Después de crear y organizar tu plantilla de Dataflow, ejecútala con la consola, la API REST o la CLI de Google Cloud. Google Cloud Puedes desplegar tareas de plantillas de Dataflow desde muchos entornos, como el entorno estándar de App Engine, las funciones de Cloud Run y otros entornos con limitaciones.
Usar la Google Cloud consola
Puedes usar la Google Cloud consola para ejecutar plantillas de Dataflow personalizadas y proporcionadas por Google.
Plantillas proporcionadas por Google
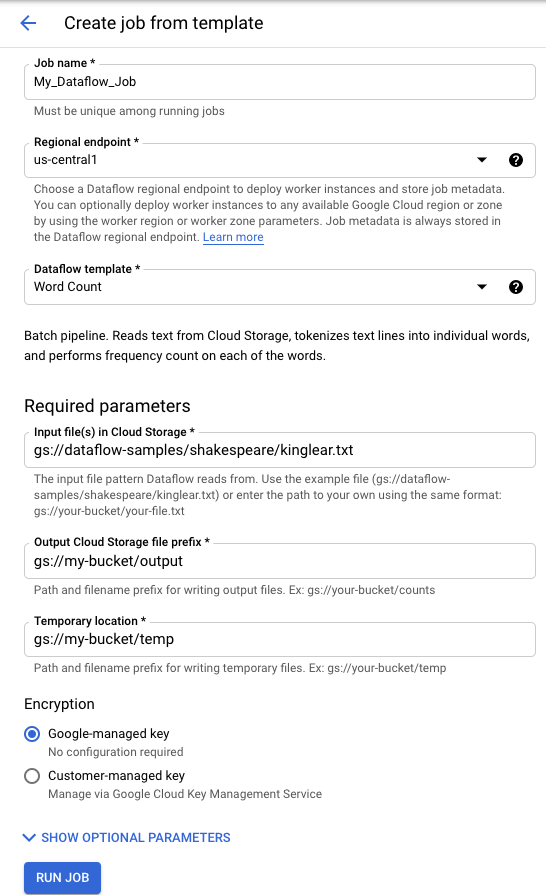
Para ejecutar una plantilla proporcionada por Google, siga estos pasos:
- Ve a la página Dataflow de la Google Cloud consola. Ir a la página Dataflow
- Haz clic en add_boxCREAR TAREA A PARTIR DE PLANTILLA.
- En el menú desplegable Plantilla de Dataflow, selecciona la plantilla proporcionada por Google que quieras ejecutar.
- Introduce un nombre de tarea en el campo Nombre de tarea.
- Introduzca los valores de los parámetros en los campos correspondientes. No necesitas la sección Parámetros adicionales cuando usas una plantilla proporcionada por Google.
- Haz clic en Ejecutar trabajo.

Plantillas personalizadas
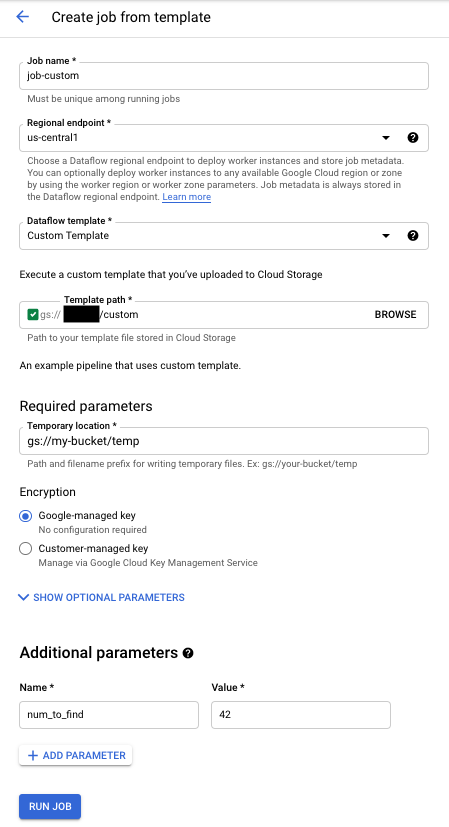
Para ejecutar una plantilla personalizada:
- Ve a la página Dataflow de la Google Cloud consola. Ir a la página Dataflow
- Haz clic en CREAR TAREA A PARTIR DE PLANTILLA.
- Selecciona Plantilla personalizada en el menú desplegable Plantilla de flujo de datos.
- Introduce un nombre de tarea en el campo Nombre de tarea.
- Introduce la ruta de Cloud Storage de tu archivo de plantilla en el campo correspondiente.
