Panoramica
Puoi utilizzare le pipeline di dati Dataflow per le seguenti attività:
- Crea pianificazioni dei job ricorrenti.
- Scopri dove vengono utilizzate le risorse su più esecuzioni di job.
- Definisci e gestisci gli obiettivi di aggiornamento dei dati.
- Visualizza in dettaglio le singole fasi della pipeline per correggere e ottimizzare le pipeline.
Per la documentazione dell'API, consulta i riferimenti di Data Pipelines.
Funzionalità
- Crea una pipeline batch ricorrente per eseguire un job batch in base a una pianificazione.
- Crea una pipeline batch incrementale ricorrente per eseguire un job batch sulla versione più recente dei dati di input.
- Utilizza il prospetto del riepilogo della pipeline per visualizzare l'utilizzo aggregato della capacità e il consumo di risorse di una pipeline.
- Visualizza l'aggiornamento dei dati di una pipeline di streaming. Questa metrica, che si evolve nel tempo, può essere collegata a un avviso che ti informa quando la freschezza scende al di sotto di un obiettivo specificato.
- Utilizza i grafici delle metriche della pipeline per confrontare i job della pipeline batch e trovare anomalie.
Limitazioni
Disponibilità regionale: puoi creare pipeline di dati nelle regioni Cloud Scheduler disponibili.
Quota:
- Numero predefinito di pipeline per progetto: 500
Numero predefinito di pipeline per organizzazione: 2500
La quota a livello di organizzazione è disattivata per impostazione predefinita. Puoi attivare le quote a livello di organizzazione e, se lo fai, ogni organizzazione può avere al massimo 2500 pipeline per impostazione predefinita.
Etichette: non puoi utilizzare etichette definite dall'utente per etichettare le pipeline di dati Dataflow. Tuttavia, quando utilizzi il campo
additionalUserLabels, questi valori vengono trasmessi al job Dataflow. Per saperne di più su come le etichette vengono applicate ai singoli job Dataflow, consulta Opzioni della pipeline.
Tipi di pipeline di dati
Dataflow ha due tipi di pipeline di dati: streaming e batch. Entrambi i tipi di pipeline eseguono job definiti nei modelli Dataflow.
- Pipeline di dati in modalità flusso
- Una pipeline di dati in modalità flusso esegue un job Dataflow in modalità flusso immediatamente dopo la creazione.
- Pipeline di dati batch
Una pipeline di dati batch esegue un job batch Dataflow in base a una pianificazione definita dall'utente. Il nome file di input della pipeline batch può essere parametrizzato per consentire l'elaborazione incrementale della pipeline batch.
Pipeline batch incrementali
Puoi utilizzare i segnaposto datetime per specificare un formato di file di input incrementale per una pipeline batch.
- È possibile utilizzare i segnaposto per anno, mese, data, ora, minuto e secondo, che
devono seguire il formato
strftime(). I segnaposto sono preceduti dal simbolo di percentuale (%). - La formattazione dei parametri non viene verificata durante la creazione della pipeline.
- Esempio: se specifichi "gs://bucket/Y" come percorso di input parametrizzato,
viene valutato come "gs://bucket/Y", perché "Y" senza il prefisso "%"
non viene mappato al formato
strftime().
- Esempio: se specifichi "gs://bucket/Y" come percorso di input parametrizzato,
viene valutato come "gs://bucket/Y", perché "Y" senza il prefisso "%"
non viene mappato al formato
A ogni ora di esecuzione della pipeline batch pianificata, la parte segnaposto del percorso di input viene valutata in base alla data e all'ora correnti (o con spostamento temporale). I valori di data vengono valutati utilizzando la data corrente nel fuso orario del job pianificato. Se il percorso valutato corrisponde al percorso di un file di input, il file viene recuperato per l'elaborazione dalla pipeline batch all'ora pianificata.
- Esempio: una pipeline batch è pianificata per ripetersi all'inizio di ogni ora
PST. Se parametrizzi il percorso di input come
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, il 15 aprile 2021 alle 18:00 PST, il percorso di input viene valutato comegs://bucket-name/2021-04-15/prefix-18_00.csv.
Utilizzare i parametri di spostamento temporale
Puoi utilizzare i parametri di spostamento dell'ora di minuti o ore con i simboli + o -.
