Per arrestare un job Dataflow, utilizza la consoleGoogle Cloud , Cloud Shell, un terminale locale installato con Google Cloud CLI o l'API REST di Dataflow.
Puoi interrompere un job Dataflow in uno dei tre modi seguenti:
Annulla un job. Questo metodo si applica sia alle pipeline di streaming sia a quelle batch. L'annullamento di un job impedisce al servizio Dataflow di elaborare qualsiasi dato, inclusi quelli nel buffer. Per saperne di più, consulta la sezione Annullare un lavoro.
Svuota un job. Questo metodo si applica solo alle pipeline di streaming. L'interruzione controllata di un job consente al servizio Dataflow di terminare l'elaborazione dei dati nel buffer interrompendo contemporaneamente l'importazione di nuovi dati. Per ulteriori informazioni, vedi Svuotare un job.
Forza l'annullamento di un job. Questo metodo si applica sia alle pipeline di streaming sia a quelle batch. L'annullamento forzato di un job interrompe immediatamente l'elaborazione dei dati da parte del servizio Dataflow, inclusi i dati nel buffer. Prima di procedere con l'annullamento forzato, devi prima tentare un annullamento normale. L'annullamento forzato è destinato esclusivamente ai job bloccati nel normale processo di annullamento. Per saperne di più, consulta la sezione Forzare l'annullamento di un job.
Quando annulli un job, non puoi riavviarlo. Se non utilizzi i modelli Flex, puoi clonare la pipeline annullata e avviare un nuovo job dalla pipeline clonata.
Prima di arrestare una pipeline di streaming, valuta la possibilità di creare uno snapshot del job. Gli snapshot di Dataflow salvano lo stato di una pipeline di streaming, in modo da poter avviare una nuova versione del job Dataflow senza perdere lo stato. Per scoprire di più, consulta la sezione Utilizzo degli snapshot di Dataflow.
Se hai una pipeline complessa, valuta la possibilità di creare un modello ed eseguire il job dal modello.
Non puoi eliminare i job Dataflow, ma puoi archiviare i job completati. Tutti i job completati, inclusi quelli nell'elenco dei job archiviati, vengono eliminati dopo un periodo di conservazione di 30 giorni.
Annullamento di un job Dataflow
Quando annulli un job, il servizio Dataflow lo interrompe immediatamente.
Quando annulli un job, si verificano le seguenti azioni:
Il servizio Dataflow interrompe tutte le operazioni di importazione ed elaborazione dei dati.
Il servizio Dataflow inizia a ripulire le risorse Google Cloud collegate al tuo job.
Queste risorse potrebbero includere l'arresto delle istanze di worker Compute Engine e la chiusura delle connessioni attive alle origini o ai sink I/O.
Informazioni importanti sull'annullamento di un lavoro
L'annullamento di un job interrompe immediatamente l'elaborazione della pipeline.
Potresti perdere i dati in volo quando annulli un job. I dati in transito si riferiscono ai dati già letti, ma ancora in fase di elaborazione da parte della pipeline.
I dati scritti dalla pipeline in un sink di output prima dell'annullamento del job potrebbero essere ancora accessibili nel sink di output.
Se la perdita di dati non è un problema, l'annullamento del job garantisce che le risorseGoogle Cloud associate al job vengano arrestate il prima possibile.
Svuotare un job Dataflow
Quando svuoti un job, il servizio Dataflow lo termina nel suo stato attuale. Se vuoi evitare la perdita di dati quando disattivi le pipeline di streaming, l'opzione migliore è svuotare il job.
Quando svuoti un job, si verificano le seguenti azioni:
Il job smette di importare nuovi dati dalle origini di input poco dopo aver ricevuto la richiesta di svuotamento (in genere entro pochi minuti).
Il servizio Dataflow conserva le risorse esistenti, come le istanze worker, per completare l'elaborazione e la scrittura di tutti i dati presenti nel buffer della pipeline.
Una volta completate tutte le operazioni di elaborazione e scrittura in attesa, il servizio Dataflow arresta le risorse Google Cloud associate al job.
Per svuotare il job, Dataflow interrompe la lettura di nuovi input, contrassegna l'origine con un timestamp evento all'infinito e poi propaga i timestamp all'infinito attraverso la pipeline. Pertanto, le pipeline in fase di svuotamento potrebbero avere una filigrana infinita.
Informazioni importanti sullo svuotamento di un job
L'interruzione controllata di un job non è supportata per le pipeline batch.
La pipeline continua a sostenere i costi di manutenzione delle risorseGoogle Cloud associate fino al termine di tutte le operazioni di elaborazione e scrittura.
