이 문서에서는 진행 중인 스트리밍 작업을 업데이트하는 방법을 설명합니다. 다음과 같은 이유로 기존 Dataflow 작업을 업데이트해야 할 수 있습니다.
- 파이프라인 코드를 향상 또는 개선하려는 경우
- 파이프라인 코드에서 버그를 수정하려는 경우
- 데이터 형식의 변경을 처리하거나 데이터 소스의 버전 또는 기타 변경 사항을 설명하기 위해 파이프라인을 업데이트하려는 경우
- 모든 Dataflow 작업자의 Container-Optimized OS와 관련된 보안 취약점을 패치하려는 경우
- 다른 작업자 수를 사용하도록 스트리밍 Apache Beam 파이프라인을 확장하려는 경우.
다음 두 가지 방법으로 작업을 업데이트할 수 있습니다.
- 진행 중인 작업 업데이트: Streaming Engine을 사용하는 스트리밍 작업의 경우 작업을 중지하거나 작업 ID를 변경하지 않고도
min-num-workers및max-num-workers작업 옵션을 업데이트할 수 있습니다. - 교체 작업: 업데이트된 파이프라인 코드를 실행하거나 진행 중인 작업 업데이트가 지원하지 않는 작업 옵션을 업데이트하려면 기존 작업을 교체하는 새 작업을 실행합니다. 교체 작업이 유효한지 확인하려면 새 작업을 시작하기 전에 작업 그래프를 검증합니다.
작업을 업데이트하면 Dataflow 서비스는 현재 실행 중인 작업과 잠재적인 교체 작업 사이의 호환성 검사를 수행합니다. 호환성 검사를 통해 중간 상태 정보 및 버퍼링된 데이터와 같은 항목을 이전 작업에서 교체 작업으로 전송할 수 있는지 확인할 수 있습니다.
Apache Beam SDK의 기본 제공되는 로깅 인프라를 사용하여 작업을 업데이트할 때도 정보를 로깅할 수 있습니다. 자세한 내용은 파이프라인 로그 작업을 참조하세요.
파이프라인 코드 문제를 식별하려면 DEBUG 로깅 수준을 사용합니다.
- 기본 템플릿을 사용하는 스트리밍 작업을 업데이트하는 방법은 커스텀 템플릿 스트리밍 작업 업데이트를 참조하세요.
- Flex 템플릿을 사용하는 스트리밍 작업을 업데이트하는 방법은 이 페이지의 gcloud CLI 안내를 따르거나 Flex 템플릿 작업 업데이트를 참조하세요.
진행 중인 작업 옵션 업데이트
Streaming Engine을 사용하는 스트리밍 작업의 경우 작업을 중지하거나 작업 ID를 변경하지 않고도 다음 작업 옵션을 업데이트할 수 있습니다.
min-num-workers: 최소 Compute Engine 인스턴스 수입니다.max-num-workers: 최대 Compute Engine 인스턴스 수입니다.worker-utilization-hint: [0.1, 0.9] 범위 이내 대상 CPU 사용률입니다.
다른 작업 업데이트의 경우 현재 작업을 업데이트된 작업으로 교체해야 합니다. 자세한 내용은 교체 작업 실행을 참조하세요.
진행 중인 업데이트 수행
진행 중인 작업 옵션 업데이트를 수행하려면 다음 단계를 수행합니다.
gcloud
gcloud dataflow jobs update-options 명령어를 사용합니다.
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
다음을 바꿉니다.
- REGION: 작업 리전 ID
- MINIMUM_WORKERS: 최소 Compute Engine 인스턴스 수
- MAXIMUM_WORKERS: 최대 Compute Engine 인스턴스 수
- TARGET_UTILIZATION: [0.1, 0.9] 범위 이내 값
- JOB_ID: 업데이트할 작업의 ID
--min-num-workers, --max-num-workers 및 worker-utilization-hint를 개별적으로 업데이트할 수도 있습니다.
REST
projects.locations.jobs.update 메서드를 사용합니다.
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
다음을 바꿉니다.
- MASK: 다음과 같이 업데이트할 쉼표로 구분된 파라미터 목록입니다.
