Quando selezioni un job Dataflow specifico, l'interfaccia di monitoraggio fornisce una rappresentazione grafica del job: il grafico del job. La pagina del grafico dei job nella console fornisce anche un riepilogo del job, un log del job e informazioni su ogni passaggio della pipeline.
Il grafico del job di una pipeline rappresenta ogni trasformazione nella pipeline come un riquadro. Ciascuna contiene il nome della trasformazione e le informazioni sullo stato del job, include:
- In esecuzione: il passaggio è in esecuzione
- In coda: il passaggio in un job FlexRS è in coda
- Riuscito: il passaggio è stato completato correttamente
- Arrestato: il passaggio è stato interrotto perché il job è stato arrestato.
- Sconosciuto: non è stato possibile segnalare lo stato del passaggio
- Non riuscito: il passaggio non è stato completato
Per impostazione predefinita, la pagina del grafico del job mostra la visualizzazione Grafico. Per visualizzare il job grafico come tabella, nella visualizzazione Passaggi del job seleziona Visualizzazione tabella. La visualizzazione tabella contiene le stesse informazioni in un formato diverso. La visualizzazione tabella è utili nei seguenti scenari:
- Il job ha molte fasi, il che rende difficile la navigazione nel grafico del job.
- Vuoi ordinare i passaggi del lavoro in base a una proprietà specifica. Ad esempio, puoi ordinare la tabella in base al tempo di esecuzione per identificare i passaggi lenti.
Grafico del job di base
Codice pipeline:
Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Vai// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Grafico del job:
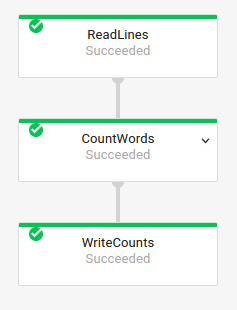
|
Trasformazioni composte
Nel grafico del job, trasformazioni composte, che contengono più sottotrasformazioni nidificate, sono espandibili. Le trasformazioni composte espandibili sono contrassegnate da una freccia nel grafico. Per espandere la trasformazione e visualizzare le trasformazioni secondarie, fai clic sull'icona freccia.
Codice pipeline:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Vai// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Grafico del job:
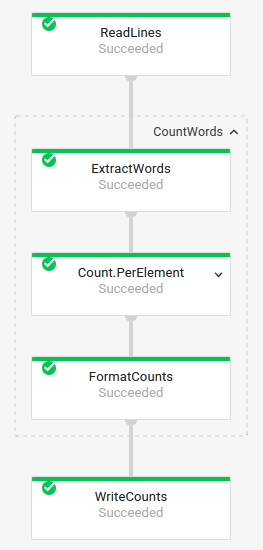
|
Nel codice della pipeline, puoi utilizzare il seguente codice per richiamare la trasformazione composita:
result = transform.apply(input);
Le trasformazioni composite richiamate in questo modo omettono il nidificazione previsto e potrebbero essere visualizzate espanse nell'interfaccia di monitoraggio di Dataflow. La pipeline potrebbe anche generare avvisi o errori relativi alla nomi univoci al momento dell'esecuzione della pipeline.
Per evitare questi problemi, invoca le trasformazioni utilizzando il formato consigliato:
result = input.apply(transform);
Nomi delle trasformazioni
Dataflow ha diversi modi per ottenere il nome della trasformazione mostrato nel grafico del job di monitoraggio. I nomi delle trasformazioni vengono utilizzati in luoghi visibili al pubblico, tra cui l'interfaccia di monitoraggio di Dataflow, i file di log e gli strumenti di debug. Non utilizzare nomi trasformati che includono informazioni che consentono l'identificazione personale, come nomi utente o nomi di organizzazioni.
Java
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Il primo
argomento fornito al metodo
applyè il nome della trasformazione. - Dataflow può dedurre il nome della trasformazione, sia dal nome della classe, se crei un
trasformazione personalizzata o il nome dell'oggetto funzione
DoFn, se utilizzi un oggetto comeParDo.
Python
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Puoi impostare il
nome della trasformazione specificando l'argomento
labeldella trasformazione. - Dataflow può dedurre il nome della trasformazione dal nome della classe, se crei una trasformazione personalizzata, o dal nome dell'oggetto funzione
DoFn, se utilizzi una trasformazione di base comeParDo.
Vai
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Puoi impostare
del nome della trasformazione specificando
Scope. - Dataflow può dedurre il nome della trasformazione dal nome della struttura se utilizzi un
DoFnstrutturale o dal nome della funzione se utilizzi unDoFnfunzionale.
Informazioni sulle metriche
Questa sezione fornisce dettagli sulle metriche associate al grafico dei job.