Puoi aggiornare una pipeline in fase di svuotamento. Se la pipeline è bloccata, l'aggiornamento con codice che corregge l'errore che sta creando il problema consente uno svuotamento riuscito senza perdita di dati.
Puoi annullare un job attualmente in esecuzione.
Il svuotamento di un job può richiedere molto tempo, ad esempio quando la pipeline contiene una grande quantità di dati memorizzati nel buffer.
Se la pipeline di streaming include una Splittable DoFn, devi troncare il risultato prima di eseguire l'opzione di svuotamento. Per ulteriori informazioni sul troncamento delle Splittable DoFn, consulta la documentazione di Apache Beam.
In alcuni casi, un job Dataflow potrebbe non essere in grado di completare l'operazione di svuotamento. Puoi consultare i log dei job per determinare la causa principale e intraprendere le azioni appropriate.
Conservazione dei dati
Lo streaming Dataflow è tollerante al riavvio dei worker e non causa errori nei job di streaming quando si verificano errori. Il servizio Dataflow riprova fino a quando non esegui un'azione, ad esempio l'annullamento o il riavvio del job. Quando svuoti il job, Dataflow continua a riprovare, il che può portare a pipeline bloccate. In questa situazione, per abilitare uno svuotamento riuscito senza perdita di dati, aggiorna la pipeline con il codice che corregge l'errore che sta creando il problema.
Dataflow non riconosce i messaggi finché il servizio Dataflow non li esegue in modo duraturo. Ad esempio, con Kafka, puoi considerare questo processo come un trasferimento sicuro della proprietà del messaggio da Kafka a Dataflow, eliminando il rischio di perdita di dati.
Job bloccati
- Lo svuotamento non risolve il problema delle pipeline bloccate. Se lo spostamento dei dati è bloccato, la pipeline rimane bloccata dopo il comando di svuotamento. Per risolvere il problema di una pipeline bloccata, utilizza il comando update per aggiornare la pipeline con il codice che risolve l'errore che sta creando il problema. Puoi anche annullare i job bloccati, ma l'annullamento potrebbe comportare la perdita di dati.
Timer
Se il codice della pipeline di streaming include un timer in loop, il job potrebbe essere lento o non essere in grado di scaricare. Poiché lo svuotamento non termina finché tutti i timer non sono completi, le pipeline con timer a ciclo infinito non terminano mai lo svuotamento.
Dataflow attende il completamento di tutti i timer del tempo di elaborazione anziché attivarli immediatamente, il che potrebbe comportare svuotamenti lenti.
Effetti dello svuotamento di un job
Quando svuoti una pipeline di streaming, Dataflow chiude immediatamente tutte le finestre in corso e attiva tutti i trigger.
Il sistema non attende il completamento di eventuali finestre temporali in sospeso in un'operazione di svuotamento.
Ad esempio, se la pipeline è a dieci minuti da una finestra di due ore quando svuoti il job, Dataflow non attende il completamento del resto della finestra. La finestra si chiude immediatamente con risultati parziali. Dataflow fa chiudere le finestre aperte facendo avanzare il watermark dei dati all'infinito. Questa funzionalità funziona anche con le origini dati personalizzate.
Quando svuota una pipeline che utilizza una classe di origine dati personalizzata,
Dataflow interrompe l'emissione di richieste di nuovi dati, porta il watermark
dei dati all'infinito e chiama il metodo finalize() dell'origine sull'ultimo
checkpoint.
Lo svuotamento può comportare finestre parzialmente riempite. In questo caso, se riavvii la pipeline svuotata, la stessa finestra potrebbe attivarsi una seconda volta, il che può causare problemi con i dati. Ad esempio, nello scenario seguente, i file potrebbero avere nomi in conflitto e i dati potrebbero essere sovrascritti:
Se svuoti una pipeline con finestre orarie alle 12:34, la finestra dalle 12:00 alle 13:00 si chiude solo con i dati attivati nei primi 34 minuti della finestra. La pipeline non legge i nuovi dati dopo le 12:34.
Se poi riavvii immediatamente la pipeline, la finestra dalle 12:00 alle 13:00 viene attivata di nuovo, con solo i dati letti dalle 12:35 alle 13:00. Non vengono inviati duplicati, ma se un nome file viene ripetuto, i dati vengono sovrascritti.
Nella console Google Cloud puoi visualizzare i dettagli delle trasformazioni della pipeline. Il seguente diagramma mostra gli effetti di un'operazione di svuotamento in corso. Tieni presente che la filigrana viene portata al valore massimo.
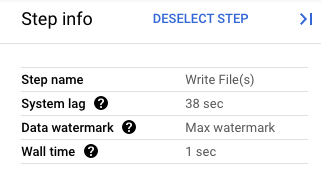
Figura 1. Una visualizzazione passo passo di un'operazione di svuotamento.
