Halaman ini memberikan ringkasan siklus proses pipeline dari kode pipeline hingga tugas Dataflow.
Halaman ini menjelaskan konsep berikut:
- Apa itu grafik eksekusi, dan bagaimana pipeline Apache Beam menjadi tugas Dataflow
- Cara Dataflow menangani error
- Cara Dataflow secara otomatis memparalelkan dan mendistribusikan logika pemrosesan di pipeline Anda ke pekerja yang menjalankan tugas Anda
- Pengoptimalan tugas yang mungkin dilakukan Dataflow
Grafik eksekusi
Saat Anda menjalankan pipeline Dataflow, Dataflow akan membuat grafik eksekusi dari kode yang membangun objek Pipeline Anda, termasuk semua transformasi dan fungsi pemrosesan terkaitnya, seperti objek DoFn. Ini adalah grafik eksekusi pipeline, dan fase ini disebut
waktu pembuatan grafik.
Selama konstruksi grafik, Apache Beam akan menjalankan kode secara lokal dari
titik entri utama kode pipeline, berhenti pada panggilan ke langkah sumber, sink,
atau transformasi, dan mengubah panggilan ini menjadi node grafik.
Oleh karena itu, potongan kode di titik entri pipeline (metode Java dan Go main
atau tingkat teratas skrip Python) dieksekusi secara lokal di mesin yang
menjalankan pipeline. Kode yang sama yang dideklarasikan dalam metode objek DoFn
dieksekusi di pekerja Dataflow.
Misalnya, sampel WordCount yang disertakan dengan SDK Apache Beam, berisi serangkaian transformasi untuk membaca, mengekstrak, menghitung, memformat, dan menulis setiap kata dalam kumpulan teks, beserta jumlah kemunculan untuk setiap kata. Diagram berikut menunjukkan cara transformasi dalam pipeline WordCount diperluas menjadi grafik eksekusi:
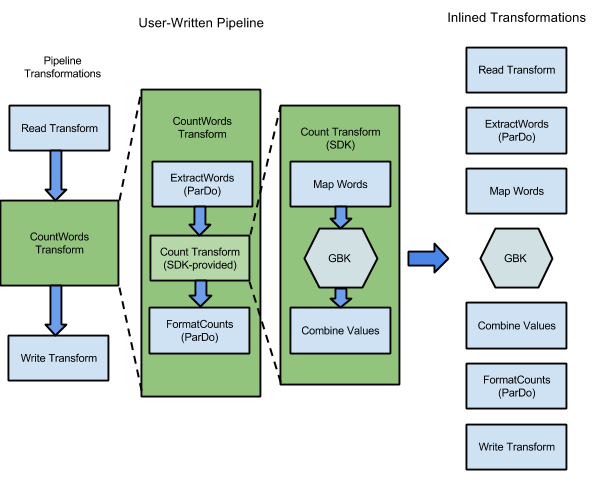
Gambar 1: Grafik eksekusi contoh WordCount
Grafik eksekusi sering kali berbeda dari urutan saat Anda menentukan transformasi saat membuat pipeline. Perbedaan ini ada karena layanan Dataflow melakukan berbagai pengoptimalan dan penggabungan pada grafik eksekusi sebelum dijalankan di resource cloud terkelola. Layanan Dataflow mematuhi dependensi data saat menjalankan pipeline Anda. Namun, langkah-langkah tanpa dependensi data di antaranya dapat dijalankan dalam urutan apa pun.
Untuk melihat grafik eksekusi yang tidak dioptimalkan yang telah dibuat Dataflow untuk pipeline Anda, pilih tugas Anda di antarmuka pemantauan Dataflow. Untuk mengetahui informasi selengkapnya tentang cara melihat tugas, lihat Menggunakan antarmuka pemantauan Dataflow.
