Questa pagina fornisce una panoramica del ciclo di vita della pipeline, dal codice della pipeline a un job Dataflow.
Questa pagina spiega i seguenti concetti:
- Che cos'è un grafico di esecuzione e come una pipeline Apache Beam diventa un job Dataflow
- Come Dataflow gestisce gli errori
- In che modo Dataflow parallelizza e distribuisce automaticamente la logica di elaborazione nella pipeline ai worker che eseguono il job
- Ottimizzazioni dei job che Dataflow potrebbe apportare
Grafico di esecuzione
Quando esegui la pipeline Dataflow, Dataflow
crea un grafico di esecuzione dal codice che costruisce l'oggetto Pipeline,
inclusi tutti i trasformatori e le relative funzioni di elaborazione, ad esempio
gli oggetti DoFn. Questo è il grafico di esecuzione della pipeline e la fase è chiamata
tempo di costruzione del grafico.
Durante la costruzione del grafico, Apache Beam esegue localmente il codice dal punto di ingresso principale del codice della pipeline, arrestandosi alle chiamate a un passaggio di origine, sink o trasformazione e trasformando queste chiamate in nodi del grafico.
Di conseguenza, un frammento di codice nel punto di ingresso di una pipeline (metodo main
Java e Go o livello superiore di uno script Python) viene eseguito localmente sulla macchina che
esegue la pipeline. Lo stesso codice dichiarato in un metodo di un oggetto DoFn
viene eseguito nei worker Dataflow.
Ad esempio, l'esempio WordCount incluso negli SDK Apache Beam contiene una serie di trasformazioni per leggere, estrarre, contare, formattare e scrivere le singole parole in una raccolta di testo, insieme a un conteggio delle occorrenze per ogni parola. Il seguente diagramma mostra come le trasformazioni nella pipeline WordCount vengono espanse in un grafico di esecuzione:
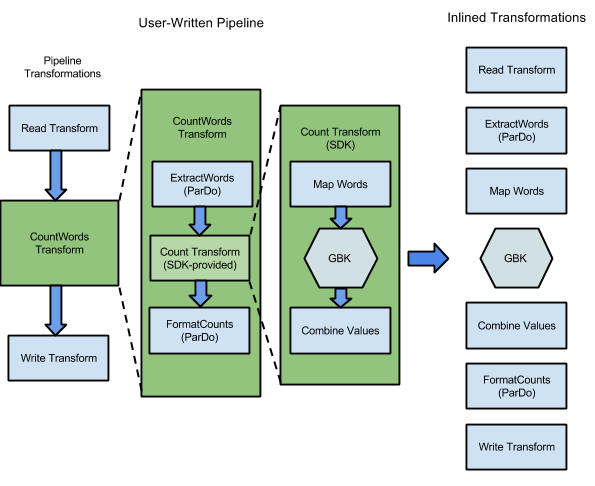
Figura 1: Grafico di esecuzione dell'esempio WordCount
Il grafico di esecuzione spesso differisce dall'ordine in cui hai specificato le trasformazioni durante la creazione della pipeline. Questa differenza esiste perché il servizio Dataflow esegue varie ottimizzazioni e fusioni sul grafico di esecuzione prima di essere eseguito su risorse cloud gestite. Il servizio Dataflow rispetta le dipendenze dei dati durante l'esecuzione della pipeline. Tuttavia, i passaggi senza dipendenze di dati tra loro potrebbero essere eseguiti in qualsiasi ordine.
Per visualizzare il grafico di esecuzione non ottimizzato generato da Dataflow per la tua pipeline, seleziona il job nell'interfaccia di monitoraggio di Dataflow. Per ulteriori informazioni sulla visualizzazione dei job, consulta Utilizzare l'interfaccia di monitoraggio di Dataflow.
Durante la costruzione del grafico, Apache Beam verifica che tutte le risorse a cui fa riferimento la pipeline, come i bucket Cloud Storage, le tabelle BigQuery e gli argomenti o le sottoscrizioni Pub/Sub, esistano effettivamente e siano accessibili. La convalida viene eseguita tramite chiamate API standard ai rispettivi servizi, pertanto è fondamentale che l'account utente utilizzato per eseguire una pipeline disponga della connettività corretta ai servizi necessari e sia autorizzato a chiamare le API dei servizi. Prima di inviare la pipeline al servizio Dataflow, Apache Beam verifica anche la presenza di altri errori e si assicura che il grafico della pipeline non contenga operazioni illegali.
Il grafico di esecuzione viene quindi tradotto in formato JSON e il grafico di esecuzione JSON viene trasmesso all'endpoint del servizio Dataflow.
