Auf dieser Seite wird beschrieben, wie Sie Fehler aufgrund fehlenden Speichers in Dataflow ermitteln und beheben.
Speichermangelfehler finden
Verwenden Sie eine der folgenden Methoden, um festzustellen, ob Ihrer Pipeline der Speicher ausgeht.
- Rufen Sie auf der Seite Jobdetails im Bereich Logs den Tab Diagnose auf. Auf diesem Tab werden Fehler im Zusammenhang mit Speicherproblemen und die Häufigkeit des Auftretens dieser Fehler angezeigt.
- Verwenden Sie in der Dataflow-Monitoring-Oberfläche das Diagramm Speicherauslastung, um die Kapazität und Nutzung des Workers zu überwachen.
- Wählen Sie auf der Seite Jobdetails im Bereich Logs die Option Worker-Logs aus, um in den Worker-Logs nach Arbeitsspeicherfehlern zu suchen.
Fehler aufgrund von fehlendem Speicherplatz können auch in Systemprotokollen angezeigt werden. Rufen Sie den Log-Explorer auf und verwenden Sie die folgende Abfrage, um diese Logs aufzurufen:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Ersetzen Sie JOB_ID durch die ID Ihrer Jobs.
Für Java-Jobs meldet der Java-Speichermonitor regelmäßig Messwerte für die automatische Speicherbereinigung. Wenn der Anteil der CPU-Zeit, der für die automatische Speicherbereinigung genutzt wird, einen Grenzwert von 50% über einen längeren Zeitraum hinweg überschreitet, schlägt das SDK-Nutzung fehl. Möglicherweise wird ein Fehler wie im folgenden Beispiel angezeigt:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Dieser Fehler kann auftreten, wenn der physische Speicher noch verfügbar ist. Er deutet in der Regel darauf hin, dass die Speichernutzung der Pipeline ineffizient ist. Optimieren Sie Ihre Pipeline, um dieses Problem zu beheben.
Der Java-Speichermonitor wird über die
MemoryMonitorOptions-Schnittstelle konfiguriert.
Wenn Ihr Job eine hohe Speichernutzung oder Fehler aufgrund fehlenden Speichers hat, folgen Sie den Empfehlungen auf dieser Seite, um die Speichernutzung zu optimieren oder die verfügbare Speichermenge zu erhöhen.