- Si tu plantilla necesita parámetros, haz clic en addAÑADIR PARÁMETRO en la sección Parámetros adicionales. Introduce el nombre y el valor del parámetro. Repite este paso con cada parámetro necesario.
- Haz clic en Ejecutar trabajo.
Utilizar la API REST
Para ejecutar una plantilla con una solicitud de API REST, envía una solicitud HTTP POST con tu ID de proyecto. Esta solicitud requiere autorización.
Consulta la referencia de la API REST para projects.locations.templates.launch para obtener más información sobre los parámetros disponibles.
Crear una tarea por lotes de plantillas personalizadas
En este ejemplo, la solicitud projects.locations.templates.launch crea una tarea por lotes a partir de una plantilla que lee un archivo de texto y escribe un archivo de texto de salida. Si la solicitud se realiza correctamente, el cuerpo de la respuesta contiene una instancia de LaunchTemplateResponse.
Modifica los siguientes valores:
- Sustituye
YOUR_PROJECT_IDpor el ID del proyecto. - Sustituye
LOCATIONpor la región de Dataflow que quieras. - Sustituye
JOB_NAMEpor el nombre de trabajo que quieras. - Sustituye
YOUR_BUCKET_NAMEpor el nombre de tu segmento de Cloud Storage. - Define
gcsPathcomo la ubicación de Cloud Storage del archivo de plantilla. - Asigna
parametersa tu lista de pares clave-valor. - Define
tempLocationen una ubicación en la que tengas permiso de escritura. Este valor es obligatorio para usar las plantillas proporcionadas por Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=gs://YOUR_BUCKET_NAME/templates/TemplateName
{
"jobName": "JOB_NAME",
"parameters": {
"inputFile" : "gs://YOUR_BUCKET_NAME/input/my_input.txt",
"output": "gs://YOUR_BUCKET_NAME/output/my_output"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Crear una tarea de streaming con una plantilla personalizada
En este ejemplo, la solicitud projects.locations.templates.launch crea una tarea de streaming a partir de una plantilla clásica que lee datos de una suscripción de Pub/Sub y los escribe en una tabla de BigQuery. Si quieres iniciar una plantilla Flex, usa projects.locations.flexTemplates.launch en su lugar. La plantilla de ejemplo es una plantilla proporcionada por Google. Puedes modificar la ruta de la plantilla para que apunte a una plantilla personalizada. Se usa la misma lógica para iniciar las plantillas proporcionadas por Google y las personalizadas. En este ejemplo, la tabla de BigQuery ya debe existir con el esquema adecuado. Si la solicitud se completa correctamente, el cuerpo de la respuesta contiene una instancia de LaunchTemplateResponse.
Modifica los siguientes valores:
- Sustituye
YOUR_PROJECT_IDpor el ID del proyecto. - Sustituye
LOCATIONpor la región de Dataflow que quieras. - Sustituye
JOB_NAMEpor el nombre de trabajo que quieras. - Sustituye
YOUR_BUCKET_NAMEpor el nombre de tu segmento de Cloud Storage. - Sustituye
GCS_PATHpor la ubicación de Cloud Storage del archivo de plantilla. La ubicación debe empezar por gs:// - Asigna
parametersa tu lista de pares clave-valor. Los parámetros que se indican son específicos de este ejemplo de plantilla. Si usas una plantilla personalizada, modifica los parámetros según sea necesario. Si usas la plantilla de ejemplo, sustituye las siguientes variables.- Sustituye
YOUR_SUBSCRIPTION_NAMEpor el nombre de tu suscripción de Pub/Sub. - Sustituye
YOUR_DATASETpor tu conjunto de datos de BigQuery yYOUR_TABLE_NAMEpor el nombre de tu tabla de BigQuery.
- Sustituye
- Define
tempLocationen una ubicación en la que tengas permiso de escritura. Este valor es obligatorio para usar las plantillas proporcionadas por Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH
{
"jobName": "JOB_NAME",
"parameters": {
"inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_SUBSCRIPTION_NAME",
"outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Actualizar un trabajo de streaming de plantilla personalizada
En este ejemplo de solicitud projects.locations.templates.launch se muestra cómo actualizar un trabajo de streaming de plantillas. Si quieres actualizar una plantilla flex, usa projects.locations.flexTemplates.launch en su lugar.
- Ejecuta el ejemplo 2: Crear una tarea de streaming con una plantilla personalizada para iniciar una tarea de plantilla de streaming.