Forzare l'annullamento di un job Dataflow
Utilizza l'annullamento forzato solo quando non riesci ad annullare il job utilizzando altri metodi. L'annullamento forzato termina il job senza eliminare tutte le risorse. Se utilizzi ripetutamente l'annullamento forzato, le risorse perse potrebbero accumularsi e utilizzare la tua quota.
Quando forzi l'annullamento di un job, il servizio Dataflow lo interrompe immediatamente, rilasciando tutte le VM create dal job Dataflow. L'annullamento normale deve essere tentato almeno 30 minuti prima dell'annullamento forzato.
Quando forzi l'annullamento di un job, si verificano le seguenti azioni:
- Il servizio Dataflow interrompe tutte le operazioni di importazione ed elaborazione dei dati.
Informazioni importanti sull'annullamento forzato di un job
L'annullamento forzato di un job interrompe immediatamente l'elaborazione della pipeline.
La forzatura dell'annullamento di un job è destinata esclusivamente ai job bloccati nel normale processo di annullamento.
Le istanze worker create dal job Dataflow non vengono necessariamente rilasciate, il che potrebbe comportare perdite di istanze worker. Le istanze worker trapelate non contribuiscono ai costi del job, ma potrebbero utilizzare la tua quota. Al termine dell'annullamento del job, puoi eliminare queste risorse.
Per i job Dataflow Prime, non puoi visualizzare o eliminare le VM compromesse. Nella maggior parte dei casi, queste VM non creano problemi. Tuttavia, se le VM trapelate causano problemi, ad esempio il consumo della quota di VM, contatta l'assistenza.
Arrestare un job Dataflow
Prima di interrompere un job, devi comprendere gli effetti dell'annullamento, dell'esaurimento o dell'annullamento forzato di un job.
Console
Vai alla pagina Job Dataflow:
Fai clic sul job che vuoi interrompere.
Per interrompere un job, il suo stato deve essere In esecuzione.
Nella pagina dei dettagli del job, fai clic su Interrompi.
Esegui una di queste operazioni:
Per una pipeline batch, fai clic su Annulla o Forza annullamento.
Per una pipeline di streaming, fai clic su Annulla, Svuota o Forza annullamento.
Per confermare la tua scelta, fai clic su Interrompi lavoro.
gcloud
Per svuotare o annullare un job Dataflow,
puoi utilizzare il comando gcloud dataflow jobs
in Cloud Shell o in un terminale locale con gcloud CLI installato.
Accedi alla shell.
Elenca gli ID job per i job Dataflow attualmente in esecuzione e poi annota l'ID job per il job che vuoi arrestare:
gcloud dataflow jobs listSe il flag
--regionnon è impostato, vengono visualizzati i job Dataflow di tutte le regioni disponibili.Esegui una di queste operazioni:
Per svuotare un job di streaming:
gcloud dataflow jobs drain JOB_IDSostituisci
JOB_IDcon l'ID job che hai copiato in precedenza.Per annullare un job batch o di streaming:
gcloud dataflow jobs cancel JOB_IDSostituisci
JOB_IDcon l'ID job che hai copiato in precedenza.Per forzare l'annullamento di un job batch o di streaming:
gcloud dataflow jobs cancel JOB_ID --forceSostituisci
JOB_IDcon l'ID job che hai copiato in precedenza.
API
Per annullare o svuotare un job utilizzando l'API REST Dataflow, puoi scegliere projects.locations.jobs.update o projects.jobs.update.
Nel corpo della richiesta,
trasmetti lo stato del job richiesto
nel campo requestedState dell'istanza del job dell'API scelta.
Importante: è consigliabile utilizzare projects.locations.jobs.update, poiché projects.jobs.update consente solo di aggiornare lo stato dei job in esecuzione in us-central1.
Per annullare il job, imposta lo stato del job su
JOB_STATE_CANCELLED.Per svuotare il job, imposta lo stato del job su
JOB_STATE_DRAINED.Per forzare l'annullamento del job, imposta lo stato del job su
JOB_STATE_CANCELLEDcon l'etichetta"force_cancel_job": "true". Il corpo della richiesta è:{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Rileva il completamento del job Dataflow
Per rilevare il completamento dell'annullamento o dello svuotamento del job, utilizza uno dei seguenti metodi:
- Utilizza un servizio di orchestrazione del flusso di lavoro come Cloud Composer per monitorare il job Dataflow.
- Esegui la pipeline in modo sincrono in modo che le attività vengano bloccate fino al completamento della pipeline. Per ulteriori informazioni, consulta Controllo delle modalità di esecuzione in Impostazione delle opzioni della pipeline.
