Cloud Profiler es un generador de perfiles estadístico y de baja sobrecarga que recopila de manera continua información de las aplicaciones de producción sobre la asignación de memoria y el uso de la CPU. Para obtener más detalles, consulta Conceptos sobre la generación de perfiles. Para solucionar problemas o supervisar el rendimiento de la canalización, usa la integración de Dataflow con Cloud Profiler a fin de identificar las partes del código de la canalización que consumen más recursos.
Si deseas obtener sugerencias para solucionar problemas y estrategias de depuración a fin de compilar o ejecutar tu canalización de Dataflow, consulta Soluciona problemas y depura canalizaciones.
Antes de comenzar
Comprende los conceptos de generación de perfiles y familiarízate con la interfaz de Profiler. Si deseas obtener información para comenzar a usar la interfaz de Profiler, consulta Selecciona los perfiles que se analizarán.
Se debe habilitar la API de Cloud Profiler en tu proyecto antes de que comience el trabajo.
Se habilita de forma automática la primera vez que visitas la página de Profiler.
Como alternativa, puedes habilitar la API de Cloud Profiler con la CLI de Google Cloud la herramienta de línea de comandos gcloud de la CLI de Google Cloud o la consola de Google Cloud.
Para usar Cloud Profiler, el proyecto debe tener una cuota suficiente.
Además, la cuenta de servicio de trabajador del trabajo de Dataflow debe tener los permisos adecuados para Profiler. Por ejemplo, para crear perfiles, la cuenta de servicio de trabajador debe tener el permiso cloudprofiler.profiles.create, que se incluye en el rol de IAM de agente de Cloud Profiler (roles/cloudprofiler.agent).
Para obtener más información, consulta Control de acceso con la IAM.
Habilita Cloud Profiler para las canalizaciones de Dataflow
Cloud Profiler está disponible para las canalizaciones de Dataflow escritas en el SDK de Apache Beam para Java y Python, versión 2.33.0 o posterior. Las canalizaciones de Python deben usar Dataflow Runner v2. Cloud Profiler se puede habilitar en el momento del inicio de la canalización. Se espera que la CPU amortizada y la sobrecarga de la memoria sean inferiores al 1% para las canalizaciones.
Java
Para habilitar la generación de perfiles de CPU, inicia la canalización con la siguiente opción.
--dataflowServiceOptions=enable_google_cloud_profiler
Para habilitar la generación de perfiles del montón, inicia la canalización con las siguientes opciones. Para la generación de perfiles del montón se necesita Java 11 o una versión posterior.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Para usar Cloud Profiler, la canalización de Python debe ejecutarse con Runner v2 de Dataflow.
Para habilitar la generación de perfiles de CPU, inicia la canalización con la siguiente opción. La creación de perfiles del montón aún no es compatible con Python.
--dataflow_service_options=enable_google_cloud_profiler
Go
Para habilitar la generación de perfiles del montón y de CPU, inicia la canalización con la siguiente opción.
--dataflow_service_options=enable_google_cloud_profiler
Si implementas las canalizaciones desde las plantillas de Dataflow y deseas habilitar Cloud Profiler, especifica las marcas enable_google_cloud_profiler y enable_google_cloud_heap_sampling como experimentos adicionales.
Console
Si usas una plantilla proporcionada por Google, puedes especificar las marcas en el flujo de datos Crear trabajo a partir de una plantilla en la página Experimentos adicionales.
gcloud
Si usas Google Cloud CLI para ejecutar plantillas, gcloud
dataflow jobs run o gcloud dataflow flex-template run, según el tipo de plantilla, usa la opción --additional-experiments para especificar las marcas.
API
Si usas la API de REST para ejecutar plantillas, según el tipo de plantilla, especifica las marcas con el campo additionalExperiments del entorno de ejecución, ya sea RuntimeEnvironment o FlexTemplateRuntimeEnvironment.
Ve los datos de creación de perfiles
Si Cloud Profiler está habilitado, se muestra un vínculo a la página de Profiler en la página de trabajo.
