L'échantillonnage de données vous permet d'observer les données à chaque étape d'un pipeline Dataflow. Ces informations peuvent vous aider à résoudre les problèmes liés à votre pipeline en affichant les entrées et sorties réelles d'un job en cours ou terminé.
Voici quelques cas d'utilisation de l'échantillonnage de données :
Pendant le développement, voir quels éléments sont produits tout au long du pipeline.
Si un pipeline génère une exception, affichez les éléments corrélés avec cette exception.
Lors du débogage, visualiser les sorties des transformations pour s'assurer qu'elles sont correctes.
Comprendre le comportement d'un pipeline sans avoir à examiner le code du pipeline.
Visualiser les éléments échantillonnés ultérieurement, une fois le job terminé, ou comparer les données échantillonnées avec une exécution précédente.
Présentation
Dataflow peut échantillonner les données du pipeline de différentes manières :
Échantillonnage périodique. Avec ce type d'échantillonnage, Dataflow collecte des échantillons lors de l'exécution de la tâche. Vous pouvez utiliser les données échantillonnées pour vérifier si votre pipeline traite les éléments comme prévu et pour diagnostiquer les problèmes d'exécution tels que les clés d'hôte ou les résultats incorrects. Pour en savoir plus, consultez la section Utiliser l'échantillonnage périodique des données dans ce document.
Échantillonnage d'exceptions. Avec ce type d'échantillonnage, Dataflow collecte des échantillons si un pipeline génère une exception. Vous pouvez utiliser les exemples pour afficher les données en cours de traitement lorsque l'exception s'est produite. L'échantillonnage des exceptions est activé par défaut et peut être désactivé. Pour en savoir plus, consultez la section Utiliser l'échantillonnage des exceptions de ce document.
Dataflow écrit les éléments échantillonnés dans le chemin Cloud Storage spécifié par l'option de pipeline temp_location. Vous pouvez afficher les données échantillonnées dans la console Google Cloud ou examiner les fichiers de données brutes dans Cloud Storage. Les fichiers sont conservés dans Cloud Storage jusqu'à ce que vous les supprimiez.
L'échantillonnage de données est exécuté par les nœuds de calcul Dataflow. L'échantillonnage est réalisé de la manière la plus optimale possible. Des échantillons peuvent être supprimés en cas d'erreurs temporaires.
Exigences
Pour utiliser l'échantillonnage des données, vous devez activer l'exécuteur v2. Pour en savoir plus, consultez la page Activer l'exécuteur Dataflow v2.
Pour afficher les données échantillonnées dans la console Google Cloud, vous devez disposer des autorisations Identity and Access Management suivantes :
storage.buckets.getstorage.objects.getstorage.objects.list
L'échantillonnage périodique nécessite le SDK Apache Beam suivant :
- SDK Java Apache Beam 2.47.0 ou versions ultérieures
- SDK Python Apache Beam 2.46.0 ou versions ultérieures
- SDK Apache Beam pour Go version 2.53.0 ou ultérieure
L'échantillonnage d'exceptions nécessite le SDK Apache Beam suivant :
- SDK Java Beam 2.51.0 ou version ultérieure
- SDK Apache Beam pour Python 2.51.0 ou version ultérieure
- Le SDK Apache Beam Go n'est pas compatible avec l'échantillonnage des exceptions.
À partir de ces SDK, Dataflow active par défaut l'échantillonnage des exceptions pour toutes les tâches.
Utiliser l'échantillonnage périodique des données
Cette section explique comment échantillonner les données de pipeline en continu pendant l'exécution d'une tâche.
Activer l'échantillonnage périodique des données
L'échantillonnage périodique est désactivé par défaut. Pour l'activer, définissez l'option de pipeline suivante :
Java
--experiments=enable_data_sampling
Python
--experiments=enable_data_sampling
Go
--experiments=enable_data_sampling
Vous pouvez définir cette option de manière automatisée ou à l'aide de la ligne de commande. Pour en savoir plus, consultez la page Définir les options de pipeline expérimentales.
Lorsque vous exécutez un modèle Dataflow, utilisez l'option additional-experiments pour activer l'échantillonnage de données :
--additional-experiments=enable_data_sampling
Lorsque l'échantillonnage périodique est activé, Dataflow collecte des échantillons sur chaque PCollection du graphique de la tâche. Le taux d'échantillonnage correspond à environ un échantillon toutes les 30 secondes.
Selon le volume de données, l'échantillonnage de données périodique peut avoir un impact considérable sur les performances. Par conséquent, nous vous recommandons de n'activer l'échantillonnage périodique que pendant les tests et de le désactiver pour les charges de travail de production.