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: Dataflow 작업의 Google Cloud 프로젝트 ID
- REGION: 작업 리전 ID
- JOB_ID: 업데이트할 작업의 ID
- MINIMUM_WORKERS: 최소 Compute Engine 인스턴스 수
- MAXIMUM_WORKERS: 최대 Compute Engine 인스턴스 수
- TARGET_UTILIZATION: [0.1, 0.9] 범위 이내 값
min_num_workers, max_num_workers 및 worker_utilization_hint를 개별적으로 업데이트할 수도 있습니다.
updateMask 쿼리 매개변수에서 업데이트할 매개변수를 지정하고 요청 본문의 runtimeUpdatableParams 필드에 업데이트된 값을 포함합니다. 다음 예시는 min_num_workers를 업데이트합니다.
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
진행 중인 업데이트의 조건을 충족하려면 작업이 실행 중 상태여야 합니다. 작업이 시작되지 않았거나 이미 취소된 경우 오류가 발생합니다. 마찬가지로 대체 작업을 시작하는 경우에는 새 작업에 진행 중인 업데이트를 보내기 전에 작업 실행이 시작되기를 기다려야 합니다.
업데이트 요청을 제출한 후에는 요청이 완료될 때까지 기다린 후에 다른 업데이트를 전송하는 것이 좋습니다. 작업 로그에서 요청이 완료되는 시점을 확인하세요.
교체 작업 유효성 검사
교체 작업이 유효한지 확인하려면 새 작업이 시작되기 전에 작업 그래프의 유효성을 검사합니다. Dataflow에서 작업 그래프는 파이프라인을 그래픽으로 표현한 것입니다. 작업 그래프의 유효성을 검사하면 업데이트 후 파이프라인에 오류가 발생하거나 파이프라인 장애가 발생할 위험을 줄일 수 있습니다. 또한 작업에 다운타임이 발생하지 않도록 원래 작업을 중지할 필요 없이 업데이트 유효성을 검사할 수 있습니다.
작업 그래프의 유효성을 검사하려면 교체 작업을 시작하는 단계를 따르세요. 업데이트 명령어에 graph_validate_only Dataflow 서비스 옵션을 포함합니다.
자바
--update옵션을 전달합니다.PipelineOptions의--jobName옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.--dataflowServiceOptions=graph_validate_only서비스 옵션을 포함합니다.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transformNameMapping옵션을 사용하여 전달해야 합니다. - 이후 버전의 Apache Beam SDK를 사용하는 대체 작업을 제출하는 경우
--updateCompatibilityVersion을 원래 작업에서 사용된 Apache Beam SDK 버전으로 설정합니다.
Python
--update옵션을 전달합니다.PipelineOptions의--job_name옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.--dataflow_service_options=graph_validate_only서비스 옵션을 포함합니다.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform_name_mapping옵션을 사용하여 전달해야 합니다. - 이후 버전의 Apache Beam SDK를 사용하는 대체 작업을 제출하는 경우
--updateCompatibilityVersion을 원래 작업에서 사용된 Apache Beam SDK 버전으로 설정합니다.
Go
--update옵션을 전달합니다.--job_name옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.--dataflow_service_options=graph_validate_only서비스 옵션을 포함합니다.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform_name_mapping옵션을 사용하여 전달해야 합니다.
gcloud
Flex 템플릿 작업의 작업 그래프를 검증하려면 additional-experiments 옵션과 함께 gcloud dataflow flex-template run 명령어를 사용합니다.
--update옵션을 전달합니다.- JOB_NAME을(를) 업데이트할 작업과 동일한 이름으로 설정합니다.
--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.--additional-experiments=graph_validate_only옵션을 포함합니다.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform-name-mappings옵션을 사용하여 전달해야 합니다.
예를 들면 다음과 같습니다.
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
JOB_NAME을 업데이트할 작업의 이름으로 바꿉니다.
REST
FlexTemplateRuntimeEnvironment(Flex 템플릿) 또는 RuntimeEnvironment 객체에서 additionalExperiments 필드를 사용합니다.
{
additionalExperiments : ["graph_validate_only"]
...
}
graph_validate_only 서비스 옵션은 파이프라인 업데이트만 검증합니다. 파이프라인을 만들거나 실행할 때는 이 옵션을 사용하지 마세요. 파이프라인을 업데이트하려면 graph_validate_only 서비스 옵션 없이 교체 작업을 실행합니다.
