JupyterLab 노트북에서 Apache Beam 대화형 실행기를 사용하여 다음 작업을 완료합니다.
- 파이프라인을 반복적으로 개발합니다.
- 파이프라인 그래프를 검사합니다.
- REPL(read-eval-print-loop) 워크플로에서 개별
PCollections를 파싱합니다.
이러한 Apache Beam 노트북은 최신 데이터 과학과 머신러닝 프레임워크가 미리 설치된 노트북 가상 머신을 호스트하는 서비스인 Vertex AI Workbench를 통해 제공됩니다. Dataflow는 Apache Beam 컨테이너를 사용하는 Workbench 인스턴스만 지원합니다.
이 가이드에서는 Apache Beam 노트북에서 도입한 기능을 중점적으로 설명하지만 노트북 빌드 방법을 설명하지는 않습니다. Apache Beam에 대한 자세한 내용은 Apache Beam 프로그래밍 가이드를 참조하세요.
지원 및 제한 사항
- Apache Beam 노트북은 Python만 지원합니다.
- 이러한 노트북에서 실행되는 Apache Beam 파이프라인 세그먼트는 프로덕션 Apache Beam 실행기가 아닌 테스트 환경에서 실행됩니다. Dataflow 서비스에서 노트북을 실행하려면 Apache Beam 노트북에서 생성된 파이프라인을 내보내세요. 자세한 내용은 노트북에서 생성된 파이프라인에서 Dataflow 작업 실행을 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Apache Beam 노트북 인스턴스를 만들기 전에 Pub/Sub과 같은 다른 서비스를 사용하는 파이프라인에 추가 API를 사용 설정합니다.
지정하지 않으면 노트북 인스턴스는 IAM 프로젝트 편집자 역할이 있는 기본 Compute Engine 서비스 계정에서 실행됩니다. 프로젝트에서 서비스 계정의 역할을 명시적으로 제한하는 경우 노트북을 실행할 수 있는 충분한 권한이 있는지 확인합니다. 예를 들어 Pub/Sub 주제에서 읽는 경우에는 암시적으로 구독이 생성되고, 서비스 계정에 IAM Pub/Sub 편집자 역할이 필요합니다. 반면에 Pub/Sub 구독에서 읽으려면 IAM Pub/Sub 구독자 역할만 필요합니다.
이 가이드를 마쳤으면 요금이 계속 청구되지 않도록 만든 리소스를 삭제합니다. 자세한 내용은 삭제를 참조하세요.
Apache Beam 노트북 인스턴스 실행
Google Cloud 콘솔에서 Dataflow Workbench 페이지로 이동합니다.
인스턴스 탭에 있는지 확인합니다.
툴바에서 새로 만들기를 클릭합니다.
환경 섹션의 환경에서 컨테이너가 Apache Beam이어야 합니다. Apache Beam 노트북에는 JupyterLab 3.x만 지원됩니다.
선택사항: GPU에서 노트북을 실행하려면 머신 유형 섹션에서 GPU를 지원하는 머신 유형을 선택합니다. 자세한 내용은 GPU 플랫폼을 참조하세요.
네트워킹 섹션에서 노트북 VM의 서브네트워크를 선택합니다.
선택사항: 커스텀 노트북 인스턴스를 설정하려면 커스텀 컨테이너를 사용하여 인스턴스 만들기를 참조하세요.
만들기를 클릭합니다. Dataflow Workbench에서 새 Apache Beam 노트북 인스턴스를 만듭니다.
노트북 인스턴스가 생성되면 JupyterLab 열기 링크가 활성화됩니다. JupyterLab 열기를 클릭합니다.
선택사항: 종속 항목 설치
Apache Beam 노트북에는 Apache Beam 및Google Cloud 커넥터 종속 항목이 이미 설치되어 있습니다. 파이프라인에 서드 파티 라이브러리에 종속된 커스텀 커넥터이나 커스텀 PTransforms가 포함된 경우 노트북 인스턴스를 만든 후에 설치합니다.
Apache Beam 노트북 예시
노트북 인스턴스를 만든 후에 JupyterLab에서 엽니다. JupyterLab 사이드바의 파일 탭에 있는 예시 폴더에는 예시 노트북이 포함되어 있습니다. JupyterLab 파일 사용 방법에 대한 자세한 내용은 JupyterLab 사용자 가이드의 파일 작업을 참조하세요.
다음과 같은 노트북을 사용할 수 있습니다.
- 단어 수
- 단어 수 스트리밍
- NYC 택시 탑승 데이터 스트리밍
- 노트북의 Apache Beam SQL와 파이프라인 비교
- Dataflow 실행기를 사용하는 노트북의 Apache Beam SQL
- 노트북의 Apache Beam SQL
- Dataflow 단어 수 확인
- 규모에 따른 대화형 Flink
- RunInference
- Apache Beam에서 GPU 사용
- 데이터 시각화
튜토리얼 폴더에는 Apache Beam의 기본 사항을 설명하는 추가 튜토리얼이 있습니다. 제공되는 튜토리얼은 다음과 같습니다.
- 기본 작업
- 요소별 작업
- 집계
- Windows
- I/O 작업
- 스트리밍
- 마지막 실습
이 노트에는 Apache Beam 개념 및 API 사용을 이해하는 데 도움이 되는 설명 텍스트 및 댓글 코드 블록이 포함되어 있습니다. 또한 이 튜토리얼에서는 개념을 연습하기 위한 실습을 제공합니다.
다음 섹션에서는 단어 수 스트리밍 노트북의 예시 코드를 사용합니다. 이 가이드의 코드 스니펫과 단어 수 스트리밍 노트북에 있는 코드는 약간 다를 수 있습니다.
노트북 인스턴스 만들기
파일 > 새 항목 > 노트북으로 이동하여 Apache Beam 2.22 이상인 커널을 선택합니다.
참고: Apache Beam 노트북은 Apache Beam SDK의 마스터 브랜치에 대해 빌드됩니다. 즉, 노트북 UI에 표시되는 커널의 최신 버전이 가장 최근에 출시된 SDK 버전보다 앞서 있을 수 있습니다.
Apache Beam은 메모장 인스턴스에 설치되므로 메모장에 interactive_runner 및 interactive_beam 모듈을 포함합니다.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
노트북에서 다른 Google API를 사용하는 경우 다음 가져오기 구문을 추가합니다.
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
상호작용 옵션 설정
다음은 대화형 실행자가 제한되지 않은 소스에서 데이터를 기록하는 시간을 설정하는 시간입니다. 이 예시에서 시간은 10분으로 설정됩니다.
ib.options.recording_duration = '10m'
recording_size_limit 속성을 사용하여 제한되지 않은 소스의 기록 크기 제한(바이트)을 변경할 수도 있습니다.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
추가 대화형 옵션은 interactive_beam.options 클래스를 참조하세요.