Tempo totale di esecuzione
Quando fai clic su un passaggio, la metrica Tempo di esecuzione viene visualizzata nel riquadro Informazioni passaggio. Il tempo reale fornisce il tempo approssimativo totale impiegato in tutti i thread di tutti i worker per le seguenti azioni:
- Inizializzazione del passaggio
- Elaborazione dei dati
- Mescolare i dati
- Terminare il passaggio
Per i passaggi compositi, il tempo totale di esecuzione indica la somma del tempo trascorso nel componente passaggi. Questa stima può aiutarti a identificare i passaggi lenti e a diagnosticare la parte della pipeline che richiede più tempo del necessario.
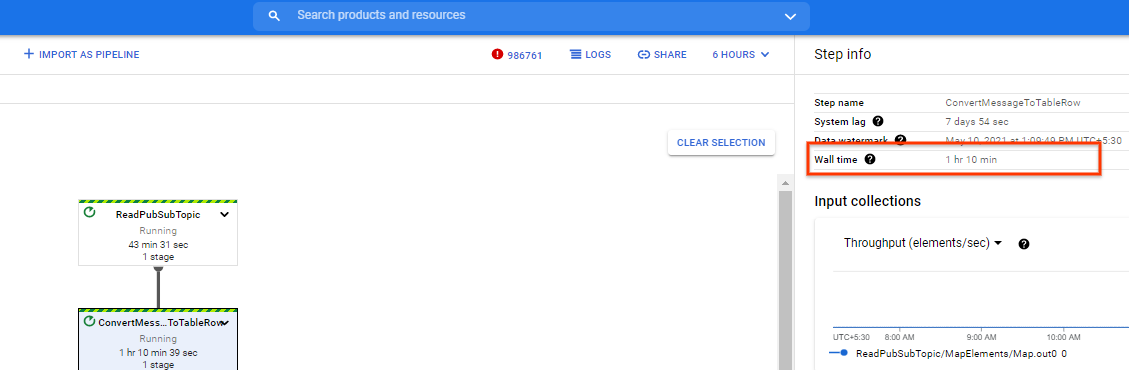
Metriche di input aggiuntive
Le metriche relative all'input secondario mostrano in che modo i pattern di accesso e gli algoritmi dell'input secondario influiscono sul rendimento della pipeline. Quando usa un input aggiuntivo, Dataflow scrive la raccolta in una permanente, come un disco, e le trasformazioni lette da questo livello . Queste letture e scritture influiscono sul tempo di esecuzione del job.
L'interfaccia di monitoraggio di Dataflow mostra le metriche di input secondario quando selezioni una trasformazione che crea o utilizza una raccolta di input aggiuntivi. Puoi visualizza le metriche nella sezione Metriche di input aggiuntivo del riquadro Informazioni sul passaggio.
Trasformazioni che creano un input aggiuntivo
Se la trasformazione selezionata crea una raccolta di input laterale, La sezione Metriche di input aggiuntivo mostra il nome della raccolta, insieme con le seguenti metriche:
- Tempo dedicato alla scrittura: il tempo dedicato a scrivere il raccolta di input aggiuntivi.
- Byte scritti:il numero totale. di byte scritti nella raccolta di input laterali.
- Tempo e byte letti dall'input aggiuntivo: una tabella che contiene e metriche aggiuntive per tutte le trasformazioni che utilizzano la raccolta di input aggiuntivi. chiamati consumatori di input aggiuntivi.
L'opzione Time & byte letti dall'input aggiuntivo contiene le seguenti informazioni per ogni consumatore di input:
- Client input aggiuntivo: il nome della trasformazione del lato un consumatore di input.
- Tempo di lettura: il tempo che questo consumatore ha impiegato per leggere la raccolta di input secondari.
- Byte letti: il numero di byte letti da questo consumer. la raccolta di input aggiuntivi.
Se la pipeline ha una trasformazione composita che crea un input aggiuntivo, espandi la trasformazione composita fino a vediamo la sottotrasformazione specifica che crea l'input aggiuntivo. Quindi, seleziona questa sottotrasformazione per visualizzare la sezione Metriche input laterali.
La Figura 4 mostra le metriche degli input aggiuntivi per una trasformazione che crea una raccolta di input aggiuntivi.