작업 그래프의 유효성 검사가 성공하면 작업 상태와 작업 로그에 다음 상태가 표시됩니다.
- 작업 상태는
JOB_STATE_DONE입니다. - Google Cloud 콘솔에서 작업 상태는
Succeeded입니다. 다음 메시지가 작업 로그에 표시됩니다.
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
작업 그래프의 유효성 검사가 실패하면 작업 상태와 작업 로그에 다음 상태가 표시됩니다.
- 작업 상태는
JOB_STATE_FAILED입니다. - Google Cloud 콘솔에서 작업 상태는
Failed입니다. - 작업 로그에 비호환성 오류를 설명하는 메시지가 표시됩니다. 메시지 내용은 오류에 따라 다릅니다.
교체 작업 실행
다음과 같은 이유로 기존 작업을 교체할 수 있습니다.
- 업데이트된 파이프라인 코드를 실행하려는 경우
- 진행 중인 업데이트를 지원하지 않는 작업 옵션을 업데이트하려는 경우
교체 작업이 유효한지 확인하려면 새 작업이 시작되기 전에 작업 그래프의 유효성을 검사합니다.
교체 작업을 실행할 때는 작업의 일반 옵션 외에도 업데이트 프로세스를 수행하도록 다음 파이프라인 옵션을 설정합니다.
자바
--update옵션을 전달합니다.PipelineOptions의--jobName옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transformNameMapping옵션을 사용하여 전달해야 합니다. - 이후 버전의 Apache Beam SDK를 사용하는 대체 작업을 제출하는 경우
--updateCompatibilityVersion을 원래 작업에서 사용된 Apache Beam SDK 버전으로 설정합니다.
Python
--update옵션을 전달합니다.PipelineOptions의--job_name옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform_name_mapping옵션을 사용하여 전달해야 합니다. - 이후 버전의 Apache Beam SDK를 사용하는 대체 작업을 제출하는 경우
--updateCompatibilityVersion을 원래 작업에서 사용된 Apache Beam SDK 버전으로 설정합니다.
Go
--update옵션을 전달합니다.--job_name옵션을 업데이트할 작업과 동일한 이름으로 설정합니다.--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform_name_mapping옵션을 사용하여 전달해야 합니다.
gcloud
gcloud CLI를 사용하여 Flex 템플릿 작업을 업데이트하려면 gcloud dataflow flex-template run 명령어를 사용합니다. gcloud CLI를 사용한 다른 작업 업데이트는 지원되지 않습니다.
--update옵션을 전달합니다.- JOB_NAME을(를) 업데이트할 작업과 동일한 이름으로 설정합니다.
--region옵션을 업데이트할 작업 리전과 동일한 리전으로 설정하세요.- 파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
--transform-name-mappings옵션을 사용하여 전달해야 합니다.
REST
다음 안내에서는 REST API를 사용하여 템플릿이 아닌 작업을 업데이트하는 방법을 보여줍니다. REST API를 사용하여 기본 템플릿 작업을 업데이트하려면 커스텀 템플릿 스트리밍 작업 업데이트를 참조하세요. REST API를 사용하여 Flex 템플릿 작업을 업데이트하려면 Flex 템플릿 작업 업데이트를 참조하세요.
projects.locations.jobs.get메서드를 사용하여 교체하려는 작업의job리소스를 가져옵니다.view쿼리 매개변수에JOB_VIEW_DESCRIPTION값을 포함합니다.JOB_VIEW_DESCRIPTION을 포함하면 후속 요청이 크기 한도를 초과하지 않도록 응답에 포함할 데이터 양이 제한됩니다. 자세한 작업 정보가 필요하면JOB_VIEW_ALL값을 사용합니다.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTION다음 값을 바꿉니다.
- PROJECT_ID: Dataflow 작업의 Google Cloud 프로젝트 ID
- REGION: 업데이트할 작업의 리전입니다.
- JOB_ID: 업데이트할 작업의 작업 ID입니다.
작업을 업데이트하려면
projects.locations.jobs.create메서드를 사용합니다. 요청 본문에서 가져온job리소스를 사용합니다.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }다음을 바꿉니다.
