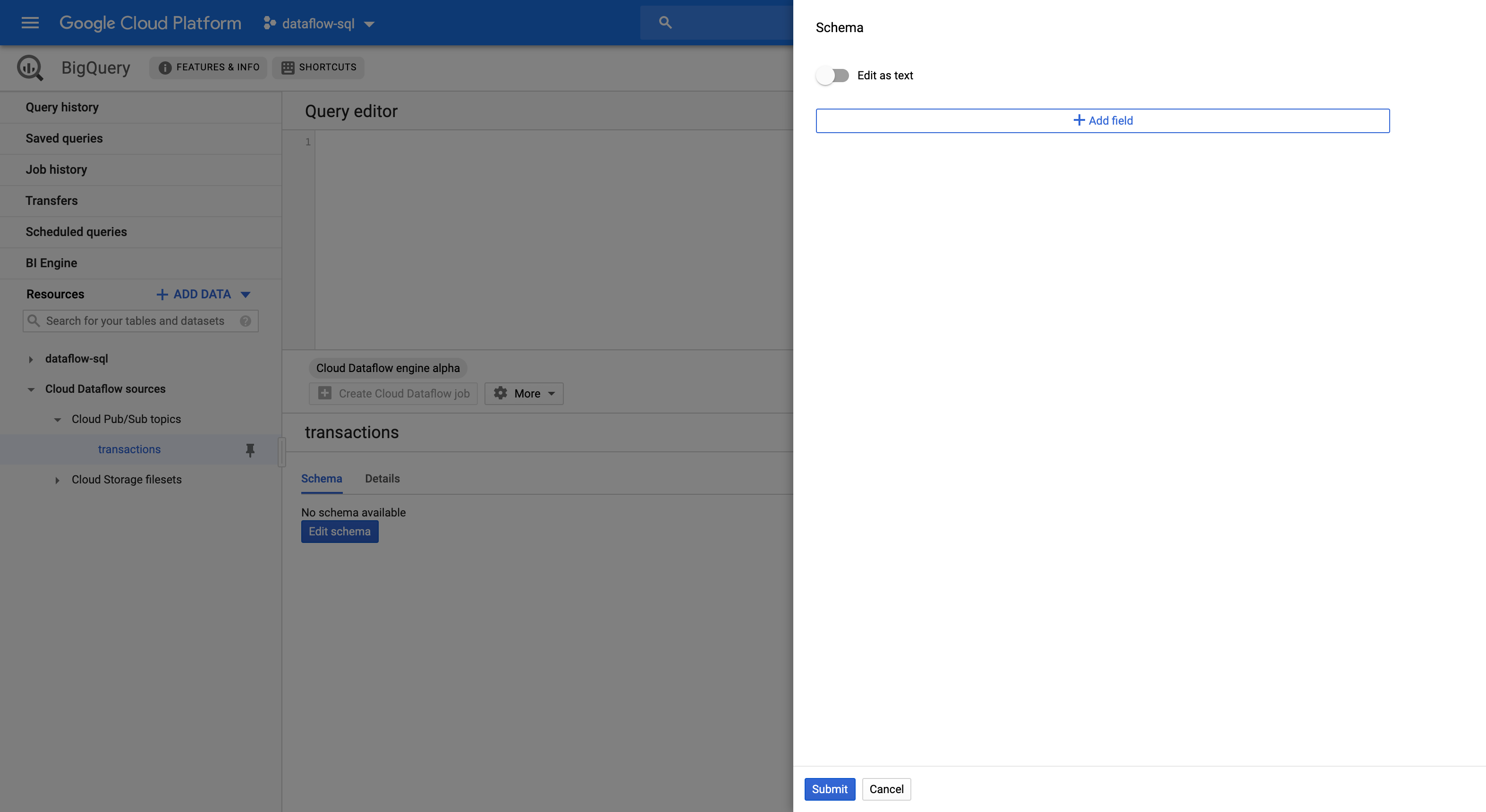
Klicken Sie auf Feld hinzufügen, um ein Feld zum Schema hinzuzufügen, oder auf die Schaltfläche Als Text bearbeiten, um den gesamten Schematext zu kopieren und einzufügen.
Im Folgenden finden Sie beispielsweise den Schematext für ein Pub/Sub-Thema mit Verkaufstransaktionen.
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Klicken Sie auf Senden.
(Optional) Klicken Sie auf Vorschau des Themas, um den Inhalt Ihrer Nachrichten zu prüfen und zu bestätigen, dass sie mit dem von Ihnen definierten Schema übereinstimmen.
gcloud
Führen Sie die folgenden Schritte aus, um einem Pub/Sub-Thema ein Schema zuzuweisen:
Erstellen Sie eine JSON-Datei mit dem Schematext.