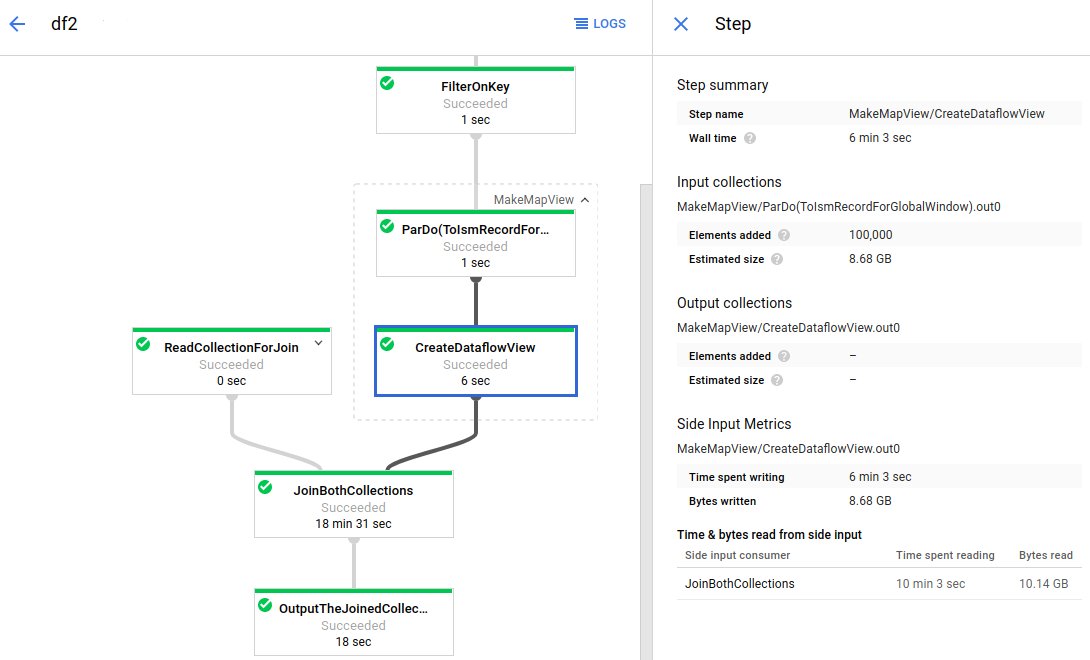
MakeMapView). La trasformazione secondaria che crea l'input laterale (CreateDataflowView) è selezionata e le metriche dell'input laterale sono visibili nel riquadro laterale Informazioni sul passaggio.Trasformazioni che consumano uno o più input aggiuntivi
Se la trasformazione selezionata utilizza uno o più input secondari, la sezione Metriche input secondari mostra la tabella Ora e byte letti dall'input secondario. Questa tabella contiene le seguenti informazioni per ogni raccolta di input secondari:
- Raccolta input aggiuntivi: il nome dell'input aggiuntivo. .
- Tempo di lettura: il tempo impiegato dalla trasformazione per leggere questa raccolta di input secondari.
- Byte letti: il numero di byte letti dalla trasformazione da questa raccolta di input secondari.
Se la pipeline ha una trasformazione composita che legge un input aggiuntivo, espandi la trasformazione composita fino a vediamo la sottotrasformazione specifica che legge l'input aggiuntivo. Quindi, seleziona questa sottotrasformazione per visualizzare la sezione Metriche input laterali.
La Figura 5 mostra le metriche degli input aggiuntivi per una trasformazione che legge da una raccolta di input aggiuntivi.
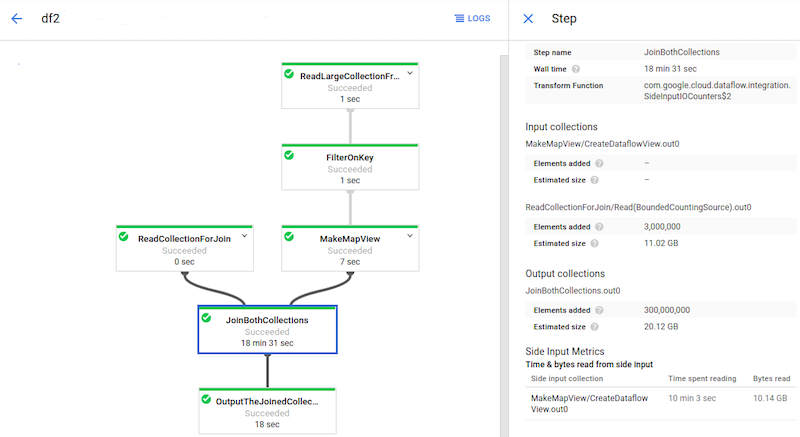
JoinBothCollections legge da una raccolta di input secondari. JoinBothCollections è selezionato nel grafico del job e le metriche di input laterali sono visibili nel riquadro laterale Informazioni passaggio.Identificare i problemi di prestazioni degli input collaterali
La ripetizione è un problema comune di prestazioni degli input. Se il tuo input aggiuntivo
PCollection è troppo grande. I worker non possono memorizzare nella cache l'intera raccolta.