파이프라인 만들기
InteractiveRunner 객체를 사용하여 파이프라인을 초기화합니다.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
데이터 읽기 및 시각화
다음 예시는 지정된 Pub/Sub 주제에 대한 구독을 만들고 구독에서 읽는 Apache Beam 파이프라인을 보여줍니다.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
파이프라인은 소스의 윈도우를 기준으로 단어 수를 계산합니다. 각 윈도우가 10초 길이인 고정 윈도우가 생성됩니다.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
데이터에 윈도우가 만들어지면 단어는 윈도우를 기준으로 계산됩니다.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
show() 메서드는 노트북에서 결과 PCollection을 시각화합니다.
ib.show(windowed_word_counts, include_window_info=True)
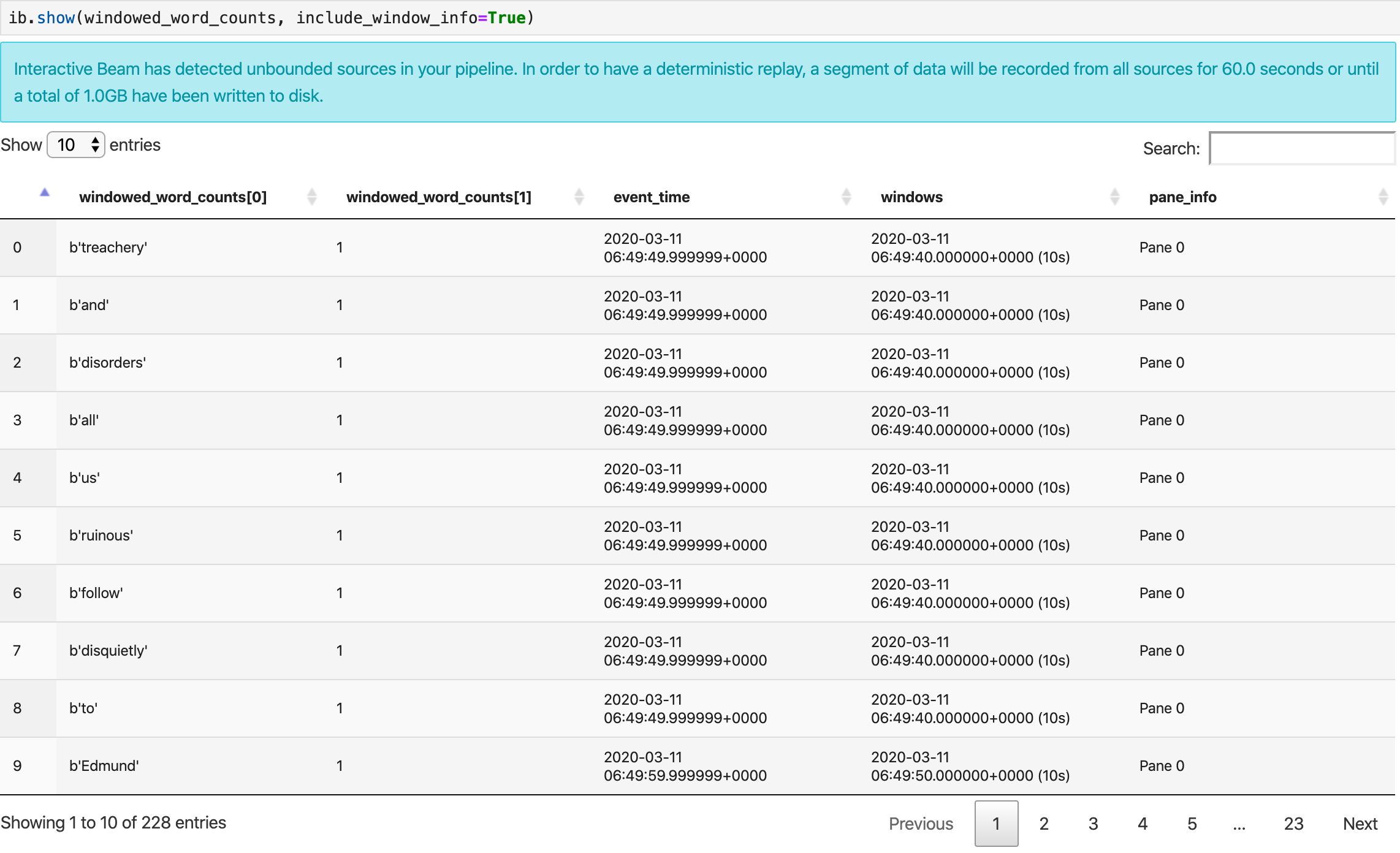
선택적 매개변수 n과 duration을 설정하여 show()에서 결과 집합의 범위를 다시 지정할 수 있습니다.
n을 설정하면 결과 집합이 최대n개의 요소(예: 20개)로 표시됩니다.n이 설정되지 않은 경우 기본 동작은 소스 기록이 끝날 때까지 캡처된 가장 최근 요소를 나열하는 것입니다.duration을 설정하여 소스 기록을 시작할 때 지정된 시간(초) 분량의 결과 집합을 데이터로 제한합니다.duration을 설정하지 않으면 기본 동작은 기록이 완료될 때까지 모든 요소를 나열하는 것입니다.
두 선택적 매개변수가 모두 설정되면 임계값이 둘 중 하나라도 충족될 때마다 show()가 중지됩니다. 다음 예시에서 show()는 기록된 소스에서 처음 30초 분량의 데이터를 기반으로 계산된 최대 20개의 요소를 반환합니다.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
데이터 시각화를 표시하려면 show() 메서드로 visualize_data=True를 전달합니다. 여러 필터를 시각화에 적용할 수 있습니다. 다음 시각화를 사용하면 라벨과 축을 기준으로 필터링할 수 있습니다.
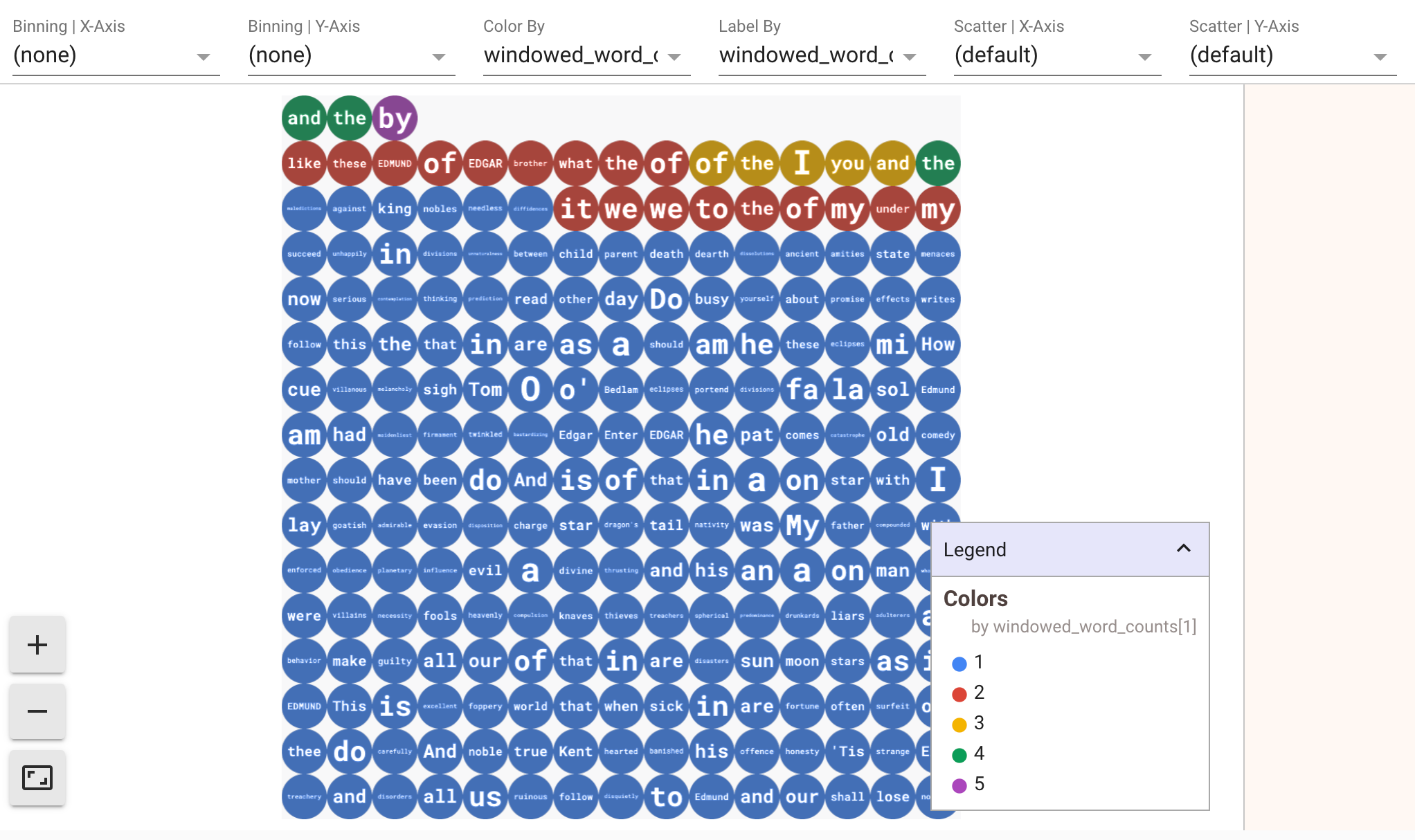
스트리밍 파이프라인을 프로토타입으로 제작하는 동안 재생성을 보장하기 위해 show() 메서드 호출은 기본적으로 캡처된 데이터를 재사용합니다. 이 동작을 변경하고 show() 메서드가 항상 새 데이터를 가져오도록 하려면 interactive_beam.options.enable_capture_replay = False를 설정하세요. 또한 노트북에 두 번째로 제한되지 않은 소스를 추가하면 이전의 제한되지 않은 소스의 데이터가 삭제됩니다.
