Ejecuta una canalización con el compilador de trabajos
En esta guía de inicio rápido, se muestra cómo ejecutar un trabajo de Dataflow con el Compilador de trabajos de Dataflow. El compilador de trabajos es una IU visual para compilar y ejecutar canalizaciones de Dataflow en la consola de Google Cloud , sin escribir ningún código.
En esta guía de inicio rápido, cargarás una canalización de ejemplo en el compilador de trabajos, ejecutarás un trabajo y verificarás que el resultado haya creado el trabajo.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
- Crea un bucket de Cloud Storage:
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a unique bucket name. Don't include sensitive information in the bucket name, because the bucket namespace is global and publicly visible.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- In the Set a default class section, select the following: Standard.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
- Click Create.
Para completar los pasos de esta guía de inicio rápido, tu cuenta de usuario debe tener los roles de Administrador de Dataflow y Usuario de cuenta de servicio. La cuenta de servicio predeterminada de Compute Engine debe tener el rol de trabajador de Dataflow. Para agregar los roles necesarios en la consola de Google Cloud , haz lo siguiente:
- Ir a la página IAM.
Ir a IAM - Elige tu proyecto.
- En la fila que contiene tu cuenta de usuario, haz clic en Editar principal.
- Haz clic en Agregar otro rol y, en la lista desplegable, selecciona Administrador de Dataflow.
- Haz clic en Agregar otro rol y, en la lista desplegable, selecciona Usuario de cuenta de servicio.
- Haz clic en Guardar.
- En la fila que contiene la cuenta de servicio predeterminada de Compute Engine, haz clic en Editar principal.
- Haz clic en Agregar otro rol y, en la lista desplegable, selecciona Trabajador de Dataflow.
- Haz clic en Agregar otra función y, en la lista desplegable, selecciona Administrador de objetos de almacenamiento.
Haz clic en Guardar.
Para obtener más información sobre cómo otorgar roles, consulta Otorga un rol de IAM mediante la consola.
- Ir a la página IAM.
- De forma predeterminada, cada proyecto nuevo comienza con una red predeterminada.
Si la red predeterminada de tu proyecto está inhabilitada o se borró, debes tener una red en tu proyecto para la que tenga tu cuenta de usuario Rol de usuario de la red de Compute (
roles/compute.networkUser).
Carga la canalización de ejemplo
En este paso, cargarás una canalización de ejemplo que cuenta las palabras en El rey Lear de Shakespeare.
Ve a la página Trabajos en la consola de Google Cloud .
Haz clic en Crear trabajo a partir de una plantilla.
Haz clic en Compilador de trabajos.
Haz clic en Cargar.
Haz clic en Recuento de palabras. El compilador de trabajos se propaga con una representación gráfica de la canalización.
Para cada paso de la canalización, el compilador de trabajos muestra una tarjeta que especifica los parámetros de configuración de ese paso. Por ejemplo, el primer paso lee archivos de texto desde Cloud Storage. La ubicación de los datos de origen se propaga previamente en el cuadro Ubicación del texto.
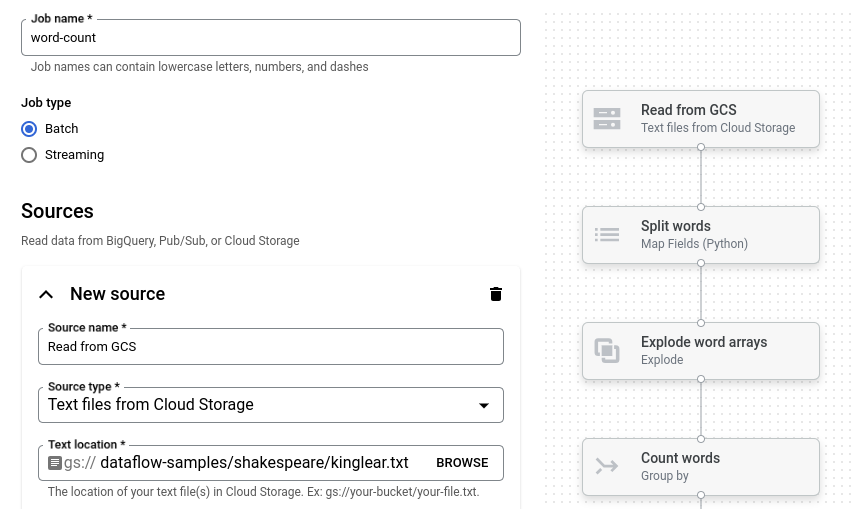
Configura la ubicación de salida
En este paso, debes especificar un bucket de Cloud Storage en el que la canalización escribe el resultado.
Busca la tarjeta titulada Nuevo receptor. Es posible que debas desplazarte.
En el cuadro Ubicación del texto, haz clic en Explorar.
Selecciona el nombre del bucket de Cloud Storage que creaste en Antes de comenzar.
Haz clic en Ver recursos secundarios.
En el cuadro Nombre del archivo, ingresa
words.Haz clic en Seleccionar.
Ejecuta el trabajo
Haga clic en Ejecutar trabajo. El compilador de trabajos crea un trabajo de Dataflow y, luego, navega al gráfico del trabajo. Cuando se inicia el trabajo, el gráfico del trabajo muestra una representación gráfica de la canalización, similar a la que se muestra en el compilador de trabajos. A medida que se ejecuta cada paso de la canalización, el estado se actualiza en el gráfico de trabajo.
En el panel Información del trabajo, se muestra el estado general del trabajo. Si el trabajo se completa correctamente, el campo Estado del trabajo se actualizará a Succeeded.
Examina el resultado del trabajo
Cuando se complete el trabajo, realiza los siguientes pasos para ver el resultado de la canalización:
En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
En la lista de buckets, haz clic en el nombre del bucket que creaste en la sección Antes de comenzar.
Haz clic en el archivo llamado
words-00000-of-00001.En la página Detalles del objeto, haz clic en la URL autenticada para ver el resultado de la canalización.
El resultado debería ser similar al siguiente:
brother: 20
deeper: 1
wrinkles: 1
'alack: 1
territory: 1
dismiss'd: 1
[....]
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta página.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el Google Cloud proyecto que creaste para la guía de inicio rápido.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Borra los recursos individuales
Si deseas conservar el proyecto Google Cloud que usaste en esta guía de inicio rápido, borra el bucket de Cloud Storage:
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click the checkbox for the bucket that you want to delete.
- To delete the bucket, click Delete, and then follow the instructions.