Les E/S gérées permettent à Dataflow de gérer des connecteurs d'E/S spécifiques utilisés dans les pipelines Apache Beam. Les E/S gérées simplifient la gestion des pipelines qui s'intègrent aux sources et récepteurs compatibles.
Les E/S gérées se composent de deux éléments qui fonctionnent ensemble :
Transformation Apache Beam qui fournit une API commune pour créer des connecteurs d'E/S (sources et récepteurs).
Un service Dataflow qui gère ces connecteurs d'E/S pour vous, y compris la possibilité de les mettre à niveau indépendamment de la version d'Apache Beam.
Voici quelques avantages de l'E/S gérée :
Mises à niveau automatiques. Dataflow met automatiquement à niveau les connecteurs d'E/S gérés dans votre pipeline. Cela signifie que votre pipeline reçoit des correctifs de sécurité, des améliorations de performances et des corrections de bugs pour ces connecteurs, sans nécessiter de modifications de code. Pour en savoir plus, consultez Mises à niveau automatiques.
API cohérente : Traditionnellement, les connecteurs d'E/S dans Apache Beam disposent d'API distinctes, et chaque connecteur est configuré différemment. Managed I/O fournit une API de configuration unique qui utilise des propriétés clé-valeur, ce qui permet d'obtenir un code de pipeline plus simple et plus cohérent. Pour en savoir plus, consultez la documentation de l'API Configuration.
Conditions requises
Les SDK suivants sont compatibles avec les E/S gérées :
- SDK Apache Beam pour Java version 2.58.0 ou ultérieure.
- Le SDK Apache Beam pour Python version 2.61.0 ou ultérieure.
Le service de backend nécessite Dataflow Runner v2. Si Runner V2 n'est pas activé, votre pipeline s'exécute quand même, mais il ne bénéficie pas des avantages du service d'E/S géré.
Mises à niveau automatiques
Les pipelines Dataflow avec des connecteurs d'E/S gérés utilisent automatiquement la dernière version fiable du connecteur, comme suit :
Lorsque vous envoyez un job, Dataflow utilise la version la plus récente du connecteur qui a été testée et fonctionne correctement.
Pour les jobs de streaming, Dataflow recherche les mises à jour chaque fois que vous lancez un job de remplacement et utilise automatiquement la dernière version stable connue. Dataflow effectue cette vérification même si vous ne modifiez aucun code dans le job de remplacement.
Vous n'avez pas à vous soucier de la mise à jour manuelle du connecteur ou de la version Apache Beam de votre pipeline.
Le schéma suivant illustre le processus de mise à niveau. L'utilisateur crée un pipeline Apache Beam à l'aide de la version X du SDK. Lorsque l'utilisateur envoie le job, Dataflow vérifie la version des E/S gérées et la met à niveau vers la version Y.
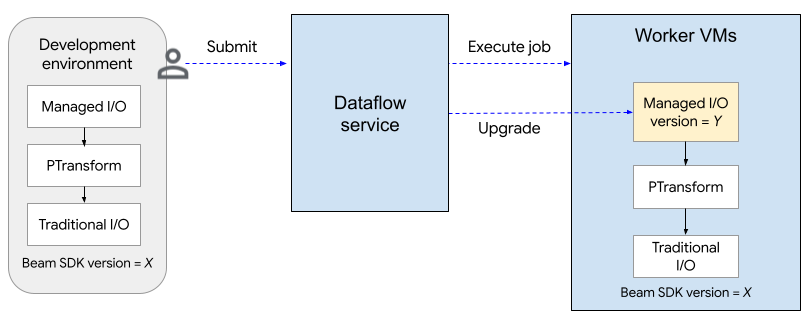
Le processus de mise à niveau ajoute environ deux minutes au temps de démarrage d'un job. Pour vérifier l'état des opérations d'E/S gérées, recherchez les entrées de journal qui incluent la chaîne "Managed Transform(s)".
API de configuration
Les E/S gérées sont une transformation Apache Beam clé en main qui fournit une API cohérente pour configurer les sources et les récepteurs.
Java
Pour créer une source ou un récepteur compatibles avec Managed I/O, vous utilisez la classe Managed. Spécifiez la source ou le récepteur à instancier, et transmettez un ensemble de paramètres de configuration, comme suit :
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
Vous pouvez également transmettre les paramètres de configuration sous la forme d'un fichier YAML. Pour obtenir un exemple de code complet, consultez Lire à partir d'Apache Iceberg.
Python
Importez le module apache_beam.transforms.managed et appelez la méthode managed.Read ou managed.Write. Spécifiez la source ou le récepteur à instancier, et transmettez un ensemble de paramètres de configuration, comme suit :
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
Vous pouvez également transmettre les paramètres de configuration sous la forme d'un fichier YAML. Pour obtenir un exemple de code complet, consultez Lire à partir d'Apache Kafka.
Destinations dynamiques
Pour certains récepteurs, le connecteur d'E/S géré peut sélectionner dynamiquement une destination en fonction des valeurs de champ dans les enregistrements entrants.
Pour utiliser des destinations dynamiques, fournissez une chaîne de modèle pour la destination. La chaîne de modèle peut inclure des noms de champs entre accolades, comme "tables.{field1}". Au moment de l'exécution, le connecteur substitue la valeur du champ pour chaque enregistrement entrant, afin de déterminer la destination de cet enregistrement.
Par exemple, supposons que vos données comportent un champ nommé airport. Vous pouvez définir la destination sur "flights.{airport}". Si airport=SFO, l'enregistrement est écrit dans flights.SFO. Pour les champs imbriqués, utilisez la notation par points. Par exemple :{top.middle.nested}.
Pour obtenir un exemple de code montrant comment utiliser des destinations dynamiques, consultez Écrire avec des destinations dynamiques.
Filtrage
Vous pouvez filtrer certains champs avant qu'ils ne soient écrits dans la table de destination. Pour les récepteurs qui acceptent les destinations dynamiques, vous pouvez utiliser les paramètres drop, keep ou only à cet effet. Ces paramètres vous permettent d'inclure des métadonnées de destination dans les enregistrements d'entrée, sans les écrire dans la destination.
Vous ne pouvez définir qu'un seul de ces paramètres pour un récepteur donné.
| Paramètre de configuration | Type de données | Description |
|---|---|---|
drop |
liste de chaînes | Liste des noms de champs à supprimer avant l'écriture dans la destination. |
keep |
liste de chaînes | Liste des noms de champs à conserver lors de l'écriture dans la destination. Les autres champs sont supprimés. |
only |
chaîne | Nom d'un seul champ à utiliser comme enregistrement de premier niveau à écrire lors de l'écriture dans la destination. Tous les autres champs sont supprimés. Ce champ doit être de type "ligne". |
Sources et récepteurs compatibles
Les E/S gérées sont compatibles avec les sources et les récepteurs suivants.
Pour en savoir plus, consultez Connecteurs d'E/S gérés dans la documentation Apache Beam.