Il servizio Dataflow convalida quindi il grafico di esecuzione JSON. Quando il grafico viene convalidato, diventa un job nel servizio Dataflow. Puoi visualizzare il job, il relativo grafico di esecuzione, lo stato e le informazioni di log utilizzando l'interfaccia di monitoraggio di Dataflow.
Java
Il servizio Dataflow invia una risposta alla macchina su cui esegui
il programma Dataflow. Questa risposta è incapsulata nell'oggetto
DataflowPipelineJob, che contiene jobId del tuo job Dataflow.
Utilizza jobId per monitorare, monitorare e risolvere i problemi del job utilizzando l'interfaccia di monitoraggio di Dataflow e l'interfaccia a riga di comando di Dataflow.
Per ulteriori informazioni, consulta il
riferimento API per DataflowPipelineJob.
Python
Il servizio Dataflow invia una risposta alla macchina su cui esegui
il programma Dataflow. Questa risposta è incapsulata nell'oggetto
DataflowPipelineResult, che contiene job_id del tuo job Dataflow.
Utilizza job_id per monitorare, tenere traccia e risolvere i problemi relativi al tuo job
utilizzando l'interfaccia di monitoraggio di Dataflow e l'interfaccia a riga di comando di Dataflow.
Vai
Il servizio Dataflow invia una risposta alla macchina su cui esegui
il programma Dataflow. Questa risposta è incapsulata nell'oggetto
dataflowPipelineResult, che contiene jobID del tuo job Dataflow.
Utilizza jobID per monitorare, tenere traccia e risolvere i problemi relativi al tuo job
utilizzando l'interfaccia di monitoraggio di Dataflow e l'interfaccia a riga di comando di Dataflow.
La costruzione del grafico avviene anche quando esegui la pipeline localmente, ma il grafico non viene convertito in JSON o trasmesso al servizio. Il grafico viene invece eseguito localmente sulla stessa macchina in cui hai avviato il programma Dataflow. Per ulteriori informazioni, consulta Configurazione di PipelineOptions per l'esecuzione locale.
Gestione di errori ed eccezioni
La pipeline potrebbe generare eccezioni durante l'elaborazione dei dati. Alcuni di questi errori sono temporanei, ad esempio la difficoltà temporanea di accedere a un servizio esterno. Altri errori sono permanenti, ad esempio quelli causati da dati di input danneggiati o non analizzabili o da puntatori nulli durante il calcolo.
Dataflow elabora gli elementi in bundle arbitrari e riprova a elaborare l'intero bundle quando viene generato un errore per qualsiasi elemento del bundle. Quando viene eseguita in modalità batch, i bundle che includono un elemento non riuscito vengono ritentati quattro volte. La pipeline non viene eseguita quando un singolo bundle non è stato eseguito quattro volte. Quando viene eseguito in modalità streaming, un bundle che include un elemento non riuscito viene ritentato indefinitamente, il che potrebbe causare l'arresto permanente della pipeline.
Durante l'elaborazione in modalità batch, potresti notare un numero elevato di errori individuali prima che un job della pipeline non riesca completamente, il che si verifica quando un determinato bundle non riesce dopo quattro tentativi. Ad esempio, se la tua pipeline tenta di elaborare 100 bundle, Dataflow potrebbe generare diverse centinaia di errori individuali finché un singolo bundle non raggiunge la condizione di quattro errori per l'uscita.
Gli errori del worker di avvio, come l'impossibilità di installare pacchetti sui worker, sono temporanei. Questo scenario comporta tentativi di ripetizione indefiniti e potrebbe causare l'arresto permanente della pipeline.
Parallelizzazione e distribuzione
Il servizio Dataflow parallelizza e distribuisce automaticamente la logica di elaborazione nella pipeline ai worker che assegni per eseguire il job. Dataflow utilizza le astrazioni nel
modello di programmazione per rappresentare
le funzioni di elaborazione parallela. Ad esempio, le trasformazioni ParDo in una pipeline
fanno sì che Dataflow distribuisca automaticamente il codice di elaborazione,
rappresentato da oggetti DoFn, a più worker da eseguire in parallelo.
Esistono due tipi di parallelismo dei job:
Il parallelismo orizzontale si verifica quando i dati della pipeline vengono suddivisi ed elaborati su più worker contemporaneamente. L'ambiente di runtime di Dataflow è basato su un pool di worker distribuiti. Una pipeline ha un potenziale parallelismo più elevato quando il pool contiene più worker, ma questa configurazione ha anche un costo maggiore. In teoria, il parallelismo orizzontale non ha un limite superiore. Tuttavia, Dataflow limita il pool di worker a 4000 worker per ottimizzare l'utilizzo delle risorse a livello di flotta.