Afficher les données échantillonnées
Pour afficher les données échantillonnées dans la console Google Cloud, procédez comme suit :
Dans la console Google Cloud, accédez à la page Tâches de Dataflow.
Sélectionnez une tâche.
Cliquez sur keyboard_capslock dans le panneau inférieur pour développer le panneau des journaux.
Cliquez sur l'onglet Échantillonnage de données.
Dans le champ Étape, sélectionnez une étape du pipeline. Vous pouvez également sélectionner une étape dans le graphique du job.
Dans le champ Collection, choisissez un
PCollection.
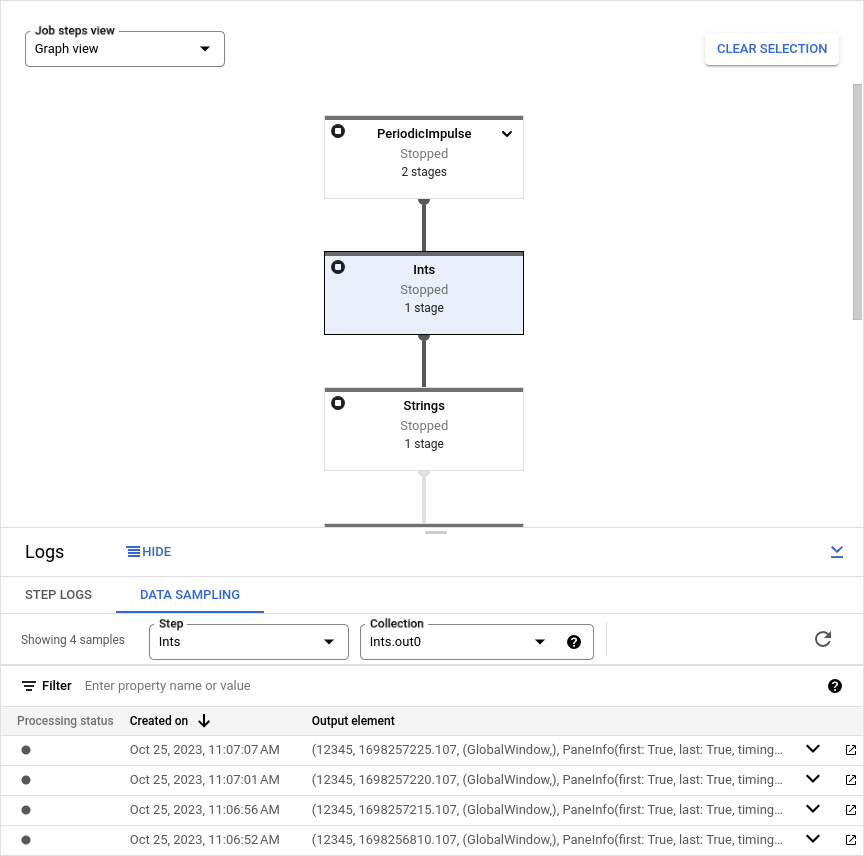
Si Dataflow a collecté des échantillons pour cette PCollection, les données échantillonnées apparaissent dans l'onglet. Pour chaque échantillon, l'onglet affiche la date de création et l'élément de sortie. L'élément de sortie est une représentation sérialisée de l'élément de collecte, y compris les données de l'élément, l'horodatage, ainsi que les informations sur la fenêtre et le volet.
Les exemples suivants montrent des éléments échantillonnés.
Java
TimestampedValueInGlobalWindow{value=KV{way, [21]},
timestamp=294247-01-09T04:00:54.775Z, pane=PaneInfo{isFirst=true, isLast=true,
timing=ON_TIME, index=0, onTimeIndex=0}}
Python
(('THE', 1), MIN_TIMESTAMP, (GloblWindow,), PaneInfo(first: True, last: True,
timing: UNKNOWN, index: 0, nonspeculative_index: 0))
Go
KV<THE,1> [@1708122738999:[[*]]:{3 true true 0 0}]
L'image suivante montre comment les données échantillonnées apparaissent dans la console Google Cloud.
Utiliser l'échantillonnage des exceptions
Si votre pipeline génère une exception non gérée, vous pouvez afficher l'exception et l'élément d'entrée corrélé avec cette exception. L'échantillonnage d'exceptions est activé par défaut lorsque vous utilisez un SDK Apache Beam compatible.
Afficher les exceptions
Pour afficher une exception, procédez comme suit :
Dans la console Google Cloud, accédez à la page Tâches de Dataflow.