Nicht genügend Arbeitsspeicherfehler beheben
Änderungen an der Dataflow-Pipeline können Probleme mit fehlendem Arbeitsspeicher auflösen oder die Arbeitsspeichernutzung reduzieren. Mögliche Änderungen beinhalten die folgenden Aktionen:
- Pipeline optimieren
- Anzahl der Threads reduzieren
- Maschinentyp mit mehr Arbeitsspeicher pro vCPU verwenden
Das folgende Diagramm zeigt den Workflow zur Dataflow-Fehlerbehebung, der auf dieser Seite beschrieben wird.
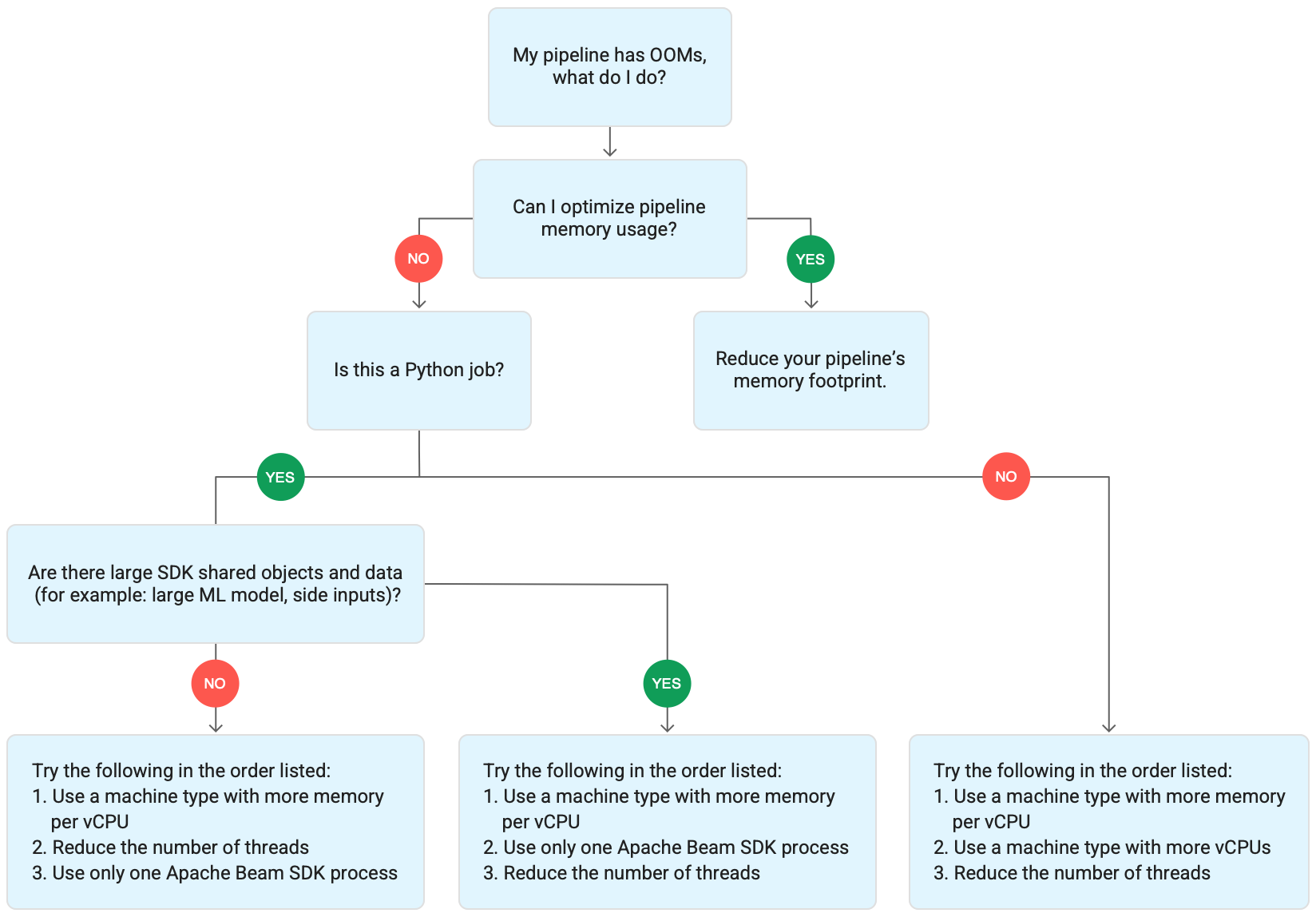
Versuchen Sie es mit den folgenden Maßnahmen:
- Optimieren Sie Ihre Pipeline nach Möglichkeit, um die Speichernutzung zu reduzieren.
- Wenn es sich um einen Batchjob handelt, führen Sie die folgenden Schritte in der angegebenen Reihenfolge aus:
- Verwenden Sie einen Maschinentyp mit mehr Arbeitsspeicher pro vCPU.
- Reduzieren Sie die Anzahl der Threads auf weniger als die Anzahl der vCPUs pro Worker.
- Verwenden Sie einen benutzerdefinierten Maschinentyp mit mehr Arbeitsspeicher pro vCPU.
- Wenn es sich um einen Streamingjob handelt, für den Python verwendet wird, reduzieren Sie die Anzahl der Threads auf weniger als 12.
- Wenn es sich um einen Streamingjob handelt, für den Java oder Go verwendet wird, versuchen Sie Folgendes:
- Reduzieren Sie die Anzahl der Threads auf weniger als 500 für Runner v2-Jobs oder auf weniger als 300 für Jobs, die Runner v2 nicht verwenden.
- Verwenden Sie einen Maschinentyp mit mehr Arbeitsspeicher.
Pipeline optimieren
Mehrere Pipelinevorgänge können zu Speicherfehlern führen. Dieser Abschnitt bietet Optionen zur Reduzierung der Speichernutzung Ihrer Pipeline. Verwenden Sie Cloud Profiler, um die Pipelineleistung zu überwachen und um die Pipelinephasen zu identifizieren, die den meisten Arbeitsspeicher belegen.
