To stop a Dataflow job, use either the Google Cloud console, Cloud Shell, a local terminal installed with the Google Cloud CLI, or the Dataflow REST API.
You can stop a Dataflow job in one of the following three ways:
Cancel a job. This method applies to both streaming pipelines and batch pipelines. Canceling a job stops the Dataflow service from processing any data, including buffered data. For more information, see Cancel a job.
Drain a job. This method applies only to streaming pipelines. Draining a job enables the Dataflow service to finish processing the buffered data while simultaneously ceasing the ingestion of new data. For more information, see Drain a job.
Force cancel a job. This method applies to both streaming pipelines and batch pipelines. Force canceling a job immediately stops the Dataflow service from processing any data, including buffered data. Before force canceling, you must first attempt a regular cancel. Force canceling is only intended for jobs that have become stuck in the regular canceling process. For more information, see Force cancel a job.
When you cancel a job, you can't restart it. If you're not using Flex Templates, you can clone the cancelled pipeline and start a new job from the cloned pipeline.
Before stopping a streaming pipeline, consider creating a snapshot of the job. Dataflow snapshots save the state of a streaming pipeline, so you can start a new version of your Dataflow job without losing state. To learn more, see Using Dataflow snapshots.
If you have a complex pipeline, consider creating a template and running the job from the template.
You can't delete Dataflow jobs, but you can archive completed jobs. All completed jobs, including jobs in the archived jobs list, are deleted after a 30 day retention period.
Cancel a Dataflow job
When you cancel a job, the Dataflow service stops the job immediately.
The following actions occur when you cancel a job:
The Dataflow service halts all data ingestion and data processing.
The Dataflow service begins cleaning up the Google Cloud Platform resources that are attached to your job.
These resources might include shutting down Compute Engine worker instances and closing active connections to I/O sources or sinks.
Important information about canceling a job
Canceling a job immediately halts the processing of the pipeline.
You might lose in-flight data when you cancel a job. In-flight data refers to data that is already read but is still being processed by the pipeline.
Data that's written from the pipeline to an output sink before you cancelled the job might still be accessible on your output sink.
If data loss is not a concern, canceling your job ensures that the Google Cloud resources that are associated with your job are shut down as soon as possible.
Drain a Dataflow job
When you drain a job, the Dataflow service finishes your job in its current state. If you want to prevent data loss as you bring down your streaming pipelines, the best option is to drain your job.
The following actions occur when you drain a job:
Your job stops ingesting new data from input sources soon after receiving the drain request (typically within a few minutes).
The Dataflow service preserves any existing resources, such as worker instances, to finish processing and writing any buffered data in your pipeline.
When all pending processing and write operations are complete, the Dataflow service shuts down Google Cloud resources that are associated with your job.
To drain your job, Dataflow stops reading new input, marks the source with an event timestamp at infinity, and then propagates infinity timestamps through the pipeline. Therefore, pipelines in the process of draining might have an infinite watermark.
Important information about draining a job
Draining a job is not supported for batch pipelines.
Your pipeline continues to incur the cost of maintaining any associated Google Cloud resources until all processing and writing is finished.
You can update a pipeline that is being drained. If your pipeline is stuck, updating the pipeline with code that fixes the error that is creating the problem enables a successful drain without data loss.
You can cancel a job that is currently draining.
Draining a job can take a significant amount of time to complete, such as when your pipeline has a large amount of buffered data.
If your streaming pipeline includes a Splittable DoFn, you must truncate the result before running the drain option. For more information about truncating Splittable DoFns, see the Apache Beam documentation.
In some cases, a Dataflow job might be unable to complete the drain operation. You can consult the job logs to determine the root cause and take appropriate action.
Data retention
Dataflow streaming is tolerant to workers restarting and doesn't fail streaming jobs when errors occur. Instead, the Dataflow service retries until you take an action such as canceling or restarting the job. When you drain the job, Dataflow continues to retry, which can lead to stuck pipelines. In this situation, to enable a successful drain without data loss, update the pipeline with code that fixes the error that is creating the problem.
Dataflow doesn't acknowledge messages until the Dataflow service durably commits them. For example, with Kafka, you can view this process as a safe handoff of ownership of the message from Kafka to Dataflow, eliminating the risk of data loss.
Stuck jobs
- Draining doesn't fix stuck pipelines. If data movement is blocked, the pipeline remains stuck after the drain command. To address a stuck pipeline, use the update command to update the pipeline with code that resolves the error that is creating the problem. You can also cancel stuck jobs, but canceling jobs might result in data loss.