Apache Beam 노트북의 또 다른 유용한 시각화는 Pandas DataFrame입니다. 다음 예시는 먼저 단어를 소문자로 변환한 다음 각 단어의 빈도를 계산합니다.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
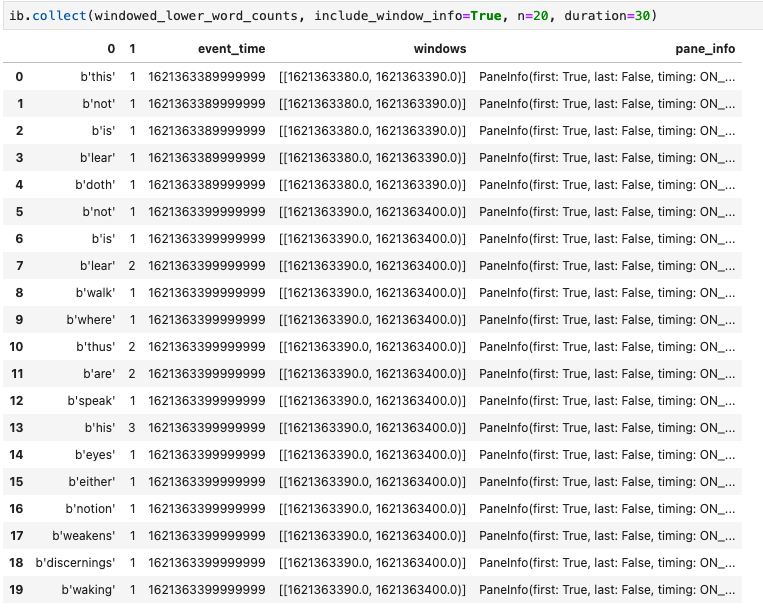
collect() 메서드는 Pandas DataFrame에 출력을 제공합니다.
ib.collect(windowed_lower_word_counts, include_window_info=True)
노트북을 개발하는 경우 셀을 편집하고 재실행하는 것이 일반적입니다. Apache Beam 노트북에서 셀을 편집하고 다시 실행하면 원래의 셀은 셀에서 의도한 코드 작업을 실행취소하지 않습니다. 예를 들어 셀이 파이프라인에 PTransform을 추가하는 경우 해당 셀을 다시 실행하면 파이프라인에 PTransform이 또 추가됩니다. 상태를 지우려면 커널을 다시 시작하고 셀을 다시 실행합니다.
대화형 Beam 검사기를 통해 데이터 시각화
특히 출력이 화면 공간을 상당히 차지하고 노트북 간 탐색이 어려울 때는 show() 및 collect()를 지속적으로 호출하여 PCollection의 데이터를 검사하는 것이 쉽지 않을 수 있습니다. 변환이 의도한 대로 작동하는지 확인하기 위해 여러 개의 PCollections를 나란히 비교할 수도 있습니다. 한 PCollection이 변환을 거쳐 다른 하나를 생성하는 경우를 예로 들어 보겠습니다. 이러한 사용 사례에서는 대화형 Beam 검사기가 편리한 솔루션입니다.
대화형 Beam 검사기는 Apache Beam 노트북에 사전 설치된 JupyterLab 확장 프로그램 apache-beam-jupyterlab-sidepanel로 제공됩니다. 이 확장 프로그램을 사용하면 show() 또는 collect()를 명시적으로 호출하지 않아도 각 PCollection과 연결된 파이프라인 및 데이터 상태를 대화형으로 검사할 수 있습니다.
