Dataflow 작업을 중지하려면 Google Cloud 콘솔, Cloud Shell, Google Cloud CLI가 설치된 로컬 터미널, Dataflow REST API를 사용합니다.
다음 세 가지 방법 중 하나로 Dataflow 작업을 중지할 수 있습니다.
작업을 취소합니다. 이 방법은 스트리밍 파이프라인과 일괄 파이프라인 모두에 적용됩니다. 작업을 취소하면 Dataflow 서비스에서 버퍼링된 데이터 등 데이터를 처리하지 못합니다. 자세한 내용은 작업 취소를 참조하세요.
작업을 드레이닝합니다. 이 방법은 스트리밍 파이프라인에만 적용됩니다. 작업을 드레이닝하면 Dataflow 서비스에서 버퍼링된 데이터 처리를 완료하지만 동시에 새 데이터 수집을 중단할 수 있습니다. 자세한 내용은 작업 드레이닝을 참조하세요.
작업을 강제 취소합니다. 이 방법은 스트리밍 파이프라인과 일괄 파이프라인 모두에 적용됩니다. 작업을 강제로 취소하면 Dataflow 서비스에서 버퍼링된 데이터를 포함하여 모든 데이터 처리가 즉시 중지됩니다. 강제 취소 전에 먼저 일반적인 취소를 시도해야 합니다. 강제 취소는 일반적인 취소 과정에서 중단된 작업만을 대상으로 합니다. 자세한 내용은 작업 강제 취소를 참조하세요.
작업을 취소하면 다시 시작할 수 없습니다. Flex 템플릿을 사용하지 않는 경우 취소된 파이프라인을 클론하고 클론된 파이프라인에서 새 작업을 시작할 수 있습니다.
스트리밍 파이프라인을 중지하기 전에 작업의 스냅샷을 만드는 것이 좋습니다. Dataflow 스냅샷은 스트리밍 파이프라인의 상태를 저장하므로 상태를 잃지 않고 Dataflow 작업의 새 버전을 시작할 수 있습니다. 자세한 내용은 Dataflow 스냅샷 사용을 참조하세요.
복잡한 파이프라인이 있으면 템플릿을 만들고 템플릿으로부터 작업을 실행하는 것이 좋습니다.
Dataflow 작업은 삭제할 수 없지만 완료된 작업을 보관처리할 수 있습니다. 보관처리된 작업 목록의 작업을 포함하여 완료된 모든 작업은 30일 보관 기간 후에 삭제됩니다.
Dataflow 작업 취소
작업을 취소하면 Dataflow 서비스에서 즉시 작업을 중지합니다.
작업을 취소하면 다음과 같은 작업이 발생합니다.
Dataflow 서비스가 모든 데이터 수집 및 데이터 처리를 중지합니다.
Dataflow 서비스에서 작업에 연결된 Google Cloud Platform 리소스를 삭제하기 시작합니다.
여기에는 Compute Engine 작업자 인스턴스 종료와 I/O 소스 또는 싱크에 대한 활성 연결을 종료하는 작업이 포함됩니다.
작업 취소에 대한 중요 정보
작업을 취소하면 파이프라인 처리가 즉시 중지됩니다.
작업을 취소하면 이동 중인 데이터가 손실될 수 있습니다. 이동 중인 데이터란 이미 읽었지만 파이프라인에서 아직 처리 중인 데이터를 의미합니다.
작업을 취소하기 전에 파이프라인에서 출력 싱크에 기록된 데이터는 출력 싱크에서 계속 액세스할 수 있습니다.
데이터 손실에 대한 우려가 크지 않다면 작업을 취소하여 작업과 연결된Google Cloud 리소스가 가능한 빨리 종료되도록 조치해야 합니다.
Dataflow 작업 드레이닝
작업을 드레이닝하면 Dataflow 서비스가 현재 상태로 작업을 완료합니다. 스트리밍 파이프라인을 종료할 때 데이터 손실을 방지하려면 작업을 드레이닝하는 것이 좋습니다.
작업을 드레이닝하면 다음과 같은 작업이 발생합니다.
드레이닝 요청을 수신하면 (대부분 몇 분 후에) 입력 소스에서 새 데이터를 수집하는 작업이 즉시 중단됩니다.