Mit den folgenden Best Practices können Sie Ihre Pipeline optimieren:
- Integrierte E/A-Connectors von Apache Beam zum Lesen von Dateien verwenden
- Vorgänge bei der Verwendung von
GroupByKeyPTransforms neu gestalten - Eingehenden Traffic aus externen Quellen reduzieren
- Objekte über Threads hinweg freigeben
- Speichereffiziente Elementdarstellungen verwenden
- Größe der Nebeneingaben verringern
- Splittable DoFns von Apache Beam verwenden
Integrierte E/A-Connectors von Apache Beam zum Lesen von Dateien verwenden
Öffnen Sie keine großen Dateien in einem DoFn. Verwenden Sie zum Lesen von Dateien integrierte E/A-Connectors von Apache Beam.
Dateien, die in einem DoFn geöffnet werden, müssen in den Arbeitsspeicher passen. Da mehrere DoFn-Instanzen gleichzeitig ausgeführt werden, können große Dateien, die in DoFn geöffnet sind, zu wenig Arbeitsspeicher führen.
Vorgänge bei der Verwendung von GroupByKey PTransforms neu gestalten
Wenn Sie eine GroupByKey PTransform in Dataflow verwenden, werden die resultierenden Werte pro Schlüssel und pro Fenster in einem einzigen Thread verarbeitet. Da diese Daten als Stream vom Dataflow-Back-End-Dienst an die Worker übergeben werden, müssen sie nicht in den Worker-Arbeitsspeicher passen. Sind die Werte jedoch
im Arbeitsspeicher gesammelt, kann die Verarbeitungslogik Fehler aufgrund fehlenden Speichers verursachen.
Wenn Sie beispielsweise einen Schlüssel haben, der Daten für ein Fenster enthält, und Sie die Schlüsselwerte zu einem speicherinternen Objekt wie einer Liste hinzufügen, kann es zu Fehlern aufgrund von fehlendem Speicherplatz kommen. In diesem Szenario verfügt der Worker möglicherweise nicht über genügend Arbeitsspeicherkapazität, um alle Objekte zu enthalten.
Weitere Informationen zu GroupByKey PTransforms finden Sie in der Apache Beam-Dokumentation zu Python GroupByKey und Java GroupByKey.
Die folgende Liste enthält Vorschläge zum Entwerfen Ihrer Pipeline, um den Speicherverbrauch bei Verwendung von GroupByKey PTransforms zu minimieren.
- Um die Datenmenge pro Schlüssel und pro Fenster zu reduzieren, sollten Sie Schlüssel mit vielen Werten vermeiden, die auch als „heiße“ Schlüssel bezeichnet werden.
- Wenn Sie die Menge der pro Fenster erhobenen Daten reduzieren möchten, verwenden Sie eine kleinere Fenstergröße.
- Wenn Sie Werte eines Schlüssels in einem Fenster verwenden, um eine Zahl zu berechnen, verwenden Sie die
Combine-Transformation. Führen Sie die Berechnung nicht in einer einzelnenDoFn-Instanz durch, nachdem Sie die Werte erfasst haben. - Filtern Sie Werte oder Duplikate vor der Verarbeitung. Weitere Informationen finden Sie in der Transformationsdokumentation zu Python
Filterund JavaFilter.
Eingehende Daten aus externen Quellen reduzieren
Wenn Sie externe APIs oder Datenbanken für die Datenanreicherung aufrufen, müssen die zurückgegebenen Daten in den Arbeitsspeicher des Workers passen.
Wenn Sie Aufrufe zusammenfassen, empfiehlt sich die Verwendung einer GroupIntoBatches-Transformation.
Wenn Fehler aufgrund fehlenden Speichers auftreten, verringern Sie die Batchgröße. Weitere Informationen zum Gruppieren in Batches finden Sie in der Transformationsdokumentation zu Python GroupIntoBatches und Java GroupIntoBatches.
