Gunakan runner interaktif Apache Beam dengan notebook JupyterLab untuk menyelesaikan tugas berikut:
- Mengembangkan pipeline secara iteratif.
- Periksa grafik pipeline Anda.
- Mengurai setiap
PCollectionsdalam alur kerja read-eval-print-loop (REPL).
Notebook Apache Beam ini tersedia melalui Vertex AI Workbench, layanan yang menghosting virtual machine notebook yang telah diinstal sebelumnya dengan framework data science dan machine learning terbaru. Dataflow hanya mendukung instance Workbench yang menggunakan penampung Apache Beam.
Panduan ini berfokus pada fitur yang diperkenalkan oleh notebook Apache Beam, tetapi tidak menunjukkan cara mem-build notebook. Untuk informasi selengkapnya tentang Apache Beam, lihat panduan pemrograman Apache Beam.
Dukungan dan batasan
- Notebook Apache Beam hanya mendukung Python.
- Segmen pipeline Apache Beam yang berjalan di notebook ini dijalankan di lingkungan pengujian, dan bukan di runner Apache Beam produksi. Untuk meluncurkan notebook di layanan Dataflow, ekspor pipeline yang dibuat di notebook Apache Beam Anda. Untuk mengetahui detail selengkapnya, lihat Meluncurkan tugas Dataflow dari pipeline yang dibuat di notebook.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Sebelum membuat instance notebook Apache Beam, aktifkan API tambahan untuk pipeline yang menggunakan layanan lain, seperti Pub/Sub.
Jika tidak ditentukan, instance notebook akan dijalankan oleh akun layanan Compute Engine default dengan peran editor project IAM. Jika project secara eksplisit membatasi peran akun layanan, pastikan project tersebut masih memiliki otorisasi yang cukup untuk menjalankan notebook Anda. Misalnya, membaca dari topik Pub/Sub secara implisit akan membuat langganan, dan akun layanan Anda memerlukan peran editor Pub/Sub IAM. Sebaliknya, membaca dari langganan Pub/Sub hanya memerlukan peran pelanggan Pub/Sub IAM.
Setelah menyelesaikan panduan ini, untuk menghindari penagihan berkelanjutan, hapus resource yang Anda buat. Untuk detail selengkapnya, lihat Pembersihan.
Meluncurkan instance notebook Apache Beam
Di konsol Google Cloud, buka halaman Workbench Dataflow.
Pastikan Anda berada di tab INSTANCES.
Di toolbar, klik Buat baru.
Di bagian Environment, untuk Environment, Container harus berupa Apache Beam. Hanya JupyterLab 3.x yang didukung untuk notebook Apache Beam.
Opsional: Jika Anda ingin menjalankan notebook di GPU, di bagian Machine type, pilih jenis mesin yang mendukung GPU. Untuk mengetahui informasi selengkapnya, lihat platform GPU.
Di bagian Networking, pilih subnetwork untuk VM notebook.
Opsional: Jika Anda ingin menyiapkan instance notebook kustom, lihat Membuat instance menggunakan penampung kustom.
Klik Buat. Dataflow Workbench membuat instance notebook Apache Beam baru.
Setelah instance notebook dibuat, link Open JupyterLab akan aktif. Klik Open JupyterLab.
Opsional: Menginstal dependensi
Notebook Apache Beam sudah dilengkapi dengan Apache Beam dan dependensi konektorGoogle Cloud yang diinstal. Jika pipeline Anda berisi
konektor kustom atau PTransforms kustom yang bergantung pada library pihak ketiga,
instal setelah Anda membuat instance notebook.
Contoh notebook Apache Beam
Setelah membuat instance notebook, buka di JupyterLab. Di tab Files di sidebar JupyterLab, folder Examples berisi contoh notebook. Untuk informasi selengkapnya tentang cara menggunakan file JupyterLab, lihat Menggunakan file dalam panduan pengguna JupyterLab.
Notebook berikut tersedia:
- Jumlah Kata
- Jumlah Kata Streaming
- Streaming Data Perjalanan Taksi NYC
- Apache Beam SQL di notebook dengan perbandingan ke pipeline
- Apache Beam SQL di notebook dengan Dataflow Runner
- Apache Beam SQL di notebook
- Jumlah Kata Dataflow
- Flink Interaktif dalam Skala Besar
- RunInference
- Menggunakan GPU dengan Apache Beam
- Visualisasikan Data
Folder Tutorial berisi tutorial tambahan yang menjelaskan dasar-dasar Apache Beam. Tutorial berikut tersedia:
- Operasi Dasar
- Operasi Element Wise
- Agregasi
- Windows
- Operasi I/O
- Streaming
- Latihan Akhir
Notebook ini menyertakan teks penjelasan dan blok kode yang diberi komentar untuk membantu Anda memahami konsep Apache Beam dan penggunaan API. Tutorial ini juga menyediakan latihan untuk Anda mempraktikkan konsep.
Bagian berikut menggunakan contoh kode dari notebook Streaming Word Count. Cuplikan kode dalam panduan ini dan yang ditemukan di notebook Streaming Word Count mungkin memiliki perbedaan kecil.
Buat instance notebook
Buka File > New > Notebook, lalu pilih kernel yang merupakan Apache Beam 2.22 atau yang lebih baru.
Notebook Apache Beam dibuat berdasarkan cabang master Apache Beam SDK. Artinya, versi kernel terbaru yang ditampilkan di UI notebook mungkin lebih baru dari versi SDK yang baru dirilis.
Apache Beam diinstal di instance notebook Anda, jadi sertakan modul interactive_runner dan interactive_beam di notebook Anda.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Jika notebook Anda menggunakan Google API lainnya, tambahkan pernyataan impor berikut:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Menetapkan opsi interaktivitas
Baris berikut menetapkan jumlah waktu InteractiveRunner merekam data dari sumber yang tidak terbatas. Dalam contoh ini, durasi ditetapkan ke 10 menit.
ib.options.recording_duration = '10m'
Anda juga dapat mengubah batas ukuran rekaman (dalam byte) untuk sumber tanpa batas
menggunakan properti recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Untuk opsi interaktif tambahan, lihat class interactive_beam.options.
Membuat pipeline
Lakukan inisialisasi pipeline menggunakan objek InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Membaca dan memvisualisasikan data
Contoh berikut menunjukkan pipeline Apache Beam yang membuat langganan ke topik Pub/Sub tertentu dan membaca dari langganan.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
Pipeline menghitung kata berdasarkan periode dari sumber. Fungsi ini membuat periode tetap dengan durasi setiap periode 10 detik.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Setelah data dikelompokkan, kata-kata dihitung berdasarkan kelompok.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Metode show() memvisualisasikan PCollection yang dihasilkan di notebook.