Dataflow 서비스는 기존 리소스(예: 작업자 인스턴스)를 유지하여 파이프라인의 버퍼링된 데이터를 처리하고 기록합니다.
보류 중인 모든 처리 및 쓰기 작업이 완료되면 Dataflow 서비스가 작업과 관련된 Google Cloud 리소스를 종료합니다.
작업을 드레이닝하기 위해 Dataflow는 새 입력 읽기를 중지하고, 소스를 이벤트 타임스탬프로 무한으로 표시한 다음, 파이프라인을 통해 무한 타임스탬프를 전파합니다. 따라서 배수 중인 파이프라인에는 무한 워터마크가 있을 수 있습니다.
작업 드레이닝에 대한 중요 정보
일괄 파이프라인에는 작업 드레이닝이 지원되지 않습니다.
파이프라인에서는 모든 처리 및 쓰기가 완료될 때까지 관련된Google Cloud 리소스를 유지보수하는 비용이 계속 발생합니다
드레이닝되는 파이프라인을 업데이트할 수 있습니다. 파이프라인이 중단된 경우 문제를 일으키는 오류를 수정하는 코드로 파이프라인을 업데이트하면 데이터 손실 없이 성공적으로 드레이닝할 수 있습니다.
현재 드레이닝 중인 작업을 취소할 수 있습니다.
파이프라인에 많은 양의 버퍼링된 데이터가 있는 경우 등에는 작업을 드레이닝하는 데 상당한 시간이 소요될 수 있습니다.
스트리밍 파이프라인에 분할 가능한 DoFn이 포함된 경우에는 드레이닝 옵션을 실행하기 전에 결과를 잘라야 합니다. 분할 가능한 DoFn 자르기에 대한 자세한 내용은 Apache Beam 문서를 참조하세요.
경우에 따라 Dataflow 작업에서 드레이닝 작업을 완료하지 못할 수 있습니다. 작업 로그를 참조하여 근본 원인을 확인하고 적절한 조치를 취할 수 있습니다.
데이터 보관
Dataflow 스트리밍은 작업자 재시작을 허용하며 오류가 발생해도 스트리밍 작업이 실패하지 않습니다. 대신 Dataflow 서비스는 작업 취소 또는 다시 시작과 같은 작업을 수행할 때까지 재시도됩니다. 작업을 드레이닝하면 Dataflow가 계속 재시도되어 파이프라인이 중단될 수 있습니다. 이 경우 데이터 손실 없이 성공적인 드레이닝을 사용 설정하려면 문제를 생성하는 오류를 수정하는 코드로 파이프라인을 업데이트합니다.
Dataflow는 Dataflow 서비스에서 메시지를 영구 커밋할 때까지 메시지를 확인하지 않습니다. 예를 들어 Kafka를 사용하는 경우 이 프로세스를 통해 Kafka에서 Dataflow로 메시지 소유권을 안전하게 전달하여 데이터 손실 위험을 제거할 수 있습니다.
중단된 작업
- 드레이닝해도 중단된 파이프라인은 수정되지 않습니다. 데이터 이동이 차단되면 파이프라인은 드레이닝 명령어 후에도 중단된 상태로 유지됩니다. 중단된 파이프라인을 해결하려면 업데이트 명령어를 사용하여 문제를 일으키는 오류를 해결하는 코드로 파이프라인을 업데이트합니다. 중단된 작업을 취소할 수도 있지만 작업을 취소하면 데이터가 손실될 수 있습니다.
타이머
스트리밍 파이프라인 코드에 루핑 타이머가 포함된 경우 작업이 느려지거나 드레이닝되지 않을 수 있습니다. 모든 타이머가 완료될 때까지 드레이닝이 끝나지 않으므로 무한 루프 타이머가 있는 파이프라인은 드레이닝을 완료하지 않습니다.
Dataflow에서 즉시 실행하지 않고 모든 처리 시간 타이머가 완료될 때까지 기다리므로 드레이닝 속도가 느려질 수 있습니다.
작업 드레이닝의 효과
스트리밍 파이프라인을 드레이닝하면 Dataflow가 진행 중인 모든 기간을 즉시 종료하고 모든 트리거를 실행합니다.