Selama konstruksi grafik, Apache Beam memvalidasi bahwa semua resource yang dirujuk oleh pipeline, seperti bucket Cloud Storage, tabel BigQuery, dan topik atau langganan Pub/Sub, benar-benar ada dan dapat diakses. Validasi dilakukan melalui panggilan API standar ke layanan masing-masing, jadi penting agar akun pengguna yang digunakan untuk menjalankan pipeline memiliki konektivitas yang tepat ke layanan yang diperlukan dan diizinkan untuk memanggil API layanan. Sebelum mengirimkan pipeline ke layanan Dataflow, Apache Beam juga memeriksa kesalahan lainnya, dan memastikan bahwa grafik pipeline tidak berisi operasi ilegal.
Grafik eksekusi kemudian diterjemahkan ke dalam format JSON, dan grafik eksekusi JSON dikirimkan ke endpoint layanan Dataflow.
Layanan Dataflow kemudian memvalidasi grafik eksekusi JSON. Saat grafik divalidasi, grafik tersebut akan menjadi tugas di layanan Dataflow. Anda dapat melihat tugas, grafik eksekusi, status, dan informasi log menggunakan antarmuka pemantauan Dataflow.
Java
Layanan Dataflow mengirim respons ke komputer tempat Anda menjalankan
program Dataflow. Respons ini dienkapsulasi dalam objek
DataflowPipelineJob, yang berisi jobId tugas Dataflow Anda.
Gunakan jobId untuk memantau, melacak, dan memecahkan masalah tugas Anda menggunakan
Antarmuka pemantauan Dataflow
dan Antarmuka command-line Dataflow.
Untuk mengetahui informasi selengkapnya, lihat
referensi API untuk DataflowPipelineJob.
Python
Layanan Dataflow mengirim respons ke komputer tempat Anda menjalankan
program Dataflow. Respons ini dienkapsulasi dalam objek
DataflowPipelineResult, yang berisi job_id tugas Dataflow Anda.
Gunakan job_id untuk memantau, melacak, dan memecahkan masalah tugas Anda
dengan menggunakan
Antarmuka pemantauan Dataflow
dan
Antarmuka command line Dataflow.
Go
Layanan Dataflow mengirim respons ke komputer tempat Anda menjalankan
program Dataflow. Respons ini dienkapsulasi dalam objek
dataflowPipelineResult, yang berisi jobID tugas Dataflow Anda.
Gunakan jobID untuk memantau, melacak, dan memecahkan masalah tugas Anda
dengan menggunakan
Antarmuka pemantauan Dataflow
dan
Antarmuka command line Dataflow.
Konstruksi grafik juga terjadi saat Anda menjalankan pipeline secara lokal, tetapi grafik tidak diterjemahkan ke JSON atau dikirim ke layanan. Sebagai gantinya, grafik dijalankan secara lokal di mesin yang sama tempat Anda meluncurkan program Dataflow. Untuk mengetahui informasi selengkapnya, lihat Mengonfigurasi PipelineOptions untuk eksekusi lokal.
Penanganan error dan pengecualian
Pipeline Anda mungkin memunculkan pengecualian saat memproses data. Beberapa error ini bersifat sementara, seperti kesulitan sementara dalam mengakses layanan eksternal. Error lainnya bersifat permanen, seperti error yang disebabkan oleh data input yang rusak atau tidak dapat diuraikan, atau pointer null selama komputasi.
Dataflow memproses elemen dalam paket arbitrer, dan mencoba kembali paket lengkap saat error terjadi untuk elemen apa pun dalam paket tersebut. Saat berjalan dalam mode batch, paket yang menyertakan item yang gagal akan dicoba lagi sebanyak empat kali. Pipeline akan gagal sepenuhnya jika satu paket gagal empat kali. Saat berjalan dalam mode streaming, bundle yang menyertakan item yang gagal akan dicoba lagi tanpa batas waktu, yang dapat menyebabkan pipeline Anda terhenti secara permanen.
Saat memproses dalam mode batch, Anda mungkin melihat sejumlah besar kegagalan individual sebelum tugas pipeline gagal sepenuhnya, yang terjadi saat setiap paket tertentu gagal setelah empat kali percobaan ulang. Misalnya, jika pipeline Anda mencoba memproses 100 paket, Dataflow dapat menghasilkan beberapa ratus kegagalan individual hingga satu paket mencapai kondisi empat kegagalan untuk keluar.