Il parallelismo verticale si verifica quando i dati della pipeline vengono suddivisi ed elaborati da più core CPU sullo stesso worker. Ogni worker è alimentato da una VM Compute Engine. Una VM può eseguire più processi per saturare tutti i core della CPU. Una VM con più core ha un potenziale parallelismo verticale maggiore, ma questa configurazione comporta costi più elevati. Un numero maggiore di core spesso comporta un aumento dell'utilizzo della memoria, quindi il numero di core viene in genere scalato insieme alla dimensione della memoria. Dato il limite fisico delle architetture dei computer, il limite superiore del parallelismo verticale è molto inferiore al limite superiore del parallelismo orizzontale.
Parallelismo gestito
Per impostazione predefinita, Dataflow gestisce automaticamente il parallelismo dei job. Dataflow monitora le statistiche di runtime del job, come l'utilizzo di CPU e memoria, per determinare come scalare il job. A seconda delle impostazioni del job, Dataflow può scalare i job orizzontalmente, operazione denominata scalabilità automatica orizzontale, o verticalmente, operazione denominata scalabilità verticale. La scalabilità automatica per il parallelismo ottimizza il costo e il rendimento del job.
Per migliorare le prestazioni dei job, Dataflow ottimizza anche le pipeline internamente. Le ottimizzazioni tipiche sono l'ottimizzazione della fusione e l'ottimizzazione della combinazione. Unendo i passaggi della pipeline, Dataflow elimina i costi non necessari associati al coordinamento dei passaggi in un sistema distribuito e all'esecuzione separata di ogni singolo passaggio.
Fattori che influiscono sul parallelismo
I seguenti fattori influiscono sul funzionamento del parallelismo nei job Dataflow.
Origine di input
Quando un'origine di input non consente il parallelismo, il passaggio di importazione dell'origine di input può diventare un collo di bottiglia in un job Dataflow. Ad esempio, quando inserisci dati da un singolo file di testo compresso, Dataflow non può parallelizzare i dati di input. Poiché la maggior parte dei formati di compressione non può essere suddivisa arbitrariamente in shard durante l'importazione, Dataflow deve leggere i dati in sequenza dall'inizio del file. Il throughput complessivo della pipeline viene rallentato dalla parte non parallela della pipeline. La soluzione a questo problema è utilizzare una fonte di input più scalabile.
In alcuni casi, la fusione dei passaggi riduce anche il parallelismo. Quando l'origine di input non consente il parallelismo, se Dataflow unisce il passaggioimportazione datii con i passaggi successivi e assegna questo passaggio unito a un singolo thread, l'intera pipeline potrebbe essere eseguita più lentamente.
Per evitare questo scenario, inserisci un passaggio Redistribute dopo il passaggio di importazione dell'origine di input. Per saperne di più, consulta la sezione
Evitare la fusione di questo documento.
Fanout e forma dei dati predefiniti
Il fanout predefinito di un singolo passaggio di trasformazione può diventare un
collo di bottiglia e limitare il parallelismo. Ad esempio, la trasformazione "high fan-out" ParDo può causare
la limitazione della capacità di Dataflow di ottimizzare l'utilizzo dei worker. In
un'operazione di questo tipo, potresti avere una raccolta di input con un numero relativamente basso
di elementi, ma ParDo produce un output con centinaia o migliaia di volte
il numero di elementi, seguito da un altro ParDo. Se il servizio Dataflow unisce queste operazioni ParDo, il parallelismo in questo passaggio è limitato al massimo al numero di elementi nella raccolta di input, anche se l'PCollection intermedio contiene molti più elementi.
Per possibili soluzioni, consulta la sezione Evitare la fusione di questo documento.
Forma dei dati
La forma dei dati, che si tratti di dati di input o intermedi, può limitare il parallelismo.
Ad esempio, quando un passaggio GroupByKey su una chiave naturale, come una città,
è seguito da un passaggio map o Combine, Dataflow unisce i due
passaggi. Quando lo spazio delle chiavi è piccolo, ad esempio cinque città, e una chiave è molto
frequente, ad esempio una grande città, la maggior parte degli elementi nell'output del passaggio GroupByKey
viene distribuita a un processo. Questo processo diventa un collo di bottiglia e rallenta
il job.
In questo esempio, puoi ridistribuire i risultati del passaggio GroupByKey in uno spazio chiave artificiale più grande anziché utilizzare le chiavi naturali. Inserisci un passaggio
Redistribute tra il passaggio GroupByKey e il passaggio map o Combine. Nel passaggio Redistribute, crea lo spazio delle chiavi artificiali, ad esempio utilizzando una funzione hash, per superare il parallelismo limitato causato dalla forma dei dati.