Per supportare la corrispondenza di un percorso di input con una data e ora valutata che viene spostata prima o dopo la data e l'ora correnti della pianificazione della pipeline, racchiudi questi parametri tra parentesi graffe.
Utilizza il formato {[+|-][0-9]+[m|h]}. La pipeline batch continua a ripetersi all'ora pianificata, ma il percorso di input viene valutato con l'offset temporale specificato.
- Esempio: una pipeline batch è pianificata per ripetersi all'inizio di ogni ora
PST. Se parametrizzi il percorso di input come
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, il 15 aprile 2021 alle 18:00 PST, il percorso di input viene valutato comegs://bucket-name/2021-04-15/prefix-16_00.csv.
Ruoli della pipeline di dati
Perché le operazioni della pipeline di dati Dataflow vadano a buon fine, devi disporre dei ruoli IAM necessari, come segue:
Per eseguire le operazioni, devi disporre del ruolo appropriato:
Datapipelines.admin: Può eseguire tutte le operazioni della pipeline di datiDatapipelines.viewer: Può visualizzare pipeline di dati e jobDatapipelines.invoker: Può richiamare l'esecuzione di un job della pipeline di dati (questo ruolo può essere abilitato utilizzando l'API)
Il account di servizio utilizzato da Cloud Scheduler deve disporre del ruolo
roles/iam.serviceAccountUser, indipendentemente dal fatto che sia specificato dall'utente o che si tratti del account di servizio predefinito di Compute Engine. Per saperne di più, consulta Ruoli della pipeline di dati.Devi essere in grado di agire come il account di servizio utilizzato da Cloud Scheduler e Dataflow se ti viene concesso il ruolo
roles/iam.serviceAccountUserper quell'account. Se non selezioni un account di servizio per Cloud Scheduler e Dataflow, viene utilizzato il service account Compute Engine predefinito.
Crea una pipeline di dati
Puoi creare una pipeline di dati Dataflow in due modi:
La pagina di configurazione delle pipeline di dati:quando accedi per la prima volta alla funzionalità pipeline Dataflow nella console Google Cloud , si apre una pagina di configurazione. Abilita le API elencate per creare pipeline di dati.
Importare un job
Puoi importare un job batch o di streaming Dataflow basato su un modello classico o flessibile e trasformarlo in una pipeline di dati.
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Seleziona un job completato, quindi nella pagina Dettagli job seleziona +Importa come pipeline.
Nella pagina Crea pipeline da modello, i parametri vengono compilati con le opzioni del job importato.
Per un job batch, nella sezione Pianifica la pipeline, fornisci una pianificazione della ricorrenza. Fornire un indirizzo account email per Cloud Scheduler, che viene utilizzato per pianificare le esecuzioni batch, è facoltativo. Se non viene specificato, viene utilizzato il service account Compute Engine predefinito.
Crea una pipeline di dati
Nella console Google Cloud , vai alla pagina Pipeline di dati di Dataflow.
Seleziona +Crea pipeline di dati.
Nella pagina Crea pipeline da modello, fornisci un nome per la pipeline e compila gli altri campi di selezione e parametri del modello.
Per un job batch, nella sezione Pianifica la pipeline, fornisci una pianificazione della ricorrenza. Fornire un indirizzo account email per Cloud Scheduler, che viene utilizzato per pianificare le esecuzioni batch, è facoltativo. Se non viene specificato un valore, viene utilizzato il service account Compute Engine predefinito.
Crea una pipeline di dati batch
Per creare questa pipeline di dati batch di esempio, devi avere accesso alle seguenti risorse nel tuo progetto:
- Un bucket Cloud Storage per archiviare i file di input e output
- Un set di dati BigQuery per creare una tabella.
Questa pipeline di esempio utilizza il modello di pipeline batch Testo Cloud Storage a BigQuery. Questo modello legge i file in formato CSV da Cloud Storage, esegue una trasformazione e poi inserisce i valori in una tabella BigQuery con tre colonne.