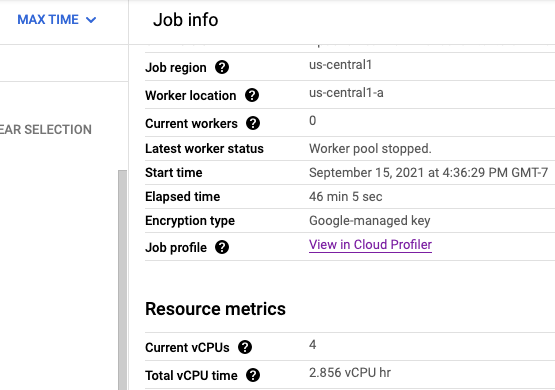
En la página de Profiler, también puedes encontrar los datos de creación de perfiles para tu canalización de Dataflow. El servicio es el nombre de tu trabajo y la versión es el ID del trabajo.

Usa Cloud Profiler
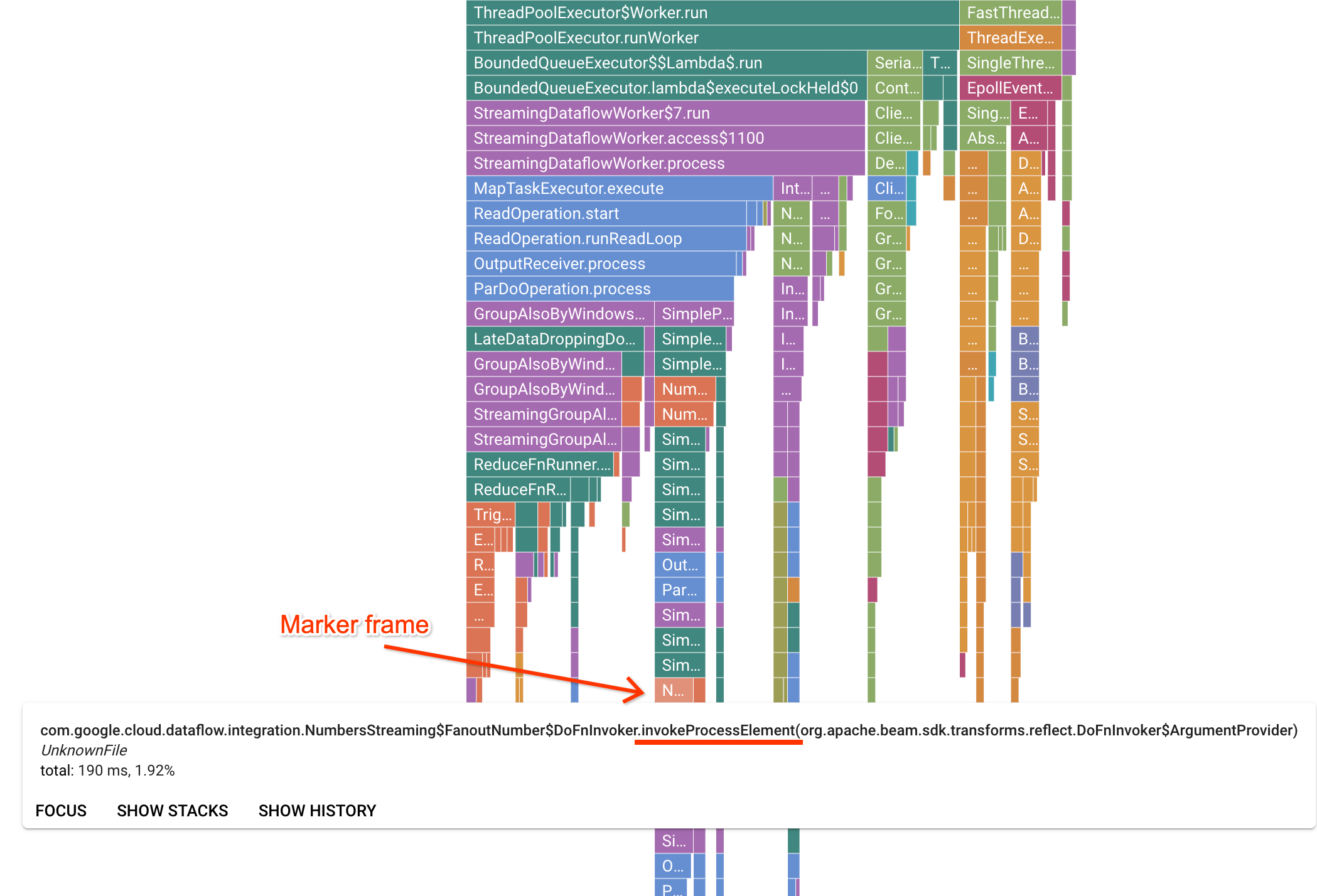
La página de Profiler contiene un gráfico tipo llama que muestra estadísticas para cada marco que se ejecuta en un trabajador. En la dirección horizontal, puedes ver cuánto tiempo tardó cada marco en ejecutarse en términos de tiempo de CPU. En la dirección vertical, puedes ver seguimientos de pila y código que se ejecuta en paralelo. El código de infraestructura de ejecutores domina los seguimientos de pila. Para fines de depuración, generalmente nos interesa la ejecución del código de usuario, que se suele encontrar cerca de las puntas inferiores del gráfico. El código de usuario se puede identificar buscando marcos de marcador, que representan el código de ejecutor que