ib.show(windowed_word_counts, include_window_info=True)
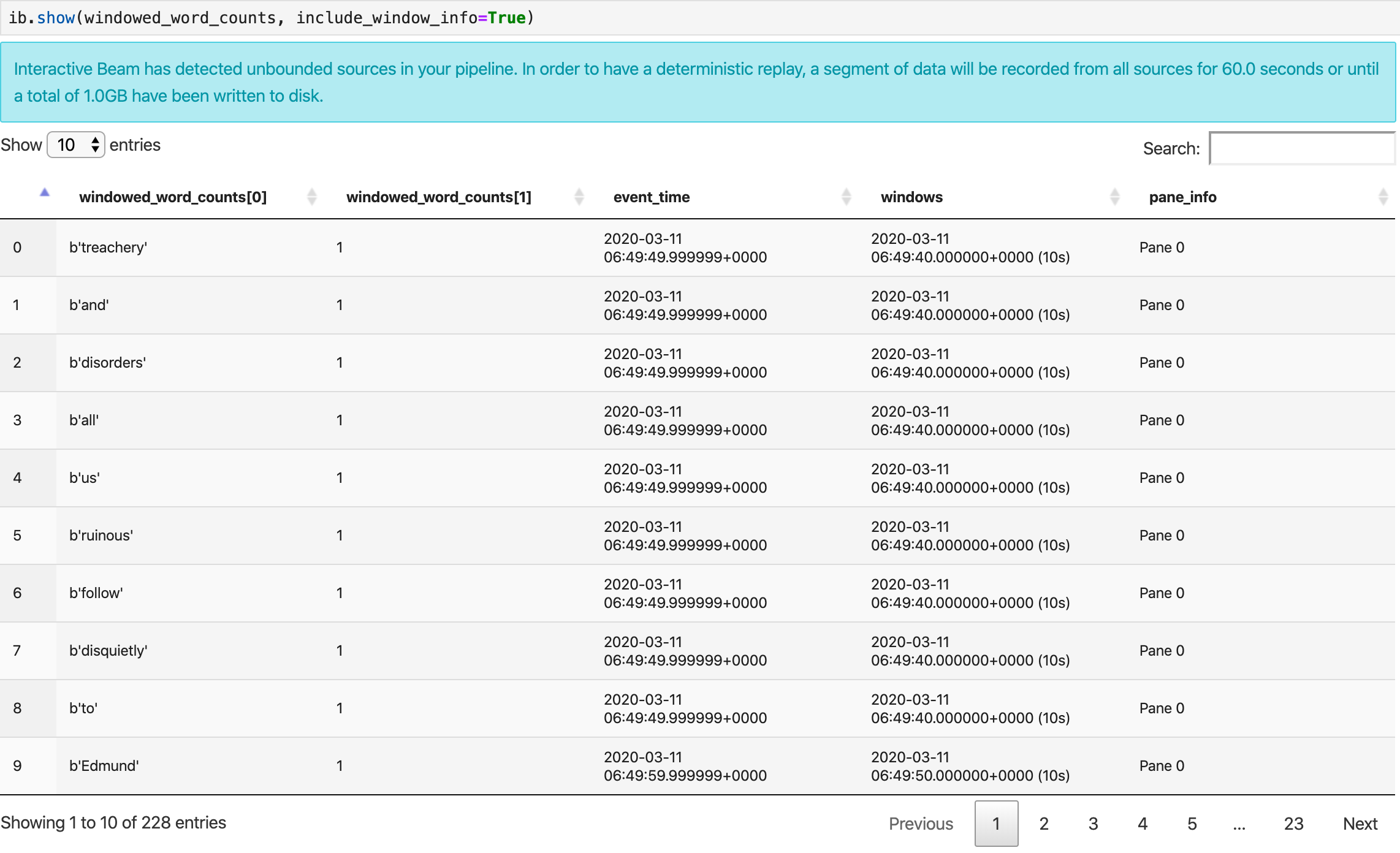
Anda dapat menjangkau kumpulan hasil kembali dari show() dengan menetapkan dua parameter
opsional: n dan duration.
- Tetapkan
nuntuk membatasi kumpulan hasil agar menampilkan maksimalnelemen, seperti 20. Jikantidak ditetapkan, perilaku default-nya adalah mencantumkan elemen terbaru yang diambil hingga perekaman sumber selesai. - Tetapkan
durationuntuk membatasi kumpulan hasil ke jumlah data detik tertentu yang dimulai dari awal rekaman sumber. Jikadurationtidak ditetapkan, perilaku default-nya adalah mencantumkan semua elemen hingga perekaman selesai.
Jika kedua parameter opsional ditetapkan, show() akan berhenti setiap kali salah satu nilai minimum terpenuhi. Dalam contoh berikut, show() menampilkan maksimal 20 elemen yang dihitung berdasarkan data selama 30 detik pertama dari sumber yang direkam.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Untuk menampilkan visualisasi data, teruskan visualize_data=True ke dalam
metode show(). Anda dapat menerapkan beberapa filter ke visualisasi. Visualisasi
berikut memungkinkan Anda memfilter menurut label dan sumbu:
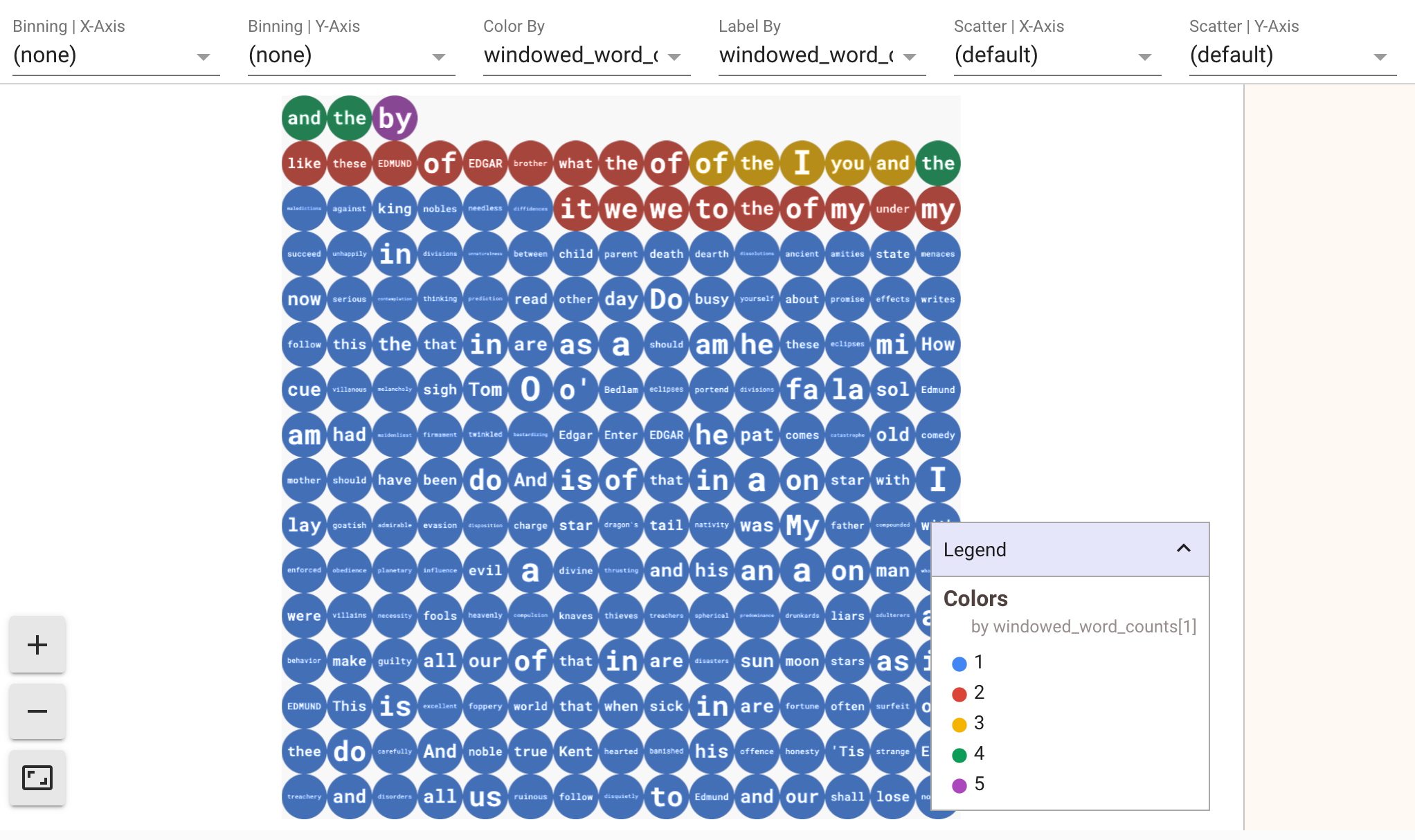
Untuk memastikan pemutaran ulang saat membuat prototipe pipeline streaming, metode show() memanggil penggunaan kembali data yang diambil secara default. Untuk mengubah perilaku
ini dan membuat metode show() selalu mengambil data baru, tetapkan
interactive_beam.options.enable_capture_replay = False. Selain itu, jika Anda menambahkan
sumber tak terbatas kedua ke notebook, data dari sumber tak terbatas
sebelumnya akan dihapus.
