Présentation
Vous pouvez utiliser les pipelines de données Dataflow pour les tâches suivantes :
- Créer des programmations de jobs récurrents.
- Comprendre où les ressources sont dépensées lors de plusieurs exécutions de jobs.
- Définir et gérer les objectifs de fraîcheur des données.
- Afficher le détail de chaque étape de pipeline pour corriger et optimiser vos pipelines.
Pour obtenir la documentation de l'API, consultez la documentation de référence sur les pipelines de données.
Fonctionnalités
- Créez un pipeline par lots récurrent pour exécuter une tâche par lots selon un calendrier.
- Créez un pipeline par lots incrémentiel récurrent afin d'exécuter une tâche par lot sur la dernière version des données d'entrée.
- Utilisez le tableau de données récapitulatif du pipeline pour afficher l'utilisation totale et la consommation des ressources d'un pipeline.
- Affichez la fraîcheur des données d'un pipeline de traitement par flux. Cette métrique, qui évolue au fil du temps, peut être liée à une alerte qui vous avertit lorsque la fraîcheur tombe en dessous d'un objectif spécifié.
- Utilisez les graphiques de métriques de pipeline pour comparer les tâches de pipeline par lot et détecter les anomalies.
Limites
Disponibilité régionale : vous pouvez créer des pipelines de données dans les régions Cloud Scheduler disponibles.
Quota :
- Nombre de pipelines par projet par défaut : 500
Nombre de pipelines par organisation par défaut : 2 500
Le quota au niveau de l'organisation est désactivé par défaut. Vous pouvez opter pour des quotas au niveau de l'organisation. Dans ce cas, chaque organisation peut utiliser un nombre maximal de 2 500 pipelines par défaut.
Libellés : vous ne pouvez pas utiliser de libellés définis par l'utilisateur pour ajouter un libellé aux pipelines de données Dataflow. Cependant, lorsque vous utilisez le champ
additionalUserLabels, ces valeurs sont transmises à votre job Dataflow. Pour plus d'informations sur la façon dont les libellés s'appliquent à des jobs Dataflow individuels, consultez la page Options de pipeline.
Types de pipelines de données
Dataflow propose deux types de pipelines de données : les flux et les lots. Ces deux types de pipelines exécutent des jobs définis dans les modèles Dataflow.
- Pipeline de données en flux continu
- Un pipeline de flux de données exécute un job par flux Dataflow immédiatement après sa création.
- Pipeline de données par lot
Un pipeline de données par lot exécute un job par lot Dataflow selon un calendrier défini par l'utilisateur. Le nom du fichier d'entrée du pipeline par lot peut être paramétré pour permettre le traitement incrémentiel du pipeline par lot.
Pipelines par lots incrémentiels
Vous pouvez utiliser des espaces réservés de date et d'heure pour spécifier un format de fichier d'entrée incrémentiel pour un pipeline par lots.
- Les espaces réservés pour l'année, le mois, la date, l'heure, la minute et la seconde peuvent être utilisés et doivent respecter le format
strftime(). Les espaces réservés sont précédés du symbole pourcentage (%). - La mise en forme des paramètres n'a pas été vérifiée lors de la création du pipeline.
- Exemple : Si vous spécifiez "gs://bucket/Y" comme chemin d'entrée paramétré, il sera évalué comme "gs://bucket/Y", car "Y" qui n'est pas précédé de "%" ne correspond pas au format
strftime().
- Exemple : Si vous spécifiez "gs://bucket/Y" comme chemin d'entrée paramétré, il sera évalué comme "gs://bucket/Y", car "Y" qui n'est pas précédé de "%" ne correspond pas au format
À chaque heure d'exécution programmée du pipeline par lot, la partie de l'espace réservé du chemin d'entrée est évaluée à la date et l'heure actuelles (ou décalées dans le temps). Les valeurs de date sont évaluées à l'aide de la date actuelle dans le fuseau horaire du job planifié. Si le chemin évalué correspond à celui d'un fichier d'entrée, le fichier est sélectionné pour le traitement par le pipeline de traitement par lot à l'heure planifiée.
