總覽
您可以使用 Dataflow 資料管道執行下列工作:
- 建立週期性工作排程。
- 瞭解資源在多項工作執行作業中的使用位置。
- 定義及管理資料更新間隔目標。
- 深入瞭解個別管道階段,修正及最佳化管道。
如需 API 說明文件,請參閱 Data Pipelines 參考資料。
功能
- 建立週期性批次管道,依排程執行批次工作。
- 建立週期性增量批次管道,針對最新版本的輸入資料執行批次工作。
- 使用管道摘要評量表,查看管道的匯總容量用量和資源消耗量。
- 查看串流管道的資料更新間隔。這項指標會隨時間演變,您可以將其與快訊連結,在新鮮度低於指定目標時收到通知。
- 使用管道指標圖表比較批次管道工作,並找出異常狀況。
限制
區域可用性:您可以在可用的 Cloud Scheduler 區域中建立資料管道。
配額:
- 每個專案的預設管道數量:500 個
每個機構的預設管道數量:2500
機構層級配額預設為停用。您可以選擇採用機構層級配額,如果採用,每個機構預設最多可有 2500 個管道。
標籤:您無法使用使用者定義的標籤,為 Dataflow 資料管道加上標籤。不過,使用
additionalUserLabels欄位時,這些值會傳遞至 Dataflow 工作。如要進一步瞭解標籤如何套用至個別 Dataflow 工作,請參閱「管道選項」。
資料管道類型
Dataflow 有兩種資料管道類型:串流和批次。 這兩種管道都會執行 Dataflow 範本中定義的工作。
- 串流資料管道
- 串流資料管道會在建立後立即執行 Dataflow 串流作業。
- 批次資料管道
批次資料管道會按照使用者定義的時程,執行 Dataflow 批次工作。批次管道輸入檔案名稱可以參數化,以便漸進式處理批次管道。
增量批次管道
您可以透過日期時間預留位置,為批次管道指定遞增輸入檔案格式。
- 您可以使用年、月、日、時、分和秒的預留位置,且必須遵循
strftime()格式。預留位置前面會加上百分比符號 (%)。 - 建立管道時,系統不會驗證參數格式。
- 示例:如果您指定「gs://bucket/Y」做為參數化輸入路徑,系統會評估為「gs://bucket/Y」,因為「Y」前面沒有「%」,因此不會對應至
strftime()格式。
- 示例:如果您指定「gs://bucket/Y」做為參數化輸入路徑,系統會評估為「gs://bucket/Y」,因為「Y」前面沒有「%」,因此不會對應至
在每個排定的批次管道執行時間,系統會評估輸入路徑的預留位置部分,以取得目前 (或時間偏移) 的日期時間。系統會根據排定工作時區的目前日期評估日期值。如果評估的路徑與輸入檔案的路徑相符,系統會在排定的時間擷取該檔案,並透過批次管道處理。
- 範例:批次管道排定在太平洋標準時間每小時開始時重複執行。如果您將輸入路徑參數化為
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv,在 2021 年 4 月 15 日下午 6 點 (太平洋標準時間),輸入路徑會評估為gs://bucket-name/2021-04-15/prefix-18_00.csv。
使用時移參數
你可以使用 + 或 - 分鐘或小時的時間偏移參數。
如要支援將輸入路徑與評估的日期時間相符,並在管線排程的目前日期時間之前或之後調整,請將這些參數放在大括號中。請使用 {[+|-][0-9]+[m|h]} 格式。批次管道會在排定的時間繼續重複執行,但輸入路徑會以指定的時間偏移量評估。
- 範例:批次管道排定在太平洋標準時間每小時開始時重複執行。如果您將輸入路徑參數化為
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h},在 2021 年 4 月 15 日下午 6 點 (太平洋標準時間),輸入路徑會評估為gs://bucket-name/2021-04-15/prefix-16_00.csv。