- JOB_ID: 업데이트할 작업의 ID와 동일한 작업 ID입니다.
- JOB_NAME: 업데이트할 작업 이름과 동일한 작업 이름입니다.
파이프라인의 변환 이름이 변경되면 변환 매핑을 제공하고
transformNameMapping필드를 사용하여 전달해야 합니다.선택사항: curl(Linux, macOS 또는 Cloud Shell)을 사용하여 요청을 보내려면 요청을 JSON 파일에 저장한 후 다음 명령어를 실행합니다.
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsFILE_PATH를 요청 본문이 포함된 JSON 파일의 경로로 바꿉니다.
교체 작업 이름 지정
자바
교체 작업 실행 시 --jobName 옵션과 관련하여 전달하는 값은 교체할 작업 이름과 정확히 일치해야 합니다.
Python
교체 작업 실행 시 --job_name 옵션과 관련하여 전달하는 값은 교체할 작업 이름과 정확히 일치해야 합니다.
Go
교체 작업 실행 시 --job_name 옵션과 관련하여 전달하는 값은 교체할 작업 이름과 정확히 일치해야 합니다.
gcloud
교체 작업 실행 시 JOB_NAME은 교체할 작업 이름과 정확히 일치해야 합니다.
REST
replaceJobId 필드 값을 업데이트할 작업과 동일한 작업 ID로 설정합니다. 올바른 작업 이름 값을 찾으려면 Dataflow 모니터링 인터페이스에서 이전 작업을 선택합니다.
그런 다음 작업 정보 측면 패널에서 작업 ID 필드를 찾습니다.
올바른 작업 이름 값을 찾으려면 Dataflow 모니터링 인터페이스에서 이전 작업을 선택합니다. 그런 다음 작업 정보 측면 패널에서 작업 이름 필드를 찾습니다.
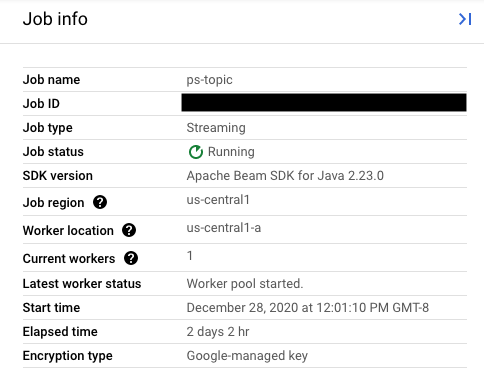
또는 Dataflow 명령줄 인터페이스를 사용하여 기존 작업 목록을 쿼리합니다.
gcloud dataflow jobs list 명령어를 셸이나 터미널 창에 입력하여 Google Cloud Platform 프로젝트의 Dataflow 작업 목록을 가져오고 교체할 작업의 NAME 필드를 찾습니다.
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
변환 매핑 만들기
교체 파이프라인이 이전 파이프라인의 이름에서 변환 이름을 변경한 경우 Dataflow 서비스에 변환 매핑이 필요합니다. 변환 매핑은 이전 파이프라인 코드의 이름이 지정된 변환을 교체 파이프라인 코드의 이름에 매핑합니다
자바
--transformNameMapping 명령줄 옵션을 사용하여 매핑을 전달할 때 다음의 일반적인 형식을 사용합니다.
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
이전 파이프라인과 교체 파이프라인 사이에 변경된 변환 이름에 대해서만 --transformNameMapping에 매핑 항목을 제공해야 합니다.
--transformNameMapping을 사용하여 실행할 때 따옴표를 셸에 맞게 이스케이프 처리해야 할 수 있습니다. 예를 들어 Bash에서는 다음과 같습니다.
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
--transform_name_mapping 명령줄 옵션을 사용하여 매핑을 전달할 때 다음의 일반적인 형식을 사용합니다.
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
이전 파이프라인과 교체 파이프라인 사이에 변경된 변환 이름에 대해서만 --transform_name_mapping에 매핑 항목을 제공해야 합니다.
--transform_name_mapping을 사용하여 실행할 때 따옴표를 셸에 맞게 이스케이프 처리해야 할 수 있습니다. 예를 들어 Bash에서는 다음과 같습니다.
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
--transform_name_mapping 명령줄 옵션을 사용하여 매핑을 전달할 때 다음의 일반적인 형식을 사용합니다.