Crea i seguenti file sull'unità locale:
Un file
bq_three_column_table.jsonche contiene il seguente schema della tabella BigQuery di destinazione.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }Un file JavaScript
split_csv_3cols.js, che implementa una semplice trasformazione sui dati di input prima dell'inserimento in BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }Un file CSV
file01.csvcon diversi record inseriti nella tabella BigQuery.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Utilizza il comando
gcloud storage cpper copiare i file nelle cartelle di un bucket Cloud Storage nel tuo progetto, nel seguente modo:Copia
bq_three_column_table.jsonesplit_csv_3cols.jsings://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Copia
file01.csvings://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
Per creare una cartella
tmpnel bucket Cloud Storage, seleziona il nome della cartella per aprire la pagina dei dettagli del bucket, poi fai clic su Crea cartella.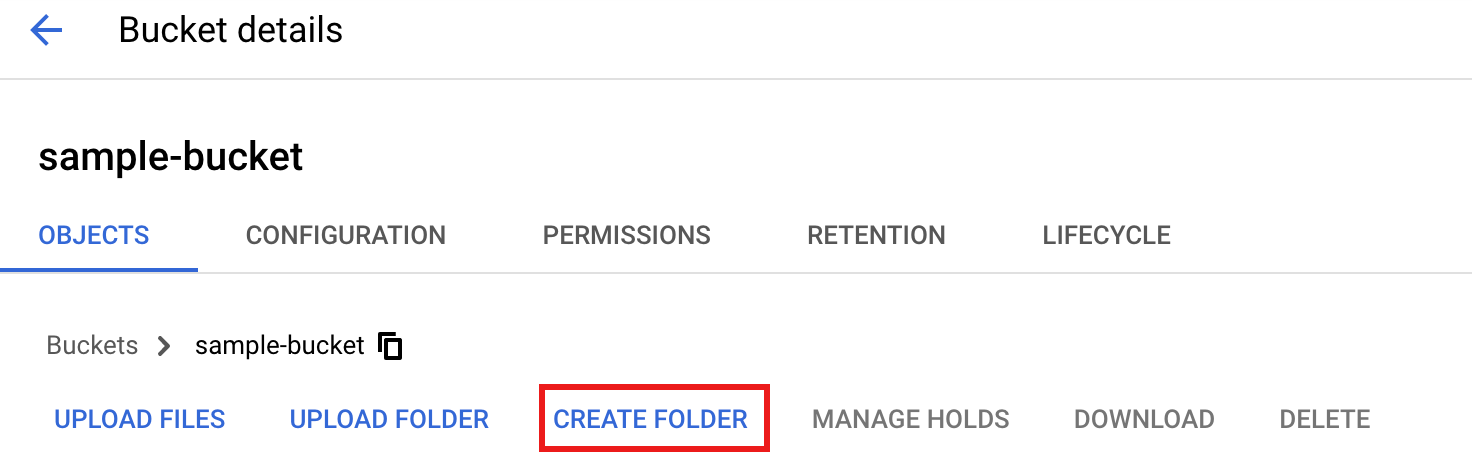
Nella console Google Cloud , vai alla pagina Pipeline di dati di Dataflow.
Seleziona Crea pipeline di dati. Inserisci o seleziona i seguenti elementi nella pagina Crea pipeline da modello:
- In Nome pipeline, inserisci
text_to_bq_batch_data_pipeline. - Per Endpoint a livello di regione, seleziona una regione di Compute Engine. Le regioni di origine e di destinazione devono corrispondere. Pertanto, il bucket Cloud Storage e la tabella BigQuery devono trovarsi nella stessa regione.
In Modello Dataflow, in Elabora i dati in blocco (batch), seleziona Text Files on Cloud Storage to BigQuery.
Per Pianifica la pipeline, seleziona una pianificazione, ad esempio Ogni ora al minuto 25, nel tuo fuso orario. Puoi modificare la pianificazione dopo aver inviato la pipeline. Fornire un indirizzo email per l'account Cloud Scheduler, che viene utilizzato per pianificare le esecuzioni batch, è facoltativo. Se non viene specificato, viene utilizzato il service account Compute Engine predefinito.
In Parametri obbligatori, inserisci quanto segue:
- Per Percorso della funzione JavaScript definita dall'utente in Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- Per Percorso JSON:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- Per Nome della funzione JavaScript definita dall'utente:
transform - In Tabella di output BigQuery:
PROJECT_ID:DATASET_ID.three_column_table
- Per Percorso di input di Cloud Storage:
BUCKET_ID/inputs/file01.csv
- Per Directory BigQuery temporanea:
BUCKET_ID/tmp
- Per Posizione temporanea:
BUCKET_ID/tmp
- Per Percorso della funzione JavaScript definita dall'utente in Cloud Storage:
Fai clic su Crea pipeline.