검사기를 여는 데에는 3가지 방법이 있습니다.
JupyterLab의 상단 메뉴 바에서
Interactive Beam을 클릭합니다. 드롭다운에서Open Inspector를 찾아 클릭하여 검사기를 엽니다.
런처 페이지를 사용합니다. 런처 페이지가 열려 있지 않으면
File->New Launcher를 클릭하여 엽니다. 런처 페이지에서Interactive Beam을 찾아Open Inspector를 클릭하여 검사기를 엽니다.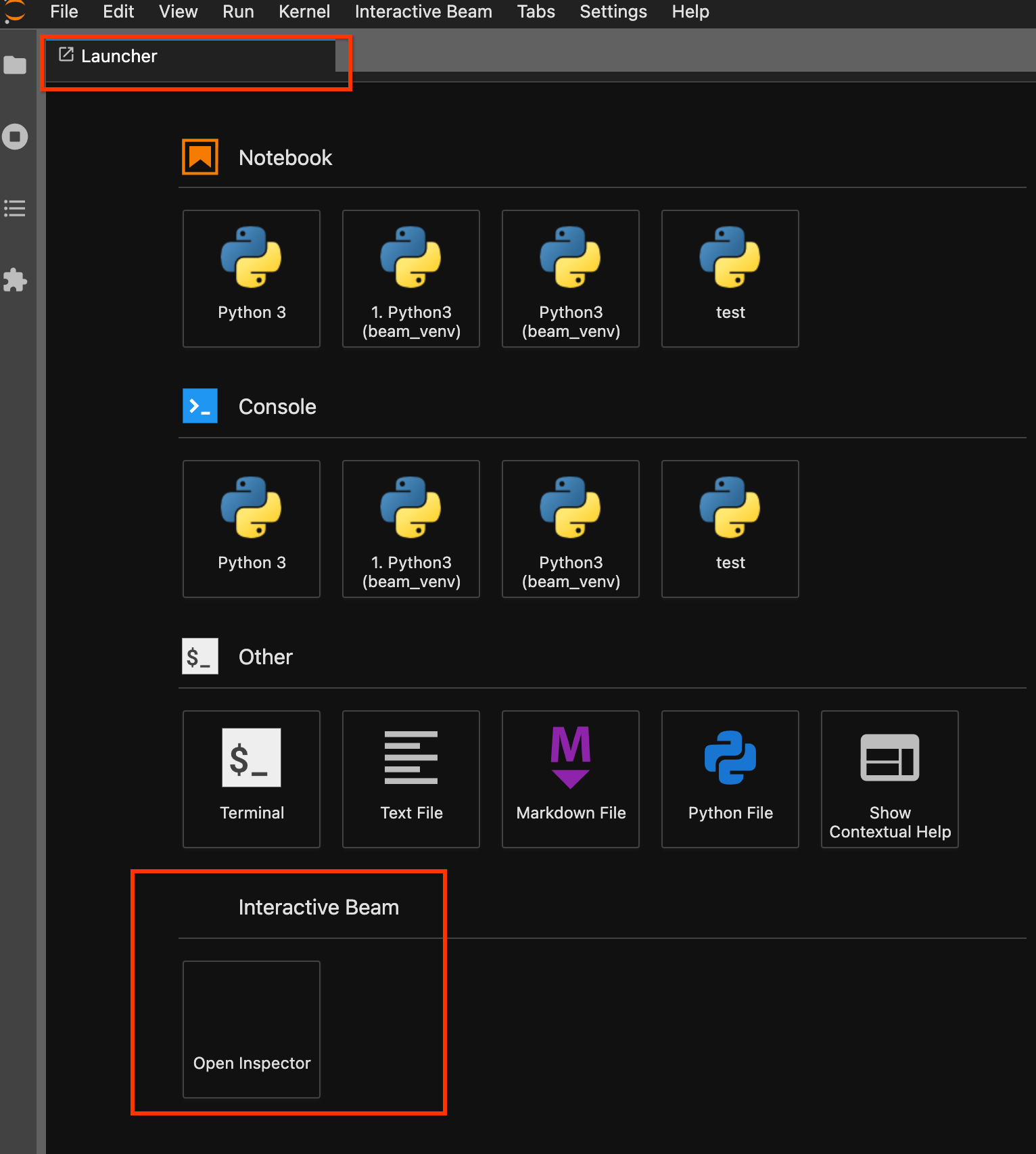
명령어 팔레트를 사용합니다. JupyterLab 메뉴 바에서
View>Activate Command Palette를 클릭합니다. 대화상자에서Interactive Beam을 검색하여 확장 프로그램의 모든 옵션을 나열합니다.Open Inspector를 클릭하여 검사기를 엽니다.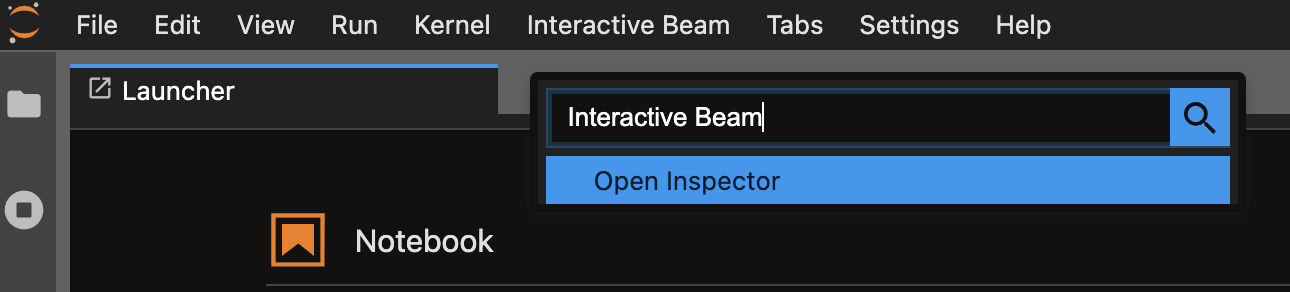
검사기가 열릴 때:
노트북이 단 하나만 열려 있으면 검사기가 자동으로 여기에 연결합니다.
열려 있는 노트북이 없는 경우 커널을 선택할 수 있는 대화상자가 표시됩니다.
여러 개의 노트북이 열려 있는 경우 노트북 세션을 선택할 수 있는 대화상자가 나타납니다.
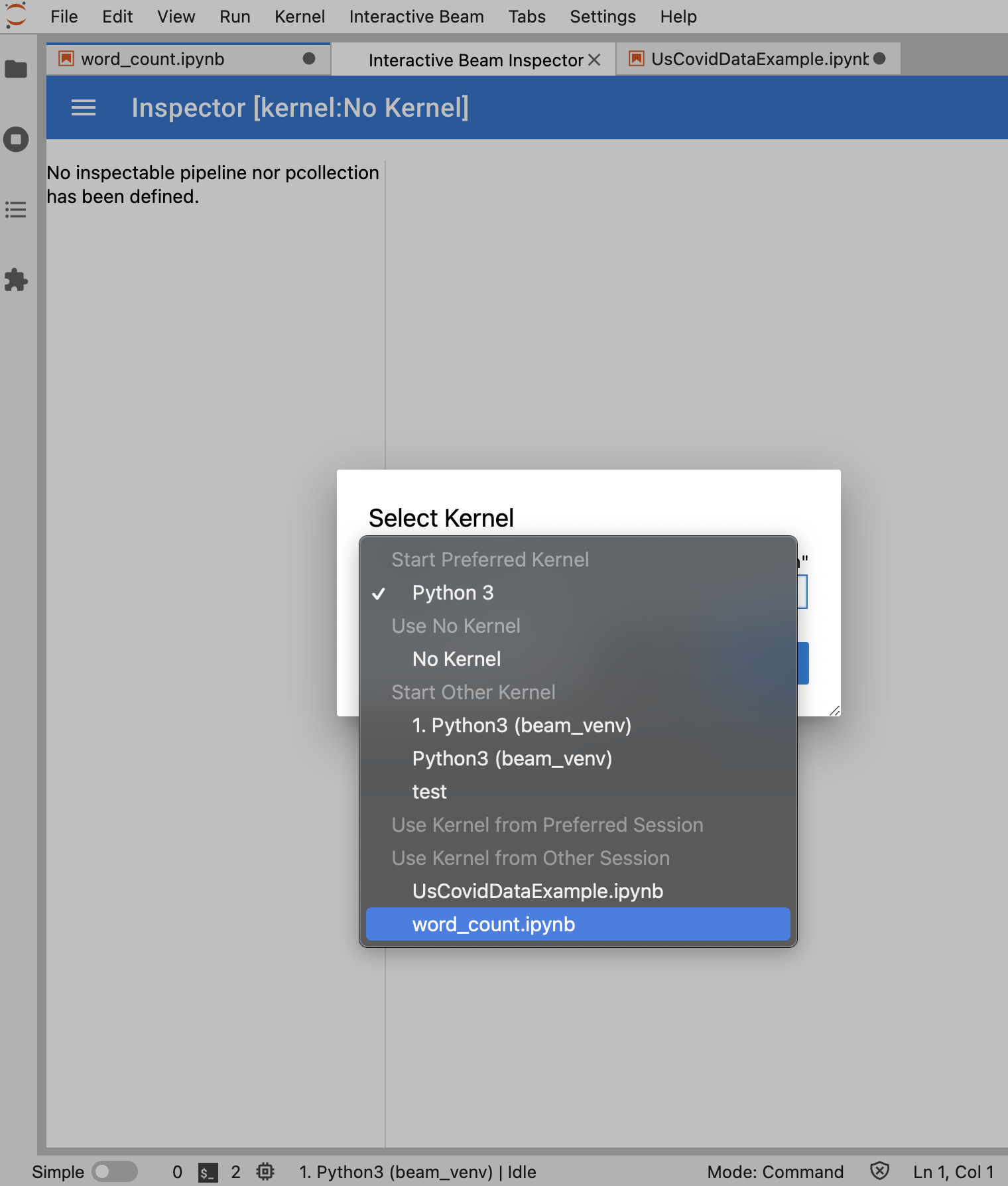
검사기를 열기 전 최소 1개의 노트북을 열고 커널을 선택하는 것이 좋습니다. 노트북을 열기 전 커널로 검사기를 열면 나중에 검사기에 연결할 노트북을 열 때 Use
Kernel from Preferred Session에서 Interactive Beam Inspector Session을 선택해야 합니다. 검사기 및 노트북은 동일한 커널에서 만든 다른 세션이 아니라 동일한 세션을 공유할 때 연결됩니다. Start Preferred Kernel에서 동일한 커널을 선택하면 열린 노트북 또는 검사기의 기존 세션과 독립적인 새 세션이 생성됩니다.