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
이전 파이프라인과 교체 파이프라인 사이에 변경된 변환 이름에 대해서만 --transform_name_mapping에 매핑 항목을 제공해야 합니다.
--transform_name_mapping을 사용하여 실행할 때 따옴표를 셸에 맞게 이스케이프 처리해야 할 수 있습니다. 예를 들어 Bash에서는 다음과 같습니다.
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
--transform-name-mappings 옵션을 사용하여 매핑을 전달할 때 다음의 일반적인 형식을 사용합니다.
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
이전 파이프라인과 교체 파이프라인 사이에 변경된 변환 이름에 대해서만 --transform-name-mappings에 매핑 항목을 제공해야 합니다.
--transform-name-mappings을 사용하여 실행할 때 따옴표를 셸에 맞게 이스케이프 처리해야 할 수 있습니다. 예를 들어 Bash에서는 다음과 같습니다.
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
transformNameMapping 필드를 사용하여 매핑을 전달할 때 다음의 일반적인 형식을 사용합니다.
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
이전 파이프라인과 교체 파이프라인 사이에 변경된 변환 이름에 대해서만 transformNameMapping에 매핑 항목을 제공해야 합니다.
변환 이름 확인
맵의 각 인스턴스에서 변환 이름은 파이프라인에서 변환 적용 시 제공한 이름입니다 예를 들면 다음과 같습니다.
자바
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
Dataflow 모니터링 인터페이스에서 작업의 실행 그래프를 검토하여 이전 작업의 변환 이름을 가져올 수도 있습니다.

복합 변환 이름 지정
변환 이름은 계층적이며 파이프라인의 변환 계층구조를 기반으로 합니다. 파이프라인에 복합 변환이 있는 경우, 중첩된 변환은 포괄하는 변환의 관점에서 이름이 지정됩니다. 예를 들어, 파이프라인에 CountWidgets라는 복합 변환이 포함되어 있고 여기에 Parse라는 내부 변환이 포함되어 있다고 가정합니다. 변환의 전체 이름은 CountWidgets/Parse가 되고 변환 매핑에 이 전체 이름을 지정해야 합니다.
새 파이프라인이 복합 변환을 다른 이름에 매핑하는 경우, 중첩된 모든 변환의 이름도 자동으로 바뀌므로, 변환 매핑의 내부 변환에 변경된 이름을 지정해야 합니다.
변환 계층 구조 리팩터링
교체 파이프라인에 이전 파이프라인과 다른 변환 계층 구조가 사용되는 경우 매핑을 명시적으로 선언해야 합니다. 복합 변환을 리팩터링했기 때문에 다른 변한 계층 구조가 있을 수 있고 아니면 파이프라인이 변경된 라이브러리의 복합 변환에 의존합니다.
예를 들어 이전 파이프라인에 Parse라는 내부 변환이 포함된 복합 변환 CountWidgets가 적용되었습니다. 교체 파이프라인은 CountWidgets를 리팩토링하고 Scan이라는 다른 변환 안에 Parse를 중첩합니다. 업데이트에 성공하려면 이전 파이프라인(CountWidgets/Parse)의 전체 변환 이름을 새 파이프라인(CountWidgets/Scan/Parse)의 변환 이름에 명시적으로 매핑해야 합니다:
자바
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
교체 파이프라인에서 변환을 완전히 삭제하는 경우, null 매핑을 제공해야 합니다. 교체 파이프라인이 CountWidgets/Parse 변환을 완전히 제거한다고 가정합니다.
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
교체 파이프라인에서 변환을 완전히 삭제하는 경우, null 매핑을 제공해야 합니다. 교체 파이프라인이 CountWidgets/Parse 변환을 완전히 제거한다고 가정합니다.
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
교체 파이프라인에서 변환을 완전히 삭제하는 경우, null 매핑을 제공해야 합니다. 교체 파이프라인이 CountWidgets/Parse 변환을 완전히 제거한다고 가정합니다.
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
교체 파이프라인에서 변환을 완전히 삭제하는 경우, null 매핑을 제공해야 합니다. 교체 파이프라인이 CountWidgets/Parse 변환을 완전히 제거한다고 가정합니다.