- In Nome pipeline, inserisci
Conferma le informazioni sulla pipeline e sul modello e visualizza la cronologia attuale e precedente nella pagina Dettagli pipeline.
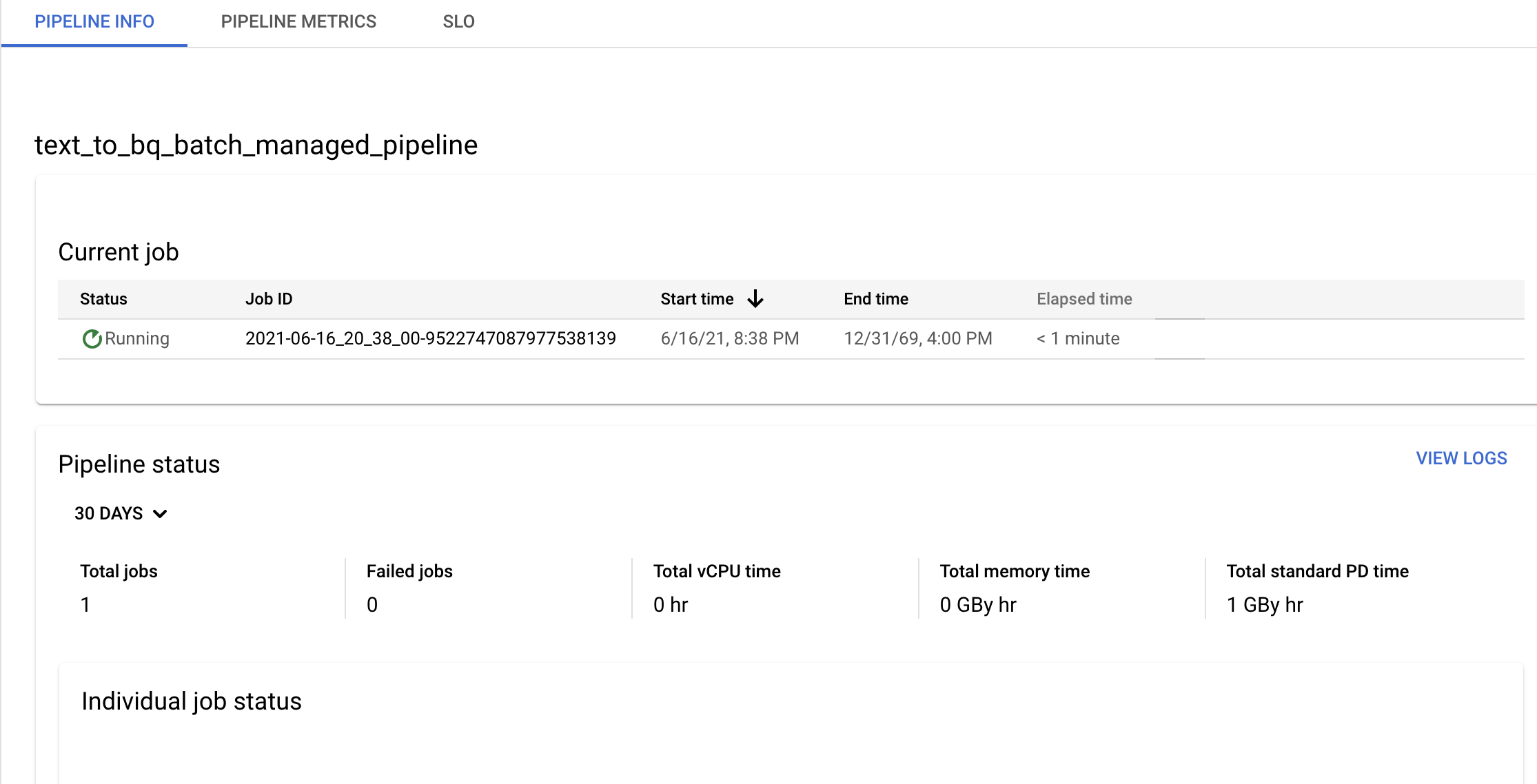
Puoi modificare la pianificazione della pipeline di dati dal riquadro Informazioni pipeline nella pagina Dettagli pipeline.
