Antarmuka pemantauan Dataflow memberikan representasi grafis setiap tugas: grafik tugas. Grafik tugas juga memberikan ringkasan tugas, log tugas, dan informasi tentang setiap langkah dalam pipeline.
Untuk melihat grafik tugas, lakukan langkah-langkah berikut:
Di konsol Google Cloud , buka halaman Dataflow > Jobs.
Pilih lowongan.
Klik tab Grafik tugas.
Secara default, halaman grafik tugas menampilkan Tampilan grafik. Untuk melihat grafik tugas sebagai tabel, di Tampilan langkah tugas, pilih Tampilan tabel. Tampilan tabel berisi informasi yang sama dalam format yang berbeda. Tampilan tabel berguna dalam skenario berikut:
- Tugas Anda memiliki banyak tahap, sehingga grafik tugas sulit dinavigasi.
- Anda ingin mengurutkan langkah-langkah tugas berdasarkan properti tertentu. Misalnya, Anda dapat mengurutkan tabel berdasarkan waktu proses untuk mengidentifikasi langkah-langkah yang lambat.
Tampilan grafik
Grafik tugas merepresentasikan setiap transformasi dalam pipeline sebagai kotak. Gambar
berikut menunjukkan grafik tugas dengan tiga transformasi: Read PubSub Events,
5m Window, dan Write File(s).
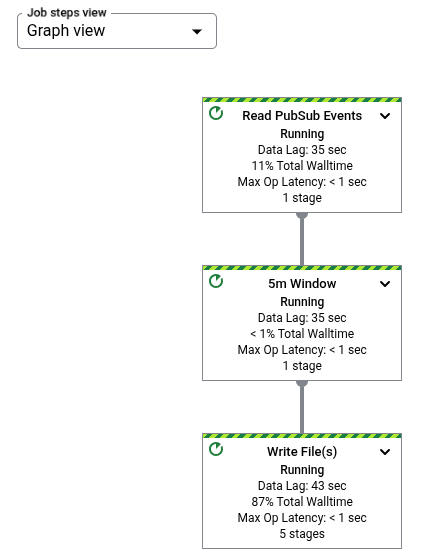
Setiap kotak berisi informasi berikut:
Status; salah satu dari berikut ini:
- Berjalan: langkah sedang berjalan
- Dalam antrean: langkah dalam tugas FlexRS berada dalam antrean
- Berhasil: langkah berhasil diselesaikan
- Dihentikan: langkah dihentikan karena tugas dihentikan
- Tidak diketahui: langkah gagal melaporkan status
- Gagal: langkah gagal diselesaikan
Jumlah tahap tugas yang menjalankan langkah ini
Jika langkah mewakili transformasi gabungan, Anda dapat meluaskan langkah untuk melihat sub-transformasi. Untuk meluaskan langkah, klik panah Luaskan node.
Nama transformasi
Dataflow memiliki beberapa cara berbeda untuk mendapatkan nama transformasi yang ditampilkan dalam grafik tugas pemantauan. Nama transformasi digunakan di tempat yang dapat dilihat publik, termasuk antarmuka pemantauan Dataflow, file log, dan alat proses debug. Jangan gunakan nama transformasi yang menyertakan informasi identitas pribadi, seperti nama pengguna atau nama organisasi.
Java
- Dataflow dapat menggunakan nama yang Anda tetapkan saat Anda menerapkan transformasi. Argumen
pertama yang Anda berikan ke metode
applyadalah nama transformasi Anda. - Dataflow dapat menyimpulkan nama transformasi, baik dari nama class, jika Anda membuat
transformasi kustom, atau nama objek fungsi
DoFn, jika Anda menggunakan transformasi inti sepertiParDo.
Python
- Dataflow dapat menggunakan nama yang Anda tetapkan saat Anda menerapkan transformasi. Anda dapat menetapkan
nama transformasi dengan menentukan argumen
labeltransformasi. - Dataflow dapat menyimpulkan nama transformasi, baik dari nama class, jika Anda membuat
transformasi kustom, atau nama objek fungsi
DoFn, jika Anda menggunakan transformasi inti sepertiParDo.
Go
- Dataflow dapat menggunakan nama yang Anda tetapkan saat Anda menerapkan transformasi. Anda dapat menetapkan
nama transformasi dengan menentukan
Scope. - Dataflow dapat menyimpulkan nama transformasi, baik dari
nama struct jika Anda menggunakan
DoFnstruktural atau dari nama fungsi jika Anda menggunakanDoFnfungsional.
Melihat informasi langkah
Saat Anda mengklik langkah dalam grafik tugas, panel Info Langkah akan menampilkan detail selengkapnya tentang langkah tersebut. Untuk mengetahui informasi selengkapnya, lihat Informasi langkah tugas.
Bottleneck
Jika Dataflow mendeteksi hambatan, grafik tugas akan menampilkan simbol peringatan pada langkah-langkah yang terpengaruh. Untuk melihat penyebab hambatan, klik langkah untuk membuka panel Info Langkah. Untuk mengetahui informasi selengkapnya, lihat Memecahkan masalah hambatan.

Contoh grafik tugas
Bagian ini menampilkan beberapa contoh kode pipeline dan grafik tugas yang sesuai.
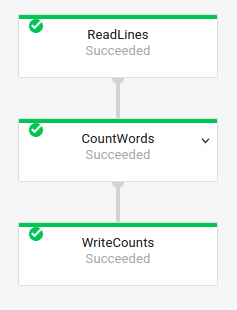
Grafik tugas dasar
Kode Pipeline:
Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Grafik tugas:
|
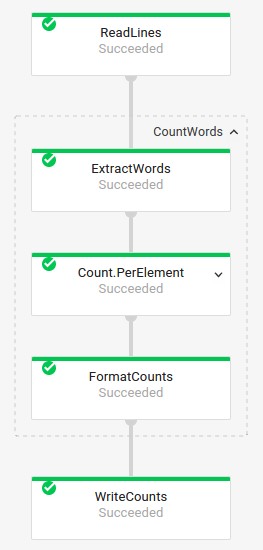
Grafik tugas dengan transformasi komposit
Transformasi gabungan adalah transformasi yang berisi beberapa sub-transformasi bertingkat. Dalam grafik tugas, transformasi komposit dapat diluaskan. Untuk meluaskan transformasi dan melihat sub-transformasi, klik panah.
Kode Pipeline:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Grafik tugas:
|
Dalam kode pipeline, Anda dapat menggunakan kode berikut untuk memanggil transformasi komposit:
result = transform.apply(input);
Transformasi gabungan yang dipanggil dengan cara ini menghilangkan nesting yang diharapkan dan mungkin tampak diperluas di antarmuka pemantauan Dataflow. Pipeline Anda juga dapat menghasilkan peringatan atau error tentang nama unik yang stabil pada waktu eksekusi pipeline.
Untuk menghindari masalah ini, panggil transformasi Anda menggunakan format yang direkomendasikan:
result = input.apply(transform);
Langkah berikutnya
- Melihat informasi langkah tugas yang mendetail
- Melihat tahap tugas di tab Detail eksekusi
- Memecahkan masalah pipeline