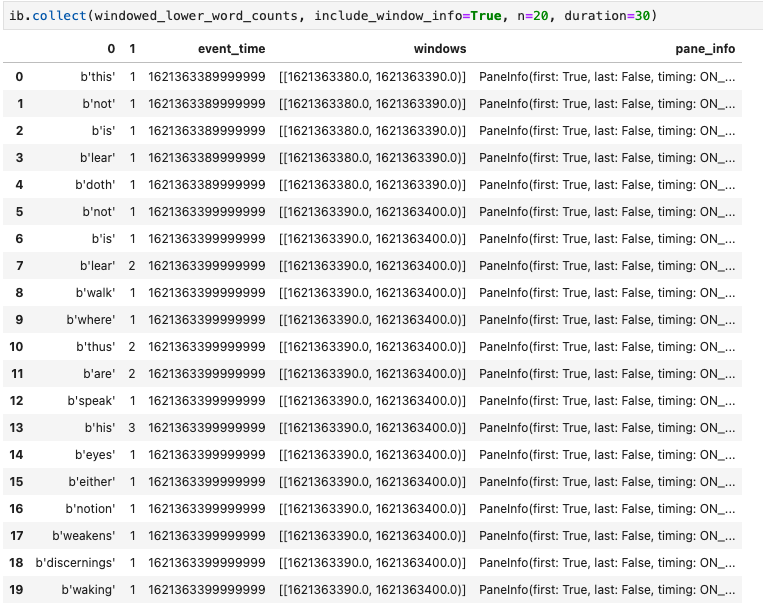
Visualisasi lain yang berguna di notebook Apache Beam adalah Pandas DataFrame. Contoh berikut pertama-tama mengonversi kata menjadi huruf kecil, lalu menghitung frekuensi setiap kata.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
Metode collect() memberikan output dalam DataFrame Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
Mengedit dan menjalankan ulang sel adalah praktik umum dalam pengembangan
notebook. Saat Anda mengedit dan menjalankan ulang sel di notebook Apache Beam,
sel tidak akan mengurungkan tindakan kode yang diinginkan di sel asli. Misalnya, jika sel menambahkan PTransform ke pipeline, menjalankan ulang sel tersebut
akan menambahkan PTransform tambahan ke pipeline. Jika Anda ingin menghapus status,
mulai ulang kernel, lalu jalankan kembali sel.
Memvisualisasikan data melalui Interactive Beam Inspector
Anda mungkin merasa terganggu untuk mengintropeksi data PCollection dengan
terus memanggil show() dan collect(), terutama jika output menghabiskan
banyak ruang di layar dan mempersulit navigasi melalui
notebook. Anda juga dapat membandingkan beberapa PCollections secara berdampingan untuk memvalidasi apakah transformasi berfungsi sebagaimana mestinya. Misalnya, saat satu PCollection
melakukan transformasi dan menghasilkan yang lain. Untuk kasus penggunaan ini, Interactive Beam inspector adalah solusi yang praktis.
Beam Inspector interaktif disediakan sebagai ekstensi JupyterLab
apache-beam-jupyterlab-sidepanel
yang telah diinstal sebelumnya di notebook Apache Beam. Dengan ekstensi ini,
Anda dapat memeriksa status pipeline dan data yang terkait dengan