Error pekerja saat startup, seperti kegagalan menginstal paket di pekerja, bersifat sementara. Skenario ini akan menyebabkan percobaan ulang tanpa batas, dan dapat menyebabkan pipeline Anda terhenti secara permanen.
Paralelisasi dan distribusi
Layanan Dataflow secara otomatis memparalelkan dan mendistribusikan logika pemrosesan di pipeline Anda ke pekerja yang Anda tetapkan untuk menjalankan tugas Anda. Dataflow menggunakan abstraksi dalam
model pemrograman untuk merepresentasikan
fungsi pemrosesan paralel. Misalnya, transformasi ParDo dalam pipeline menyebabkan Dataflow secara otomatis mendistribusikan kode pemrosesan, yang diwakili oleh objek DoFn, ke beberapa pekerja untuk dijalankan secara paralel.
Ada dua jenis paralelisme tugas:
Paralelisme horizontal terjadi saat data pipeline dibagi dan diproses di beberapa pekerja secara bersamaan. Lingkungan runtime Dataflow didukung oleh kumpulan pekerja terdistribusi. Pipeline memiliki paralelisme yang lebih tinggi jika kumpulan berisi lebih banyak pekerja, tetapi konfigurasi tersebut juga memiliki biaya yang lebih tinggi. Secara teoretis, paralelisme horizontal tidak memiliki batas atas. Namun, Dataflow membatasi kumpulan pekerja hingga 4.000 pekerja untuk mengoptimalkan penggunaan resource di seluruh armada.
Paralelisme vertikal terjadi saat data pipeline dibagi dan diproses oleh beberapa core CPU pada worker yang sama. Setiap pekerja didukung oleh VM Compute Engine. VM dapat menjalankan beberapa proses untuk memaksimalkan semua core CPU-nya. VM dengan lebih banyak core memiliki potensi paralelisme vertikal yang lebih tinggi, tetapi konfigurasi ini menghasilkan biaya yang lebih tinggi. Jumlah core yang lebih tinggi sering kali menghasilkan peningkatan penggunaan memori, sehingga jumlah core biasanya diskalakan bersama dengan ukuran memori. Mengingat batas fisik arsitektur komputer, batas atas paralelisme vertikal jauh lebih rendah daripada batas atas paralelisme horizontal.
Paralelisme terkelola
Secara default, Dataflow mengelola paralelisme tugas secara otomatis. Dataflow memantau statistik runtime untuk tugas, seperti penggunaan CPU dan memori, untuk menentukan cara menskalakan tugas. Bergantung pada setelan tugas, Dataflow dapat menskalakan tugas secara horizontal, yang disebut sebagai Penskalaan Otomatis Horizontal, atau secara vertikal, yang disebut sebagai Penskalaan vertikal. Penskalaan otomatis untuk paralelisme mengoptimalkan biaya tugas dan performa tugas.
Untuk meningkatkan performa tugas, Dataflow juga mengoptimalkan pipeline secara internal. Pengoptimalan umum adalah pengoptimalan fusion dan pengoptimalan kombinasi. Dengan menggabungkan langkah-langkah pipeline, Dataflow menghilangkan biaya yang tidak perlu terkait dengan mengoordinasikan langkah-langkah dalam sistem terdistribusi dan menjalankan setiap langkah satu per satu.
Faktor yang memengaruhi paralelisme
Faktor-faktor berikut memengaruhi seberapa baik fungsi paralelisme dalam tugas Dataflow.
Sumber input
Jika sumber input tidak mengizinkan paralelisme, langkah penyerapan sumber input dapat menjadi hambatan dalam tugas Dataflow. Misalnya, saat Anda memproses data dari satu file teks terkompresi, Dataflow tidak dapat memparalelkan data input. Karena sebagian besar format kompresi tidak dapat dibagi secara arbitrer menjadi shard selama penyerapan, Dataflow perlu membaca data secara berurutan dari awal file. Throughput keseluruhan pipeline diperlambat oleh bagian pipeline yang tidak paralel. Solusi untuk masalah ini adalah menggunakan sumber input yang lebih skalabel.