資料管道角色
如要順利執行 Dataflow 資料 pipeline 作業,您需要下列必要的 IAM 角色:
您必須具備適當的角色,才能執行作業:
Datapipelines.admin: 可執行所有資料管道作業Datapipelines.viewer:可查看資料管道和工作Datapipelines.invoker: 可叫用資料管道工作執行 (可使用 API 啟用此角色)
無論服務帳戶是由使用者指定,還是預設的 Compute Engine 服務帳戶,Cloud Scheduler 使用的服務帳戶都必須具備「
roles/iam.serviceAccountUser」角色。詳情請參閱資料管道角色。您必須能夠充當 Cloud Scheduler 和 Dataflow 使用的服務帳戶,方法是在該帳戶上獲授
roles/iam.serviceAccountUser角色。如果未選取 Cloud Scheduler 和 Dataflow 的服務帳戶,系統會使用預設的 Compute Engine 服務帳戶。
建立資料 pipeline
您可以透過下列兩種方式建立 Dataflow 資料管道:
資料管道設定頁面:首次在 Google Cloud 控制台中存取 Dataflow 管道功能時,系統會開啟設定頁面。啟用所列 API 來建立資料管道。
匯入工作
您可以匯入以傳統或彈性範本為基礎的 Dataflow 批次或串流工作,並將其設為資料管道。
前往 Google Cloud 控制台的 Dataflow「Jobs」(工作) 頁面。
選取已完成的工作,然後在「Job Details」頁面中,選取「+Import as a pipeline」。
在「Create pipeline from template」(使用範本建立管道) 頁面中,系統會填入匯入工作的選項參數。
如果是批次工作,請在「Schedule your pipeline」部分中,提供週期性排程。 您可以視需要提供 Cloud Scheduler 的電子郵件帳戶地址,用於排定批次執行時間。如未指定,系統會使用預設的 Compute Engine 服務帳戶。
建立資料 pipeline
前往 Google Cloud 控制台的 Dataflow「資料管道」頁面。
選取「+ 建立資料管道」。
在「使用範本建立管道」頁面中,提供管道名稱,並填寫其他範本選取和參數欄位。
如果是批次工作,請在「Schedule your pipeline」部分中,提供週期性排程。 您可以視需要提供 Cloud Scheduler 的電子郵件帳戶地址,用於排定批次執行時間。如未指定值,系統會使用預設的 Compute Engine 服務帳戶。
建立批次資料管道
如要建立這個範例批次資料管道,您必須有權存取專案中的下列資源:
- Cloud Storage 值區,用於儲存輸入和輸出檔案
- 用來建立資料表的 BigQuery 資料集。
這個管道範例使用「Cloud Storage Text 到 BigQuery」批次管道範本。這個範本會從 Cloud Storage 讀取 CSV 格式的檔案、執行轉換,然後將值插入含有三個資料欄的 BigQuery 資料表。
在本機磁碟機上建立下列檔案:
bq_three_column_table.json檔案,內含目的地 BigQuery 資料表的下列結構定義。{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }split_csv_3cols.jsJavaScript 檔案,可對輸入資料進行簡單轉換,再插入 BigQuery。function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }file01.csv含有多筆記錄的 CSV 檔案,這些記錄會插入 BigQuery 資料表。b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