열린 노트북에 대해 여러 검사기를 열고 작업공간에 해당 탭을 자유롭게 드래그 앤 드롭하여 검사기를 배열할 수 있습니다.
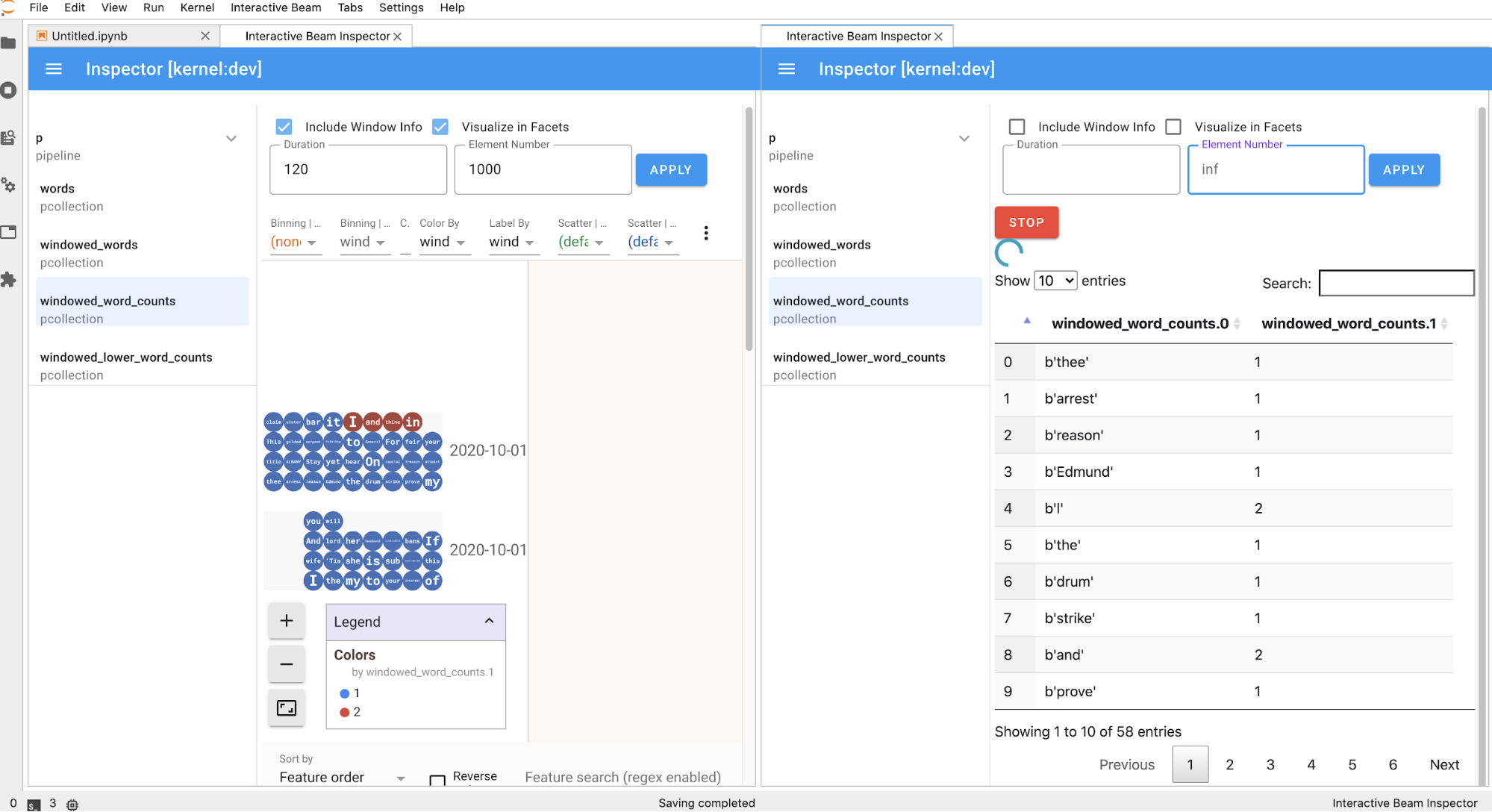
노트북에서 셀을 실행하면 검사기 페이지가 자동으로 새로고침됩니다. 연결된 노트북에 정의된 파이프라인과 PCollections가 페이지에 나열됩니다. PCollections는 속하는 파이프라인에 따라 정리되며 헤더 파이프라인을 클릭하여 축소할 수 있습니다.
파이프라인 및 PCollections 목록에서 항목을 클릭하면 검사기가 오른쪽에서 해당 시각화를 렌더링합니다.
PCollection인 경우에는 검사기가APPLY버튼을 클릭한 후 시각화를 조정하는 추가 위젯과 함께 데이터를 렌더링합니다(데이터가 계속 unboundedPCollections에 대해 수신되는 경우에는 동적으로).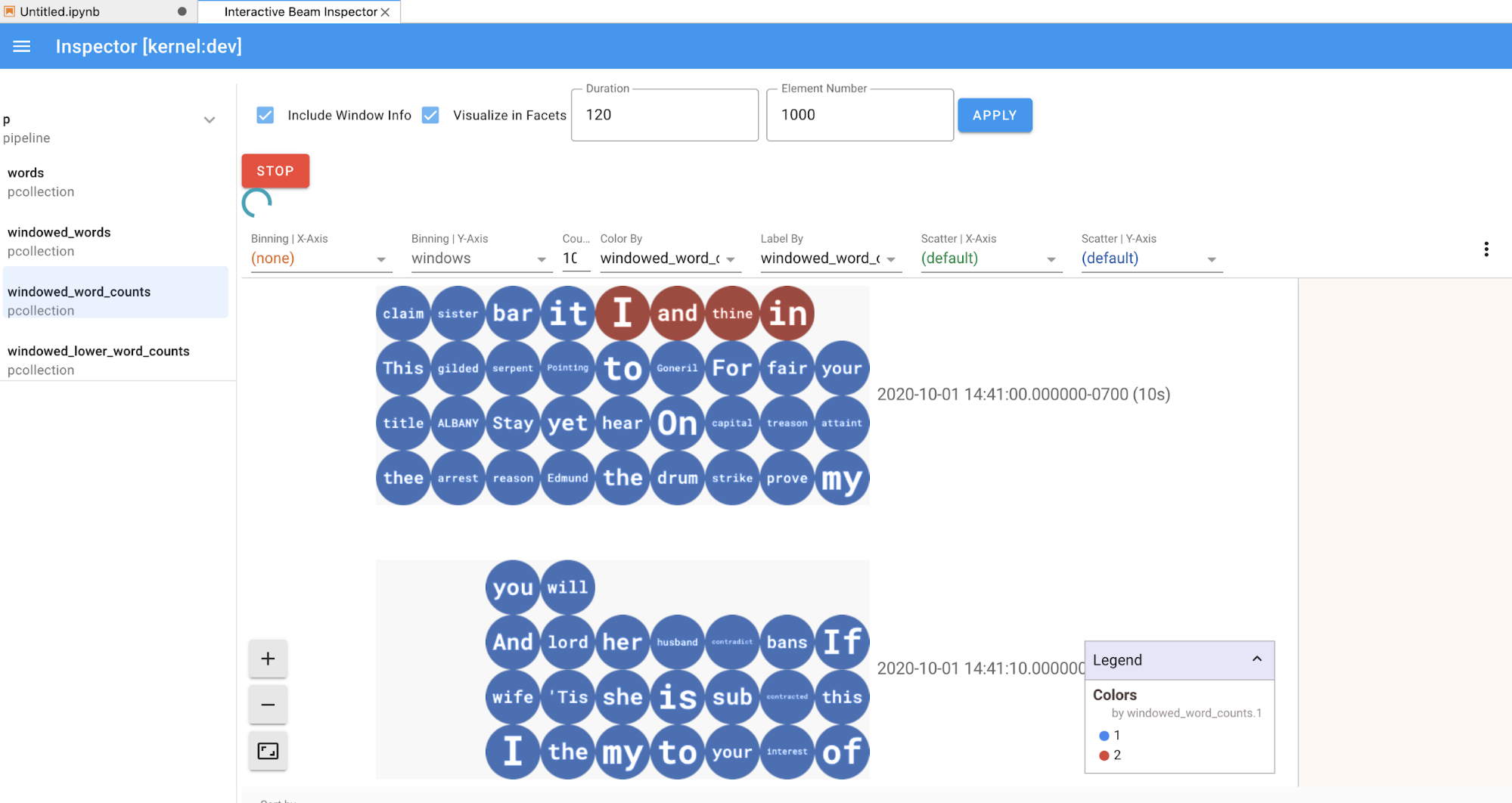
검사기와 열린 노트북은 동일한 커널 세션을 공유하기 때문에 서로 실행을 차단합니다. 예를 들어 노트북이 코드를 실행 중이라면 노트북의 실행이 완료될 때까지 검사기가 업데이트되지 않습니다. 반대로 검사기가
PCollection을 동적으로 시각화하는 동안 노트북에서 일부 코드를 즉시 실행하려면STOP버튼을 클릭하여 시각화를 중지하고 선점형으로 커널을 노트북에 릴리스해야 합니다.파이프라인의 경우 검사기가 파이프라인 그래프를 표시합니다.