시스템은 드레이닝 작업에서 처리되지 않은 시간 기반 기간이 종료될 때까지 기다리지 않습니다.
예를 들어 작업을 드레이닝할 때 2시간 분량의 파이프라인이 10분만 진행된 경우 Dataflow는 남은 시간을 기다리지 않습니다. 이 경우 기간이 즉시 종료되고 부분적인 결과만 표시됩니다. Dataflow는 데이터 워터마크를 무한으로 올려 열린 기간을 종료합니다. 이 기능은 커스텀 데이터 소스에서도 작동합니다.
커스텀 데이터 소스 클래스를 사용하는 파이프라인을 드레이닝하면 Dataflow는 새 데이터의 실행 요청을 중지하고, 데이터 워터마크를 무한으로 올리고, 마지막 체크포인트에서 소스의 finalize() 메서드를 호출합니다.
드레이닝을 수행하면 일부 기간이 채워질 수 있습니다. 이 경우 드레이닝 파이프라인을 다시 시작하면 동일한 기간이 다시 실행되어 데이터에 문제가 발생할 수 있습니다. 예를 들어 다음 시나리오에서는 파일 이름이 충돌하고 데이터가 덮어쓸 수 있습니다.
오후 12시 34분에 시간별 기간으로 파이프라인을 드레이닝하면 오후 12:00~1:00 기간에는 해당 기간의 처음 34분 이내에 실행된 데이터만 종료됩니다. 오후 12시 34분 이후에는 파이프라인에서 새 데이터를 읽지 않습니다.
그런 다음 파이프라인을 즉시 다시 시작하면 오후 12:35~1:00까지 읽은 데이터로만 오후 12:00~1:00 기간이 다시 트리거됩니다. 중복이 전송되지 않지만 파일 이름이 반복되면 데이터가 덮어쓰기됩니다.
Google Cloud 콘솔에서 파이프라인 변환의 세부정보를 볼 수 있습니다. 다음 다이어그램에서는 프로세스 내 드레이닝 작업의 효과를 보여줍니다. 워터마크는 최댓값으로 설정되어 있습니다.
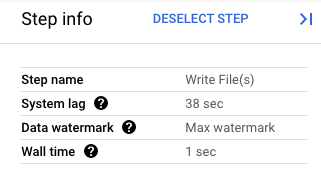
그림 1. 드레이닝 작업의 단계 뷰
Dataflow 작업 강제 취소
다른 방법으로 작업을 취소할 수 없는 경우에만 강제 취소를 사용하세요. 강제 취소는 모든 리소스를 정리하지 않고 작업을 종료합니다. 강제 취소를 반복적으로 사용하면 유출된 리소스가 누적될 수 있으며 유출된 리소스는 할당량을 사용합니다.
작업을 강제 취소하면 Dataflow 서비스에서 즉시 작업을 중지하여 Dataflow 작업으로 생성된 모든 VM이 노출됩니다. 일반 취소는 강제 취소 최소 30분 전에 시도해야 합니다.
작업을 강제 취소하면 다음과 같은 작업이 발생합니다.
- Dataflow 서비스가 모든 데이터 수집 및 데이터 처리를 중지합니다.
작업 강제 취소에 대한 중요 정보
작업을 강제 취소하면 파이프라인 처리가 즉시 중지됩니다.
작업 강제 취소는 일반 취소 프로세스에서 중단된 작업만을 대상으로 합니다.
Dataflow 작업으로 생성된 모든 작업자 인스턴스가 반드시 해제되지는 않으므로 작업자 인스턴스가 유출될 수 있습니다. 유출된 작업자 인스턴스는 작업 비용에 영향을 미치지 않지만 할당량을 사용할 수 있습니다. 작업 취소가 완료되면 이러한 리소스를 삭제할 수 있습니다.
Dataflow Prime 작업의 경우 유출된 VM을 보거나 삭제할 수 없습니다. 대부분의 경우 이러한 VM은 문제를 일으키지 않습니다. 그러나 유출된 VM으로 인해 VM 할당량 사용과 같은 문제가 발생할 경우 지원팀에 문의하세요.