solo llama al código de usuario. En el caso del ejecutor de ParDo de Beam, se crea una capa de adaptador dinámico para invocar la firma del método DoFn suministrada por el usuario. Esta capa se puede identificar como un marco con el sufijo invokeProcessElement. En la siguiente imagen, se muestra cómo encontrar un marco de marcador.
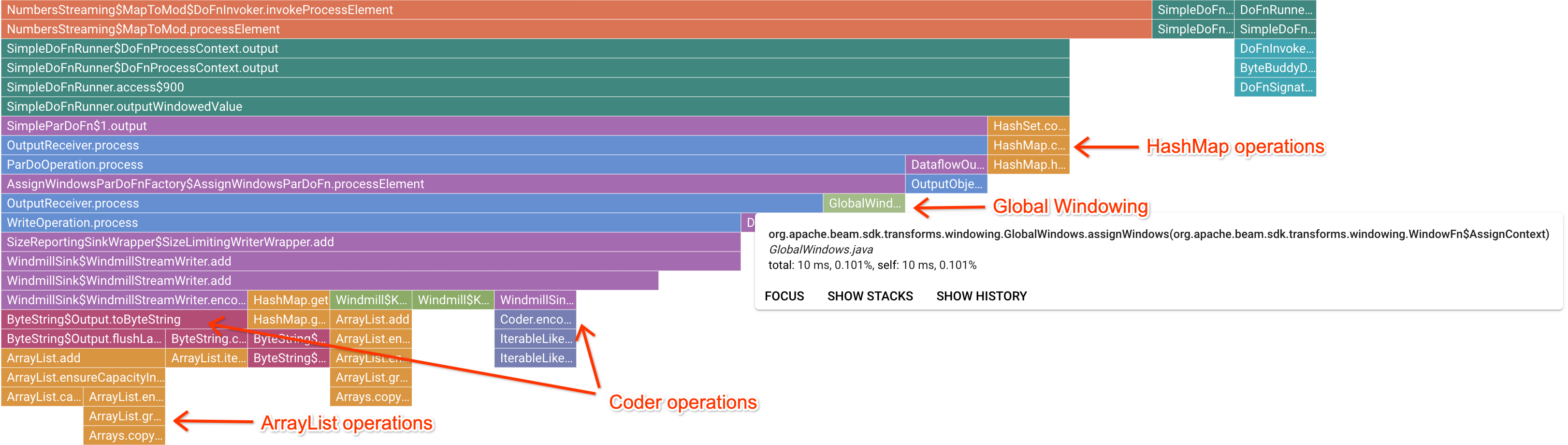
Después de que se hace clic en un marco de marcador interesante, el gráfico tipo llama se enfoca en ese seguimiento de pila y proporciona una buena idea del código de usuario de larga duración. Las operaciones más lentas pueden indicar dónde se formaron los cuellos de botella y presentan oportunidades de optimización. En el siguiente ejemplo, es posible ver que el sistema de ventanas global se está usando con ByteArrayCoder. En este caso, el codificador puede ser una buena área de optimización, ya que ocupa un tiempo de CPU considerable en comparación con las operaciones ArrayList y HashMap.