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
교체 파이프라인에서 변환을 완전히 삭제하는 경우, null 매핑을 제공해야 합니다. 교체 파이프라인이 CountWidgets/Parse 변환을 완전히 제거한다고 가정합니다.
"transformNameMapping": {
CountWidgets/main.Parse: null
}
작업 교체의 효과
기존 작업을 교체하면 새 작업이 업데이트된 파이프라인 코드를 실행합니다. Dataflow 서비스는 작업 이름을 유지하지만 업데이트된 작업 ID로 교체 작업을 실행합니다. 이 프로세스로 인해 기존 작업이 중지되고 호환성 검사가 실행되어 새 작업이 시작될 때 다운타임이 발생할 수 있습니다.
교체 작업 시 다음 항목은 보존됩니다.
- 이전 작업의 중간 상태 데이터. 인메모리 캐시는 저장되지 않습니다.
- 버퍼링된 데이터 레코드 또는 이전 작업에서 현재 '처리 중'인 메타데이터. 예를 들어, 파이프라인의 일부 레코드는 윈도우의 확인을 기다리는 동안 버퍼링될 수 있습니다.
- 이전 작업에 적용한 진행 중인 작업 옵션 업데이트
중간 상태 데이터
이전 작업의 중간 상태 데이터는 유지됩니다. 상태 데이터에는 인메모리 캐시가 포함되지 않습니다. 파이프라인을 업데이트할 때 인메모리 캐시 데이터를 보존하려면 해결 방법으로서 파이프라인을 리팩터링하여 캐시를 상태 데이터 또는부차 입력으로 변환합니다. 부차 입력 사용에 대한 자세한 내용은 Apache Beam 문서의 부차 입력 패턴을 참조하세요.
스트리밍 파이프라인에는 ValueState 및 부차 입력에 대한 크기 한도가 있습니다.
따라서 보존하려는 대용량 캐시가 있으면 Memorystore 또는 Bigtable과 같은 외부 스토리지를 사용해야 할 수 있습니다.
진행 중인 데이터
'진행 중인' 데이터는 새 파이프라인의 변환에 의해 계속 처리됩니다. 하지만 교체 파이프라인 코드에 추가되는 추가 변환은 레코드가 버퍼링되는 위치에 따라 적용되거나 적용되지 않을 수 있습니다. 이 예시에서 기존 파이프라인에는 다음 변환이 포함됩니다.
자바
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
다음과 같이 작업을 새 파이프라인 코드로 바꿀 수 있습니다.
자바
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
문자 'A'로 시작되는 문자열을 필터링하도록 변환을 추가한 경우에도 다음 변환(FormatStrings) 시 이전 작업에서 전송되고 'A'로 시작되는 버퍼링된 문자열 또는 진행 중인 문자열이 계속 표시될 수 있습니다.
기간 설정 변경
교체 파이프라인에서 PCollection 요소의 기간 설정 및 트리거 전략을 변경할 수 있지만 주의해야 합니다.
윈도우 또는 트리거 전략을 변경해도 이미 버퍼링되었거나 진행 중인 데이터는 영향을 받지 않습니다.
고정 기간 또는 슬라이딩 기간 창과 같이 파이프라인의 윈도우에 더 사소한 변경만 시도하는 것이 좋습니다. 윈도우 알고리즘 변경과 같이 윈도우나 트리거에 대대적인 변경을 수행하면 파이프라인 출력에 예측할 수 없는 결과가 발생할 수 있습니다.
작업 호환성 검사
교체 작업을 실행하면 Dataflow 서비스는 교체 작업과 이전 작업 사이의 호환성 검사를 수행합니다. 호환성 검사에 통과하면 이전 작업이 중지되고, 그러면 동일한 작업 이름을 유지하면서 대체 작업이 Dataflow 서비스에서 실행됩니다. 호환성 검사에 실패하면 이전 작업이 Dataflow 서비스에서 계속 실행되며 교체 작업은 오류를 반환합니다.
자바
제한사항으로 인해 콘솔 또는 터미널에서 실패한 업데이트 시도 오류를 보려면 실행 차단을 사용해야 합니다. 현재 해결 방법은 다음 단계로 구성됩니다.
- 파이프라인 코드에 pipeline.run().waitUntilFinish()를 사용합니다.