Dalam beberapa kasus, penggabungan langkah juga mengurangi paralelisme. Jika sumber input tidak mengizinkan paralelisme, dan Dataflow menggabungkan langkah penyerapan data dengan langkah-langkah berikutnya serta menetapkan langkah gabungan ini ke satu thread, seluruh pipeline mungkin berjalan lebih lambat.
Untuk menghindari skenario ini, masukkan langkah Redistribute setelah langkah penyerapan sumber input. Untuk mengetahui informasi selengkapnya, lihat bagian
Mencegah penggabungan dalam dokumen ini.
Penyebaran dan bentuk data default
Fanout default dari satu langkah transformasi dapat menjadi
penghambat dan membatasi paralelisme. Misalnya, transformasi "fan-out tinggi" ParDo dapat menyebabkan
penggabungan membatasi kemampuan Dataflow untuk mengoptimalkan penggunaan pekerja. Dalam
operasi tersebut, Anda mungkin memiliki koleksi input dengan elemen yang relatif sedikit, tetapi ParDo menghasilkan output dengan elemen yang ratusan atau ribuan kali lebih banyak, diikuti dengan ParDo lainnya. Jika layanan Dataflow menggabungkan operasi ParDo ini, paralelisme dalam langkah ini dibatasi hingga paling banyak jumlah item dalam koleksi input, meskipun PCollection perantara berisi lebih banyak elemen.
Untuk mengetahui kemungkinan solusi, lihat bagian Mencegah penggabungan dalam dokumen ini.
Bentuk data
Bentuk data, baik data input maupun data perantara, dapat membatasi paralelisme.
Misalnya, saat langkah GroupByKey pada kunci alami, seperti kota,
diikuti dengan langkah map atau Combine, Dataflow akan menggabungkan kedua
langkah tersebut. Jika ruang kunci kecil, misalnya, lima kota, dan satu kunci sangat
populer, misalnya, kota besar, sebagian besar item dalam output GroupByKey
didistribusikan ke satu proses. Proses ini menjadi hambatan dan memperlambat tugas.
Dalam contoh ini, Anda dapat mendistribusikan ulang hasil langkah GroupByKey ke dalam
ruang kunci buatan yang lebih besar, bukan menggunakan kunci alami. Sisipkan langkah Redistribute
antara langkah GroupByKey dan langkah map atau Combine. Pada langkah Redistribute, buat ruang kunci buatan, misalnya dengan
menggunakan fungsi hash, untuk mengatasi paralelisme terbatas yang disebabkan oleh bentuk
data.
Untuk mengetahui informasi selengkapnya, lihat bagian Mencegah penggabungan dalam dokumen ini.
Sink output
Sink adalah transformasi yang menulis ke sistem penyimpanan data eksternal, seperti
file atau database. Dalam praktiknya, sink dimodelkan dan diimplementasikan sebagai objek DoFn standar dan digunakan untuk mewujudkan PCollection ke sistem eksternal.
Dalam hal ini, PCollection berisi hasil akhir pipeline. Thread yang
memanggil API sink dapat berjalan secara paralel untuk menulis data ke sistem eksternal. Secara
default, tidak ada koordinasi antar-thread. Tanpa lapisan
perantara untuk mem-buffer permintaan penulisan dan alur kontrol, sistem eksternal dapat
kelebihan beban dan mengurangi throughput penulisan. Menskalakan sumber daya dengan menambahkan lebih banyak
paralelisme dapat memperlambat pipeline lebih lanjut.
Solusi untuk masalah ini adalah mengurangi paralelisme pada langkah penulisan.
Anda dapat menambahkan langkah GroupByKey tepat sebelum langkah penulisan. Grup langkah GroupByKey
mengeluarkan data ke dalam kumpulan batch yang lebih kecil untuk mengurangi total panggilan RPC
dan koneksi ke sistem eksternal. Misalnya, gunakan GroupByKey untuk membuat
ruang hash 50 dari 1 juta titik data.