Timers
If your streaming pipeline code includes a looping timer, the job might be slow or unable to drain. Because draining doesn't finish until all timers complete, pipelines with infinite looping timers never finish draining.
Dataflow waits until all processing-time timers complete instead of firing them right away, which might result in slow drains.
Effects of draining a job
When you drain a streaming pipeline, Dataflow immediately closes any in-process windows and fires all triggers.
The system doesn't wait for any outstanding time-based windows to finish in a drain operation.
For example, if your pipeline is ten minutes into a two-hour window when you drain the job, Dataflow doesn't wait for the remainder of the window to finish. It closes the window immediately with partial results. Dataflow causes open windows to close by advancing the data watermark to infinity. This functionality also works with custom data sources.
When draining a pipeline that uses a custom data source class,
Dataflow stops issuing requests for new data, advances the data
watermark to infinity, and calls your source's finalize() method on the last
checkpoint.
Draining can result in partially filled windows. In that case, if you restart the drained pipeline, the same window might fire a second time, which can cause issues with your data. For example, in the following scenario, files might have conflicting names, and data might be overwritten:
If you drain a pipeline with hourly windowing at 12:34 PM, the 12:00 PM to 1:00 PM window closes with only the data that fired within the first 34 minutes of the window. The pipeline doesn't read new data after 12:34 PM.
If you then immediately restart the pipeline, the 12:00 PM to 1:00 PM window is triggered again, with only the data that was read from 12:35 PM to 1:00 PM. No duplicates are sent, but if a filename is repeated, data is overwritten.
In the Google Cloud console, you can view the details of your pipeline's transforms. The following diagram shows the effects of an in-process drain operation. Note that the watermark is advanced to the maximum value.
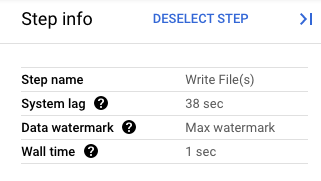
Figure 1. A step view of a drain operation.
Force cancel a Dataflow job
Use force cancel only when you're unable to cancel your job using other methods. Force cancel terminates your job without cleaning up all of the resources. If you use force cancel repeatedly, leaked resources might accumulate, and leaked resources use your quota.
When you force cancel a job, the Dataflow service stops the job immediately, leaking any VMs the Dataflow job created. Regular cancel must be attempted at least 30 minutes before force canceling.
The following actions occur when you force cancel a job:
- The Dataflow service halts all data ingestion and data processing.
Important information about force canceling a job
Force canceling a job immediately halts the processing of the pipeline.
Force canceling a job is only intended for jobs that have become stuck in the regular canceling process.
Any worker instances that the Dataflow job created are not necessarily released, which might result in leaked worker instances. Leaked worker instances don't contribute to job costs but they might use your quota. After the job cancellation completes, you can delete these resources.
For Dataflow Prime jobs, you can't see or delete the leaked VMs. In most cases, these VMs don't create issues. However, if the leaked VMs cause problems, such as consuming your VM quota, contact support.
Stop a Dataflow job
Before stopping a job, you must understand the effects of canceling, draining, or force canceling a job.
Console
Go to the Dataflow Jobs page.
Click the job that you want to stop.
To stop a job, the status of the job must be running.
In the job details page, click Stop.
Do one of the following:
For a batch pipeline, click Cancel or Force Cancel.
For a streaming pipeline, click either Cancel, Drain or Force Cancel.
To confirm your choice, click Stop Job.
gcloud
To either drain or cancel a Dataflow job,
you can use the gcloud dataflow jobs command
in the Cloud Shell or a local terminal installed with the gcloud CLI.
Log in to your shell.
List the job IDs for the Dataflow jobs that are currently running, and then note the job ID for the job that you want to stop:
gcloud dataflow jobs listIf the
--regionflag is not set, Dataflow jobs from all available regions are displayed.Do one of the following:
To drain a streaming job:
gcloud dataflow jobs drain JOB_IDReplace
JOB_IDwith the job ID that you copied earlier.To cancel a batch or streaming job:
gcloud dataflow jobs cancel JOB_IDReplace
JOB_IDwith the job ID that you copied earlier.To force cancel a batch or streaming job:
gcloud dataflow jobs cancel JOB_ID --forceReplace
JOB_IDwith the job ID that you copied earlier.
API
To cancel or drain a job using the
Dataflow REST API,
you can choose either
projects.locations.jobs.update
or projects.jobs.update.
