Job builder adalah UI visual untuk membangun dan menjalankan pipeline Dataflow di konsol Google Cloud , tanpa perlu menulis kode.
Gambar berikut menunjukkan detail dari UI pembuat tugas. Pada gambar ini, pengguna membuat pipeline untuk membaca dari Pub/Sub ke BigQuery:

Ringkasan
Pembangun tugas mendukung pembacaan dan penulisan jenis data berikut:
- Pesan Pub/Sub
- Data tabel BigQuery
- File CSV, file JSON, dan file teks di Cloud Storage
- Data tabel PostgreSQL, MySQL, Oracle, dan SQL Server
Alat ini mendukung transformasi pipeline termasuk filter, peta, SQL, pengelompokan menurut, gabung, dan explode (perataan array).
Dengan pembuat tugas, Anda dapat:
- Streaming dari Pub/Sub ke BigQuery dengan transformasi dan agregasi berwindow
- Menulis data dari Cloud Storage ke BigQuery
- Menggunakan penanganan error untuk memfilter data yang salah (antrean pesan yang tidak terkirim)
- Memanipulasi atau menggabungkan data menggunakan SQL dengan transformasi SQL
- Menambahkan, mengubah, atau menghapus kolom dari data dengan transformasi pemetaan
- Menjadwalkan tugas batch berulang
Pembangun tugas juga dapat menyimpan pipeline sebagai file YAML Apache Beam dan memuat definisi pipeline dari file YAML Beam. Dengan menggunakan fitur ini, Anda dapat mendesain pipeline di pembuat tugas lalu menyimpan file YAML di Cloud Storage atau repositori kontrol sumber untuk digunakan kembali. Definisi tugas YAML juga dapat digunakan untuk meluncurkan tugas menggunakan gcloud CLI.
Pertimbangkan pembuat tugas untuk kasus penggunaan berikut:
- Anda ingin membuat pipeline dengan cepat tanpa menulis kode.
- Anda ingin menyimpan pipeline ke YAML untuk digunakan kembali.
- Pipeline Anda dapat dinyatakan menggunakan sumber, sink, dan transformasi yang didukung.
- Tidak ada template yang disediakan Google yang cocok dengan kasus penggunaan Anda.
Menjalankan tugas contoh
Contoh Word Count adalah pipeline batch yang membaca teks dari Cloud Storage, membuat token baris teks menjadi kata individual, dan menjalankan penghitungan frekuensi pada setiap kata.
Jika bucket Cloud Storage berada di luar perimeter layanan Anda, buat aturan keluar yang mengizinkan akses ke bucket tersebut.
Untuk menjalankan pipeline Word Count, ikuti langkah-langkah berikut:
Buka halaman Jobs di konsol Google Cloud .
Klik Buat tugas dari template.
Di panel samping, klik Job builder.
Klik Muat cetak biru.
Klik Jumlah Kata. Penyusun tugas diisi dengan representasi grafis pipeline.
Untuk setiap langkah pipeline, builder tugas menampilkan kartu yang menentukan parameter konfigurasi untuk langkah tersebut. Misalnya, langkah pertama membaca file teks dari Cloud Storage. Lokasi data sumber sudah diisi otomatis di kotak Lokasi teks.
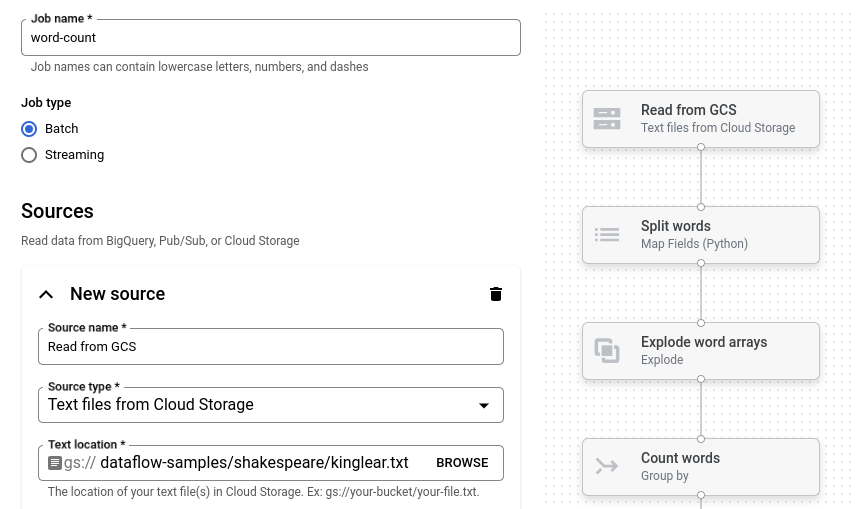
Cari kartu berjudul Wastafel baru. Anda mungkin perlu men-scroll.
Di kotak Text location, masukkan awalan jalur lokasi Cloud Storage untuk file teks output.
Klik Run job. Builder tugas membuat tugas Dataflow, lalu membuka grafik tugas. Saat tugas dimulai, grafik tugas akan menampilkan representasi grafis pipeline. Representasi grafik ini mirip dengan yang ditampilkan di pembuat tugas. Saat setiap langkah pipeline berjalan, status akan diperbarui dalam grafik tugas.
Panel Info tugas menampilkan status keseluruhan tugas. Jika tugas selesai
dengan berhasil, kolom Status tugas akan diperbarui menjadi Succeeded.
Langkah berikutnya
- Gunakan antarmuka pemantauan tugas Dataflow.
- Buat tugas kustom di pembuat tugas.
- Simpan dan muat definisi tugas YAML di pembuat tugas.
- Pelajari lebih lanjut YAML Beam.