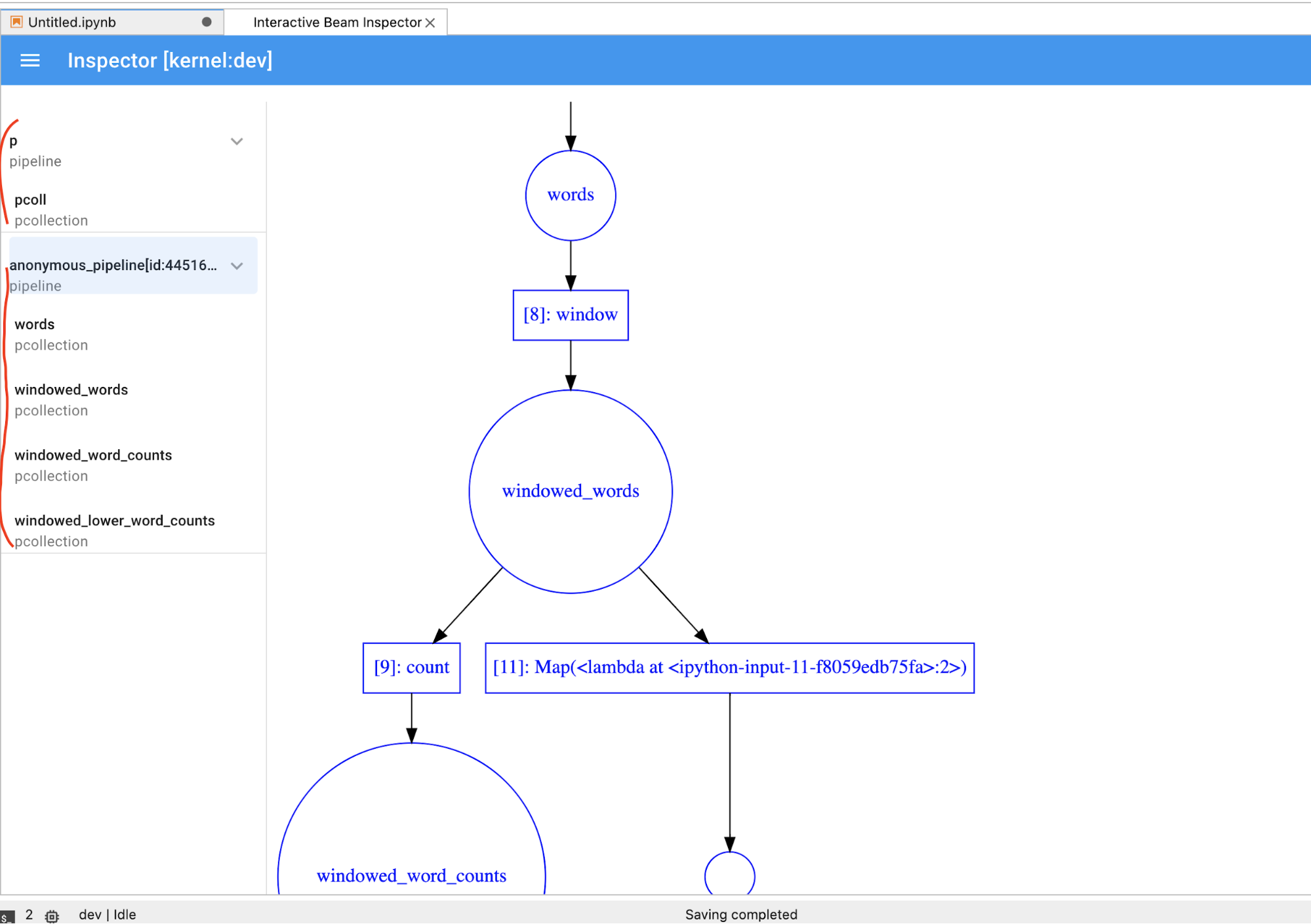
익명의 파이프라인이 표시될 수 있습니다. 이러한 파이프라인에는 액세스할 수 있는 PCollections가 있지만 더 이상 기본 세션에서 참조되지 않습니다. 예를 들면 다음과 같습니다.
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
이전 예시에서는 비어 있는 파이프라인 p 및 하나의 PCollection pcoll을 포함하는 익명의 파이프라인을 생성합니다. pcoll.pipeline을 사용하여 익명 파이프라인에 액세스할 수 있습니다.
파이프라인과 PCollection 목록을 전환하여 큰 시각화의 공간을 절약할 수 있습니다.