In the request body,
pass the required job state
in the requestedState field of the job instance of the chosen API.
Important: Using projects.locations.jobs.update
is recommended, as projects.jobs.update only allows updating the state of jobs running in us-central1.
To cancel the job, set the job state to
JOB_STATE_CANCELLED.To drain the job, set the job state to
JOB_STATE_DRAINED.To force cancel the job, set the job state to
JOB_STATE_CANCELLEDwith the label"force_cancel_job": "true". The request body is:{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Detect Dataflow job completion
To detect when the job cancellation or draining has completed, use one of the following methods:
- Use a workflow orchestration service such as Cloud Composer to monitor your Dataflow job.
- Run the pipeline synchronously so that tasks are blocked until pipeline completion. For more information, see Controlling execution modes in Setting pipeline options.
Use the command-line tool in the Google Cloud CLI to poll the job status. To get a list of all the Dataflow jobs in your project, run the following command in your shell or terminal:
gcloud dataflow jobs listThe output shows the job ID, name, status (
STATE), and other information for each job. For more information, see Use the Google Cloud CLI to list jobs.
Archive completed Dataflow jobs
When you archive a Dataflow job, the job is removed from the list of jobs in the Dataflow Jobs page in the console. The job is moved to an archived jobs list. You can only archive completed jobs, which includes jobs in the following states:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
For more information on verifying these states, see Detect Dataflow job completion.
For troubleshooting information when you are archiving jobs, see Archive job errors in "Troubleshoot Dataflow errors."
All archived jobs are deleted after a 30 day retention period.
Archive a job
Follow these steps to remove a completed job from the main jobs list on the Dataflow Jobs page.
Console
In the Google Cloud console, go to the Dataflow Jobs page.
A list of Dataflow jobs appears along with their status.
Select a job.
On the Job Details page, click Archive. If the job hasn't completed, the Archive option isn't available.
REST
To archive a job using the API, use the
projects.locations.jobs.update
method.
In this request you must specify an updated
JobMetadata
object. In the JobMetadata.userDisplayProperties object, use the key-value
pair "archived":"true".
In addition to the updated JobMetadata object, your API request must also
include the
updateMask
query parameter in the request URL:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Before using any of the request data, make the following replacements:
- PROJECT_ID: your project ID
- REGION: a Dataflow region
- JOB_ID: the ID of your Dataflow job
HTTP method and URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Request JSON body:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "true"
}
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
You should receive a JSON response similar to the following:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "true"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
gcloud
This command archives a single job. The job must be in a terminal state to be able to archive it. Otherwise, the request is rejected. After sending the command, you must confirm that you want to run it.
Before using any of the command data below, make the following replacements:
JOB_ID: The ID of the Dataflow job that you want to archive.REGION: Optional. The Dataflow region of your job.
Execute the following command:
Linux, macOS, or Cloud Shell
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (PowerShell)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (cmd.exe)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
You should receive a response similar to the following:
Archived job [JOB_ID].
createTime: '2025-06-29T11:00:02.432552Z'
currentState: JOB_STATE_DONE
currentStateTime: '2025-06-29T11:04:25.125921Z'
id: JOB_ID
jobMetadata:
userDisplayProperties:
archived: 'true'
projectId: PROJECT_ID
startTime: '2025-06-29T11:00:02.432552Z'
View and restore archived jobs
Follow these steps to view archived jobs or to restore archived jobs to the main jobs list on the Dataflow Jobs page.
Console
In the Google Cloud console, go to the Dataflow Jobs page.
Click the Archived toggle. A list of archived Dataflow jobs appears.
Select a job.
To restore the job to the main jobs list on the Dataflow Jobs page, on the Job Details page, click Restore.
REST
To restore an archived job using the API, use the
projects.locations.jobs.update
method.
In this request you must specify an updated
JobMetadata
object. In the JobMetadata.userDisplayProperties object, use the
key-value pair "archived":"false".
In addition to the updated JobMetadata object, your API request must also
include the
updateMask
query parameter in the request URL:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Before using any of the request data, make the following replacements:
- PROJECT_ID: your project ID
- REGION: a Dataflow region
- JOB_ID: the ID of your Dataflow job
HTTP method and URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Request JSON body:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "false"
}
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
You should receive a JSON response similar to the following:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "false"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
What's next
- Explore the Dataflow REST API.
- Explore the Dataflow monitoring interface in the Google Cloud console.
- Learn more about updating a pipeline.