Utilizza lo strumento a riga di comando in Google Cloud CLI per eseguire il polling dello stato del job. Per visualizzare un elenco di tutti i job Dataflow nel tuo progetto, esegui questo comando nella shell o nel terminale:
gcloud dataflow jobs listL'output mostra l'ID, il nome, lo stato (
STATE) e altre informazioni per ogni job. Per ulteriori informazioni, vedi Utilizzare Google Cloud CLI per elencare i job.
Archivia i job Dataflow completati
Quando archivi un job Dataflow, questo viene rimosso dall'elenco dei job nella pagina Job di Dataflow nella console. Il job viene spostato in un elenco di job archiviati. Puoi archiviare solo i job completati, inclusi quelli nei seguenti stati:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Per maggiori informazioni sulla verifica di questi stati, consulta Rilevare il completamento del job Dataflow.
Per informazioni sulla risoluzione dei problemi durante l'archiviazione dei job, vedi Errori di archiviazione dei job in "Risolvere i problemi relativi a Dataflow".
Tutti i lavori archiviati vengono eliminati dopo un periodo di conservazione di 30 giorni.
Archiviare un job
Segui questi passaggi per rimuovere un job completato dall'elenco principale dei job nella pagina Job di Dataflow.
Console
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Viene visualizzato un elenco di job Dataflow insieme al relativo stato.
Seleziona un lavoro.
Nella pagina Dettagli job, fai clic su Archivia. Se il job non è stato completato, l'opzione Archivia non è disponibile.
REST
Per archiviare un job utilizzando l'API, utilizza il metodo
projects.locations.jobs.update.
In questa richiesta devi specificare un oggetto
JobMetadata
aggiornato. Nell'oggetto JobMetadata.userDisplayProperties, utilizza la coppia chiave-valore
"archived":"true".
Oltre all'oggetto JobMetadata aggiornato, la richiesta API deve includere anche il parametro di query updateMask nell'URL della richiesta:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: il tuo ID progetto
- REGION: una regione Dataflow
- JOB_ID: l'ID del job Dataflow
Metodo HTTP e URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Corpo JSON della richiesta:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "true"
}
}
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
quindi esegui il comando seguente:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
Dovresti ricevere una risposta JSON simile alla seguente:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "true"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
gcloud
Questo comando archivia un singolo job. Il job deve essere in uno stato terminale per poterlo archiviare. In caso contrario, la richiesta viene rifiutata. Dopo aver inviato il comando, devi confermare che vuoi eseguirlo.
Prima di utilizzare i dati dei comandi riportati di seguito, effettua le seguenti sostituzioni:
JOB_ID: l'ID del job Dataflow che vuoi archiviare.REGION: (Facoltativo). La regione Dataflow del job.
Esegui questo comando:
Linux, macOS o Cloud Shell
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (PowerShell)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (cmd.exe)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Dovresti ricevere una risposta simile alla seguente:
Archived job [JOB_ID].
createTime: '2025-06-29T11:00:02.432552Z'
currentState: JOB_STATE_DONE
currentStateTime: '2025-06-29T11:04:25.125921Z'
id: JOB_ID
jobMetadata:
userDisplayProperties:
archived: 'true'
projectId: PROJECT_ID
startTime: '2025-06-29T11:00:02.432552Z'
Visualizzare e ripristinare i job archiviati
Segui questi passaggi per visualizzare i job archiviati o per ripristinarli nell'elenco principale dei job nella pagina Job di Dataflow.
Console
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Fai clic sul pulsante di attivazione/disattivazione Archiviati. Viene visualizzato un elenco di job Dataflow archiviati.
Seleziona un lavoro.
Per ripristinare il job nell'elenco principale dei job nella pagina Job di Dataflow, fai clic su Ripristina nella pagina Dettagli job.
REST
Per ripristinare un job archiviato utilizzando l'API, utilizza il metodo
projects.locations.jobs.update.
In questa richiesta devi specificare un oggetto
JobMetadata
aggiornato. Nell'oggetto JobMetadata.userDisplayProperties, utilizza la
coppia chiave-valore "archived":"false".
Oltre all'oggetto JobMetadata aggiornato, la richiesta API deve includere anche il parametro di query updateMask nell'URL della richiesta:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: il tuo ID progetto
- REGION: una regione Dataflow
- JOB_ID: l'ID del job Dataflow
Metodo HTTP e URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Corpo JSON della richiesta:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "false"
}
}
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
quindi esegui il comando seguente:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
Dovresti ricevere una risposta JSON simile alla seguente:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "false"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
Passaggi successivi
- Esplora l'API REST Dataflow.
- Esplora l'interfaccia di monitoraggio di Dataflow nella console Google Cloud .
- Scopri di più sull'aggiornamento di una pipeline.