Objekte in Threads freigeben
Das Freigeben eines speicherinternen Datenobjekts auf DoFn-Instanzen kann den Speicherplatz und die Zugriffseffizienz verbessern. Datenobjekte, die in einer beliebigen DoFn-Methode erstellt wurden, einschließlich Setup, StartBundle, Process, FinishBundle und Teardown, werden für jede DoFn aufgerufen. In Dataflow kann jeder Worker mehrere DoFn-Instanzen haben. Für eine effizientere Speichernutzung übergeben Sie ein Datenobjekt als Singleton, um es für mehrere DoFns freizugeben. Weitere Informationen finden Sie im Blogpost Cache-Wiederverwendung in DoFns.
Speichereffiziente Elementdarstellungen verwenden
Prüfen Sie, ob Sie Darstellungen für PCollection-Elemente verwenden können, die weniger Arbeitsspeicher verwenden. Wenn Sie Codierer in Ihrer Pipeline verwenden, sollten Sie nicht nur codierte, sondern auch decodierte PCollection-Elementdarstellungen berücksichtigen. Sparse-Matrizen können häufig von dieser Art von Optimierung profitieren.
Größe der Nebeneingaben verringern
Wenn Ihre DoFns Nebeneingaben verwenden, reduzieren Sie die Größe der Nebeneingabe. Für Nebeneingaben, bei denen es sich um Sammlungen von Elementen handelt, sollten Sie iterierbare Ansichten wie AsIterable oder AsMultimap anstelle von Ansichten verwenden, die die gesamte Nebeneingabe auf einmal materialisieren, wie AsList.
Reduzieren Sie die Anzahl der Threads.
Sie können den pro Thread verfügbaren Arbeitsspeicher erhöhen, indem Sie die maximale Anzahl der Threads, die DoFn-Instanzen ausführen, reduzieren. Durch diese Änderung wird die Parallelität reduziert, aber für jede DoFn steht mehr Arbeitsspeicher zur Verfügung.
In der folgenden Tabelle sehen Sie die Standardanzahl der Threads, die von Dataflow erstellt werden:
| Jobtyp | Python SDK | Java-/Go-SDKs |
|---|---|---|
| Batch | 1 Thread pro vCPU | 1 Thread pro vCPU |
| Streaming mit Runner v2 | 12 Threads pro vCPU | 500 Threads pro Worker-VM |
| Streaming ohne Runner v2 | 12 Threads pro vCPU | 300 Threads pro Worker-VM |
Um die Anzahl der Apache Beam SDK-Threads zu reduzieren, legen Sie die folgende Pipelineoption fest:
Java
Verwenden Sie die Pipelineoption --numberOfWorkerHarnessThreads.
Python
Verwenden Sie die Pipelineoption --number_of_worker_harness_threads.
Go
Verwenden Sie die Pipelineoption --number_of_worker_harness_threads.
Setzen Sie den Wert für Batchjobs auf eine Zahl, die kleiner als die Anzahl der vCPUs ist.
Bei Streamingjobs sollten Sie den Wert zuerst auf die Hälfte des Standardwerts reduzieren. Wenn das Problem dadurch nicht behoben wird, halbieren Sie den Wert weiter und beobachten Sie die Ergebnisse bei jedem Schritt. Wenn Sie beispielsweise Python verwenden, probieren Sie die Werte 6, 3 und 1 aus.
Maschinentyp mit mehr Arbeitsspeicher pro vCPU verwenden.
Verwenden Sie eine der folgenden Methoden, um einen Worker mit mehr Arbeitsspeicher pro vCPU auszuwählen.
- Verwenden Sie einen Maschinentyp mit großem Arbeitsspeicher in der Maschinenfamilie für allgemeine Zwecke. Maschinentypen mit großem Speicher haben einen höheren Arbeitsspeicher pro vCPU als Standardmaschinentypen. Bei einem Maschinentyp mit großem Speicher wird der für jeden Worker verfügbare Arbeitsspeicher erhöht und der pro Thread verfügbare Speicher, da die Anzahl der vCPUs gleich bleibt. Daher kann die Verwendung eines Maschinentyps mit großem Speicher eine kostengünstige Möglichkeit sein, einen Worker mit mehr Arbeitsspeicher pro vCPU auszuwählen.
- Für mehr Flexibilität bei der Angabe der Anzahl der vCPUs und der Größe des Arbeitsspeichers können Sie Folgendes verwenden: Sie können einen benutzerdefinierten Maschinentyp verwenden. Mit benutzerdefinierten Maschinentypen können Sie den Speicher um 256-MB-Schritte erhöhen. Diese Maschinentypen unterscheiden sich preislich von den standardmäßigen Maschinentypen.