Im Folgenden finden Sie beispielsweise den Schematext für ein Pub/Sub-Thema mit Verkaufstransaktionen.
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Weisen Sie das Schema mithilfe des Befehls
gcloud data-catalog entriesdem Pub/Sub-Thema zu:gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
Dabei gilt:
PROJECT_ID: Ihre Projekt-IDTOPIC_NAME: der Name Ihres Pub/Sub-ThemasFILE_PATH: der Pfad für die JSON-Datei mit dem Schematext
Optional: Überprüfen Sie mit dem folgenden Befehl, ob Ihr Schema dem Pub/Sub-Thema erfolgreich zugewiesen wurde:
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Pub/Sub-Thema verwenden
Verwenden Sie die folgenden Kennzeichnungen, um in einer Dataflow SQL-Abfrage auf ein Pub/Sub-Thema zu verweisen:
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
Dabei gilt:
PROJECT_ID: Ihre Projekt-IDTOPIC_NAME: der Name Ihres Pub/Sub-Themas
Die folgende Abfrage wählt beispielsweise aus dem Dataflow-Thema daily.transactions im Projekt dataflow-sql aus:
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
In Pub/Sub-Themen schreiben
Sie können Abfrageergebnisse mithilfe der Cloud Console oder der Google Cloud CLI in ein Pub/Sub-Thema schreiben.
Console
Führen Sie die Abfrage mit Dataflow SQL aus, um Abfrageergebnisse in ein Pub/Sub-Thema zu schreiben:
Rufen Sie in der Cloud Console die Seite BigQuery auf, auf der Sie Dataflow SQL verwenden können.
Geben Sie die Dataflow SQL-Abfrage in den Abfrageeditor ein.
Klicken Sie auf Cloud Dataflow-Job erstellen, um einen Bereich mit Joboptionen zu öffnen.
Wählen Sie in diesem Bereich im Abschnitt Ziel die Option Ausgabetyp > Cloud Pub/Sub-Thema aus.
Klicken Sie auf Cloud Pub/Sub-Thema auswählen und wählen Sie ein Thema aus.
Klicken Sie auf Erstellen.
gcloud
Verwenden Sie das Flag --pubsub-topic des Befehls gcloud dataflow sql query, um Abfrageergebnisse in ein Pub/Sub-Thema zu schreiben:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
Dabei gilt:
JOB_NAME: ein Jobname Ihrer WahlREGION: der regionale Endpunkt (z. B.us-west1)PROJECT_ID: Ihre Projekt-IDTOPIC_NAME: der Name Ihres Pub/Sub-ThemasQUERY: Dataflow-SQL-Abfrage
Das Schema der Pub/Sub-Zielthemen muss mit dem Schema der Abfrageergebnisse übereinstimmen. Wenn ein Pub/Sub-Zielthema kein Schema hat, wird automatisch ein Schema zugewiesen, das mit den Abfrageergebnissen übereinstimmt.
Cloud Storage
Cloud Storage-Dateisätze abfragen
Führen Sie die folgenden Schritte aus, um mithilfe von Dataflow SQL einen Cloud Storage-Dateisatz abzufragen:
Erstellen Sie einen Data Catalog-Dateisatz für Dataflow SQL.
Fügen Sie den Cloud Storage-Dateisatz als Dataflow-Quelle hinzu.
Verwenden Sie den Cloud Storage-Dateisatz in einer Dataflow SQL-Abfrage.
Cloud Storage-Dateisätze erstellen
Informationen zum Erstellen eines Cloud Storage-Dateisatzes finden Sie unter Eintragsgruppen und Dateisätze erstellen.
Der Cloud Storage-Dateisatz muss ein Schema haben und darf nur CSV-Dateien ohne Kopfzeilen enthalten.
Cloud Storage-Dateisätze hinzufügen
Sie können ein Cloud Storage-Dateisatz als Dataflow-Quelle mithilfe von Dataflow SQL hinzufügen:
Rufen Sie in der Cloud Console die Seite BigQuery auf, auf der Sie Dataflow SQL verwenden können.
Klicken Sie im Navigationsbereich auf die Drop-down-Liste Daten hinzufügen und wählen Sie Cloud Dataflow-Quellen aus.
Wählen Sie im Bereich Cloud Dataflow-Quelle hinzufügen die Option Cloud Storage-Dateisätze aus und suchen Sie nach dem Thema.
Klicken Sie auf Hinzufügen.
Nachdem Sie den Cloud Storage-Dateisatz als Dataflow-Quelle hinzugefügt haben, wird er im Navigationsmenü im Bereich Ressourcen angezeigt.
Maximieren Sie Cloud Dataflow-Quellen > Cloud Storage-Themen, um den Dateisatz zu finden.