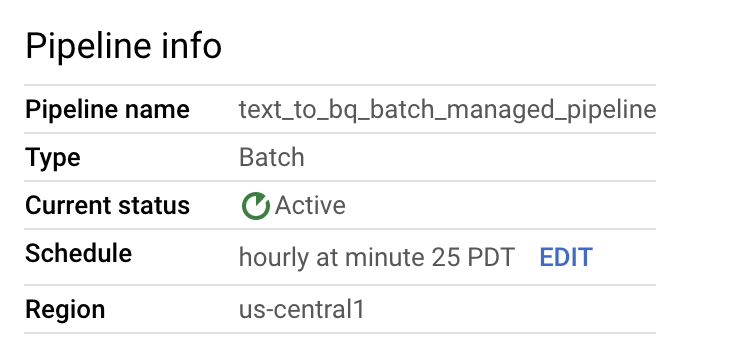
Puoi anche eseguire una pipeline batch on demand utilizzando il pulsante Esegui nella console Dataflow Pipelines.
Crea una pipeline di dati in modalità flusso di esempio
Puoi creare una pipeline di dati in streaming di esempio seguendo le istruzioni per la pipeline batch di esempio, con le seguenti differenze:
- Per Pianificazione pipeline, non specificare una pianificazione per una pipeline di dati in modalità flusso. Il job Dataflow in modalità flusso viene avviato immediatamente.
- In Modello Dataflow, in Elabora i dati in modo continuo (stream), seleziona File di testo su Cloud Storage a BigQuery.
- Per Tipo di macchina worker, la pipeline elabora il set iniziale di
file corrispondenti al pattern
gs://BUCKET_ID/inputs/file01.csve qualsiasi file aggiuntivo corrispondente a questo pattern che carichi nella cartellainputs/. Se le dimensioni dei file CSV superano diversi GB, per evitare possibili errori di memoria insufficiente, seleziona un tipo di macchina con più memoria rispetto al tipo di macchinan1-standard-4predefinito, ad esempion1-highmem-8.
Risoluzione dei problemi
Questa sezione mostra come risolvere i problemi relativi alle pipeline di dati Dataflow.
Impossibile avviare il job della pipeline di dati
Quando utilizzi le pipeline di dati per creare una pianificazione dei job ricorrenti, il job Dataflow potrebbe non essere avviato e viene visualizzato un errore di stato 503 nei file di log di Cloud Scheduler.
Questo problema si verifica quando Dataflow non è temporaneamente in grado di eseguire il job.
Per risolvere questo problema, configura Cloud Scheduler in modo che riprovi a eseguire il job. Poiché il problema è temporaneo, quando il job viene ritentato, potrebbe riuscire. Per ulteriori informazioni sull'impostazione dei valori di nuovi tentativi in Cloud Scheduler, consulta Crea un job.
Esaminare le violazioni degli obiettivi della pipeline
Le sezioni seguenti descrivono come esaminare le pipeline che non soddisfano gli obiettivi di rendimento.
Pipeline batch ricorrenti
Per un'analisi iniziale dell'integrità della pipeline, utilizza i grafici Stato del singolo job e Tempo di thread per passaggio nella pagina Informazioni pipeline della console Google Cloud . Questi grafici si trovano nel riquadro dello stato della pipeline.
Esempio di indagine:
Hai una pipeline batch ricorrente che viene eseguita ogni ora alle 3 minuti dopo l'ora. Ogni job viene eseguito normalmente per circa 9 minuti. Hai un obiettivo per tutti i job da completare in meno di 10 minuti.
Il grafico dello stato del job mostra che un job è stato eseguito per più di 10 minuti.
Nella tabella della cronologia Aggiornamento/Esecuzione, individua il job eseguito durante l'ora di interesse. Fai clic per accedere alla pagina dei dettagli del job Dataflow. In questa pagina, individua la fase di esecuzione più lunga e poi cerca nei log possibili errori per determinare la causa del ritardo.
Pipeline in modalità flusso
Per un'analisi iniziale dello stato della pipeline, nella pagina Dettagli pipeline, nella scheda Informazioni pipeline, utilizza il grafico di aggiornamento dei dati. Questo grafico si trova nel riquadro dello stato della pipeline.
Esempio di indagine:
Hai una pipeline di streaming che normalmente produce un output con una freschezza dei dati di 20 secondi.
Hai impostato l'obiettivo di avere una garanzia di aggiornamento dei dati di 30 secondi. Quando esamini il grafico di aggiornamento dei dati, noti che tra le 9:00 e le 10:00, l'aggiornamento dei dati è aumentato fino a quasi 40 secondi.