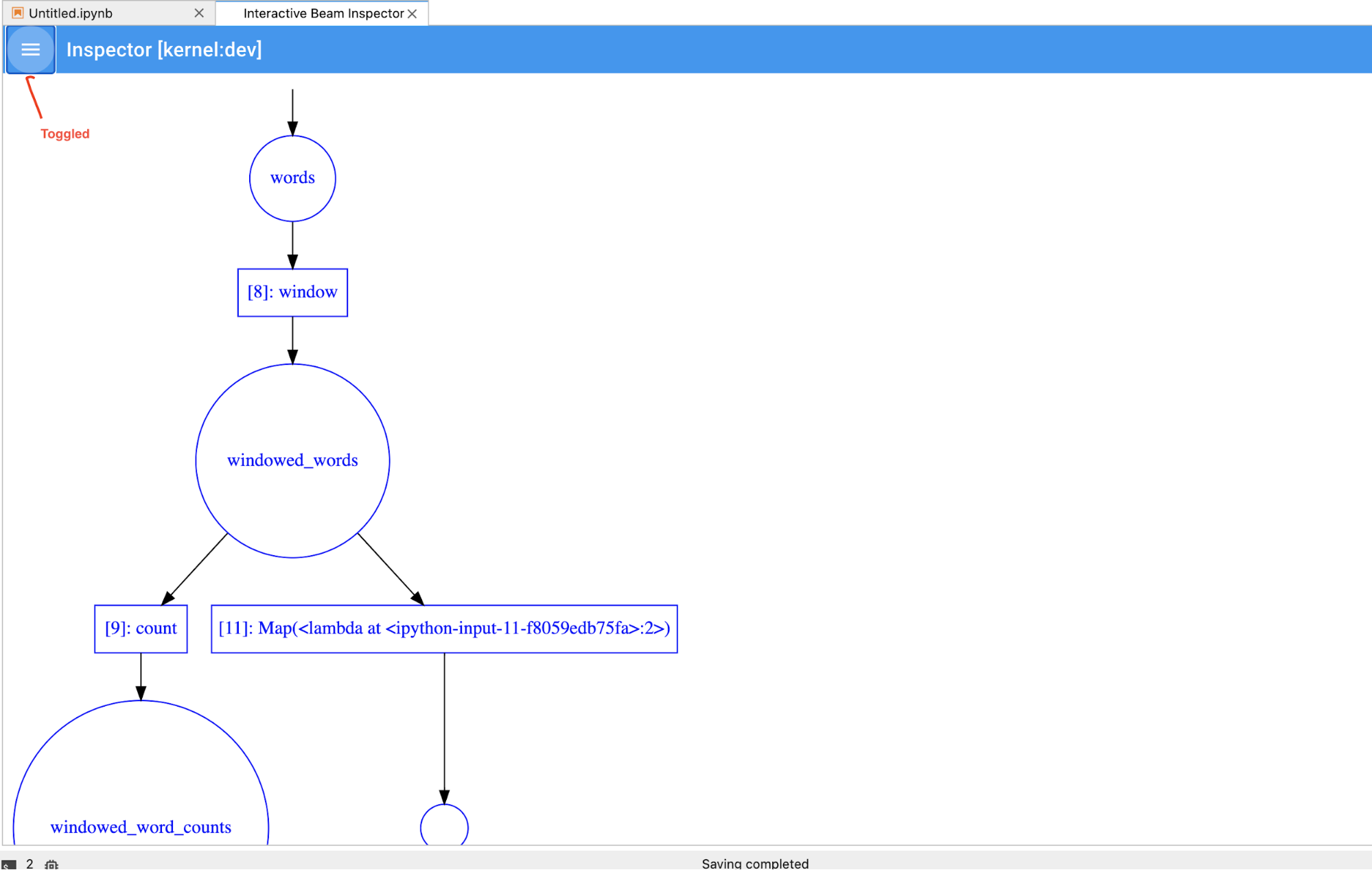
파이프라인의 기록 상태 이해
시각화를 제공할 뿐만 아니라 describe를 호출하여 노트북 인스턴스에 있는 1개 또는 모든 파이프라인의 기록 상태를 검사할 수도 있습니다.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
describe() 메서드는 다음 세부정보를 제공합니다.
- 디스크에 저장된 파이프라인의 모든 기록 파일의 총 크기(바이트)
- 백그라운드 기록 작업이 시작된 시작 시간(초 단위, Unix 에포크 기준)
- 백그라운드 기록 작업의 현재 파이프라인 상태
- 파이프라인의 Python 변수
노트북에서 만든 파이프라인에서 Dataflow 작업 실행
- 선택사항: Dataflow 작업을 실행하기 전에 노트북을 사용하여 커널을 다시 시작한 다음 모든 셀을 다시 실행하고 출력을 확인합니다. 이 단계를 건너뛰면 노트북의 숨겨진 상태가 파이프라인 객체의 작업 그래프에 영향을 줄 수 있습니다.
- Dataflow API를 사용 설정합니다.
다음 import 문을 추가합니다.
from apache_beam.runners import DataflowRunner파이프라인 옵션을 전달합니다.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)매개변수 값을 조정할 수 있습니다. 예를 들어
us-central1에서region값을 변경할 수 있습니다.DataflowRunner를 사용하여 파이프라인을 실행합니다. 이 단계에서 Dataflow 서비스에서 작업을 실행합니다.runner = DataflowRunner() runner.run_pipeline(p, options=options)p은 파이프라인 만들기의 파이프라인 객체입니다.
대화형 노트북에서 이 변환을 수행하는 방법에 대한 예시는 노트북 인스턴스의 Dataflow 단어 수 노트북을 참조하세요.
또는 노트북을 실행 가능한 스크립트로 내보내고 이전 단계를 사용하여 생성된 .py 파일을 수정한 다음 Dataflow 서비스에 파이프라인을 배포할 수 있습니다.
노트북 저장
생성된 노트북은 실행 중인 노트북 인스턴스에 로컬로 저장됩니다. 개발 중에 노트북 인스턴스를 재설정하거나 종료하는 경우 새 노트북은 /home/jupyter 디렉터리에 만드는 한 유지됩니다.
하지만 노트북 인스턴스가 삭제되면 해당 노트북도 삭제됩니다.
나중에 사용할 수 있도록 노트북을 로컬에 다운로드하거나 GitHub에 저장하거나 다른 파일 형식으로 내보냅니다.
노트북을 추가 영구 디스크에 저장
노트북 및 스크립트와 같은 작업을 다양한 노트북 인스턴스에서 유지하려면 Persistent Disk에 저장하세요.
Persistent Disk를 만들거나 연결합니다. 안내에 따라
ssh를 사용하여 노트북 인스턴스의 VM에 연결하고 열린 Cloud Shell에서 명령어를 실행합니다.Persistent Disk가 마운트된 디렉터리를 확인합니다(예:
/mnt/myDisk).노트북 인스턴스의 VM 세부정보를 수정하여
Custom metadata에 다음 항목을 추가합니다. 키 -container-custom-params, 값 --v /mnt/myDisk:/mnt/myDisk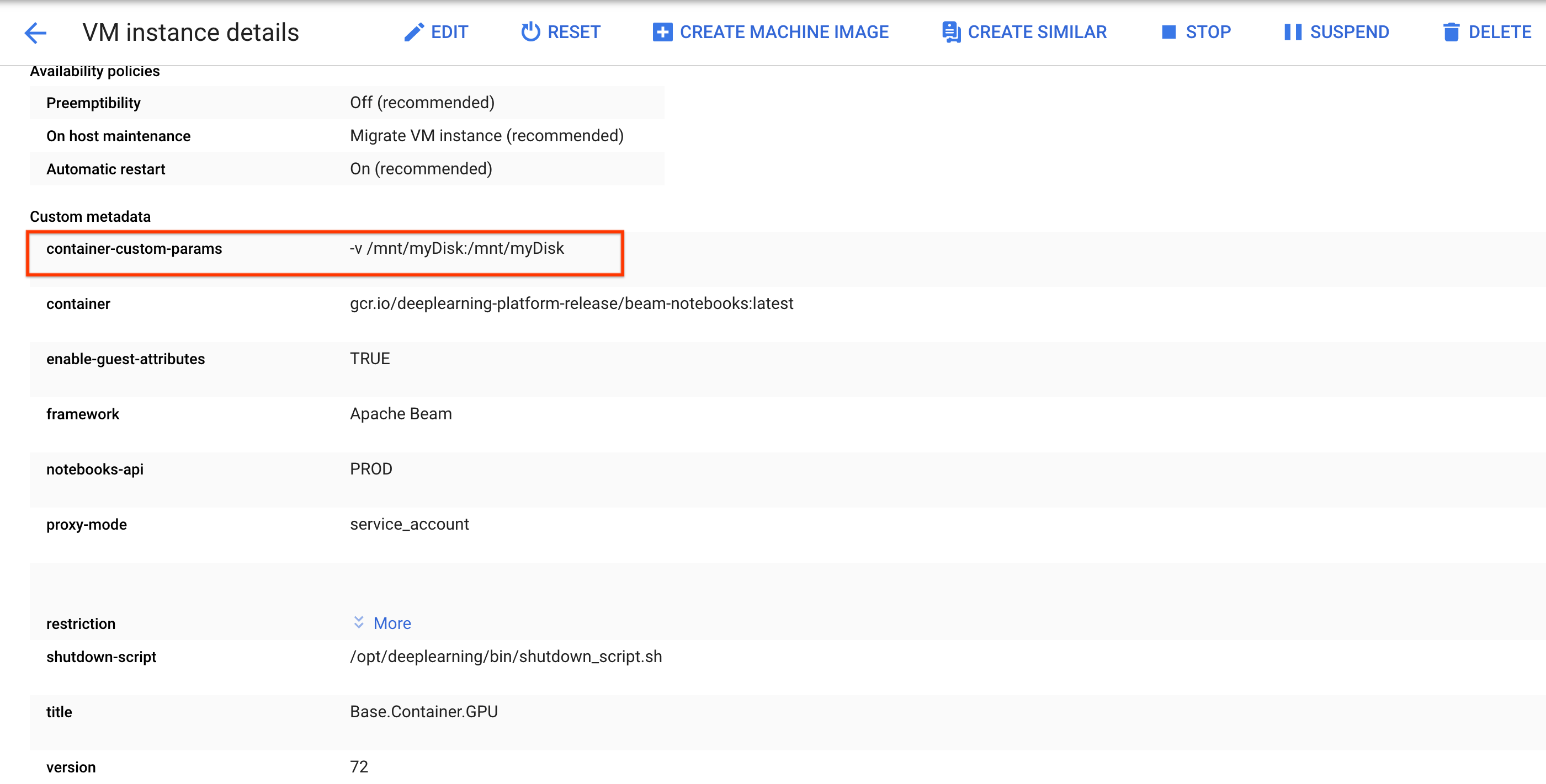
저장을 클릭합니다.