- Exemple:Un pipeline par lot se répète au début de chaque heure PST. Si vous paramétrez le chemin d'entrée sur
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, le 15 avril 2021 à 18:00 PST, le chemin d'entrée est évalué avecgs://bucket-name/2021-04-15/prefix-18_00.csv.
Utiliser les paramètres de décalage temporel
Vous pouvez utiliser les paramètres de décalage temporel de + ou - minute ou heure.
Pour prendre en charge la correspondance d'un chemin d'entrée avec une date et heure évaluée qui est modifiée avant ou après la date et l'heure actuelles de la programmation du pipeline, placez ces paramètres entre accolades.
Utilisez le format {[+|-][0-9]+[m|h]}. Le pipeline par lots continue de se répéter à l'heure prévue, mais le chemin d'entrée est évalué avec le décalage temporel spécifié.
- Exemple:Un pipeline par lot se répète au début de chaque heure PST. Si vous paramétrez le chemin d'entrée sur
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, le 15 avril 2021 à 18:00 PST, le chemin d'entrée est évalué avecgs://bucket-name/2021-04-15/prefix-16_00.csv.
Rôles de pipeline de données
Pour que les opérations de pipeline de données Dataflow réussissent, vous devez disposer des rôles IAM nécessaires, comme suit :
Vous devez disposer du rôle approprié pour effectuer des opérations :
Datapipelines.admin: peut effectuer toutes les opérations de pipeline de données.Datapipelines.viewer: peut afficher les pipelines de données et les tâches.Datapipelines.invoker: peut appeler une tâche de pipeline de données (ce rôle peut être activé à l'aide de l'API).
Le compte de service utilisé par Cloud Scheduler doit disposer du rôle
roles/iam.serviceAccountUser, que le compte de service soit spécifié par l'utilisateur ou qu'il s'agisse du compte de service Compute Engine par défaut. Pour en savoir plus, consultez la section Rôles de pipeline de données.Vous devez pouvoir agir en tant que compte de service utilisé par Cloud Scheduler et Dataflow grâce au rôle
roles/iam.serviceAccountUsersur ce compte. Si vous ne sélectionnez pas de compte de service pour Cloud Scheduler et Dataflow, le compte de service Compute Engine par défaut est utilisé.
Créer un pipeline de données
Vous pouvez créer un pipeline de données Dataflow de deux manières :
Page de configuration des pipelines de données : lorsque vous accédez pour la première fois à la fonctionnalité des pipelines Dataflow dans la console Google Cloud, une page de configuration s'ouvre. Autorisez les API répertoriées à créer des pipelines de données.
Importer une tâche
Vous pouvez importer un job par lot ou par flux Dataflow basé sur un modèle classique ou flexible et en faire un pipeline de données.
Dans la console Google Cloud, accédez à la page Tâches de Dataflow.
Sélectionnez un job terminé, puis sur la page Informations sur le job, sélectionnez + Importer en tant que pipeline.
Sur la page Créer un pipeline à partir d'un modèle, les paramètres sont renseignés avec les options du job importé.
Pour un job par lot, dans la section Planifier votre pipeline, indiquez un calendrier de récurrence. La spécification d'une adresse de compte de messagerie pour Cloud Scheduler, utilisée pour planifier des exécutions par lots, est facultative. Si elle n'est pas spécifiée, le compte de service Compute Engine par défaut est utilisé.
Créer un pipeline de données
Dans la console Google Cloud, accédez à la page Pipelines de données de Dataflow.
Sélectionnez + Créer un pipeline de données.
Sur la page Créer un pipeline à partir d'un modèle, indiquez un nom de pipeline, puis renseignez les autres champs de sélection et de paramètres du modèle.
Pour un job par lot, dans la section Planifier votre pipeline, indiquez un calendrier de récurrence. La spécification d'une adresse de compte de messagerie pour Cloud Scheduler, utilisée pour planifier des exécutions par lots, est facultative. Si aucune valeur n'est spécifiée, le compte de service Compute Engine par défaut est utilisé.
Créer un pipeline de données par lots
Pour créer cet exemple de pipeline de données par lot, vous devez avoir accès aux ressources suivantes de votre projet:
- Un bucket Cloud Storage pour stocker les fichiers d'entrée et de sortie
- Un ensemble de données BigQuery pour créer une table.