- Bei einigen Maschinenfamilien können Sie Erweiterter Arbeits-Speicher-benutzerdefinierten Maschinentypen verwenden. Der erweiterte Speicher ermöglicht ein höheres Verhältnis von Arbeitsspeicher zu vCPU. Die Kosten sind höher.
Verwenden Sie die folgende Pipelineoption, um Worker-Typen festzulegen. Weitere Informationen finden Sie unter Pipelineoptionen festlegen und Pipelineoptionen.
Java
Verwenden Sie die Pipelineoption --workerMachineType.
Python
Verwenden Sie die Pipelineoption --machine_type.
Go
Verwenden Sie die Pipelineoption --worker_machine_type.
Nur einen Apache Beam SDK-Prozess verwenden
Bei Python-Streamingpipelines und Python-Pipelines, die Runner v2 verwenden, können Sie erzwingen, dass Dataflow nur einen Apache Beam SDK-Prozess pro Worker startet. Bevor Sie diese Option ausprobieren können, versuchen Sie zuerst, das Problem mit den anderen Methoden zu beheben. Verwenden Sie die folgende Pipeline-Option, um Dataflow-Worker-VMs so zu konfigurieren, dass nur ein containerisierter Python-Prozess gestartet wird:
--experiments=no_use_multiple_sdk_containers
Bei dieser Konfiguration erstellen Python-Pipelines einen Apache Beam SDK-Prozess pro Worker. Diese Konfiguration verhindert, dass die gemeinsam genutzten Objekte und Daten für jeden Apache Beam SDK-Prozess mehrfach repliziert werden. Es schränkt jedoch die effiziente Nutzung der auf dem Worker verfügbaren Rechenressourcen ein.
Das Reduzieren der Anzahl der Apache Beam SDK-Prozesse auf einen reduziert nicht zwingend Die Gesamtzahl der auf dem Worker gestarteten Threads. Darüber hinaus kann das Ausführen aller Threads in einem einzelnen Apache Beam SDK-Prozess zu einer langsamen Verarbeitung führen oder dazu führen, dass die Pipeline hängen bleibt. Daher müssen Sie möglicherweise die Anzahl der Threads reduzieren, wie im Abschnitt Anzahl der Threads reduzieren auf dieser Seite beschrieben wird.
Sie können auch erzwingen, dass Worker nur einen Apache Beam SDK-Prozess verwenden, indem Sie einen Maschinentyp mit nur einer vCPU verwenden.
Grundlegendes zur Dataflow-Speichernutzung
Zur Behebung von Fehlern bei unzureichendem Speicher ist es hilfreich zu verstehen, wie Dataflow-Pipelines Speicher verwenden.
Wenn Dataflow eine Pipeline ausführt, wird die Verarbeitung auf mehrere Compute Engine-VMs (VMs) verteilt, die häufig als Worker bezeichnet werden.
Worker verarbeiten Arbeitselemente aus dem Dataflow-Dienst und delegieren die Arbeitselemente an Apache Beam SDK-Prozesse. Ein Apache Beam SDK-Prozess erstellt Instanzen von DoFns. DoFn ist eine Apache Beam SDK-Klasse, die eine verteilte Verarbeitungsfunktion definiert.
Dataflow startet mehrere Threads auf jedem Worker und der Arbeitsspeicher eines jeden Workers ist für alle Threads freigegeben. Ein Thread ist eine einzelne ausführbare Aufgabe, die in einem größeren Prozess ausgeführt wird. Die Standardanzahl der Threads hängt von mehreren Faktoren ab und variiert zwischen Batch- und Streamingjobs.
Wenn Ihre Pipeline mehr Arbeitsspeicher benötigt, als standardmäßig auf den Workern verfügbar ist, kann es zu Fehlern kommen, wenn der Speicher nicht ausreicht.
Dataflow-Pipelines verwenden primär den Worker-Arbeitsspeicher auf drei Arten:
Operativer Worker-Speicher
Dataflow-Worker benötigen Arbeitsspeicher für ihre Betriebssysteme und System-Prozesse. Die Worker-Speichernutzung ist in der Regel nicht größer als 1 GB. Die Nutzung beträgt normalerweise weniger als 1 GB.