- Envía la siguiente solicitud HTTP POST con los valores modificados:
- Sustituye
YOUR_PROJECT_IDpor el ID del proyecto. - Sustituye
LOCATIONpor la región de Dataflow de la tarea que vas a actualizar. - Sustituye
JOB_NAMEpor el nombre exacto del trabajo que quieras actualizar. - Sustituye
GCS_PATHpor la ubicación de Cloud Storage del archivo de plantilla. La ubicación debe empezar por gs:// - Asigna
parametersa tu lista de pares clave-valor. Los parámetros que se indican son específicos de este ejemplo de plantilla. Si usas una plantilla personalizada, modifica los parámetros según sea necesario. Si usas la plantilla de ejemplo, sustituye las siguientes variables.- Sustituye
YOUR_SUBSCRIPTION_NAMEpor el nombre de tu suscripción de Pub/Sub. - Sustituye
YOUR_DATASETpor tu conjunto de datos de BigQuery yYOUR_TABLE_NAMEpor el nombre de tu tabla de BigQuery.
- Sustituye
- Usa el parámetro
environmentpara cambiar los ajustes del entorno, como el tipo de máquina. En este ejemplo se usa el tipo de máquina n2-highmem-2, que tiene más memoria y CPU por trabajador que el tipo de máquina predeterminado.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH { "jobName": "JOB_NAME", "parameters": { "inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_TOPIC_NAME", "outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME" }, "environment": { "machineType": "n2-highmem-2" }, "update": true } - Sustituye
- Accede a la interfaz de monitorización de Dataflow y comprueba que se ha creado una tarea con el mismo nombre. Este trabajo tiene el estado Actualizado.
Usar las bibliotecas de cliente de las APIs de Google
Te recomendamos que utilices las bibliotecas de cliente de las APIs de Google para hacer llamadas a las APIs REST de Dataflow fácilmente. Este script de ejemplo usa la biblioteca de cliente de las APIs de Google para Python.
En este ejemplo, debes definir las siguientes variables:
project: se asigna a tu ID de proyecto.job: asigna el nombre único que quieras al trabajo.template: se define en la ubicación de Cloud Storage del archivo de plantilla.parameters: se asigna a un diccionario con los parámetros de la plantilla.
Para definir la región, incluya el parámetro location.
Para obtener más información sobre las opciones disponibles, consulta el método projects.locations.templates.launch de la referencia de la API REST de Dataflow.
Usar la CLI de gcloud
La CLI de gcloud puede ejecutar una plantilla personalizada o una proporcionada por Google con el comando gcloud dataflow jobs run. En la página de plantillas proporcionadas por Google se documentan ejemplos de cómo ejecutar plantillas proporcionadas por Google.
En los siguientes ejemplos de plantillas personalizadas, defina los valores que se indican a continuación:
- Sustituye
JOB_NAMEpor el nombre de trabajo que quieras. - Sustituye
YOUR_BUCKET_NAMEpor el nombre de tu segmento de Cloud Storage. - Define
--gcs-locationcomo la ubicación de Cloud Storage del archivo de plantilla. - Asigna a
--parametersla lista de parámetros separados por comas que se van a transferir a la tarea. No se permiten espacios entre comas y valores. - Para evitar que las VMs acepten claves SSH almacenadas en los metadatos del proyecto, usa la marca
additional-experimentscon la opción de servicioblock_project_ssh_keys:--additional-experiments=block_project_ssh_keys.
Crear una tarea por lotes de plantillas personalizadas
En este ejemplo se crea una tarea por lotes a partir de una plantilla que lee un archivo de texto y escribe un archivo de texto de salida.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters inputFile=gs://YOUR_BUCKET_NAME/input/my_input.txt,output=gs://YOUR_BUCKET_NAME/output/my_output
La solicitud devuelve una respuesta con el siguiente formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_BATCH
Crear una tarea de streaming con una plantilla personalizada
En este ejemplo se crea una tarea de streaming a partir de una plantilla que lee datos de un tema de Pub/Sub y los escribe en una tabla de BigQuery. La tabla de BigQuery ya debe existir con el esquema adecuado.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters topic=projects/project-identifier/topics/resource-name,table=my_project:my_dataset.my_table_name
La solicitud devuelve una respuesta con el siguiente formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_STREAMING
Para ver una lista completa de las marcas del comando gcloud dataflow jobs run, consulta la referencia de la CLI de gcloud.
Monitorización y solución de problemas
La interfaz de monitorización de Dataflow te permite monitorizar tus tareas de Dataflow. Si un trabajo falla, puedes consultar consejos para solucionar problemas, estrategias de depuración y un catálogo de errores habituales en la guía Solucionar problemas de tu canalización.