Cet exemple de pipeline utilise le modèle de pipeline par lots Texte Cloud Storage vers BigQuery. Ce modèle lit les fichiers au format CSV à partir de Cloud Storage, exécute une transformation, puis insère les valeurs dans une table BigQuery avec trois colonnes.
Créez les fichiers suivants sur votre disque local :
Un fichier
bq_three_column_table.jsoncontenant le schéma suivant de la table BigQuery de destination.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }Un fichier JavaScript
split_csv_3cols.js, qui met en œuvre une transformation simple sur les données d'entrée avant l'insertion dans BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }Un fichier CSV
file01.csvavec plusieurs enregistrements insérés dans la table BigQuery.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Utilisez la commande
gcloud storage cppour copier les fichiers dans des dossiers dans un bucket Cloud Storage de votre projet, comme suit :Copiez
bq_three_column_table.jsonetsplit_csv_3cols.jsdansgs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Copiez
file01.csvversgs://BUCKET_ID/inputs/:gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Dans la console Google Cloud, accédez à la page Buckets de Cloud Storage.
Pour créer un dossier
tmpdans votre bucket Cloud Storage, sélectionnez le nom de votre dossier pour ouvrir la page Informations sur le bucket, puis cliquez sur Créer un dossier.
Dans la console Google Cloud, accédez à la page Pipelines de données de Dataflow.
Sélectionnez Créer un pipeline de données. Saisissez ou sélectionnez les éléments suivants sur la page Créer un pipeline à partir d'un modèle:
- Dans le champ Nom du pipeline, saisissez
text_to_bq_batch_data_pipeline. - Pour le Point de terminaison régional, sélectionnez une région Compute Engine. Les régions source et de destination doivent correspondre. Par conséquent, votre bucket Cloud Storage et votre table BigQuery doivent se trouver dans la même région.
Pour Modèle Dataflow, dans Traiter les données de manière groupée (lot), sélectionnez Fichiers texte sur Cloud Storage vers BigQuery.
Pour Planifier votre pipeline, sélectionnez une programmation, par exemple toutes les heures à la minute 25, dans votre fuseau horaire. Vous pouvez modifier la programmation après avoir envoyé le pipeline. La spécification d'une adresse de compte de messagerie pour Cloud Scheduler, utilisée pour planifier des exécutions par lots, est facultative. Si elle n'est pas spécifiée, le compte de service Compute Engine par défaut est utilisé.
Dans Paramètres obligatoires, saisissez les valeurs suivantes :
- Pour le Chemin d'accès aux fonctions JavaScript définies par l'utilisateur dans Cloud Storage :
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- Pour le Chemin JSON :
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- Pour le Nom des fonctions JavaScript définies par l'utilisateur :
transform - Pour Table BigQuery de sortie :
PROJECT_ID:DATASET_ID.three_column_table
- Pour le Chemin d'entrée Cloud Storage :
BUCKET_ID/inputs/file01.csv
- Pour le Répertoire BigQuery temporaire :
BUCKET_ID/tmp
- Pour Emplacement temporaire :
BUCKET_ID/tmp
- Pour le Chemin d'accès aux fonctions JavaScript définies par l'utilisateur dans Cloud Storage :
Cliquez sur Créer un pipeline.
- Dans le champ Nom du pipeline, saisissez
Confirmez les informations sur le pipeline et le modèle, puis affichez l'historique actuel et précédent à partir de la page Détails du pipeline.
