このページでは、Dataflow で自動スケーリング対象のバッチ パイプラインに対して Flexible Resource Scheduling(FlexRS)を有効にする方法を説明します。
FlexRS は、高度なスケジューリング技術、Dataflow Shuffle サービス、プリエンプティブル仮想マシン(VM)インスタンスと通常の VM の組み合わせを使用することで、バッチ処理コストを削減します。プリエンプティブル VM と通常の VM を並列実行することで、システム イベント中に Compute Engine がプリエンプティブル VM インスタンスを停止した場合の Dataflow のユーザー エクスペリエンスが向上します。FlexRS は、プリエンプティブル VM が Compute Engine によってプリエンプトされたときに、パイプラインの処理を続行して以前の作業を確実に保持するのに効果的です。
FlexRS を使用するジョブでは、参加とグループ化のためにサービスベースの Dataflow Shuffle を使用します。その結果、FlexRS ジョブでは一時的な計算結果を保存するために Persistent Disk リソースを使用しません。Dataflow Shuffle を使用すると、Dataflow サービスで残りのワーカーにデータを再分配する必要がないため、FlexRS ではワーカー VM のプリエンプションの処理が向上します。各 Dataflow ワーカーでは、マシンイメージと一時ログを保存するために、さらに 25 GB の Persistent Disk ボリュームが必要です。
サポートと制限事項
- バッチ パイプラインをサポートします。
- Apache Beam SDK for Java 2.12.0 以降、Apache Beam SDK for Python 2.12.0 以降、または Apache Beam SDK for Go が必要です。
- Dataflow Shuffle を使用します。FlexRS をオンにすると、Dataflow Shuffle が自動的に有効になります。
- GPU はサポートしていません。
- Compute Engine の予約はサポートしていません。
- FlexRS ジョブではスケジューリングが遅延します。そのため、FlexRS は、特定の時間枠内に完了できる毎日行われるジョブや毎週行われるジョブなど、時間の制約が厳しくないワークロードに最適です。
遅延したスケジューリング
FlexRS ジョブを送信すると、Dataflow サービスでそのジョブがキューに入れられ、ジョブの作成から 6 時間以内に実行のために送信されます。Dataflow では、利用可能な容量やその他の要因に基づいて、時間枠内のジョブを開始するのに最適な時刻が決定されます。
FlexRS ジョブを送信すると、Dataflow サービスで次の手順を実行します。
- ジョブの送信直後にジョブ ID を返します。
- 早期検証を実行します。
早期検証の結果を使用して、次のステップを決定します。
- 成功すると、遅延している開始を待機するためにジョブをキューに入れます。
- それ以外の場合、ジョブは失敗し、Dataflow サービスでエラーが報告されます。
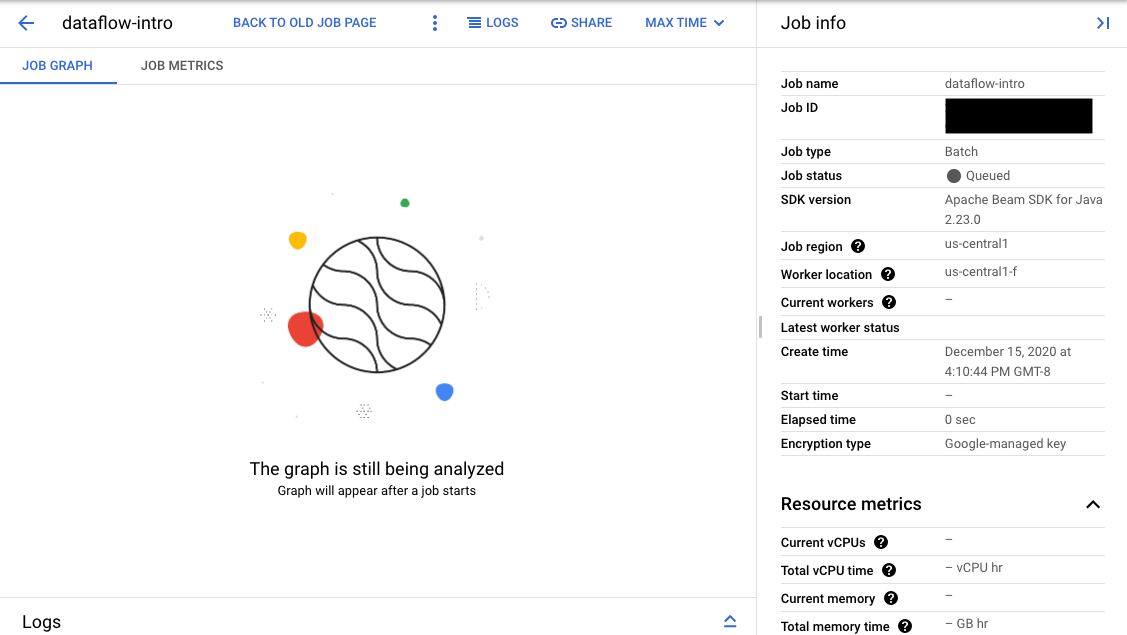
検証が成功すると、Dataflow モニタリング インターフェースに ID とステータス Queued が表示されます。検証に失敗すると、ジョブはステータス Failed を表示します。
早期検証
FlexRS ジョブは送信後すぐには開始されません。早期検証では、Dataflow サービスで実行パラメータと IAM のロールやネットワーク構成などのGoogle Cloud 環境設定が検証されます。Dataflow によって、ジョブの送信時に可能な限りジョブが検証され、エラーがあれば報告されます。この早期検証プロセスに対しては請求されません。