Di conseguenza, i worker devono leggere ripetutamente dalla raccolta di input laterali permanenti.
Nella figura 6, le metriche relative all'input secondario mostrano che i byte totali letti dalla raccolta di input secondario sono molto più grandi delle dimensioni della raccolta, ovvero i byte totali scritti.
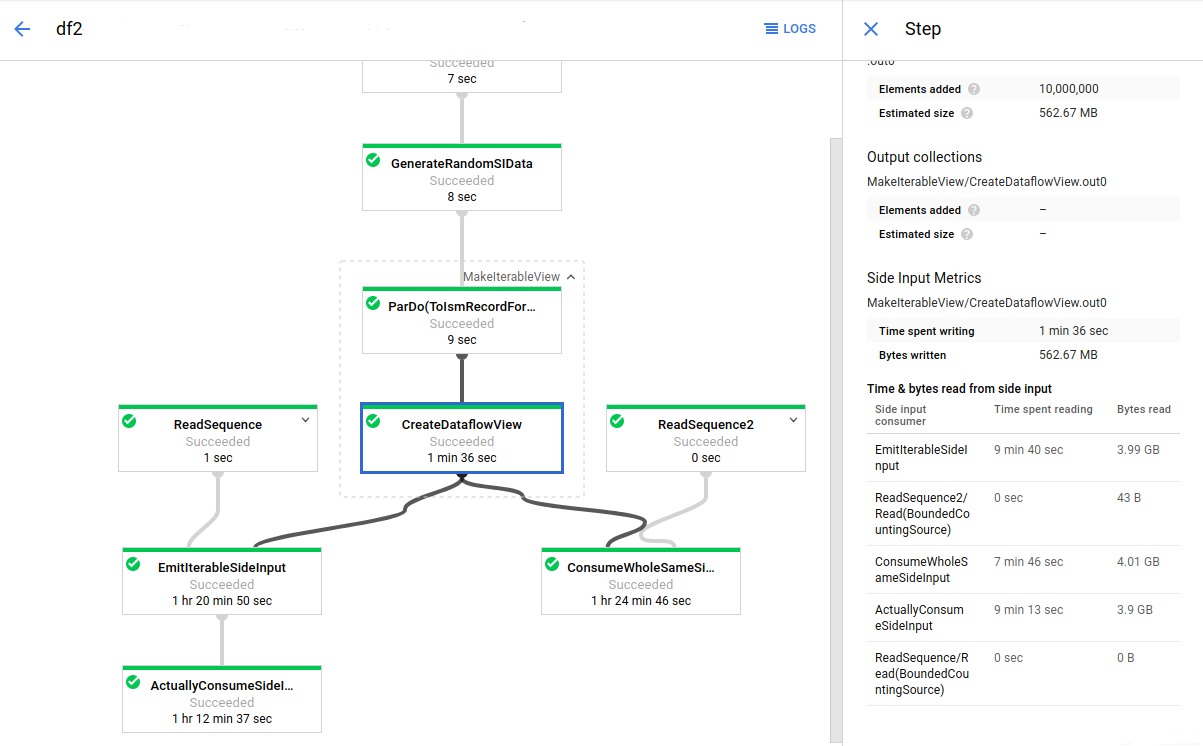
Per migliorare il rendimento di questa pipeline, riprogetta l'algoritmo per evitare di eseguire l'iterazione o il recupero dei dati di input secondari. In questo esempio, la pipeline crea il prodotto cartesiano di due raccolte. L'algoritmo esegue un'iterazione su tutta la raccolta di input secondario per ogni elemento della raccolta principale. Puoi migliorare il pattern di accesso alla pipeline eseguendo il batch insieme a più elementi della raccolta principale. Questa modifica riduce di volte in cui i worker devono rileggere la raccolta di input aggiuntivi.
Se la pipeline esegue un join, può verificarsi un altro problema di prestazioni comune.
applicando un valore ParDo con uno o più input laterali grandi. In questo caso,
i worker impiegano una grande percentuale del tempo di elaborazione dell'operazione di join per la lettura dalle
collezioni di input secondarie.
La figura 7 mostra esempi di metriche di input secondarie per questo problema:
JoinBothCollections ha un tempo di elaborazione totale di 18 minuti e 31 secondi. I worker impiegano la maggior parte del tempo di elaborazione (10 minuti e 3 secondi) a leggere dalla raccolta di input secondari di 10 GB.Per migliorare le prestazioni di questa pipeline, utilizza CoGroupByKey anziché input aggiuntivi.