Per saperne di più, consulta la sezione Evitare la fusione di questo documento.
Sink di output
Un sink è una trasformazione che scrive in un sistema di archiviazione dati esterno, ad esempio
un file o un database. In pratica, i sink vengono modellati e implementati come oggetti DoFn standard e vengono utilizzati per materializzare un PCollection in sistemi esterni.
In questo caso, PCollection contiene i risultati finali della pipeline. I thread che
chiamano le API sink possono essere eseguiti in parallelo per scrivere dati nei sistemi esterni. Per
impostazione predefinita, non si verifica alcun coordinamento tra i thread. Senza un livello intermedio
per memorizzare nel buffer le richieste di scrittura e controllare il flusso, il sistema esterno può
sovraccaricarsi e ridurre la velocità effettiva di scrittura. Aumentare le risorse aggiungendo
più parallelismo potrebbe rallentare ulteriormente la pipeline.
La soluzione a questo problema è ridurre il parallelismo nel passaggio di scrittura.
Puoi aggiungere un passaggio GroupByKey subito prima del passaggio di scrittura. Il passaggio GroupByKey
raggruppa i dati di output in un insieme più piccolo di batch per ridurre le chiamate RPC totali
e le connessioni a sistemi esterni. Ad esempio, utilizza un GroupByKey per creare uno spazio hash di 50 punti dati su 1 milione.
Lo svantaggio di questo approccio è che introduce un limite hardcoded al parallelismo. Un'altra opzione è implementare il backoff esponenziale nel sink durante la scrittura dei dati. Questa opzione può fornire una limitazione minima del client.
Monitorare il parallelismo
Per monitorare il parallelismo, puoi utilizzare la console Google Cloud per visualizzare eventuali straggler rilevati. Per ulteriori informazioni, vedi Risolvere i problemi relativi ai job batch in ritardo e Risolvere i problemi relativi ai job di streaming in ritardo.
Ottimizzazione della fusione
Una volta convalidato il formato JSON del grafico di esecuzione della pipeline, il servizio Dataflow potrebbe modificare il grafico per eseguire ottimizzazioni.
Le ottimizzazioni possono includere la fusione di più passaggi o trasformazioni nel grafico di esecuzione della pipeline in singoli passaggi. I passaggi di fusione impediscono al servizio Dataflow di dover materializzare ogni PCollection intermedio nella pipeline, il che può essere costoso in termini di memoria e overhead di elaborazione.
Sebbene tutte le trasformazioni specificate nella costruzione della pipeline vengano eseguite sul servizio, per garantire l'esecuzione più efficiente della pipeline, le trasformazioni potrebbero essere eseguite in un ordine diverso o come parte di una trasformazione combinata più grande. Il servizio Dataflow rispetta le dipendenze dei dati tra i passaggi nel grafico di esecuzione, ma altrimenti i passaggi potrebbero essere eseguiti in qualsiasi ordine.
Esempio di fusione
Il seguente diagramma mostra come il grafico di esecuzione dell'esempio WordCount incluso nell'SDK Apache Beam per Java potrebbe essere ottimizzato e unito dal servizio Dataflow per un'esecuzione efficiente:
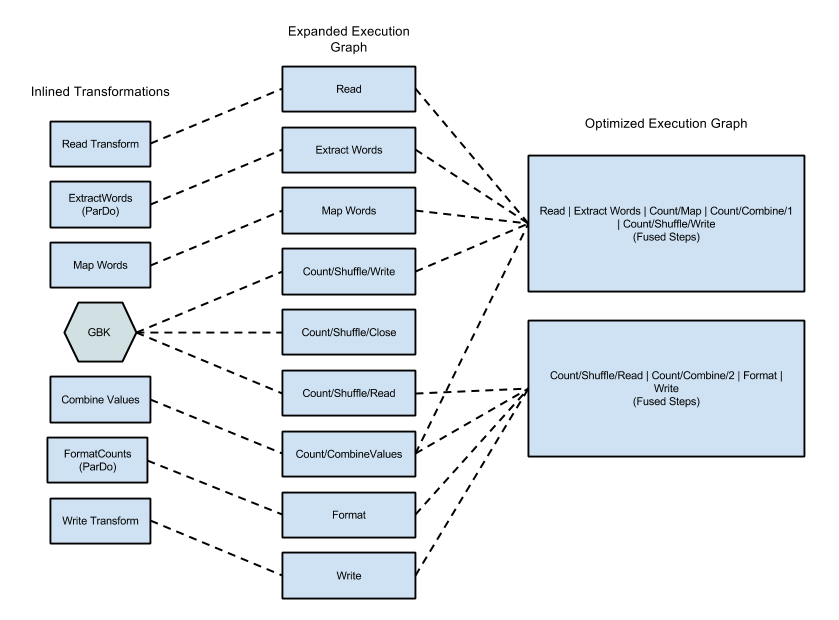
Figura 2: Esempio di WordCount Grafico esecuzione ottimizzato
Impedire la fusione
In alcuni casi, Dataflow potrebbe indovinare in modo errato il modo ottimale per unire le operazioni nella pipeline, il che può limitare la capacità di Dataflow di utilizzare tutti i worker disponibili. In questi casi,
puoi dare un suggerimento a Dataflow per ridistribuire i dati utilizzando
una trasformazione Redistribute.