早期検証ステップでは、ユーザーコードは実行されません。Apache Beam Direct Runner または FlexRS 以外のジョブを使用して問題を確認するには、コードを検証する必要があります。ジョブの作成からそのジョブの遅延されたスケジューリングまでの間に Google Cloud 環境の変更がある場合、そのジョブは検証の初期段階で成功する可能性がありますが、それでも開始時に失敗する可能性があります。
FlexRS を有効にする
FlexRS ジョブを作成すると、そのジョブのステータスがキューに格納済みであっても、同時ジョブの割り当てが取得されます。初期検証プロセスでは、他の割り当ての確認や予約は行われません。したがって、FlexRS を有効にする前に、ジョブを開始するために十分な Google Cloud プロジェクト リソースの割り当てがあることを確認してください。パブリック IP パラメータをオフにしない限り、割り当てにプリエンプティブル CPU、通常の CPU、IP アドレスの追加割り当てが含まれます。
十分な割り当てがない場合は、FlexRS ジョブのデプロイ時にアカウントに十分なリソースがない可能性があります。Dataflow では、デフォルトでワーカープール内の 90% のワーカーにプリエンプティブル VM が選択されます。CPU 割り当てを計画するときは、十分なプリエンプティブル VM 割り当てがあることを確認してください。明示的にプリエンプティブル VM 割り当てをリクエストできます。そうしないと、FlexRS ジョブを遅延なく実行するためのリソースが不足します。
料金
FlexRS ジョブでは、次のリソースに対して請求されます。
- 通常の CPU とプリエンプティブル CPU
- メモリリソース
- Dataflow Shuffle リソース
- ワーカーあたり 25 GB の Persistent Disk リソース
Dataflow では、プリエンプティブル ワーカーと通常のワーカーの両方を使用して FlexRS ジョブを実行しますが、ワーカーのタイプにかかわらず料金は均一であり、通常の Dataflow の料金と比べると割安です。Dataflow Shuffle と Persistent Disk のリソースの料金は割引されません。
詳しくは、Dataflow の料金の詳細ページをご覧ください。
パイプライン オプション
Java
FlexRS ジョブを有効にするには、次のパイプライン オプションを使用します。
--flexRSGoal=COST_OPTIMIZED。コスト最適化目標は、Dataflow サービスで使用可能な割引リソースを選択します。--flexRSGoal=SPEED_OPTIMIZED。実行時間を短縮するために最適化します。指定しない場合は、--flexRSGoalフィールドはデフォルトのSPEED_OPTIMIZEDになります。これは、このフラグを省略した場合と同じです。
FlexRS ジョブは以下の実行パラメータに影響します。
numWorkersは初期ワーカー数のみを設定します。ただし、コスト管理のためにmaxNumWorkersを設定できます。- FlexRS ジョブでは
autoscalingAlgorithmオプションを使用できません。 - FlexRS ジョブには
zoneフラグを指定できません。Dataflow サービスでは、regionパラメータで指定したリージョン内のすべての FlexRS ジョブに対してゾーンを選択します。 regionとして Dataflow のロケーションを選択する必要があります。workerMachineTypeに M2、M3、H3 マシンシリーズは使用できません。
次の例は、FlexRS を使用するために通常のパイプライン パラメータにパラメータを追加する方法を示しています。
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
region、maxNumWorkers、workerMachineType を省略した場合、Dataflow サービスによりデフォルト値が決定されます。
Python
FlexRS ジョブを有効にするには、次のパイプライン オプションを使用します。
