En esta página se ofrecen consejos para solucionar problemas y estrategias de depuración que pueden resultarte útiles si tienes problemas para crear o ejecutar tu canalización de Dataflow. Esta información puede ayudarte a detectar un fallo en una canalización, determinar el motivo de un error en la ejecución de una canalización y sugerir algunas medidas para corregir el problema.
En el siguiente diagrama se muestra el flujo de trabajo para solucionar problemas de Dataflow que se describe en esta página.

Dataflow proporciona comentarios en tiempo real sobre tu trabajo. Hay una serie de pasos básicos que puedes seguir para comprobar los mensajes de error y los registros, así como para detectar si el progreso de tu trabajo se ha detenido.
Para obtener información sobre los errores habituales que pueden producirse al ejecutar una tarea de Dataflow, consulta el artículo Solucionar problemas de Dataflow. Para monitorizar y solucionar problemas relacionados con el rendimiento de las canalizaciones, consulta Monitorizar el rendimiento de las canalizaciones.
Prácticas recomendadas para las canalizaciones
Estas son las prácticas recomendadas para las canalizaciones de Java, Python y Go.
Java
En el caso de las tareas por lotes, te recomendamos que definas un tiempo de vida (TTL) para la ubicación temporal.
Antes de configurar el TTL y como práctica recomendada general, asegúrate de que tanto la ubicación de almacenamiento temporal como la ubicación temporal sean diferentes.
No elimine los objetos de la ubicación de almacenamiento provisional, ya que se reutilizan.
Si un trabajo se completa o se detiene y los objetos temporales no se han limpiado, elimina manualmente estos archivos del segmento de Cloud Storage que se utiliza como ubicación temporal.
Python
Tanto la ubicación temporal como la de almacenamiento provisional tienen el prefijo <job_name>.<time>.
Asegúrate de que tanto la ubicación de almacenamiento provisional como la ubicación temporal sean diferentes.
Si es necesario, elimina los objetos de la ubicación de almacenamiento provisional después de que se complete o se detenga un trabajo. Además, los objetos almacenados no se reutilizan en las canalizaciones de Python.
Si una tarea finaliza y los objetos temporales no se limpian, elimina manualmente estos archivos del segmento de Cloud Storage que se utiliza como ubicación temporal.
En el caso de las tareas por lotes, te recomendamos que definas un tiempo de vida (TTL) para las ubicaciones temporales y de almacenamiento provisional.
Go
Tanto la ubicación temporal como la de almacenamiento provisional tienen el prefijo
<job_name>.<time>.Asegúrate de que tanto la ubicación de almacenamiento provisional como la ubicación temporal sean diferentes.
Si es necesario, elimina los objetos de la ubicación de almacenamiento provisional después de que se complete o se detenga un trabajo. Además, los objetos almacenados no se reutilizan en las canalizaciones de Go.
Si una tarea finaliza y los objetos temporales no se limpian, elimina manualmente estos archivos del segmento de Cloud Storage que se utiliza como ubicación temporal.
En el caso de las tareas por lotes, te recomendamos que definas un tiempo de vida (TTL) para las ubicaciones temporales y de almacenamiento provisional.
Consultar el estado de una canalización
Puedes detectar errores en las ejecuciones de tu flujo de procesamiento mediante la interfaz de monitorización de Dataflow.
- Ve a la Google Cloud consola.
- Selecciona tu proyecto de Google Cloud Platform en la lista de proyectos.
- En el menú de navegación, vaya a Big Data y haga clic en Dataflow. En el panel de la derecha se muestra una lista de los trabajos en curso.
- Selecciona el trabajo de la canalización que quieras ver. Puedes ver el estado de los trabajos de un vistazo en el campo Estado: "En curso", "Completado" o "Fallido".
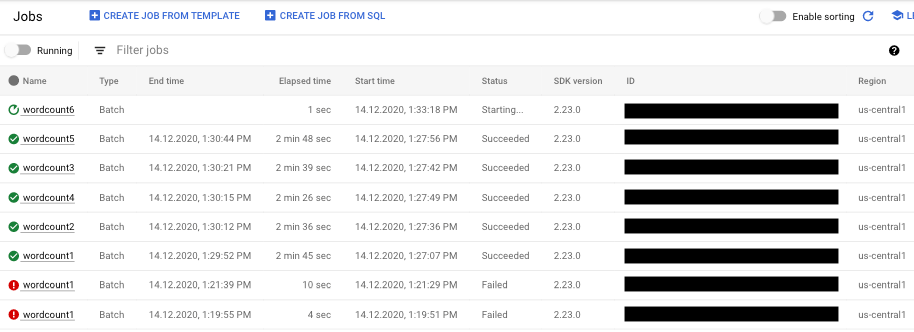
Consultar información sobre los errores de las canalizaciones
Si falla uno de los trabajos de tu canalización, puedes seleccionarlo para ver información más detallada sobre los errores y los resultados de la ejecución. Cuando seleccionas un trabajo, puedes ver gráficos clave de tu canalización, el gráfico de ejecución, el panel Información del trabajo y el panel Registros con las pestañas Registros del trabajo, Registros del trabajador, Diagnóstico y Recomendaciones.