Per aggiungere una trasformazione Redistribute, chiama uno dei seguenti metodi:
Redistribute.arbitrarily: indica che è probabile che i dati siano sbilanciati. Dataflow sceglie l'algoritmo migliore per ridistribuire i dati.Redistribute.byKey: indica che unaPCollectiondi coppie chiave-valore è probabilmente sbilanciata e deve essere ridistribuita in base alle chiavi. In genere, Dataflow colloca tutti gli elementi di una singola chiave nello stesso thread worker. Tuttavia, la collocazione congiunta delle chiavi non è garantita e gli elementi vengono elaborati in modo indipendente.
Se la pipeline contiene una trasformazione Redistribute, Dataflow
di solito impedisce la fusione dei passaggi prima e dopo la trasformazione Redistribute
e rimescola i dati in modo che i passaggi a valle della
trasformazione Redistribute abbiano un parallelismo più ottimale.
Monitor fusion
Puoi accedere al grafico ottimizzato e alle fasi unite nella console Google Cloud , utilizzando gcloud CLI o l'API.
Console
Per visualizzare le fasi e i passaggi uniti del grafico nella console, nella scheda Dettagli di esecuzione del job Dataflow, apri la visualizzazione Grafico del flusso di lavoro delle fasi.
Per visualizzare i passaggi del componente uniti per una fase, fai clic sulla fase unita nel grafico. Nel riquadro Informazioni sullo stage, la riga Passaggi del componente mostra gli stage uniti. A volte, alcune parti di una singola trasformazione composita vengono unite in più fasi.
gcloud
Per accedere al grafico ottimizzato e alle fasi unite utilizzando
gcloud CLI, esegui questo comando gcloud:
gcloud dataflow jobs describe --full JOB_ID --format json
Sostituisci JOB_ID con l'ID del tuo job Dataflow.
Per estrarre i bit pertinenti, reindirizza l'output del comando gcloud a jq:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Per visualizzare la descrizione delle fasi unite nel file di risposta dell'output, all'interno dell'array
ComponentTransform, consulta l'oggetto
ExecutionStageSummary.
API
Per accedere al grafico ottimizzato e alle fasi unite utilizzando l'API, chiama
project.locations.jobs.get.
Per visualizzare la descrizione delle fasi unite nel file di risposta dell'output, all'interno dell'array
ComponentTransform, consulta l'oggetto
ExecutionStageSummary.
Ottimizzazione combinata
Le operazioni di aggregazione sono un concetto importante nell'elaborazione di dati su larga scala.
L'aggregazione riunisce dati concettualmente molto distanti, rendendoli
estremamente utili per la correlazione. Il modello di programmazione Dataflow rappresenta le operazioni di aggregazione come trasformazioni GroupByKey, CoGroupByKey e
Combine.
Le operazioni di aggregazione di Dataflow combinano i dati dell'intero
set di dati, inclusi quelli che potrebbero essere distribuiti tra più worker. Durante queste operazioni di aggregazione, spesso è più efficiente combinare il maggior numero possibile di dati a livello locale prima di combinarli tra le istanze. Quando applichi una
GroupByKey o un'altra trasformazione di aggregazione, il servizio Dataflow
esegue automaticamente la combinazione parziale in locale prima dell'operazione
di raggruppamento principale.
Quando esegue la combinazione parziale o multilivello, il servizio Dataflow prende decisioni diverse a seconda che la pipeline funzioni con dati batch o in streaming. Per i dati delimitati, il servizio privilegia l'efficienza ed esegue il maggior numero possibile di combinazioni locali. Per i dati senza limiti, il servizio privilegia una latenza inferiore e potrebbe non eseguire la combinazione parziale, perché potrebbe aumentare la latenza.