setiap PCollection secara interaktif tanpa memanggil show() atau collect() secara eksplisit.
Ada 3 cara untuk membuka inspector:
Klik
Interactive Beamdi panel menu atas JupyterLab. Di menu dropdown, temukanOpen Inspector, lalu klik untuk membuka inspector.
Gunakan halaman peluncur. Jika tidak ada halaman peluncur yang terbuka, klik
File->New Launcheruntuk membukanya. Di halaman peluncur, temukanInteractive Beamdan klikOpen Inspectoruntuk membuka inspector.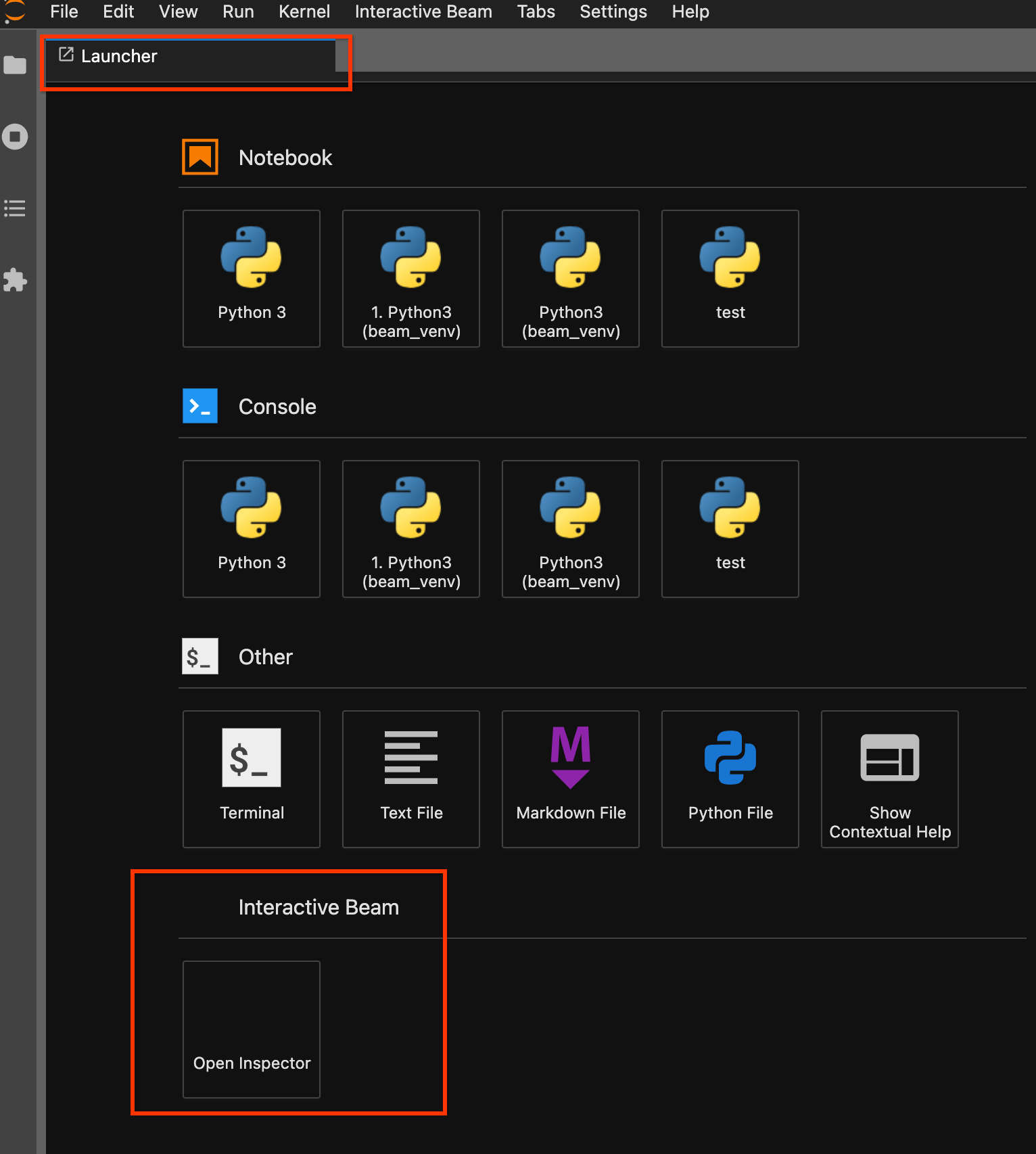
Gunakan palet perintah. Pada panel menu JupyterLab, klik
View>Activate Command Palette. Dalam dialog, telusuriInteractive Beamuntuk mencantumkan semua opsi ekstensi. KlikOpen Inspectoruntuk membuka inspector.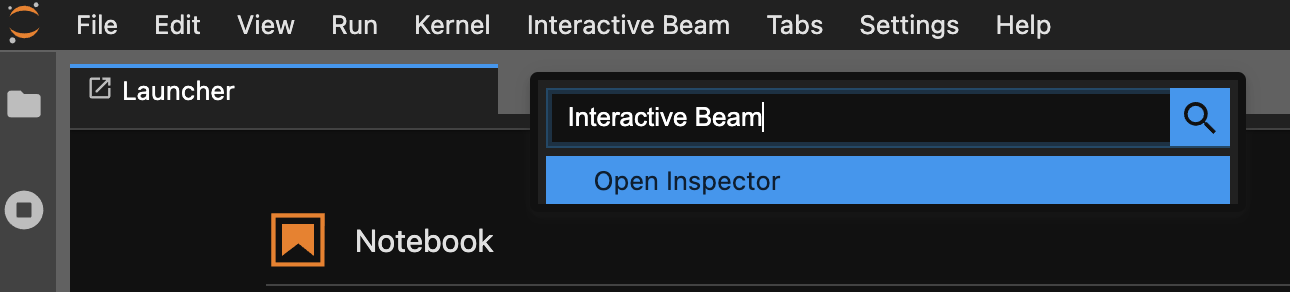
Saat pemeriksa akan terbuka:
Jika hanya ada satu notebook yang terbuka, inspector akan otomatis terhubung ke notebook tersebut.
Jika tidak ada notebook yang terbuka, dialog akan muncul yang memungkinkan Anda memilih kernel.
Jika beberapa notebook terbuka, dialog akan muncul yang memungkinkan Anda memilih sesi notebook.
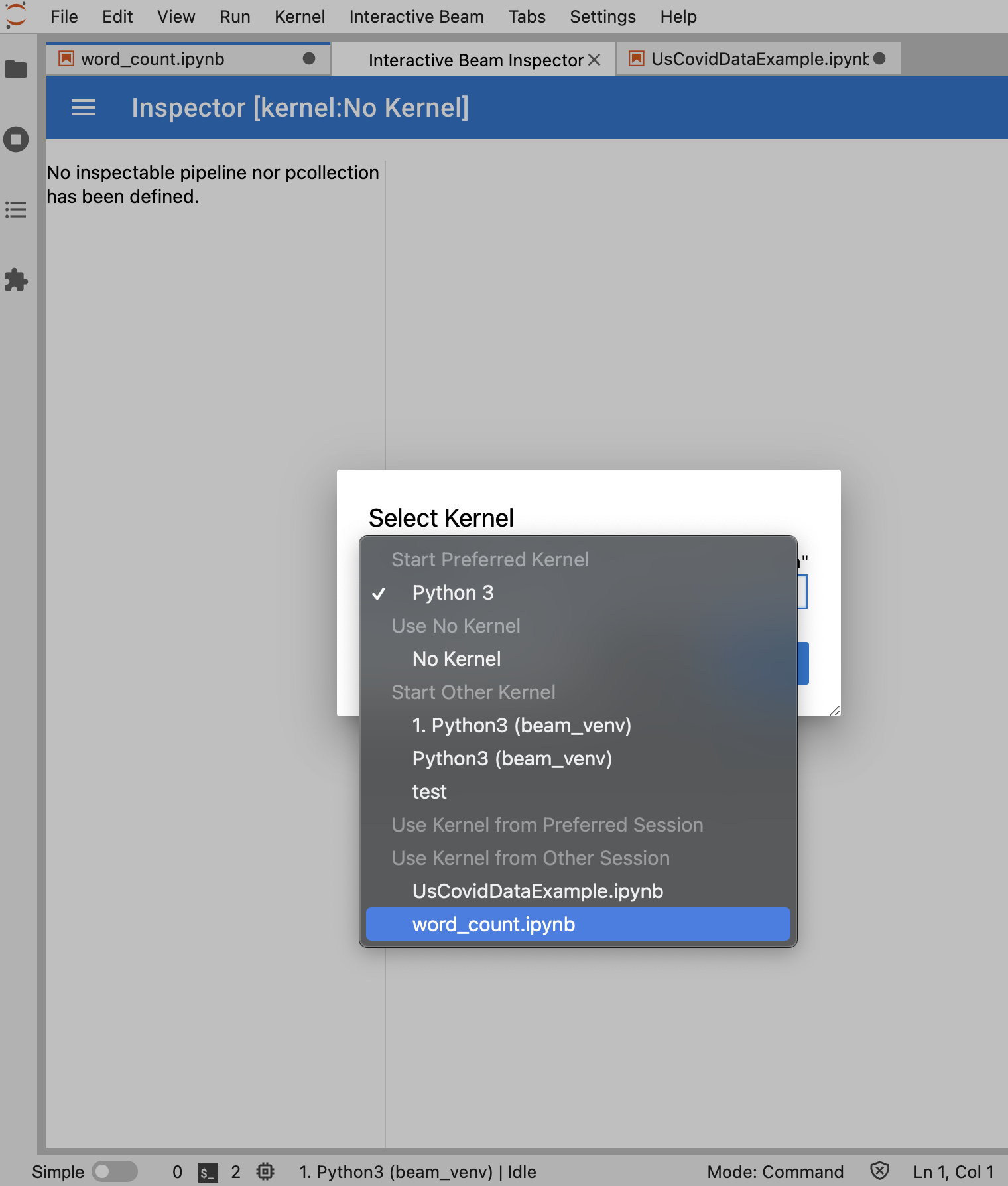
Sebaiknya buka minimal satu notebook dan pilih kernel untuknya
sebelum membuka inspector. Jika Anda membuka inspector dengan kernel sebelum
membuka notebook, nanti saat membuka notebook untuk terhubung ke
inspector, Anda harus memilih Interactive Beam Inspector Session dari Use
Kernel from Preferred Session. Inspector dan notebook terhubung saat
mereka berbagi sesi yang sama, bukan sesi yang berbeda yang dibuat dari kernel
yang sama. Memilih kernel yang sama dari Start Preferred Kernel akan membuat
sesi baru yang independen dari sesi notebook atau
inspector yang terbuka.