- Verschiedene Prozesse auf dem Worker nutzen Speicher, um sicherzustellen, dass Ihre Pipeline funktioniert. Für jeden dieser Prozesse ist möglicherweise ein wenig Arbeitsspeicher für den Vorgang reserviert.
- Wenn Ihre Pipeline keine Streaming Engine verwendet, nutzen zusätzliche Worker-Prozesse Speicher.
SDK-Prozessspeicher
Apache Beam SDK-Prozesse können Objekte und Daten erstellen, die von Threads innerhalb des Prozesses gemeinsam genutzt werden. Diese Prozesse werden auf dieser Seite als freigegebene SDK-Objekte und -Daten bezeichnet. Die Arbeitsspeichernutzung aus diesen freigegebenen SDK-Objekten und -Daten wird als SDK-Prozessspeicher bezeichnet. Die folgende Liste enthält Beispiele für freigegebene SDK-Objekte und -Daten:
- Nebeneingaben
- Modelle für maschinelles Lernen
- In-Memory-Singleton-Objekte
- Python-Objekte, die mit dem
apache_beam.utils.shared-Modul erstellt wurden - Daten, die aus externen Quellen wie Cloud Storage oder BigQuery geladen wurden
Streamingjobs, die keine Streaming Engine-Nebeneingaben im Speicher verwenden. Bei Java- und Go-Pipelines hat jeder Worker eine Kopie der Nebeneingabe. Bei Python-Pipelines enthält jeder Apache Beam SDK-Prozess eine Kopie der Nebeneingabe.
Streamingjobs, die Streaming Engine verwenden, haben eine Größenbeschränkung von 80 MB für Nebeneingaben. Nebeneingaben werden außerhalb des Worker-Arbeitsspeichers gespeichert.
Die Speichernutzung von freigegebenen SDK-Objekten und -Daten steigt linear mit der Anzahl der Apache Beam SDK-Prozesse. In Java- und Go-Pipelines wird ein Apache Beam SDK-Prozess gestartet pro Worker. In Python-Pipelines wird ein Apache Beam SDK-Prozess pro vCPU gestartet. Freigegebene Objekte und Daten des SDK werden von Threads innerhalb desselben Apache Beam SDK-Prozesses wiederverwendet.
DoFn Arbeitsspeichernutzung
DoFn ist eine Apache Beam SDK-Klasse, die eine verteilte Verarbeitungsfunktion definiert.
Jeder Worker kann gleichzeitige DoFn-Instanzen ausführen. In jedem Thread wird eine DoFn-Instanz ausgeführt. Bei der Bewertung der Gesamtspeichernutzung, der Berechnung der Arbeitssatzgröße oder der Größe des Arbeitsspeichers, die eine Anwendung weiterhin benötigt, kann es hilfreich sein. Wenn beispielsweise ein einzelner DoFn maximal 5 MB Arbeitsspeicher verwendet und ein Worker 300 Threads hat, könnte die DoFn-Speicherauslastung einen Spitzenwert von 1,5 GB erreichen, also die Anzahl der Speicherbytes multipliziert mit der Anzahl der Threads. Je nachdem, wie die Worker den Arbeitsspeicher nutzen, kann ein Anstieg der Speichernutzung dazu führen, dass den Workern der Speicher ausgeht.
Es lässt sich nur schwer schätzen, wie viele Instanzen von
DoFn
von Dataflow erstellt wird. Die Anzahl hängt von verschiedenen Faktoren ab, z. B. vom SDK, dem Maschinentyp usw. Darüber hinaus kann das DoFn von mehreren Threads hintereinander verwendet werden.
Der Dataflow-Dienst garantiert weder, wie oft ein DoFn aufgerufen wird, noch garantiert er die genaue Anzahl der DoFn-Instanzen, die im Laufe einer Pipeline erstellt werden.
Die folgende Tabelle gibt jedoch einen Einblick in die Ebene der Parallelität, die Sie erwarten können, und schätzt eine Obergrenze für die Anzahl der DoFn-Instanzen.