Kelemahan dari pendekatan ini adalah diperkenalkannya batas hard code untuk paralelisme. Opsi lainnya adalah menerapkan penundaan eksponensial di sink saat menulis data. Opsi ini dapat memberikan throttling klien minimum.
Memantau paralelisme
Untuk memantau paralelisme, Anda dapat menggunakan konsol Google Cloud untuk melihat semua tugas yang lambat yang terdeteksi. Untuk mengetahui informasi selengkapnya, lihat Memecahkan masalah tugas batch yang tertunda dan Memecahkan masalah tugas streaming yang tertunda.
Pengoptimalan gabungan
Setelah bentuk JSON dari grafik eksekusi pipeline Anda divalidasi, layanan Dataflow dapat mengubah grafik untuk melakukan pengoptimalan.
Pengoptimalan dapat mencakup penggabungan beberapa langkah atau transformasi dalam grafik eksekusi pipeline menjadi satu langkah. Penggabungan langkah-langkah mencegah layanan Dataflow perlu mewujudkan setiap PCollection perantara dalam pipeline Anda, yang dapat menimbulkan biaya besar dalam hal overhead pemrosesan dan memori.
Meskipun semua transformasi yang Anda tentukan dalam konstruksi pipeline dieksekusi di layanan, untuk memastikan eksekusi pipeline yang paling efisien, transformasi dapat dieksekusi dalam urutan yang berbeda atau sebagai bagian dari transformasi gabungan yang lebih besar. Layanan Dataflow mematuhi dependensi data antara langkah-langkah dalam grafik eksekusi, tetapi langkah-langkah dapat dieksekusi dalam urutan apa pun.
Contoh penggabungan
Diagram berikut menunjukkan cara mengoptimalkan dan menggabungkan grafik eksekusi dari contoh WordCount yang disertakan dengan Apache Beam SDK untuk Java oleh layanan Dataflow agar eksekusinya efisien:
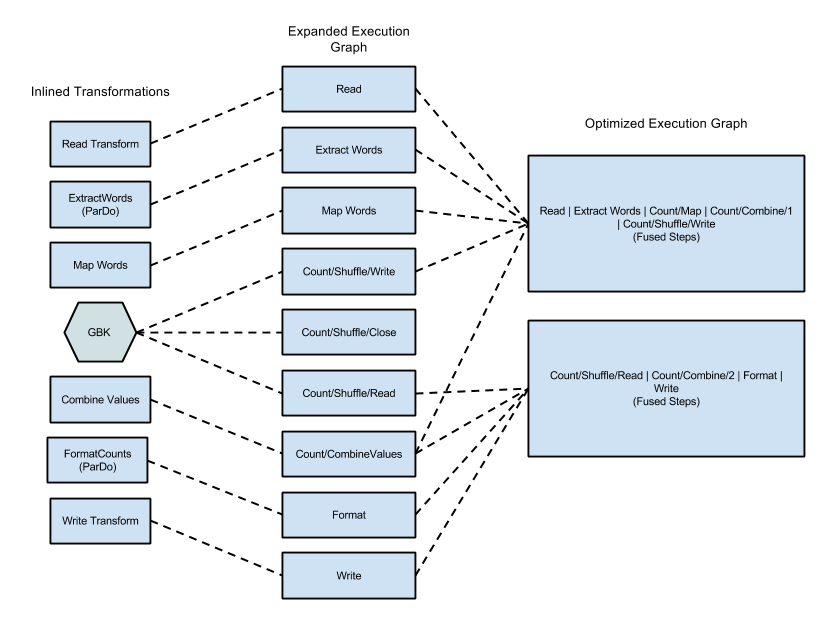
Gambar 2: Grafik Eksekusi yang Dioptimalkan untuk Contoh WordCount
Mencegah penggabungan
Dalam beberapa kasus, Dataflow mungkin salah menebak cara optimal untuk menggabungkan operasi dalam pipeline, yang dapat membatasi kemampuan Dataflow untuk menggunakan semua pekerja yang tersedia. Dalam kasus seperti itu,
Anda dapat memberikan petunjuk kepada Dataflow untuk mendistribusikan ulang data, dengan menggunakan
transformasi Redistribute.