Anda dapat membuka beberapa inspector untuk notebook yang terbuka dan mengatur inspector dengan menarik lalu melepas tabnya secara bebas di ruang kerja.
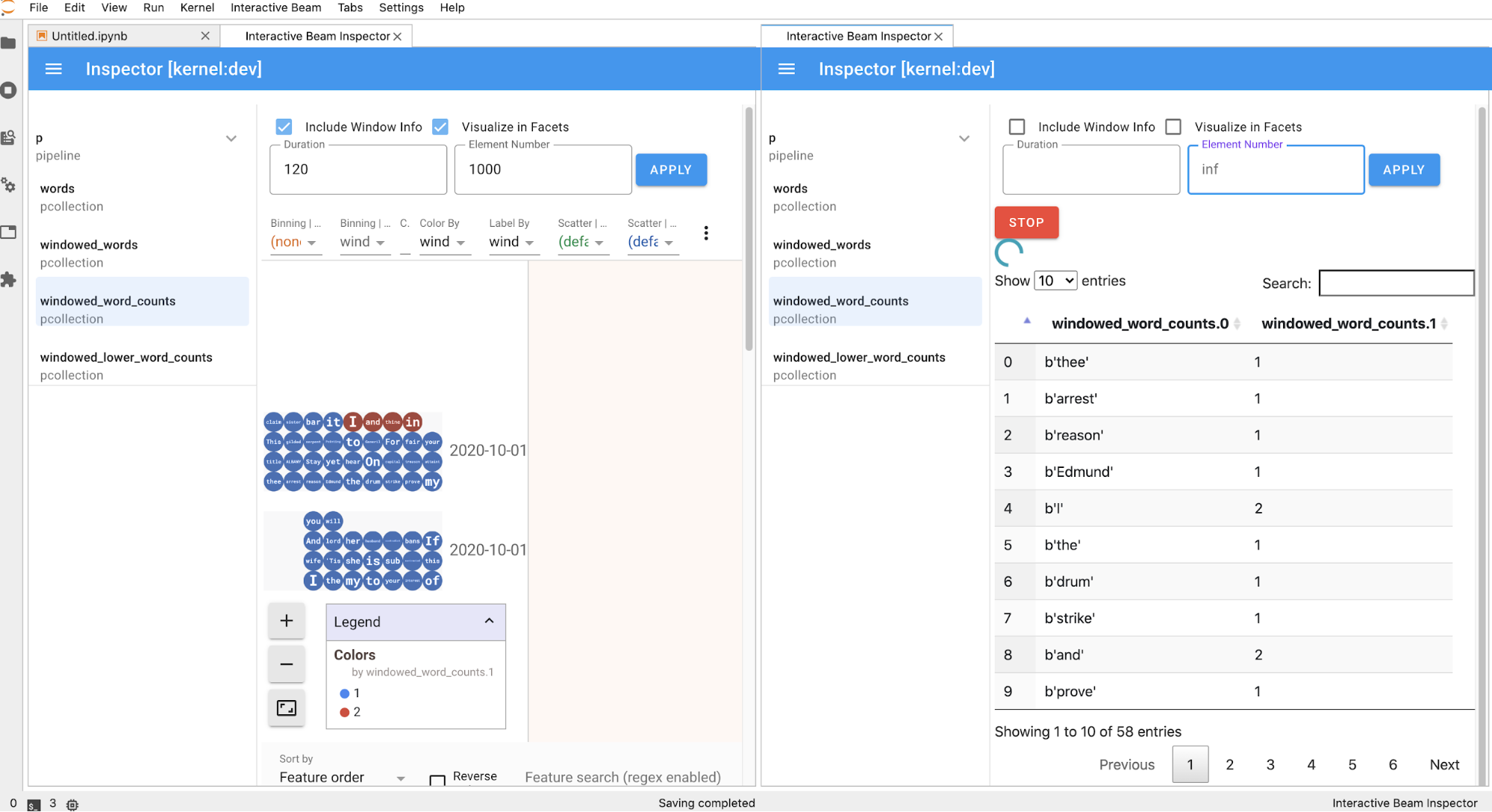
Halaman inspector akan otomatis dimuat ulang saat Anda menjalankan sel di
notebook. Halaman ini mencantumkan pipeline dan PCollections yang ditentukan dalam
notebook yang terhubung. PCollections diatur berdasarkan pipeline tempatnya berada, dan Anda dapat menciutkannya dengan mengklik pipeline header.
Untuk item dalam pipeline dan daftar PCollections, saat diklik, inspector akan merender visualisasi yang sesuai di sisi kanan:
Jika berupa
PCollection, inspector akan merender datanya (secara dinamis jika data masih masuk untukPCollectionsyang tidak dibatasi) dengan widget tambahan untuk menyesuaikan visualisasi setelah mengklik tombolAPPLY.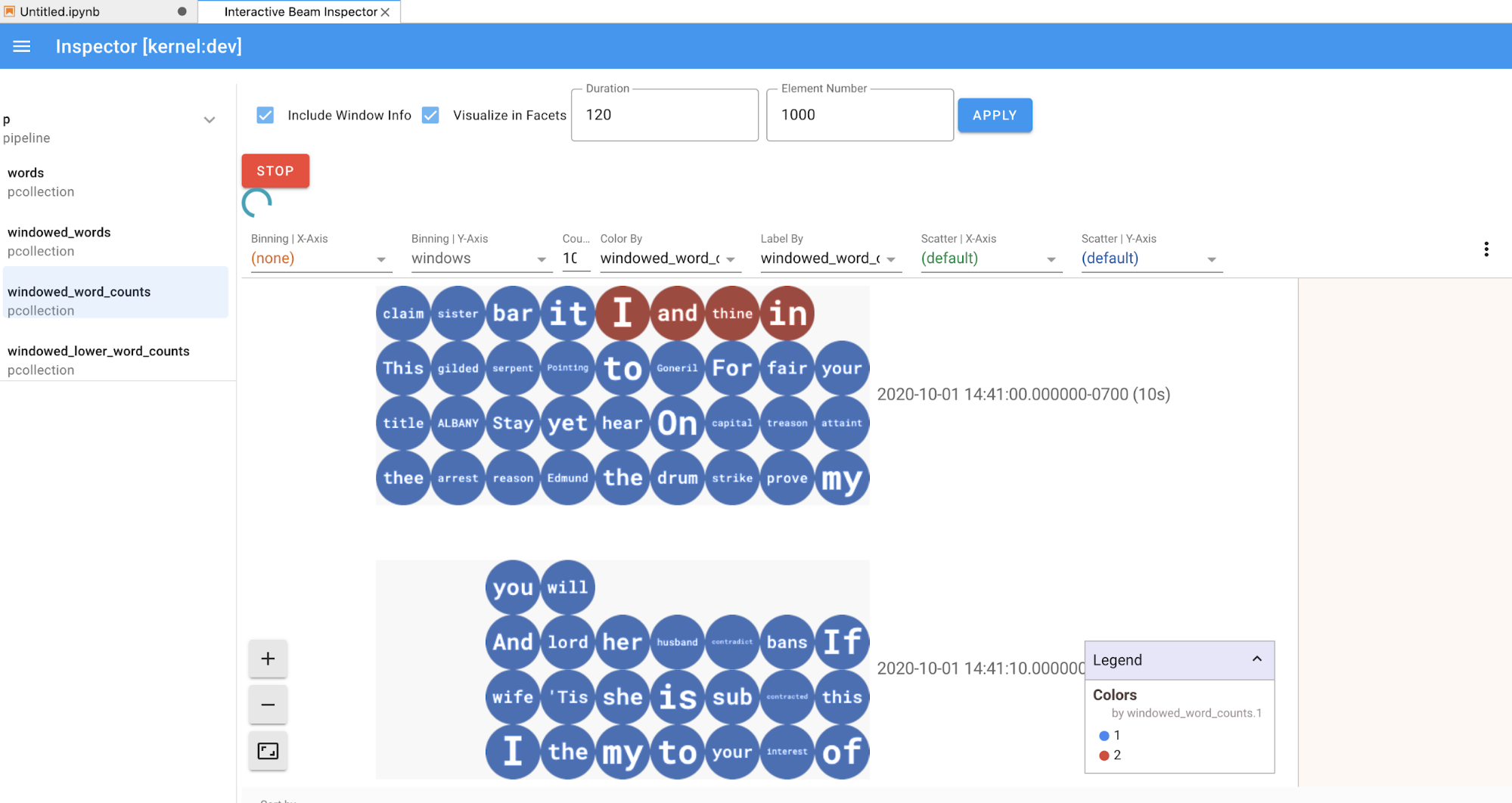
Karena inspector dan notebook yang dibuka memiliki sesi kernel yang sama, keduanya saling memblokir agar tidak berjalan. Misalnya, jika notebook sibuk menjalankan kode, inspector tidak akan diperbarui hingga notebook menyelesaikan eksekusi tersebut. Sebaliknya, jika ingin segera menjalankan kode di notebook saat inspector memvisualisasikan
PCollectionsecara dinamis, Anda harus mengklik tombolSTOPuntuk menghentikan visualisasi dan merilis kernel ke notebook secara preventif.Jika merupakan pipeline, pemeriksa akan menampilkan grafik pipeline.