--update옵션을 사용하여 교체 파이프라인 프로그램을 실행합니다.- 교체 작업이 호환성 검사를 통과할 때까지 기다립니다.
Ctrl+C를 입력하여 차단 실행자 프로세스를 종료합니다.
또는 Dataflow 모니터링 인터페이스에서 교체 작업 상태를 모니터링할 수 있습니다. 작업이 성공적으로 시작되었으면 호환성 검사를 통과한 것입니다.
Python
제한사항으로 인해 콘솔 또는 터미널에서 실패한 업데이트 시도 오류를 보려면 실행 차단을 사용해야 합니다. 현재 해결 방법은 다음 단계로 구성됩니다.
- 파이프라인 코드에 pipeline.run().wait_until_finish()를 사용합니다.
--update옵션을 사용하여 교체 파이프라인 프로그램을 실행합니다.- 교체 작업이 호환성 검사를 통과할 때까지 기다립니다.
Ctrl+C를 입력하여 차단 실행자 프로세스를 종료합니다.
또는 Dataflow 모니터링 인터페이스에서 교체 작업 상태를 모니터링할 수 있습니다. 작업이 성공적으로 시작되었으면 호환성 검사를 통과한 것입니다.
Go
제한사항으로 인해 콘솔 또는 터미널에서 실패한 업데이트 시도 오류를 보려면 실행 차단을 사용해야 합니다.
특히 --execute_async 또는 --async 플래그를 사용하여 비차단 실행을 지정해야 합니다. 현재 해결 방법은 다음 단계로 구성됩니다.
--update옵션을 사용하고--execute_async또는--async플래그 없이 교체 파이프라인 프로그램을 실행합니다.- 교체 작업이 호환성 검사를 통과할 때까지 기다립니다.
Ctrl+C를 입력하여 차단 실행자 프로세스를 종료합니다.
gcloud
제한사항으로 인해 콘솔 또는 터미널에서 실패한 업데이트 시도 오류를 보려면 실행 차단을 사용해야 합니다. 현재 해결 방법은 다음 단계로 구성됩니다.
- Java 파이프라인의 경우 파이프라인 코드에 pipeline.run().waitUntilFinish()를 사용합니다. Python 파이프라인의 경우 파이프라인 코드에 pipeline.run().wait_until_finish()를 사용합니다. Go 파이프라인의 경우 Go 탭의 단계를 따르세요.
--update옵션을 사용하여 교체 파이프라인 프로그램을 실행합니다.- 교체 작업이 호환성 검사를 통과할 때까지 기다립니다.
Ctrl+C를 입력하여 차단 실행자 프로세스를 종료합니다.
REST
제한사항으로 인해 콘솔 또는 터미널에서 실패한 업데이트 시도 오류를 보려면 실행 차단을 사용해야 합니다. 현재 해결 방법은 다음 단계로 구성됩니다.
- Java 파이프라인의 경우 파이프라인 코드에 pipeline.run().waitUntilFinish()를 사용합니다. Python 파이프라인의 경우 파이프라인 코드에 pipeline.run().wait_until_finish()를 사용합니다. Go 파이프라인의 경우 Go 탭의 단계를 따르세요.
replaceJobId필드를 사용하여 교체 파이프라인 프로그램을 실행합니다.- 교체 작업이 호환성 검사를 통과할 때까지 기다립니다.
Ctrl+C를 입력하여 차단 실행자 프로세스를 종료합니다.
호환성 검사는 제공된 변환 매핑을 사용해서 Dataflow가 이전 단계에서 교체 작업으로 중간 상태 데이터를 전송할 수 있는지 확인합니다. 또한 호환성 검사를 통해 파이프라인의 PCollection에 동일한 Coder가 사용되는지 확인합니다.
Coder를 변경하면 진행 중인 데이터 또는 버퍼링된 레코드가 교체 파이프라인에서 제대로 직렬화되지 않을 수 있으므로, 호환성 검사가 실패할 수 있습니다.
호환성 손상 방지
이전 파이프라인과 교체 파이프라인 간의 특정 차이로 인해 호환성 검사가 실패할 수 있습니다. 이러한 차이점은 다음과 같습니다.