Untuk menambahkan transformasi Redistribute, panggil salah satu metode berikut:
Redistribute.arbitrarily: Menunjukkan bahwa data kemungkinan tidak seimbang. Dataflow memilih algoritma terbaik untuk mendistribusikan ulang data.Redistribute.byKey: Menunjukkan bahwaPCollectionpasangan nilai kunci kemungkinan tidak seimbang dan harus didistribusikan ulang berdasarkan kunci. Biasanya, Dataflow menempatkan semua elemen dari satu kunci yang sama pada thread pekerja yang sama. Namun, penempatan bersama kunci tidak dijamin, dan elemen diproses secara independen.
Jika pipeline Anda berisi transformasi Redistribute, Dataflow biasanya mencegah penggabungan langkah-langkah sebelum dan setelah transformasi Redistribute, serta mengacak data sehingga langkah-langkah di hilir transformasi Redistribute memiliki paralelisme yang lebih optimal.
Penggabungan monitor
Anda dapat mengakses grafik yang dioptimalkan dan tahap gabungan di konsol Google Cloud , menggunakan gcloud CLI, atau menggunakan API.
Konsol
Untuk melihat tahap dan langkah yang digabungkan dalam grafik di konsol, pada tab Detail eksekusi untuk tugas Dataflow, buka tampilan grafik Alur kerja tahap.
Untuk melihat langkah-langkah komponen yang digabungkan untuk suatu tahap, klik tahap yang digabungkan dalam grafik. Di panel Info tahap, baris Langkah komponen menampilkan tahap gabungan. Terkadang, sebagian dari satu transformasi komposit digabungkan ke dalam beberapa tahap.
gcloud
Untuk mengakses grafik yang dioptimalkan dan tahap gabungan menggunakan
gcloud CLI, jalankan perintah gcloud berikut:
gcloud dataflow jobs describe --full JOB_ID --format json
Ganti JOB_ID dengan ID tugas Dataflow Anda.
Untuk mengekstrak bagian yang relevan, teruskan output perintah gcloud ke jq:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Untuk melihat deskripsi tahap gabungan dalam file respons output, dalam array
ComponentTransform, lihat objek
ExecutionStageSummary.
API
Untuk mengakses grafik yang dioptimalkan dan tahap gabungan menggunakan API, panggil
project.locations.jobs.get.
Untuk melihat deskripsi tahap gabungan dalam file respons output, dalam array
ComponentTransform, lihat objek
ExecutionStageSummary.
Pengoptimalan gabungan
Operasi agregasi adalah konsep penting dalam pemrosesan data skala besar.
Agregasi menggabungkan data yang secara konseptual sangat berbeda, sehingga sangat berguna untuk korelasi. Model pemrograman Dataflow merepresentasikan operasi agregasi sebagai transformasi GroupByKey, CoGroupByKey, dan
Combine.
Operasi agregasi Dataflow menggabungkan data di seluruh set data, termasuk data yang mungkin tersebar di beberapa pekerja. Selama operasi penggabungan tersebut, sering kali lebih efisien untuk menggabungkan sebanyak mungkin data secara lokal sebelum menggabungkan data di seluruh instance. Saat Anda menerapkan transformasi penggabungan GroupByKey atau lainnya, layanan Dataflow akan otomatis melakukan penggabungan parsial secara lokal sebelum operasi pengelompokan utama.
Saat melakukan penggabungan sebagian atau multi-level, layanan Dataflow membuat keputusan yang berbeda berdasarkan apakah pipeline Anda bekerja dengan data batch atau streaming. Untuk data yang terikat, layanan mengutamakan efisiensi dan akan melakukan penggabungan lokal sebanyak mungkin. Untuk data tanpa batas, layanan lebih memilih latensi yang lebih rendah, dan mungkin tidak melakukan penggabungan parsial, karena dapat meningkatkan latensi.