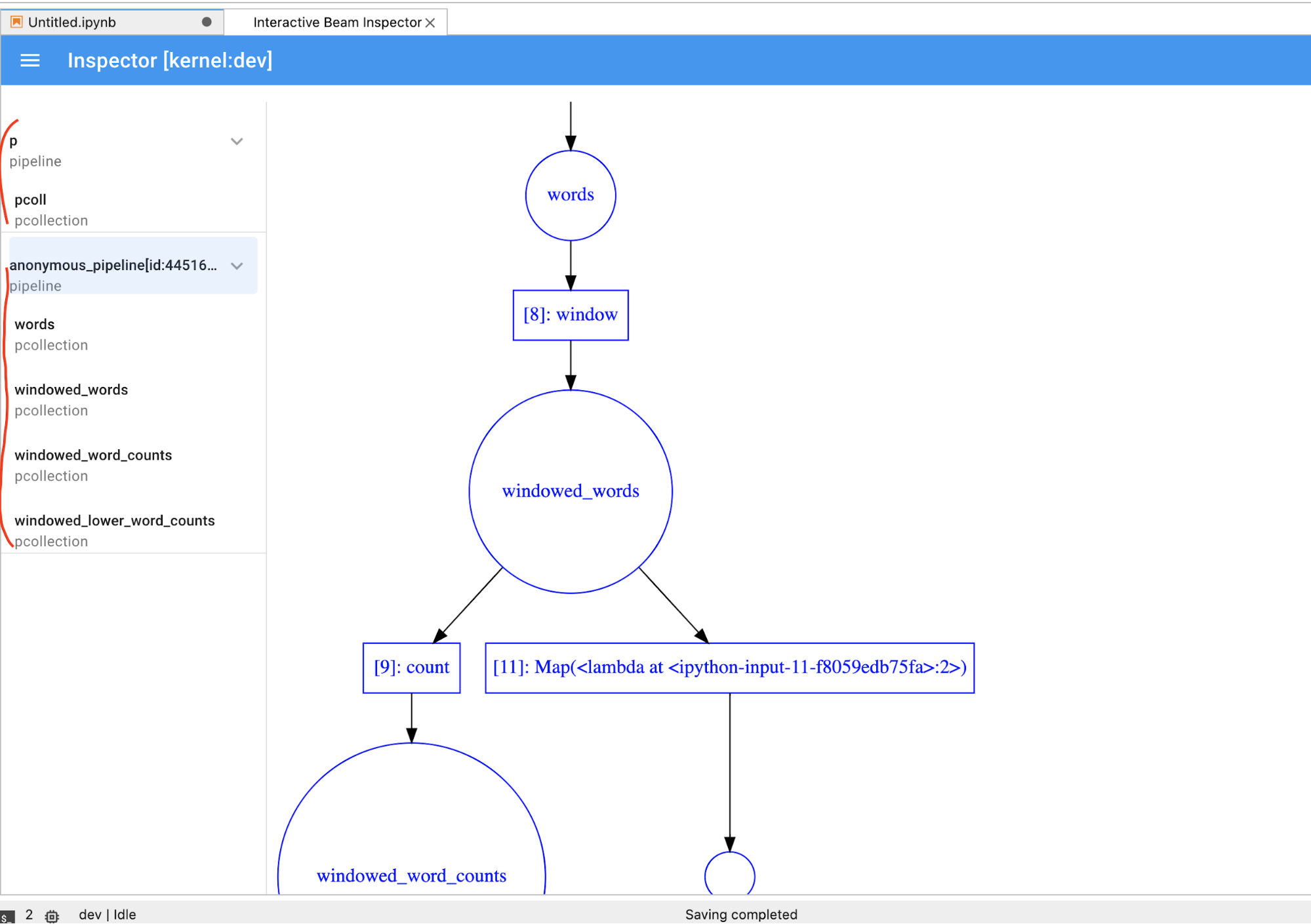
Anda mungkin melihat pipeline anonim. Pipeline tersebut memiliki
PCollections yang dapat Anda akses, tetapi tidak lagi direferensikan oleh sesi
utama. Contoh:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
Contoh sebelumnya membuat pipeline kosong p dan pipeline anonim yang
berisi satu PCollection pcoll. Anda dapat mengakses pipeline anonim
menggunakan pcoll.pipeline.
Anda dapat mengalihkan pipeline dan daftar PCollection untuk menghemat ruang bagi
visualisasi besar.