Sélectionnez une tâche.
Pour développer le panneau Journaux, cliquez sur keyboard_capslock Afficher/Masquer le panneau dans le panneau Journaux.
Cliquez sur l'onglet Échantillonnage de données.
Dans le champ Étape, sélectionnez une étape du pipeline. Vous pouvez également sélectionner une étape dans le graphique du job.
Dans le champ Collection, choisissez un
PCollection.La colonne Exception contient les détails de l'exception. Il n'y a pas d'élément de sortie pour une exception. Au lieu de cela, la colonne Élément de sortie contient le message
Failed to process input element: INPUT_ELEMENT, où INPUT_ELEMENT est l'élément d'entrée corrélé.Pour afficher l'exemple d'entrée et les détails de l'exception dans une nouvelle fenêtre, cliquez sur Ouvrir dans une nouvelle fenêtre.
L'image suivante montre comment une exception s'affiche dans la console Google Cloud.

Désactiver l'échantillonnage des exceptions
Pour désactiver l'échantillonnage des exceptions, définissez l'option de pipeline suivante :
Java
--experiments=disable_always_on_exception_sampling
Python
--experiments=disable_always_on_exception_sampling
Vous pouvez définir cette option de manière automatisée ou à l'aide de la ligne de commande. Pour en savoir plus, consultez la page Définir les options de pipeline expérimentales.
Lorsque vous exécutez un modèle Dataflow, utilisez l'option additional-experiments pour désactiver l'échantillonnage des exceptions :
--additional-experiments=disable_always_on_exception_sampling
Points à noter concernant la sécurité
Dataflow écrit les données échantillonnées dans un bucket Cloud Storage que vous créez et gérez. Utilisez les fonctionnalités de sécurité de Cloud Storage pour sécuriser vos données. Considérez notamment les mesures de sécurité supplémentaires suivantes :
- Utilisez une clé de chiffrement gérée par le client (CMEK) pour chiffrer le bucket Cloud Storage. Pour en savoir plus sur le choix d'une option de chiffrement, consultez la page Choisir le chiffrement adapté à vos besoins.
- Définissez une valeur TTL (Time To Live) sur le bucket Cloud Storage afin que les fichiers de données soient automatiquement supprimés après un certain temps. Pour en savoir plus, consultez la page Définir la configuration de cycle de vie d'un bucket.
- Appliquez le principe du moindre privilège lorsque vous attribuez des autorisations IAM au bucket Cloud Storage.
Vous pouvez également obscurcir des champs individuels dans votre type de données PCollection afin que la valeur brute n'apparaisse pas dans les données échantillonnées :
- Python : remplacez la méthode
__repr__ou__str__. - Java : remplacez la méthode
toString.
Toutefois, vous ne pouvez pas obscurcir les entrées et les sorties des connecteurs d'E/S, sauf si vous modifiez le code source du connecteur à cet effet.
Facturation
Lorsque Dataflow effectue un échantillonnage des données, le stockage des données Cloud Storage et les opérations de lecture et d'écriture sur Cloud Storage vous sont facturés. Pour en savoir plus, consultez la page Tarifs de Cloud Storage.
Chaque nœud de calcul Dataflow écrit des échantillons par lots, en traitant une opération de lecture et une opération d'écriture par lot.
Dépannage
Cette section contient des informations sur les problèmes courants liés à l'utilisation de l'échantillonnage de données.
Erreur d'autorisation
Si vous n'êtes pas autorisé à afficher les exemples, la console Google Cloud affiche l'erreur suivante :
You don't have permission to view a data sample.
Pour résoudre cette erreur, vérifiez que vous disposez des autorisations IAM requises. Si l'erreur persiste, vous pouvez être soumis à une règle de refus IAM.
Aucun échantillon ne s'affiche
Si vous ne voyez aucun échantillon, vérifiez les éléments suivants :
- Assurez-vous que l'échantillonnage de données est activé en définissant l'option
enable_data_sampling. Consultez la page Activer l'échantillonnage de données. - Vérifiez que vous utilisez Runner v2.
- Assurez-vous que les nœuds de calcul ont démarré. L'échantillonnage ne démarre pas avant le démarrage des nœuds de calcul.
- Vérifiez que le job et les nœuds de calcul sont opérationnels.
- Vérifiez attentivement les quotas Cloud Storage du projet. Si vous dépassez les limites de quota Cloud Storage, Dataflow ne peut pas écrire les données échantillonnées.
- L'échantillonnage de données ne peut pas être échantillonné à partir d'itérables. Les échantillons de ces types de flux ne sont pas disponibles.