Dataflow 작업 중지
작업을 중지하기 전에 작업 취소, 드레이닝 또는 강제 취소가 미치는 영향을 파악해야 합니다.
콘솔
Dataflow 작업 페이지로 이동합니다.
중지할 작업을 클릭합니다.
작업을 중지하려면 작업 상태가 실행 중이어야 합니다.
작업 세부정보 페이지에서 중지를 클릭합니다.
다음 중 하나를 수행합니다.
일괄 파이프라인의 경우 취소 또는 강제 취소를 클릭합니다.
스트리밍 파이프라인의 경우 취소, 드레이닝 또는 강제 취소를 클릭합니다.
선택을 확인하려면 작업 중지를 클릭합니다.
gcloud
Dataflow 작업을 드레이닝하거나 취소하려면 Cloud Shell의 gcloud dataflow jobs 명령어 또는 gcloud CLI를 통해 설치된 로컬 터미널을 사용하면 됩니다.
셸에 로그인합니다.
현재 실행 중인 Dataflow 작업의 작업 ID를 나열한 후 중지할 작업의 작업 ID를 기록해 둡니다.
gcloud dataflow jobs list--region플래그를 설정하지 않으면 사용 가능한 모든 리전의 Dataflow 작업이 표시됩니다.다음 중 하나를 수행합니다.
스트리밍 작업을 드레이닝하려면 다음 명령어를 실행합니다.
gcloud dataflow jobs drain JOB_IDJOB_ID를 앞에서 복사한 작업 ID로 바꿉니다.일괄 또는 스트리밍 작업을 취소하려면 다음 명령어를 실행합니다.
gcloud dataflow jobs cancel JOB_IDJOB_ID를 앞에서 복사한 작업 ID로 바꿉니다.일괄 또는 스트리밍 작업을 강제 취소하려면 다음 명령어를 실행합니다.
gcloud dataflow jobs cancel JOB_ID --forceJOB_ID를 앞에서 복사한 작업 ID로 바꿉니다.
API
Dataflow REST API를 사용하여 작업을 취소하거나 드레이닝하려면 projects.locations.jobs.update 또는 projects.jobs.update를 선택하면 됩니다.
요청 본문에서 선택한 API의 작업 인스턴스에 있는 requestedState 필드에 필요한 작업 상태를 전달합니다.
중요: projects.locations.jobs.update를 사용하는 것이 좋습됩니다. projects.jobs.update는 us-central1에서 실행하는 작업의 상태만 업데이트하기 때문입니다.
작업을 취소하려면 작업 상태를
JOB_STATE_CANCELLED로 설정합니다.작업을 드레이닝하려면 작업 상태를
JOB_STATE_DRAINED로 설정합니다.작업을 강제 취소하려면
"force_cancel_job": "true"라벨을 사용하여 작업 상태를JOB_STATE_CANCELLED로 설정합니다. 요청 본문은 다음과 같습니다.{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Dataflow 작업 완료 감지
작업 취소나 드레이닝이 완료된 시점을 감지하려면 다음 방법 중 하나를 사용합니다.
- Cloud Composer와 같은 워크플로 조정 서비스를 사용하여 Dataflow 작업을 모니터링합니다.
- 파이프라인이 완료될 때까지 태스크가 차단되도록 파이프라인을 동기식으로 실행합니다. 자세한 내용은 파이프라인 옵션 설정의 실행 모드 제어를 참조하세요.
Google Cloud CLI의 명령줄 도구를 사용하여 작업 상태를 폴링합니다. 프로젝트의 모든 Dataflow 작업 목록을 가져오려면 셸이나 터미널에서 다음 명령어를 실행합니다.
gcloud dataflow jobs list출력에는 각 작업의 작업 ID, 이름, 상태(
STATE), 기타 정보가 표시됩니다. 자세한 내용은 Google Cloud CLI를 사용하여 작업 나열을 참조하세요.
완료된 Dataflow 작업 보관처리
Dataflow 작업을 보관처리하면 콘솔에 있는 Dataflow 작업 페이지의 작업 목록에서 작업이 삭제됩니다. 작업이 보관처리된 작업 목록으로 이동합니다. 다음 상태의 작업이 포함된 완료된 작업만 보관처리할 수 있습니다.