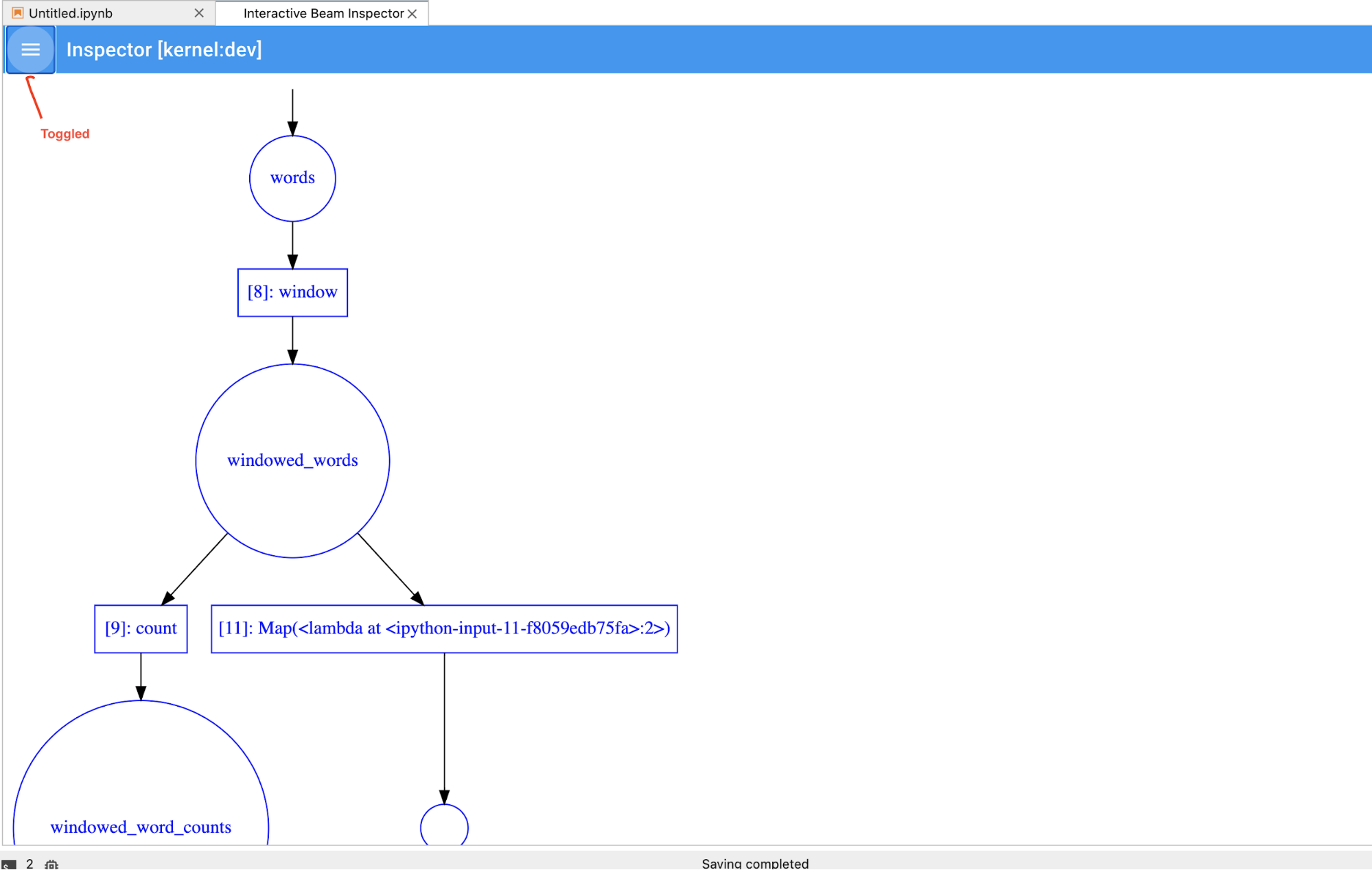
Memahami status perekaman pipeline
Selain visualisasi, Anda juga dapat memeriksa status perekaman untuk satu atau semua pipeline di instance notebook dengan memanggil describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
Metode describe() memberikan detail berikut:
- Ukuran total (dalam byte) semua rekaman untuk pipeline di disk
- Waktu mulai saat tugas perekaman latar belakang dimulai (dalam detik dari epoch Unix)
- Status pipeline saat ini dari tugas perekaman latar belakang
- Variabel Python untuk pipeline
Meluncurkan tugas Dataflow dari pipeline yang dibuat di notebook
- Opsional: Sebelum menggunakan notebook untuk menjalankan tugas Dataflow, mulai ulang kernel, jalankan ulang semua sel, dan verifikasi output. Jika Anda melewati langkah ini, status tersembunyi di notebook dapat memengaruhi grafik tugas dalam objek pipeline.
- Aktifkan Dataflow API.
Tambahkan pernyataan impor berikut:
from apache_beam.runners import DataflowRunnerTeruskan opsi pipeline Anda.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Anda dapat menyesuaikan nilai parameter. Misalnya, Anda dapat mengubah nilai
regiondarius-central1.Jalankan pipeline dengan
DataflowRunner. Langkah ini menjalankan tugas Anda di layanan Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)padalah objek pipeline dari Membuat pipeline.
Untuk contoh tentang cara melakukan konversi ini di notebook interaktif, lihat notebook Dataflow Word Count di instance notebook Anda.
Atau, Anda dapat mengekspor notebook sebagai skrip yang dapat dieksekusi, mengubah file .py yang dihasilkan menggunakan langkah-langkah sebelumnya, lalu men-deploy pipeline ke layanan Dataflow.
Menyimpan notebook
Notebook yang Anda buat disimpan secara lokal di instance notebook yang sedang berjalan. Jika Anda
mereset atau
menonaktifkan instance notebook selama pengembangan, notebook baru tersebut
akan dipertahankan selama dibuat di direktori /home/jupyter.
Namun, jika instance notebook dihapus, notebook tersebut juga akan dihapus.
Untuk menyimpan notebook untuk digunakan di masa mendatang, download secara lokal ke workstation, simpan ke GitHub, atau ekspor ke format file yang berbeda.
Menyimpan notebook ke persistent disk tambahan
Jika Anda ingin menyimpan pekerjaan seperti notebook dan skrip di berbagai instance notebook, simpan di Persistent Disk.
Buat atau lampirkan Persistent Disk. Ikuti petunjuk untuk menggunakan
sshguna terhubung ke VM instance notebook dan mengeluarkan perintah di Cloud Shell yang terbuka.Perhatikan direktori tempat Persistent Disk dipasang, misalnya,
/mnt/myDisk.Edit detail VM instance notebook untuk menambahkan entri ke
Custom metadata: kunci -container-custom-params; nilai --v /mnt/myDisk:/mnt/myDisk.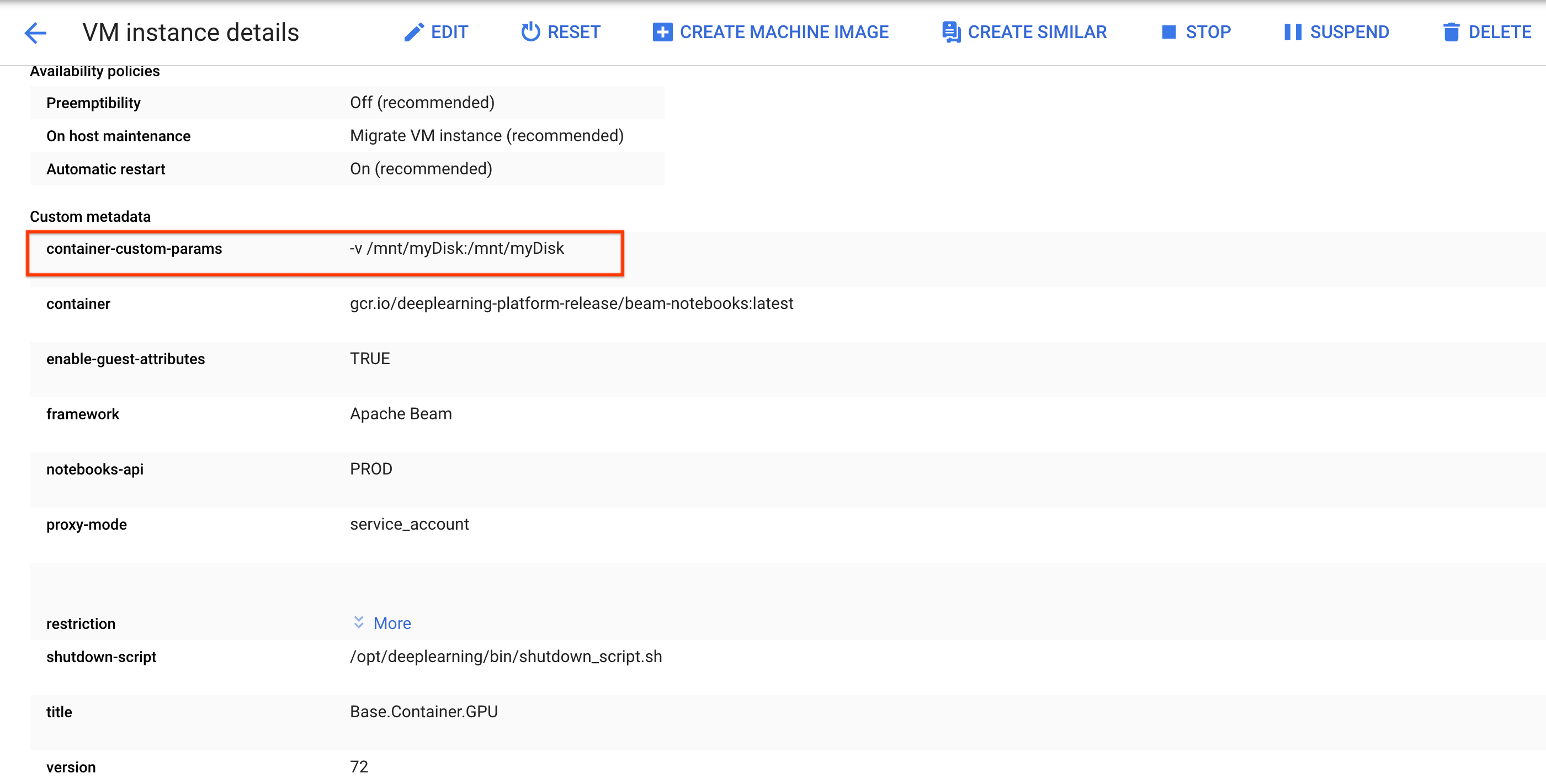
Klik Simpan.