이러한 변경사항을 업데이트하려면 노트북 인스턴스를 재설정하세요.
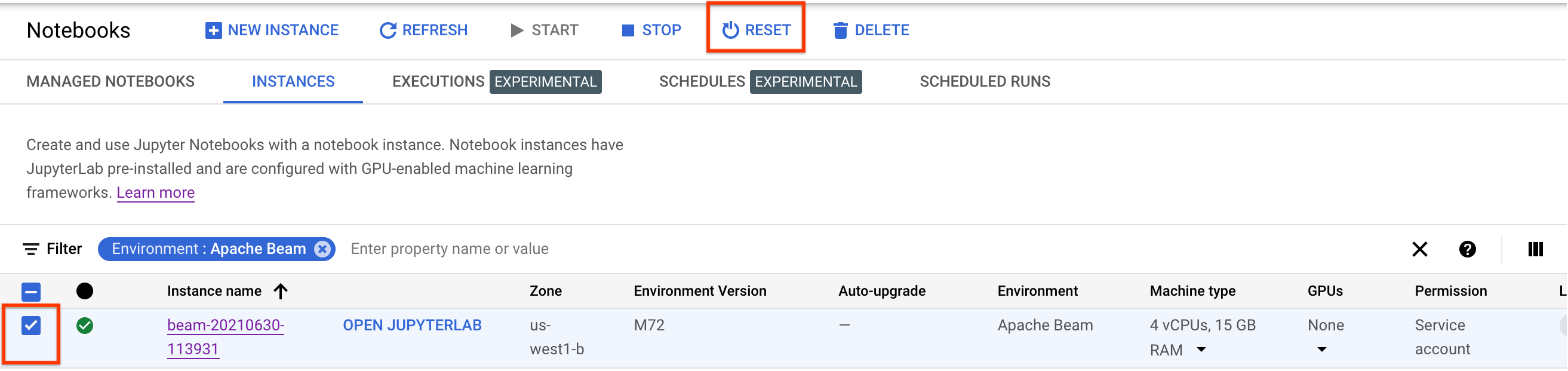
재설정 후 JupyterLab 열기를 클릭합니다. JupyterLab UI를 사용할 수 있게 될 때까지 시간이 조금 걸릴 수 있습니다. UI가 표시되면 터미널을 열고
ls -al /mnt명령어를 실행합니다. 그러면/mnt/myDisk디렉터리가 나열됩니다.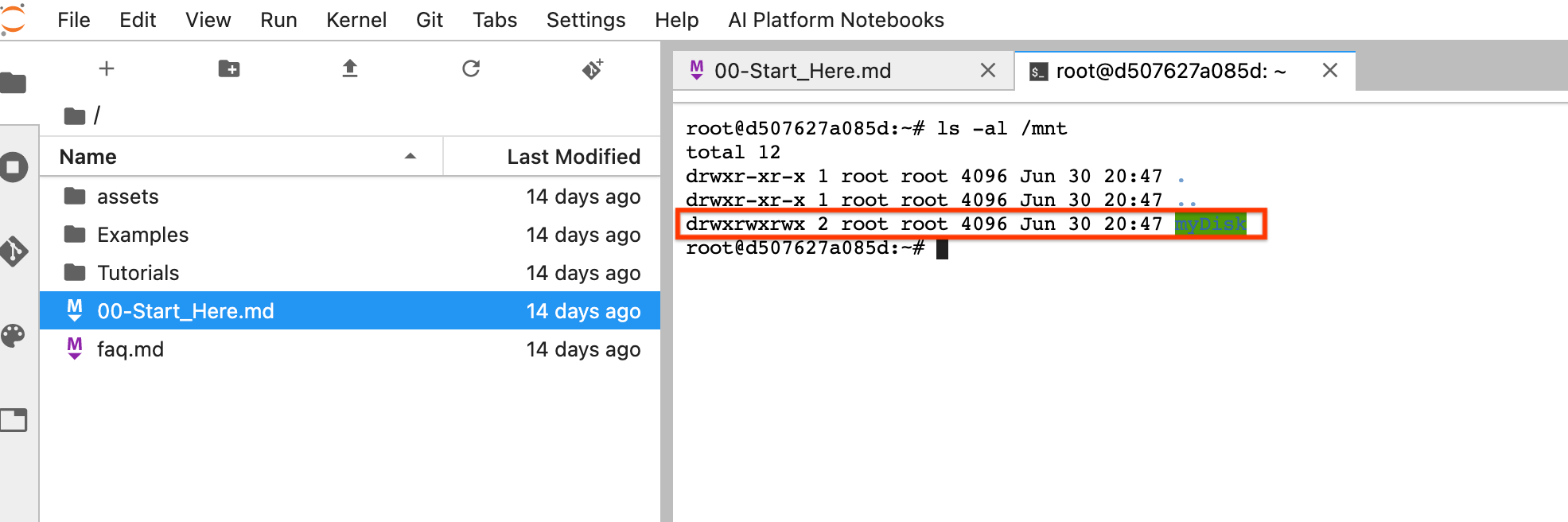
이제 /mnt/myDisk 디렉터리에 작업을 저장할 수 있습니다. 노트북 인스턴스가 삭제되더라도 Persistent Disk는 프로젝트에 계속 존재합니다. 그런 다음 이 Persistent Disk를 다른 노트북 인스턴스에 연결할 수 있습니다.
삭제
Apache Beam 노트북 인스턴스 사용을 마친 후에는 노트북 인스턴스를 종료하여 Google Cloud 에서 만든 리소스를 삭제합니다.
다음 단계
- Apache Beam 노트북에서 사용할 수 있는 고급 기능에 관해 알아봅니다. 고급 기능에는 다음 워크플로가 포함됩니다.