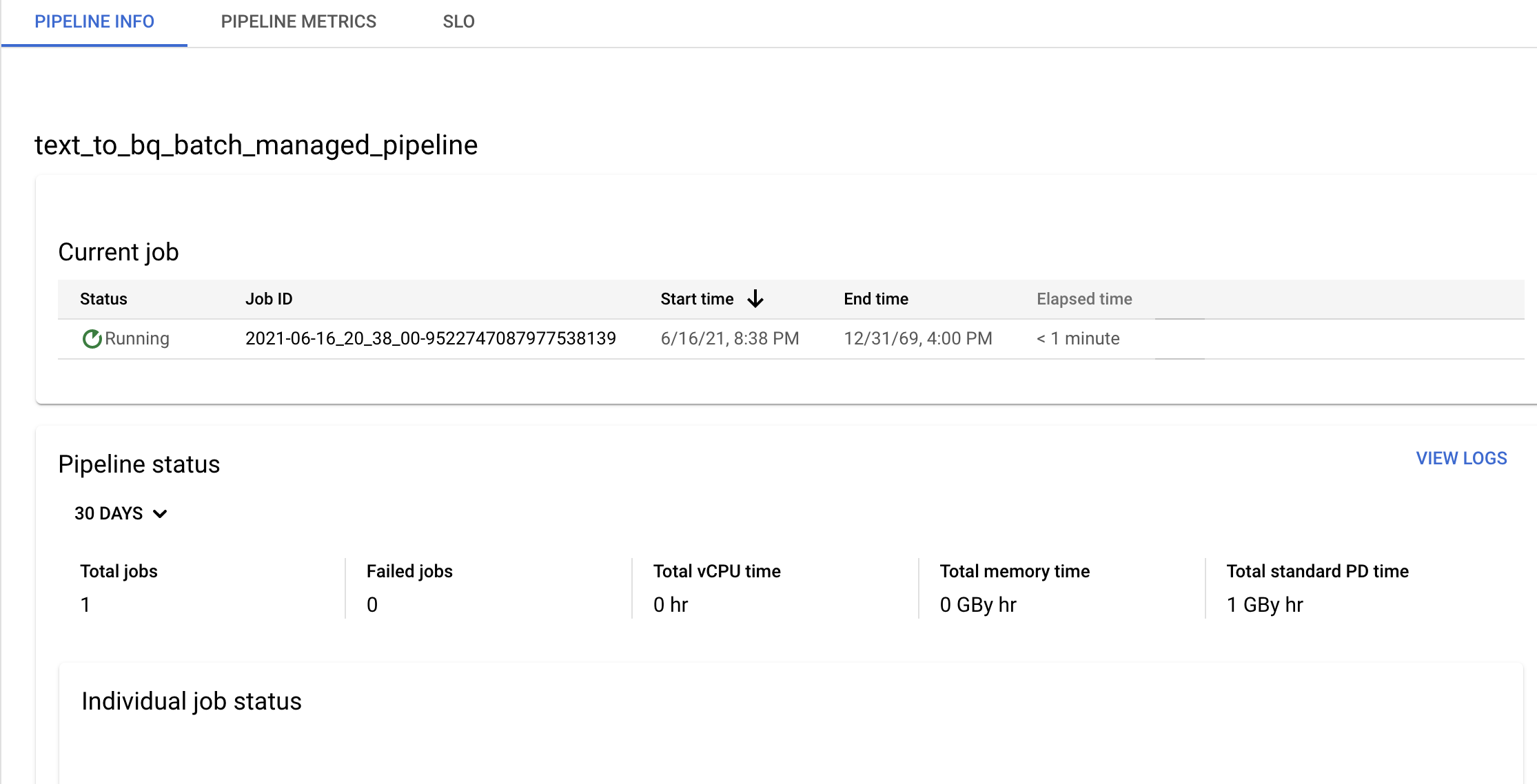
Vous pouvez modifier la programmation du pipeline de données à partir du panneau Informations sur le pipeline de la page Détails du pipeline.
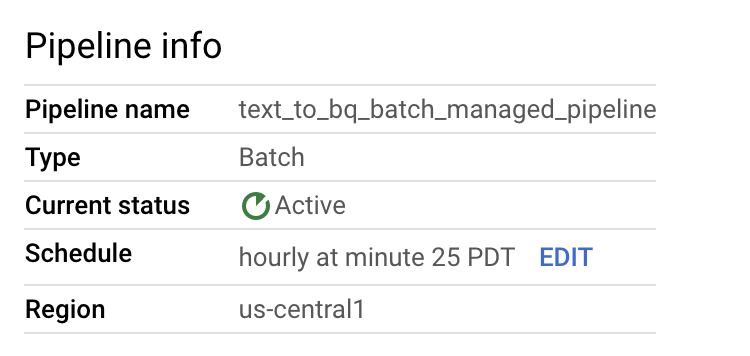
Vous pouvez également exécuter un pipeline par lot à la demande en utilisant le bouton Exécuter de la console Dataflow Pipelines.