Beam Python SDK
| Batch | Streaming ohne Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Parallelität |
1 Prozess pro vCPU 1 Thread pro Prozess 1 Thread pro vCPU
|
1 Prozess pro vCPU 12 Threads pro Prozess 12 Threads pro vCPU |
1 Prozess pro vCPU 12 Threads pro Prozess 12 Threads pro vCPU
|
Maximale Anzahl gleichzeitiger DoFn-Instanzen (Alle diese Zahlen können sich jederzeit ändern.) |
1 DoFn pro Thread
1
|
1 DoFn pro Thread
12
|
1 DoFn pro Thread
12
|
Beam Java/Go SDK
| Batch | Streaming Appliance und Streaming Engine ohne Runner v2 | Streaming Engine mit Runner v2 | |
|---|---|---|---|
| Parallelität |
1 Prozess pro Worker-VM 1 Thread pro vCPU
|
1 Prozess pro Worker-VM 300 Threads pro Prozess 300 Threads pro Worker-VM
|
1 Prozess pro Worker-VM 500 Threads pro Prozess 500 Threads pro Worker-VM
|
Maximale Anzahl gleichzeitiger DoFn-Instanzen (Alle diese Zahlen können sich jederzeit ändern.) |
1 DoFn pro Thread
1
|
1 DoFn pro Thread
300
|
1 DoFn pro Thread
500
|
Wenn Sie beispielsweise das Python SDK mit einem n1-standard-2-Dataflow-Worker verwenden, gilt Folgendes:
- Batchjobs: Dataflow startet einen Prozess pro vCPU (in diesem Fall zwei). Jeder Prozess verwendet einen Thread und in jedem Thread wird eine
DoFn-Instanz erstellt. - Streaming-Jobs mit Streaming Engine: Dataflow startet einen Prozess pro vCPU (insgesamt zwei). Jeder Prozess kann jedoch bis zu 12 Threads mit jeweils einer eigenen DoFn-Instanz erstellen.
Wenn Sie komplexe Pipelines entwerfen, ist es wichtig, den DoFn-Lebenszyklus zu verstehen.
Achten Sie darauf, dass Ihre DoFn-Funktionen serialisierbar sind, und vermeiden Sie es, das Elementargument direkt in den Funktionen zu ändern.
Wenn Sie eine mehrsprachige Pipeline haben und mehr als ein Apache Beam SDK auf dem Worker ausgeführt wird, verwendet der Worker einen möglichst niedrigen Grad an Thread-pro-Prozess-Parallelität.
Unterschiede zwischen Java, Go und Python
Prozesse und Arbeitsspeicher werden in Java, Go und Python unterschiedlich verwaltet. Die Vorgehensweise bei der Behebung von Fehlern, bei denen der Speicher nicht ausreicht, hängt daher davon ab, ob Ihre Pipeline Java, Go oder Python verwendet.
Java- und Go-Pipelines
In Java- und Go-Pipelines:
- Jeder Worker startet einen Apache Beam SDK-Prozess.
- Freigegebene SDK-Objekte und -Daten, wie Nebeneingaben und Caches, werden unter allen Threads auf dem Worker freigegeben.
- Der von freigegebenen SDK-Objekten und -Daten verwendete Arbeitsspeicher wird normalerweise nicht basierend auf der Anzahl der vCPUs auf dem Worker skaliert.
Python-Pipelines
In Python-Pipelines:
- Jeder Worker startet einen Apache Beam SDK-Prozess pro vCPU.
- Freigegebene Objekte und Daten des SDK, wie Nebeneingaben und Caches, werden von allen Threads in jedem Apache Beam SDK-Prozess gemeinsam genutzt.
- Die Gesamtzahl der Threads auf dem Worker wird linear anhand der Anzahl der vCPUs skaliert. Folglich wächst der von gemeinsam genutzten SDK-Objekten und -Daten verwendete Arbeitsspeicher linear mit der Anzahl der vCPUs.
- Threads, die die Arbeit ausführen, werden auf Prozesse verteilt. Neue Arbeitseinheiten werden entweder einem Prozess ohne Arbeitselemente oder dem Prozess mit den wenigsten gerade zugewiesenen Arbeitselementen zugewiesen.