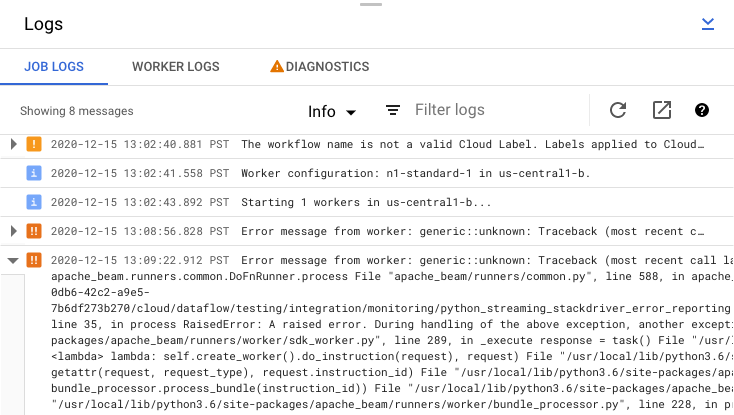
Consultar los mensajes de error de los trabajos
Para ver los registros de tareas generados por el código de tu flujo de procesamiento y el servicio Dataflow, en el panel Registros, haz clic en segmentMostrar.
Para filtrar los mensajes que aparecen en Registros de trabajos, haz clic en Informaciónarrow_drop_down y filter_listFiltrar. Para mostrar solo los mensajes de error, haz clic en Informaciónarrow_drop_down y selecciona Error.
Para desplegar un mensaje de error, haz clic en la sección desplegable arrow_right.
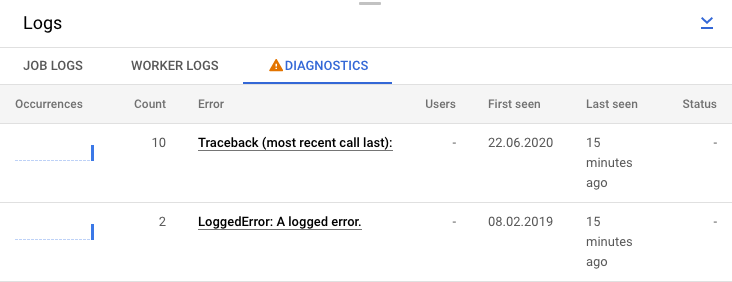
También puede hacer clic en la pestaña Diagnóstico. En esta pestaña se muestra dónde se han producido errores a lo largo de la cronología elegida, un recuento de todos los errores registrados y posibles recomendaciones para tu canalización.
Ver los registros de pasos de un trabajo
Cuando seleccionas un paso en el gráfico de tu flujo de procesamiento, el panel de registros cambia de mostrar los registros de trabajo generados por el servicio Dataflow a mostrar los registros de las instancias de Compute Engine que ejecutan el paso del flujo de procesamiento.
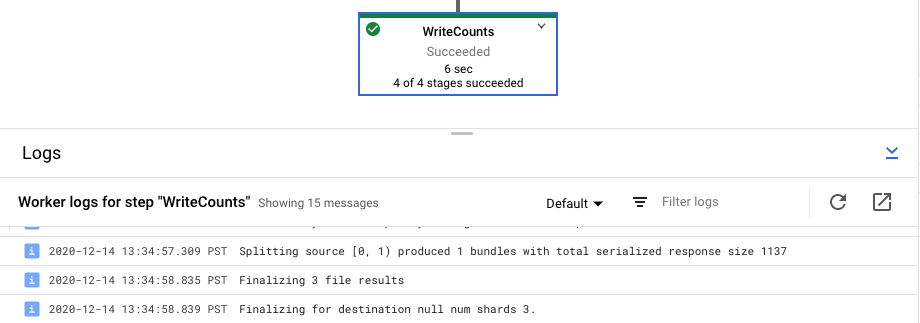
Cloud Logging combina todos los registros recogidos de las instancias de Compute Engine de tu proyecto en una sola ubicación. Consulta Registrar mensajes de la canalización para obtener más información sobre el uso de las distintas funciones de registro de Dataflow.
Gestionar el rechazo de un flujo de procesamiento automatizado
En algunos casos, el servicio Dataflow identifica que tu flujo de procesamiento puede activar problemas conocidos del SDK. Para evitar que se envíen las canalizaciones que probablemente tengan problemas, Dataflow rechaza automáticamente tu canalización y muestra el siguiente mensaje:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Después de leer las advertencias en los detalles del error vinculado, si quieres intentar ejecutar tu canalización de todos modos, puedes anular el rechazo automático. Añade el marcador --experiments=<override-flag> y vuelve a enviar tu flujo de trabajo.
Determinar la causa de un fallo en una canalización
Por lo general, la causa de un fallo en la ejecución de una canalización de Apache Beam es una de las siguientes:
- Errores de construcción de gráficos o de la canalización. Estos errores se producen cuando Dataflow tiene problemas para crear el gráfico de pasos que componen tu canalización, tal como se describe en tu canalización de Apache Beam.