Créer un exemple de pipeline de flux de données
Vous pouvez créer un exemple de pipeline de flux de données en suivant les instructions d'exemple de pipeline de traitement par lot, avec les différences suivantes:
- Pour Planification du pipeline, ne spécifiez pas de programmation pour un pipeline de flux de données. La tâche par flux Cloud Dataflow est immédiatement démarrée.
- Pour Modèle Dataflow, dans Traiter les données en continu (flux), sélectionnez Fichiers texte sur Cloud Storage vers BigQuery.
- Pour le Type de machine des nœuds de calcul, le pipeline traite l'ensemble initial de fichiers correspondant au modèle
gs://BUCKET_ID/inputs/file01.csvet tous les fichiers supplémentaires correspondant à ce modèle que vous importez dans le dossierinputs/. Si la taille des fichiers CSV dépasse plusieurs Go, pour éviter d'éventuelles erreurs de mémoire saturée, sélectionnez un type de machine doté d'une capacité de mémoire supérieure à celle du type de machinen1-standard-4par défaut, tel quen1-highmem-8.
Dépannage
Cette section explique comment résoudre les problèmes liés aux pipelines de données Dataflow.
Échec de lancement du job de pipeline de données
Lorsque vous utilisez des pipelines de données pour créer une programmation de job récurrent, votre job Dataflow peut ne pas se lancer, auquel cas une erreur d'état 503 apparaît dans les fichiers journaux Cloud Scheduler.
Ce problème se produit lorsque Dataflow est temporairement dans l'impossibilité d'exécuter le job.
Pour contourner ce problème, configurez Cloud Scheduler afin de relancer le job. Comme le problème est temporaire, une nouvelle tentative d'exécution du job peut aboutir. Pour en savoir plus sur la définition des valeurs de nouvelle tentative dans Cloud Scheduler, consultez la section Créer un job.
Examiner les violations des objectifs de pipeline
Les sections suivantes décrivent comment examiner les pipelines qui n'atteignent pas les objectifs de performances.
Pipelines par lots récurrents
Pour une analyse initiale de l'état de votre pipeline, sur la page Informations sur le pipeline de la console Google Cloud, utilisez les graphiques État d'un job spécifique et Durée des threads par étape. Ces graphiques se trouvent dans le panneau d'état du pipeline.
Exemple d'investigation :
Vous avez un pipeline par lot récurrent qui s'exécute toutes les heures à trois minutes de l'heure. Chaque job s'exécute normalement pendant environ neuf minutes. Vous avez pour objectif d'exécuter tous les jobs en moins de 10 minutes.
Le graphique d'état de la tâche indique que l'exécution d'une tâche a pris plus de 10 minutes.
Dans le tableau de l'historique des mises à jour/exécution, trouvez le job exécuté à l'heure qui vous intéresse. Cliquez dessus pour accéder à la page des détails du job Dataflow. Sur cette page, trouvez l'étape d'exécution la plus longue, puis recherchez dans les journaux les erreurs potentielles pour déterminer la cause du retard.
Pipelines en streaming
Pour une analyse initiale de l'état de votre pipeline, sur la page Détails du pipeline, dans l'onglet Informations sur le pipeline, utilisez le graphique de fraîcheur des données. Ce graphique se trouve dans le panneau d'état du pipeline.
Exemple d'investigation :
Vous disposez d'un pipeline de streaming qui produit normalement un résultat avec une fraîcheur des données de 20 secondes.
Vous avez fixé un objectif de 30 secondes pour garantir la fraîcheur des données. Lorsque vous examinez le graphique de fraîcheur des données, vous remarquez qu'entre 9h et 10h, la fraîcheur des données est passée à près de 40 secondes.