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
이러한 상태 확인에 대한 자세한 내용은 Dataflow 작업 완료 감지를 참조하세요.
작업을 보관처리할 때의 문제 해결 정보는 "Dataflow 오류 문제 해결"에서 작업 보관처리 오류를 참조하세요.
모든 보관처리된 작업은 30일 보관 기간 후에 삭제됩니다.
작업 보관처리
Dataflow 작업 페이지의 기본 작업 목록에서 완료된 작업을 삭제하려면 다음 단계를 수행합니다.
콘솔
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
Dataflow 작업 목록이 상태와 함께 표시됩니다.
작업을 선택합니다.
작업 세부정보 페이지에서 보관처리를 클릭합니다. 작업이 완료되지 않았으면 보관처리 옵션을 사용할 수 없습니다.
REST
API를 사용하여 작업을 보관처리하려면 projects.locations.jobs.update 메서드를 사용합니다.
이 요청에서는 업데이트된 JobMetadata 객체를 지정해야 합니다. JobMetadata.userDisplayProperties 객체에서 키-값 쌍 "archived":"true"를 사용합니다.
업데이트된 JobMetadata 객체 외에도 API 요청에는 해당 요청 URL에 updateMask 쿼리 매개변수가 포함되어야 합니다.
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID입니다.
- REGION: Dataflow 리전입니다.
- JOB_ID: Dataflow 작업의 ID입니다.
HTTP 메서드 및 URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
JSON 요청 본문:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "true"
}
}
}
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "true"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
gcloud
이 명령어는 단일 작업을 보관처리합니다. 작업을 보관처리할 수 있으려면 종료 상태여야 합니다. 그렇지 않으면 요청이 거부됩니다. 명령어를 보낸 후 실행할지 확인해야 합니다.
아래의 명령어 데이터를 사용하기 전에 다음을 바꿉니다.
JOB_ID: 보관처리하려는 Dataflow 작업의 ID입니다.REGION: 선택사항. 작업의 Dataflow 리전입니다.
다음 명령어를 실행합니다.
Linux, macOS 또는 Cloud Shell
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows(PowerShell)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows(cmd.exe)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
다음과 비슷한 응답이 표시됩니다.
Archived job [JOB_ID].
createTime: '2025-06-29T11:00:02.432552Z'
currentState: JOB_STATE_DONE
currentStateTime: '2025-06-29T11:04:25.125921Z'
id: JOB_ID
jobMetadata:
userDisplayProperties:
archived: 'true'
projectId: PROJECT_ID
startTime: '2025-06-29T11:00:02.432552Z'
보관처리된 작업 보기 및 복원
Dataflow 작업 페이지에서 보관처리된 작업을 보거나 보관처리된 작업을 기본 작업 목록으로 복원하려면 다음 단계를 수행합니다.
콘솔
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
보관처리됨 전환 버튼을 클릭합니다. 보관처리된 Dataflow 작업 목록이 표시됩니다.
작업을 선택합니다.
Dataflow 작업 페이지에서 작업을 기본 작업 목록으로 복원하려면 작업 세부정보 페이지에서 복원을 클릭합니다.
REST
API를 사용하여 보관처리된 작업을 복원하려면 projects.locations.jobs.update 메서드를 사용합니다.
이 요청에서는 업데이트된 JobMetadata 객체를 지정해야 합니다. JobMetadata.userDisplayProperties 객체에서 키-값 쌍 "archived":"false"를 사용합니다.
업데이트된 JobMetadata 객체 외에도 API 요청에는 해당 요청 URL에 updateMask 쿼리 매개변수가 포함되어야 합니다.
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID입니다.
- REGION: Dataflow 리전입니다.
- JOB_ID: Dataflow 작업의 ID입니다.
HTTP 메서드 및 URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
JSON 요청 본문:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "false"
}
}
}
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "false"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
다음 단계
- Dataflow REST API 살펴보기
- Google Cloud 콘솔에서 Dataflow 모니터링 인터페이스 살펴보기
- 파이프라인 업데이트 자세히 알아보기