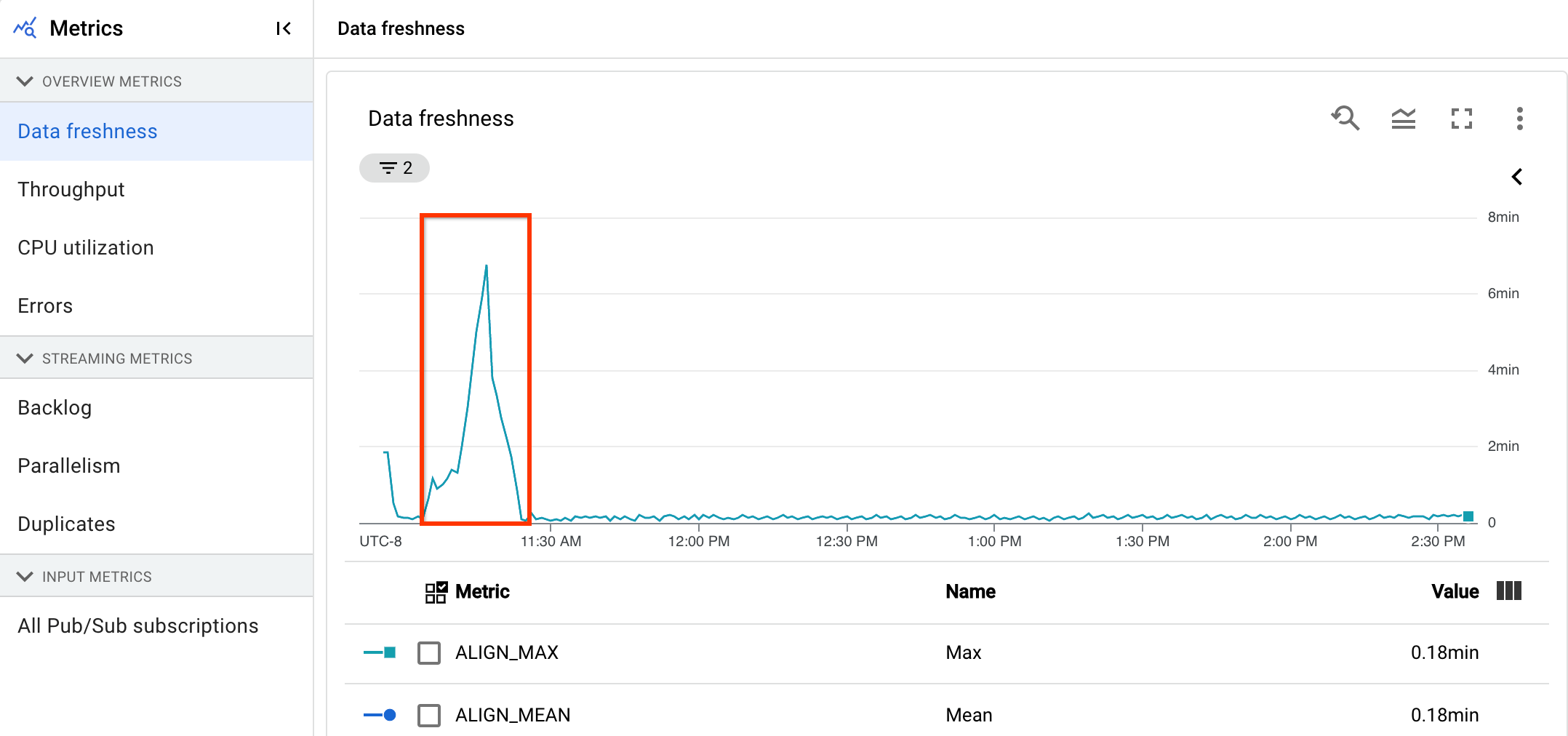
Passa alla scheda Metriche pipeline, quindi visualizza i grafici Utilizzo CPU e Utilizzo memoria per ulteriori analisi.
Errore: l'ID pipeline esiste già nel progetto
Se tenti di creare una nuova pipeline con un nome già esistente nel tuo progetto, viene visualizzato questo messaggio di errore: Pipeline Id already exist within the
project. Per evitare questo problema, scegli sempre nomi univoci per le pipeline.