Cloud Storage-Dateisatz verwenden
Verwenden Sie die folgenden Kennzeichnungen, um in einer Dataflow SQL-Abfrage auf eine Cloud Storage-Tabelle zu verweisen:
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
Dabei gilt:
PROJECT_ID: Ihre Projekt-IDREGION: der regionale Endpunkt (z. B.us-west1)ENTRY_GROUP: die Eintragsgruppe des Cloud Storage-DateisatzesFILESET_NAME: Name des Cloud Storage-Dateisatzes
Die folgende Abfrage wählt beispielsweise aus dem Cloud Storage-Dateisatz daily.registrations im Projekt dataflow-sql und der Eintragsgruppe my-fileset-group aus:
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
BigQuery-Tabellen abfragen
Führen Sie die folgenden Schritte aus, um eine BigQuery-Tabelle mithilfe von Dataflow SQL abzufragen:
Erstellen Sie eine BigQuery-Tabelle für Dataflow SQL.
Verwenden Sie die BigQuery-Tabelle in einer Dataflow SQL-Abfrage.
Es ist nicht erforderlich, dass Sie eine BigQuery-Tabelle als Dataflow-Quelle hinzufügen.
BigQuery-Tabelle erstellen
Informationen zum Erstellen einer BigQuery-Tabelle für Dataflow SQL finden Sie unter Leere Tabelle mit einer Schemadefinition erstellen.
BigQuery-Tabelle in einer Abfrage verwenden
Verwenden Sie die folgenden Kennzeichnungen, um in einer Dataflow SQL-Abfrage auf eine BigQuery-Tabelle zu verweisen:
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
Die Kennzeichnungen müssen der lexikalischen Dataflow SQL-Struktur entsprechen. Verwenden Sie Graviszeichen, um Kennzeichnungen mit Zeichen einzuschließen, die keine Buchstaben, Ziffern oder Unterstriche sind.
Die folgende Abfrage wählt beispielsweise aus der BigQuery-Tabelle us_state_salesregions im Dataset dataflow_sql_dataset und dem Projekt dataflow-sql aus:
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
In BigQuery-Tabelle schreiben
Sie können Abfrageergebnisse mit der Cloud Console oder der Google Cloud CLI in eine Dataflow SQL-Abfrage schreiben.
Console
Führen Sie die Abfrage mit Dataflow SQL aus, um Abfrageergebnisse in eine Dataflow-SQL-Abfrage zu schreiben:
Rufen Sie in der Cloud Console die Seite BigQuery auf, auf der Sie Dataflow SQL verwenden können.
Geben Sie die Dataflow SQL-Abfrage in den Abfrageeditor ein.
Klicken Sie auf Cloud Dataflow-Job erstellen, um einen Bereich mit Joboptionen zu öffnen.
Wählen Sie in diesem Bereich im Abschnitt Ziel die Option Ausgabetyp > BigQuery aus.
Klicken Sie auf Dataset-ID und wählen Sie ein geladenes Dataset oder Neues Dataset erstellen aus.
Geben Sie im Feld Tabellenname eine Zieltabelle ein.
(Optional) Wählen Sie aus, wie Daten in eine BigQuery-Tabelle geladen werden sollen.
- Schreiben, wenn leer: (Standard) Schreibt die Daten nur, wenn die Tabelle leer ist.
- An Tabelle anfügen: Fügt die Daten an das Ende der Tabelle an.
- Tabelle überschreiben: Löscht alle vorhandenen Daten in einer Tabelle, bevor die neuen Daten geschrieben werden.
Klicken Sie auf Erstellen.
gcloud
Verwenden Sie das Flag --bigquery-table des Befehls gcloud dataflow sql query, um Abfrageergebnisse in eine BigQuery-Tabelle zu schreiben:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
Dabei gilt:
JOB_NAME: ein Jobname Ihrer WahlREGION: der regionale Endpunkt (z. B.us-west1)DATASET_NAME: der Name Ihres BigQuery-DatasetsTABLE_NAME: Ihr BigQuery-TabellennameQUERY: Dataflow-SQL-Abfrage
Um auszuwählen, wie Daten in eine BigQuery-Tabelle geschrieben werden, können Sie das Flag --bigquery-write-disposition und die folgenden Werte verwenden:
write-empty: (Standard) Schreibt die Daten nur, wenn die Tabelle leer ist.write-append: Fügt die Daten an das Ende der Tabelle an.write-truncateLöscht alle vorhandenen Daten in einer Tabelle, bevor die neuen Daten geschrieben werden.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
Ersetzen Sie WRITE_MODE durch den BigQuery-Schreibanordnungswert.
Das Schema der BigQuery-Zieltabelle muss mit dem Schema der Abfrageergebnisse übereinstimmen. Wenn eine BigQuery-Zieltabelle kein Schema hat, wird automatisch ein Schema zugewiesen, das mit den Abfrageergebnissen übereinstimmt.