- 매핑을 제공하지 않고 파이프라인 그래프 변경. 작업을 업데이트하면 Dataflow가 이전 작업의 변환을 교체 작업의 변환에 매칭하려고 시도합니다. 이러한 매칭 프로세스는 각 단계에 대해 Dataflow가 중간 상태 데이터를 전송하는 데 도움을 줍니다. 단계 이름을 바꾸거나 단계를 삭제하는 경우 Dataflow가 이에 맞게 상태 데이터를 일치시킬 수 있도록 변환 매핑을 제공해야 합니다.
- 단계의 부차 입력 변경. 교체 파이프라인의 변환에 부차 입력을 추가하거나 이 변환에서 부차 입력을 제거하면 호환성 검사가 실패할 수 있습니다.
- 단계의 Coder 변경. 작업을 업데이트하면 Dataflow가 현재 버퍼링된 데이터 레코드를 보존하고 교체 작업에서 이를 처리합니다. 예를 들어 윈도잉을 완료하는 동안 버퍼링된 데이터가 발생할 수 있습니다. 교체 작업이 다르거나 호환되지 않는 데이터 인코딩을 사용하는 경우, Dataflow는 이러한 레코드를 직렬화하거나 역직렬화할 수 없습니다.
파이프라인에서 '스테이트풀(Stateful)' 작업 삭제. 파이프라인에서 스테이트풀(Stateful) 작업을 삭제하면 교체 작업에서 호환성 검사가 실패할 수 있습니다. Dataflow는 효율성을 위해 여러 단계를 함께 융합할 수 있습니다. 융합된 단계 내에서 상태 의존적인 작업을 제거하면 검사가 실패합니다. 상태 저장 작업에는 다음이 포함됩니다.
- 부차 입력을 생성하거나 소비하는 변환
- I/O 읽기
- 키가 지정된 상태를 사용하는 변환
- 윈도우 병합이 있는 변환
스테이트풀(Stateful)
DoFn변수 변경. 진행 중인 스트리밍 작업의 경우 파이프라인에 스테이트풀(Stateful)DoFn가 포함되는 경우 스테이트풀(Stateful)DoFn변수를 변경하면 파이프라인이 실패할 수 있습니다.다른 영역에서 교체 작업을 실행하려는 경우. 이전 작업을 실행한 영역과 동일한 영역에서 교체 작업을 실행합니다.
스키마 업데이트
Apache Beam에서는 PCollection에서 이름이 지정된 필드가 있는 스키마를 사용할 수 있으며, 이 경우 명시적 Coder가 필요하지 않습니다. (중첩된 필드를 포함해) 지정된 스키마의 필드 이름과 유형이 변경되지 않으면 이 스키마로 인해 업데이트 확인이 실패하지 않습니다. 그러나 새 파이프라인의 다른 세그먼트가 호환되지 않을 경우 업데이트가 차단될 수 있습니다.
스키마 개선
비즈니스 요구사항이 발전함에 따라 PCollection의 스키마를 개선해야 하는 경우가 종종 있습니다. Dataflow 서비스를 사용하면 파이프라인을 업데이트할 때 다음과 같이 스키마를 변경할 수 있습니다.
- 스키마에 중첩 필드를 포함하여 새 필드를 하나 이상 추가
- 필수(null 비허용) 필드 유형을 선택사항(null 허용)으로 만들기
업데이트 중에는 필드를 삭제하거나 필드 이름을 변경하거나 필드 유형을 변경할 수 없습니다.
기존 ParDo 작업에 추가 데이터 전달
사용 사례에 따라 다음 방법 중 하나를 사용하여 추가(대역 외) 데이터를 기존 ParDo 작업에 전달할 수 있습니다.
- 정보를
DoFn서브클래스의 필드로 직렬화합니다. - 익명의
DoFn에서 메서드로 참조하는 변수는 자동으로 직렬화됩니다. DoFn.startBundle()내에서 데이터를 계산합니다.ParDo.withSideInputs를 사용하여 데이터를 전달합니다.
자세한 내용은 다음 페이지를 참조하세요.
- Apache Beam 프로그래밍 가이드: ParDo 중 특히 DoFn 만들기 및 부차 입력 관련 섹션
- Java용 Apache Beam SDK 참조: ParDo