- Errores en la validación de trabajos. El servicio Dataflow valida cualquier tarea de flujo de procesamiento que inicies. Si se producen errores en el proceso de validación, no se podrá crear o ejecutar el trabajo correctamente. Los errores de validación pueden incluir problemas con el segmento de Cloud Storage de tu proyecto Google Cloud o con los permisos de tu proyecto.
- Excepciones en el código del trabajador. Estos errores se producen cuando hay errores o fallos en el código proporcionado por el usuario que Dataflow distribuye a los trabajadores paralelos, como las instancias
DoFnde una transformaciónParDo. - Errores causados por fallos transitorios en otros servicios de Google Cloud . Es posible que tu flujo de procesamiento falle debido a una interrupción temporal u otro problema en losGoogle Cloud servicios de los que depende Dataflow, como Compute Engine o Cloud Storage.
Detectar errores de creación de gráficos o de canalizaciones
Se puede producir un error de creación de gráficos cuando Dataflow crea el gráfico de ejecución de tu flujo de procesamiento a partir del código de tu programa de Dataflow. Durante el tiempo de construcción del grafo, Dataflow comprueba si hay operaciones no permitidas.
Si Dataflow detecta un error en la creación del gráfico, ten en cuenta que no se crea ningún trabajo en el servicio Dataflow. Por lo tanto, no verás ningún comentario en la interfaz de monitorización de Dataflow. En su lugar, aparece un mensaje de error similar al siguiente en la consola o en la ventana de terminal en la que has ejecutado tu canalización de Apache Beam:
Java
Por ejemplo, si tu canal intenta realizar una agregación como
GroupByKey en un elemento PCollection sin límites, no activado y con ventanas globales, aparecerá un mensaje de error similar al siguiente:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Por ejemplo, si tu canalización usa sugerencias de tipo y el tipo de argumento de una de las transformaciones no es el esperado, se produce un mensaje de error similar al siguiente:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
Por ejemplo, si tu canalización usa un `DoFn` que no recibe ninguna entrada, se produce un mensaje de error similar al siguiente:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Si se produce un error de este tipo, comprueba el código de la canalización para asegurarte de que las operaciones de la canalización son legales.
Detectar errores en la validación de tareas de Dataflow
Una vez que el servicio Dataflow haya recibido el gráfico de tu canalización, intentará validar tu trabajo. Esta validación incluye lo siguiente:
- Asegurarse de que el servicio pueda acceder a los segmentos de Cloud Storage asociados a tu trabajo para la puesta en escena de archivos y la salida temporal.
- Comprobando los permisos necesarios en tu proyecto Google Cloud .
- Asegurarse de que el servicio pueda acceder a las fuentes de entrada y salida, como los archivos.
Si tu trabajo no supera el proceso de validación, aparecerá un mensaje de error en la interfaz de monitorización de Dataflow, así como en la consola o en la ventana de terminal si usas la ejecución de bloqueo. El mensaje de error es similar al siguiente:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
Actualmente, no se admite la validación de trabajos descrita en esta sección para Go. Los errores debidos a estos problemas se muestran como excepciones de trabajador.
Detectar una excepción en el código del trabajador
Mientras se ejecuta el trabajo, es posible que se produzcan errores o excepciones en el código de trabajador. Estos errores suelen significar que los DoFns de tu código de la canalización han generado excepciones no controladas, lo que provoca que las tareas de tu trabajo de Dataflow fallen.
Las excepciones en el código de usuario (por ejemplo, tus instancias de DoFn) se registran en la interfaz de monitorización de Dataflow.
Si ejecutas tu canalización con la ejecución de bloqueo, los mensajes de error se imprimen en la consola o en la ventana de terminal, como en el siguiente ejemplo:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Para evitar errores en el código, añade controladores de excepciones. Por ejemplo, si quieres eliminar elementos que no superen alguna validación de entrada personalizada realizada en un ParDo, gestiona la excepción en tu DoFn y elimina el elemento.
También puedes monitorizar los elementos que fallan de varias formas:
- Puedes registrar los elementos que fallan y consultar el resultado con Cloud Logging.
- Para comprobar si hay advertencias o errores en los registros de inicio de los trabajadores de Dataflow, sigue las instrucciones que se indican en Ver registros.
- Puedes hacer que
ParDoescriba los elementos que fallan en una salida adicional para inspeccionarlos más adelante.
Para monitorizar las propiedades de una canalización en ejecución, puede usar la clase Metrics, como se muestra en el siguiente ejemplo:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Solucionar problemas de lentitud en los flujos de trabajo o de falta de resultados
Consulta las siguientes páginas:
- Soluciona problemas con trabajos de streaming lentos o bloqueados.
- Solucionar problemas con trabajos por lotes lentos o bloqueados
Errores habituales y medidas que se pueden tomar
Cuando sepas qué error ha provocado el fallo de la canalización, consulta la página Solucionar errores de Dataflow para obtener ayuda.