Soluciona problemas de Cloud Profiler
Si habilitas Cloud Profiler y la canalización no genera datos de creación de perfiles, una de las siguientes condiciones podría ser la causa.
Tu canalización usa una versión anterior del SDK de Apache Beam. Para usar Cloud Profiler, debes usar la versión 2.33.0 o una posterior del SDK de Apache Beam. Puedes ver la versión del SDK de Apache Beam de tu canalización en la página de trabajos. Si tu trabajo se crea a partir de plantillas de Dataflow, estas deben usar las versiones compatibles del SDK.
Tu proyecto se está quedando sin cuota de Cloud Profiler. Puedes ver el uso de la cuota desde la página de cuota de tu proyecto. Un error como
Failed to collect and upload profile whose profile type is WALLpuede producirse si se excede la cuota de Cloud Profiler. El servicio de Cloud Profiler rechaza los datos de creación de perfiles si alcanzaste tu cuota. Para obtener más información sobre las cuotas de Cloud Profiler, consulta las cuotas y límites.Tu trabajo no se ejecutó el tiempo suficiente para generar datos para Cloud Profiler. Es posible que los trabajos que se ejecutan durante períodos breves, como menos de cinco minutos, no providen suficientes datos de creación de perfiles para que Cloud Profiler genere resultados.
El agente de Cloud Profiler se instala durante el inicio del trabajador de Dataflow. Los mensajes de registro que genera Cloud Profiler están disponibles en los tipos de registro dataflow.googleapis.com/worker-startup.
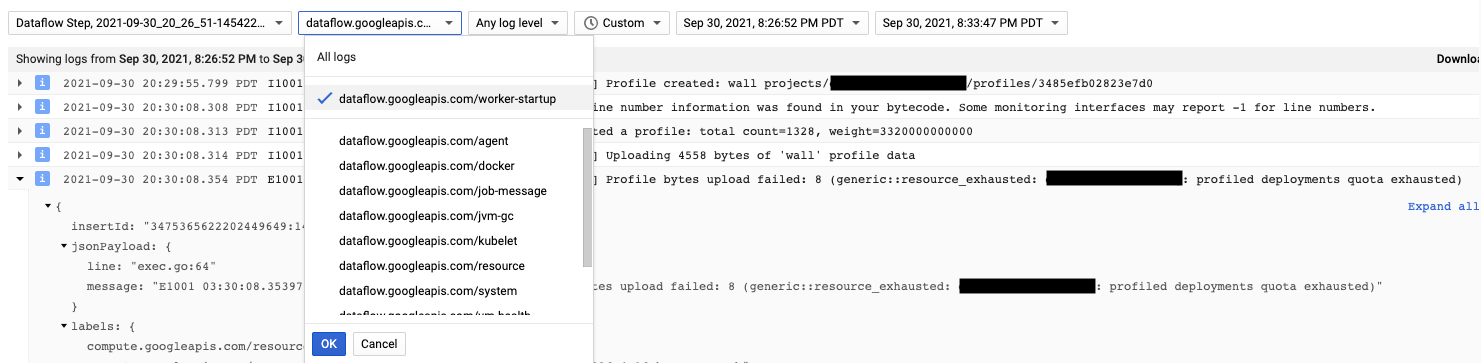
A veces, existen datos de creación de perfiles, pero Cloud Profiler no muestra ningún resultado. El generador de perfiles muestra un mensaje similar a There were
profiles collected for the specified time range, but none match the current
filters.
Para resolver este problema, realiza las siguientes acciones.
Asegúrate de que el período y la hora de finalización en el generador de perfiles incluyan el tiempo transcurrido de la tarea.
Confirma que se seleccionó el trabajo correcto en el generador de perfiles. El servicio es el nombre de tu trabajo.
Confirma que la opción de canalización
job_nametenga el mismo valor que el nombre del trabajo en la página de trabajo de Dataflow.Si especificaste un argumento de nombre del servicio cuando cargaste el agente de Profiler, confirma que el nombre del servicio esté configurado correctamente.