Untuk memperbarui perubahan ini, reset instance notebook.
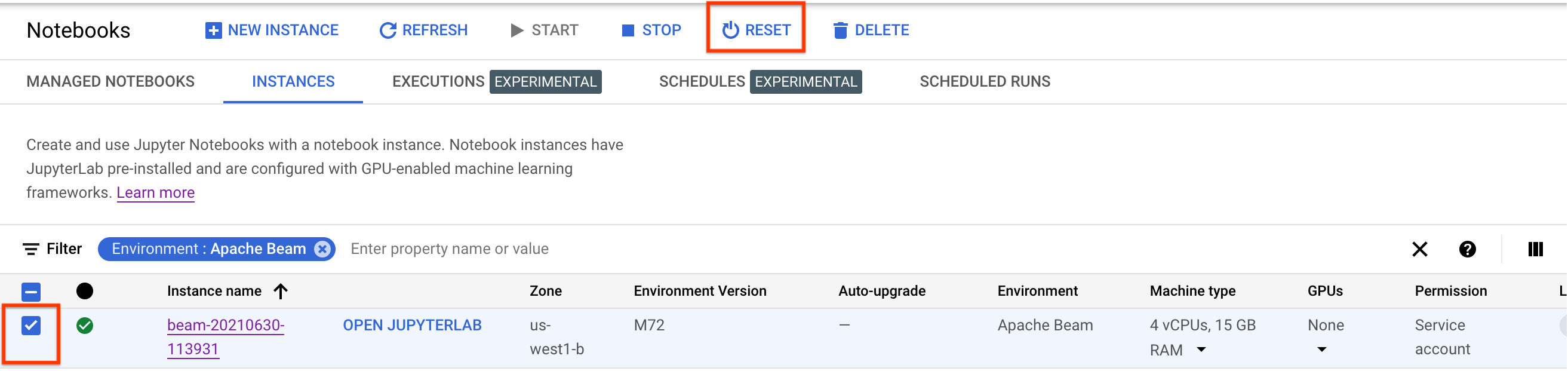
Setelah reset, klik Open JupyterLab. Mungkin perlu waktu agar UI JupyterLab tersedia. Setelah UI muncul, buka terminal dan jalankan perintah berikut:
ls -al /mntDirektori/mnt/myDiskakan tercantum.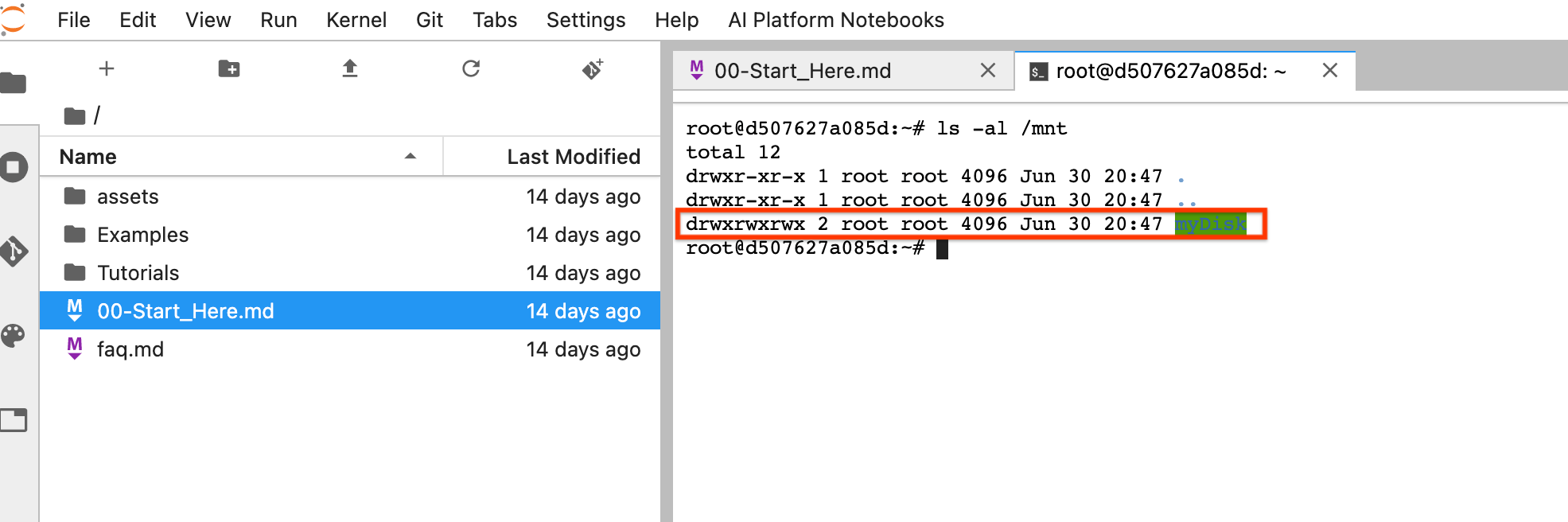
Sekarang Anda dapat menyimpan pekerjaan ke direktori /mnt/myDisk. Meskipun instance notebook dihapus, Persistent Disk akan tetap ada di project Anda. Kemudian, Anda
dapat memasang Persistent Disk ini ke instance notebook lain.
Pembersihan
Setelah selesai menggunakan instance notebook Apache Beam, bersihkan resource yang Anda buat di Google Cloud dengan menutup instance notebook.
Langkah berikutnya
- Pelajari fitur lanjutan yang dapat Anda gunakan dengan notebook Apache Beam. Fitur lanjutan mencakup alur kerja berikut: