El compilador de trabajos es una IU visual para compilar y ejecutar canalizaciones de Dataflow en la consola de Google Cloud , sin escribir código.
En la siguiente imagen, se muestra un detalle de la IU del compilador de trabajos. En esta imagen, el usuario está creando una canalización para leer de Pub/Sub a BigQuery:
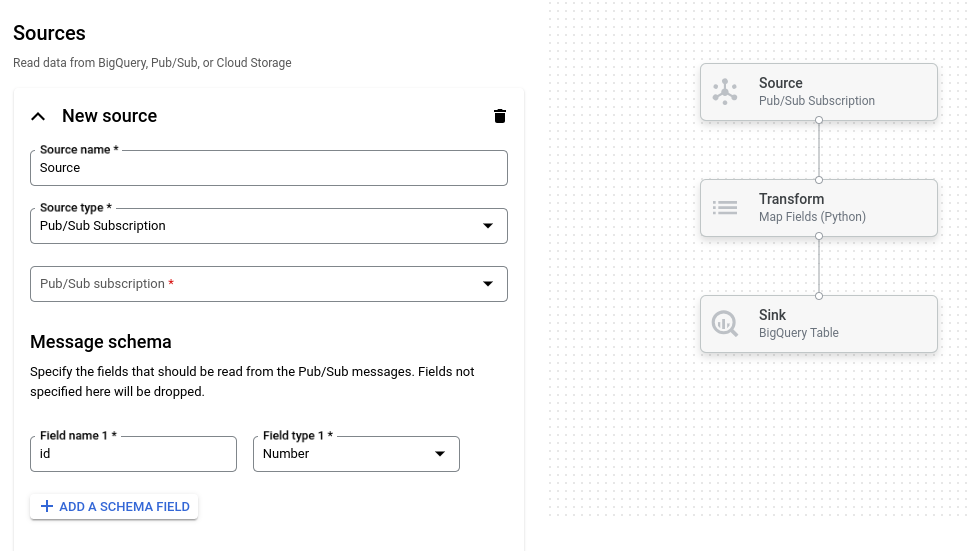
Descripción general
El compilador de trabajos admite la lectura y escritura de los siguientes tipos de datos:
- Mensajes de Pub/Sub
- Datos de la tabla de BigQuery
- Archivos CSV, JSON y de texto en Cloud Storage
- Datos de tablas de PostgreSQL, MySQL, Oracle y SQL Server
Admite transformaciones de canalización, como filtrar, asignar, SQL, agrupar, unir y explotar (aplanar el array).
Con el Creador de trabajos, puedes hacer lo siguiente:
- Transmite de Pub/Sub a BigQuery con transformaciones y agregación en ventanas
- Escribe datos de Cloud Storage en BigQuery
- Usa el manejo de errores para filtrar datos erróneos (cola de mensajes no entregados)
- Manipula o agrega datos con SQL con la transformación de SQL
- Agregar, modificar o quitar campos de los datos con transformaciones de asignación
- Programa trabajos por lotes recurrentes
El compilador de trabajos también puede guardar canalizaciones como archivos YAML de Apache Beam y cargar definiciones de canalizaciones desde archivos YAML de Beam. Con esta función, puedes diseñar tu canalización en el compilador de trabajos y, luego, almacenar el archivo YAML en Cloud Storage o en un repositorio de control de código fuente para reutilizarlo. Las definiciones de trabajos en YAML también se pueden usar para iniciar trabajos con gcloud CLI.
Considera el compilador de trabajos para los siguientes casos de uso:
- Quieres crear una canalización rápidamente sin escribir código.
- Quieres guardar una canalización en YAML para volver a usarla.
- Tu canalización se puede expresar con las fuentes, los receptores y las transformaciones compatibles.
- No hay ninguna plantilla proporcionada por Google que coincida con tu caso de uso.
Ejecuta un trabajo de muestra
El ejemplo de Word Count es una canalización por lotes que lee texto de Cloud Storage, convierte las líneas de texto en tokens de palabras individuales y cuenta la frecuencia con la que aparece cada palabra.
Si el bucket de Cloud Storage está fuera de tu perímetro de servicio, crea una regla de salida que permita el acceso al bucket.
Para ejecutar la canalización de Word Count, sigue estos pasos:
Ve a la página Trabajos en la Google Cloud consola.
Haz clic en Crear trabajo a partir de una plantilla.
En el panel lateral, haz clic en Compilador de trabajos.
Haz clic en Load blueprints.
Haz clic en Recuento de palabras. El compilador de trabajos se propaga con una representación gráfica de la canalización.
Para cada paso de la canalización, el compilador de trabajos muestra una tarjeta que especifica los parámetros de configuración de ese paso. Por ejemplo, el primer paso lee archivos de texto desde Cloud Storage. La ubicación de los datos de origen se propaga previamente en el cuadro Ubicación del texto.
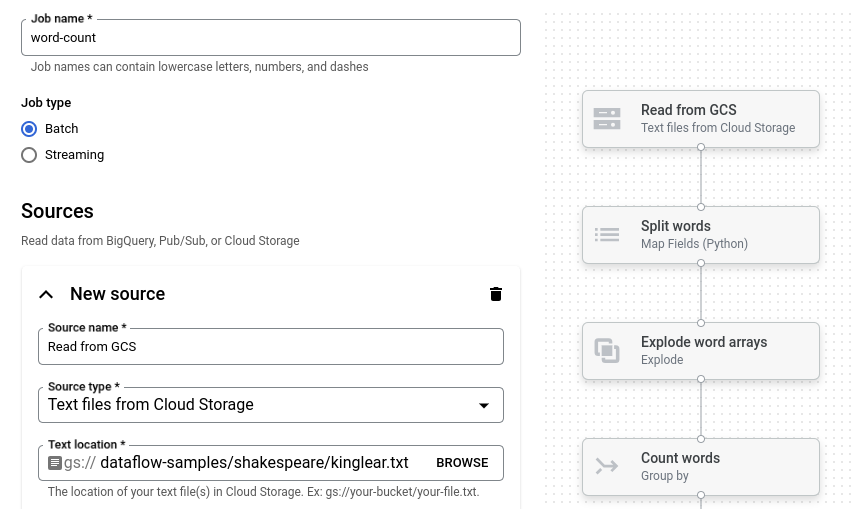
Busca la tarjeta titulada Nuevo receptor. Es posible que debas desplazarte.
En el cuadro Ubicación del texto, ingresa el prefijo de la ruta de acceso a la ubicación de Cloud Storage para los archivos de texto de salida.
Haga clic en Ejecutar trabajo. El compilador de trabajos crea un trabajo de Dataflow y, luego, navega al gráfico del trabajo. Cuando se inicia el trabajo, el gráfico del trabajo muestra una representación gráfica de la canalización. Esta representación gráfica es similar a la que se muestra en el compilador de trabajos. A medida que se ejecuta cada paso de la canalización, el estado se actualiza en el gráfico de trabajo.
En el panel Información del trabajo, se muestra el estado general del trabajo. Si el trabajo se completa correctamente, el campo Estado del trabajo se actualizará a Succeeded.
¿Qué sigue?
- Usa la interfaz de supervisión de trabajos de Dataflow
- Crea un trabajo personalizado en el compilador de trabajos.
- Guardar y cargar definiciones de trabajos en YAML en el compilador de trabajos
- Obtén más información sobre YAML de Beam.