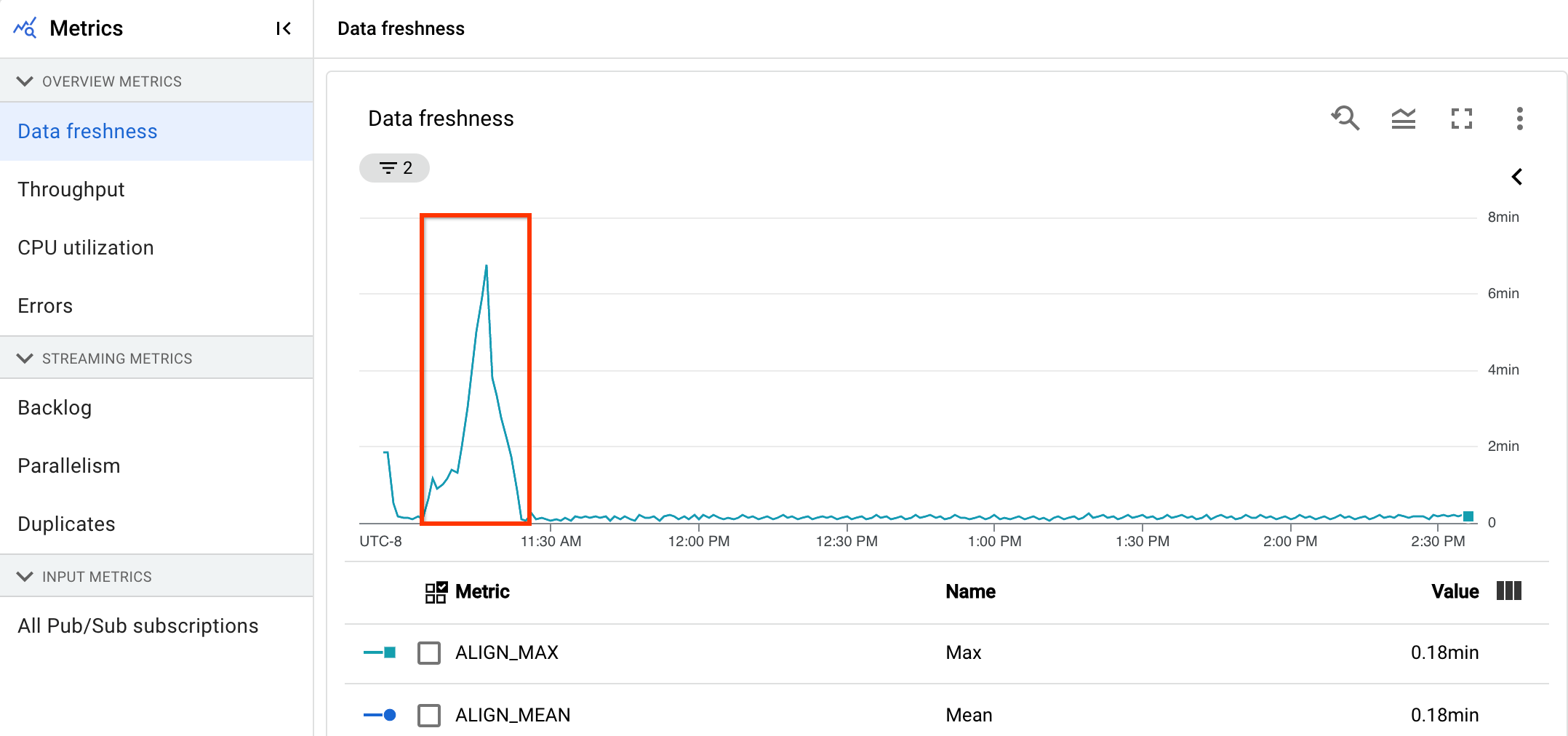
Basculez vers l'onglet Métriques du pipeline, puis affichez les graphiques d'utilisation du processeur et d'utilisation de la mémoire pour une analyse plus approfondie.
Erreur : L'ID de pipeline existe déjà dans le projet
Si vous essayez de créer un pipeline portant un nom déjà présent dans votre projet, le message d'erreur suivant s'affiche : Pipeline Id already exist within the
project. Pour éviter ce problème, choisissez toujours des noms uniques pour vos pipelines.