O criador de jobs é uma UI visual para criar e executar pipelines do Dataflow no console Google Cloud , sem escrever código.
A imagem a seguir mostra um detalhe da interface do job builder. Nesta imagem, o usuário está criando um pipeline para ler do Pub/Sub para o BigQuery:
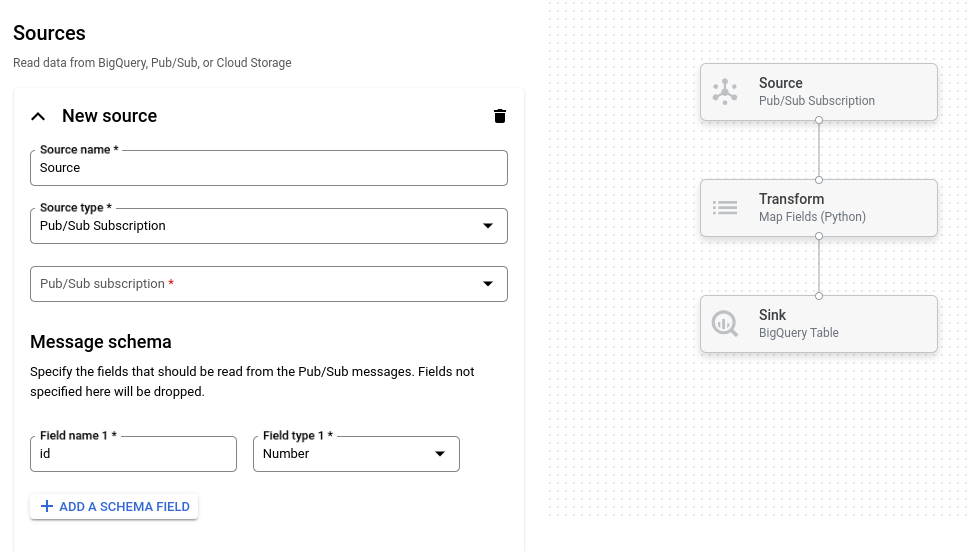
Visão geral
O criador de jobs aceita a leitura e gravação dos seguintes tipos de dados:
- Mensagens de Pub/Sub
- Dados da tabela do BigQuery
- Arquivos CSV, JSON e arquivos de texto no Cloud Storage
- Dados de tabelas do PostgreSQL, MySQL, Oracle e SQL Server
Ele é compatível com transformações de pipeline, incluindo filtrar, mapear, SQL, agrupar por, mesclar e explodir (achatamento da matriz).
Com o Job Builder, você pode:
- Fazer streaming do Pub/Sub para o BigQuery com transformações e agregação em janelas
- Gravar dados do Cloud Storage no BigQuery
- Use o tratamento de erros para filtrar dados incorretos (fila de mensagens inativas)
- Manipular ou agregar dados usando SQL com a transformação SQL
- Adicionar, modificar ou remover campos de dados com transformações de mapeamento
- Programar jobs em lote recorrentes
O criador de jobs também pode salvar pipelines como arquivos YAML do Apache Beam e carregar definições de pipeline de arquivos YAML do Beam. Ao usar esse recurso, é possível projetar o pipeline no criador de jobs e armazenar o arquivo YAML no Cloud Storage ou em um repositório de controle de origem para reutilização. As definições de job em YAML também podem ser usadas para iniciar jobs com a CLI gcloud.
Considere o criador de jobs para os seguintes casos de uso:
- Você quer criar um pipeline rapidamente sem escrever código.
- Você quer salvar um pipeline em YAML para reutilização.
- O pipeline pode ser expresso usando as origens, os coletores e as transformações compatíveis.
- Não há um modelo fornecido pelo Google que corresponda ao seu caso de uso.
Executar um job de amostra
O exemplo de contagem de palavras é um pipeline em lote que lê textos do Cloud Storage, transforma linhas de texto em palavras individuais e executa uma contagem de frequência em cada palavra.
Se o bucket do Cloud Storage estiver fora do perímetro do serviço, crie uma regra de saída que permita acesso ao bucket.
Para executar o pipeline de contagem de palavras, siga estas etapas:
Acesse a página Jobs no console Google Cloud .
Clique em Criar job a partir do modelo.
No painel lateral, clique em Criador de jobs.
Clique em Carregar plantas.
Clique em Contagem de palavras. O criador de jobs é preenchido com uma representação gráfica do pipeline.
Para cada etapa do pipeline, o criador de jobs exibe um cartão que especifica os parâmetros de configuração correspondentes para essa etapa. Por exemplo, a primeira etapa lê arquivos de texto do Cloud Storage. O local dos dados de origem é preenchido automaticamente na caixa Local do texto.
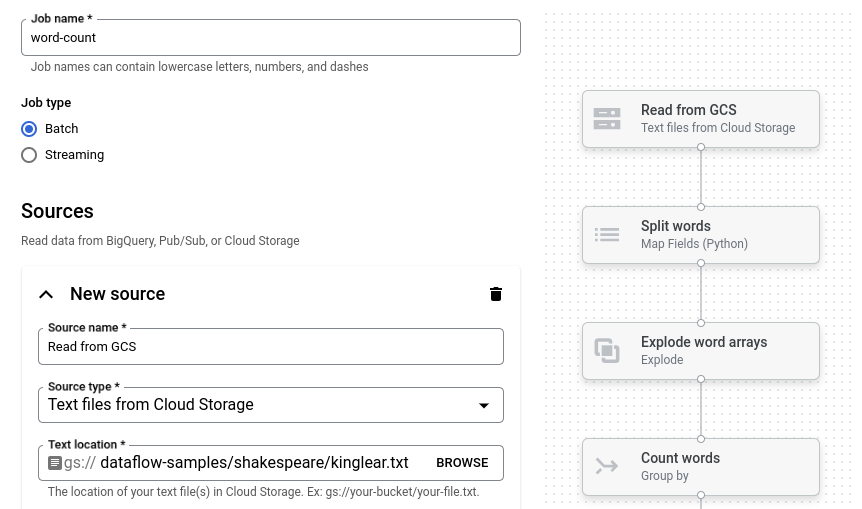
Localize o cartão intitulado Novo coletor. Talvez seja necessário rolar a tela.
Na caixa Local do texto, insira o prefixo do caminho do local do Cloud Storage para os arquivos de texto de saída.
Cliquem em Executar job. O criador de jobs cria um job do Dataflow e depois navega até o gráfico do job. Quando o job é iniciado, o gráfico do job mostra uma representação gráfica do pipeline. Essa representação gráfica é semelhante à mostrada no criador de jobs. À medida que cada etapa do pipeline é executada, o status é atualizado no gráfico do job.
O painel Informações do job mostra o status geral dele. Se o job for concluído
com sucesso, o campo Status do job será atualizado para Succeeded.
A seguir
- Usar a interface de monitoramento de jobs do Dataflow.
- Crie um job personalizado no criador de jobs.
- Salve e carregue definições de jobs YAML no criador de jobs.
- Saiba mais sobre o YAML do Beam.