--flexrs_goal=COST_OPTIMIZED。コスト最適化目標は、Dataflow サービスで使用可能な割引リソースを選択します。--flexrs_goal=SPEED_OPTIMIZED。実行時間を短縮するために最適化します。指定しない場合は、--flexrs_goalフィールドはデフォルトのSPEED_OPTIMIZEDになります。これは、このフラグを省略した場合と同じです。
FlexRS ジョブは以下の実行パラメータに影響します。
num_workersは初期ワーカー数のみを設定します。ただし、コスト管理のためにmax_num_workersを設定できます。- FlexRS ジョブでは
autoscalingAlgorithmオプションを使用できません。 - FlexRS ジョブには
zoneフラグを指定できません。Dataflow サービスでは、regionパラメータで指定したリージョン内のすべての FlexRS ジョブに対してゾーンを選択します。 regionとして Dataflow のロケーションを選択する必要があります。machine_typeに M2、M3、H3 マシンシリーズは使用できません。
次の例は、FlexRS を使用するために通常のパイプライン パラメータにパラメータを追加する方法を示しています。
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
region、max_num_workers、machine_type を省略した場合、Dataflow サービスによりデフォルト値が決定されます。
Go
FlexRS ジョブを有効にするには、次のパイプライン オプションを使用します。
--flexrs_goal=COST_OPTIMIZED。コスト最適化目標は、Dataflow サービスで使用可能な割引リソースを選択します。--flexrs_goal=SPEED_OPTIMIZED。実行時間を短縮するために最適化します。指定しない場合は、--flexrs_goalフィールドはデフォルトのSPEED_OPTIMIZEDになります。これは、このフラグを省略した場合と同じです。
FlexRS ジョブは以下の実行パラメータに影響します。
num_workersは初期ワーカー数のみを設定します。ただし、コスト管理のためにmax_num_workersを設定できます。- FlexRS ジョブでは
autoscalingAlgorithmオプションを使用できません。 - FlexRS ジョブには
zoneフラグを指定できません。Dataflow サービスでは、regionパラメータで指定したリージョン内のすべての FlexRS ジョブに対してゾーンを選択します。 regionとして Dataflow のロケーションを選択する必要があります。worker_machine_typeに M2、M3、H3 マシンシリーズは使用できません。
次の例は、FlexRS を使用するために通常のパイプライン パラメータにパラメータを追加する方法を示しています。
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
region、max_num_workers、machine_type を省略した場合、Dataflow サービスによりデフォルト値が決定されます。
Dataflow テンプレート
一部の Dataflow テンプレートは、FlexRS パイプライン オプションをサポートしていません。代わりに、次のパイプライン オプションを使用してください。
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
FlexRS ジョブをモニタリングする
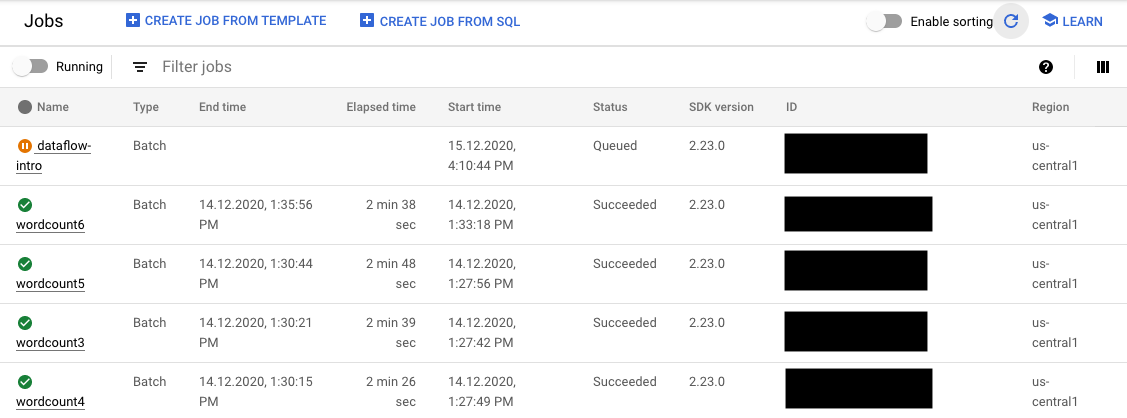
FlexRS ジョブのステータスは、 Google Cloud コンソールの次の 2 か所でモニタリングできます。
- すべてのジョブが表示される [ジョブ] ページ。
- 送信したジョブの [Monitoring Interface] ページ。
[ジョブ] ページで、開始されていないジョブのステータスは [キューに格納済み] になります。
[モニタリング インターフェース] ページの [ジョブグラフ] タブでは、キュー内で待機しているジョブに「ジョブ開始後にグラフが表示されます」というメッセージが表示されます。