使用
gcloud storage cp指令,將檔案複製到專案的 Cloud Storage bucket 中的資料夾,如下所示:將
bq_three_column_table.json和split_csv_3cols.js複製到gs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/將
file01.csv複製到gs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
在 Google Cloud 控制台,前往 Cloud Storage「Buckets」(值區) 頁面。
如要在 Cloud Storage bucket 中建立
tmp資料夾,請選取資料夾名稱開啟「Bucket details」(值區詳細資料) 頁面,然後按一下「Create folder」(建立資料夾)。
前往 Google Cloud 控制台的 Dataflow「資料管道」頁面。
選取「建立資料管道」。在「使用範本建立管道」頁面中,輸入或選取下列項目:
- 在「Pipeline name」(管道名稱) 部分輸入
text_to_bq_batch_data_pipeline。 - 在「區域端點」部分,選取 Compute Engine 地區。 來源和目的地區域必須相符。因此,Cloud Storage 值區和 BigQuery 資料表必須位於相同區域。
在「Dataflow template」(Dataflow 範本) 欄位中,選取「Process Data in Bulk (batch)」下的「Text Files on Cloud Storage to BigQuery」(將 Cloud Storage 中的文字檔案遷移至 BigQuery)。
在「Schedule your pipeline」(安排 pipeline 時間) 中,選取排程,例如時區的「Hourly」(每小時),並在第 25 分執行。提交管道後,您仍可編輯時間表。 您可以視需要提供 Cloud Scheduler 的電子郵件帳戶地址,用於排定批次執行作業。如未指定,系統會使用預設的 Compute Engine 服務帳戶。
在「Required parameters」(必要參數) 中,輸入下列內容:
- 「Cloud Storage 中的 JavaScript UDF 路徑」:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- 針對「JSON path」(JSON 路徑):
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- 「JavaScript UDF name」:
transform - 在「BigQuery output table」(BigQuery 輸出資料表) 中:
PROJECT_ID:DATASET_ID.three_column_table
- 在「Cloud Storage input path」(Cloud Storage 輸入路徑) 中:
BUCKET_ID/inputs/file01.csv
- 「臨時 BigQuery 目錄」:
BUCKET_ID/tmp
- 在「Temporary location」(臨時位置) 中:
BUCKET_ID/tmp
- 「Cloud Storage 中的 JavaScript UDF 路徑」:
按一下「建立管道」。
- 在「Pipeline name」(管道名稱) 部分輸入
確認管道和範本資訊,並在「管道詳細資料」頁面中查看目前和先前的記錄。
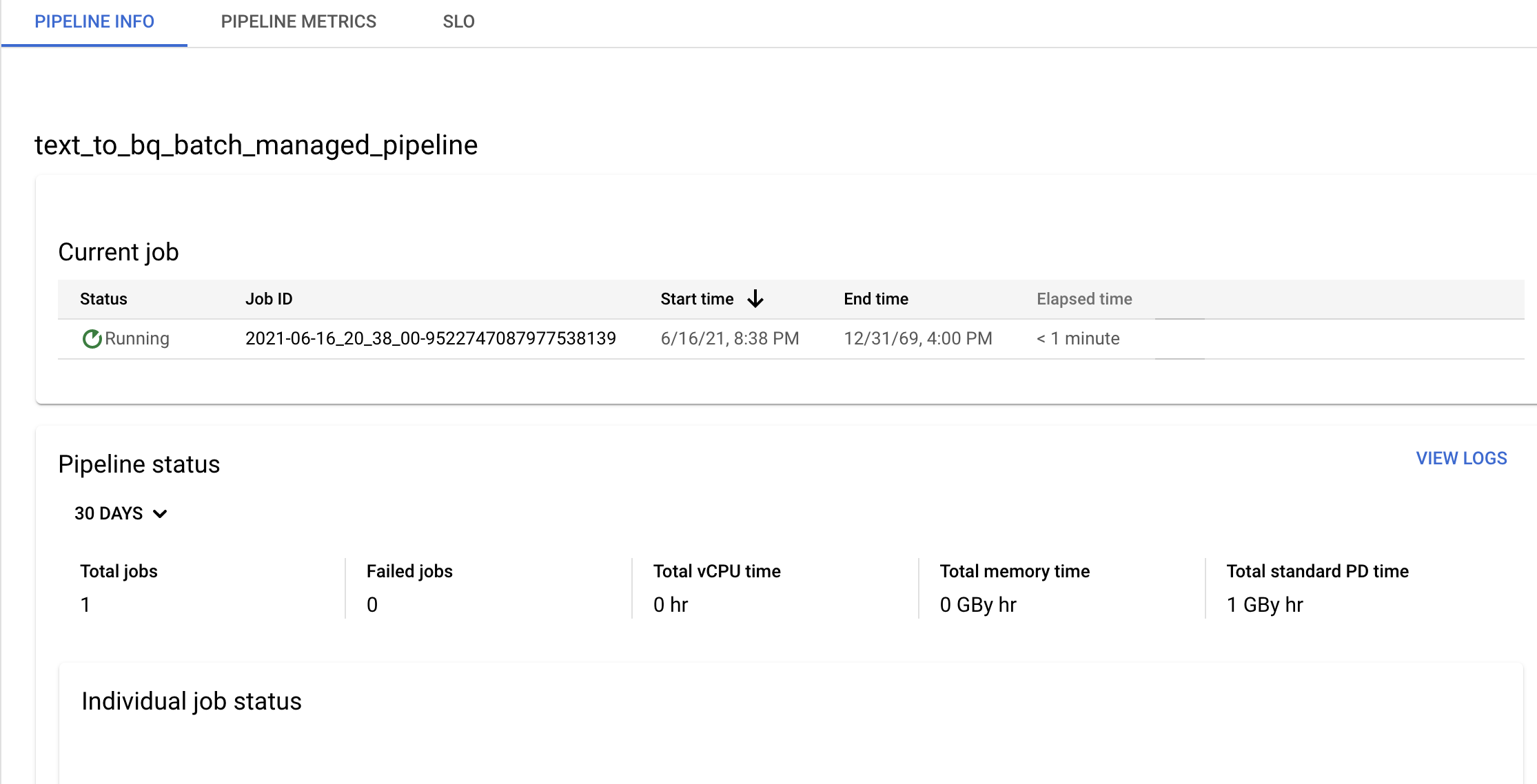
您可以在「管道詳細資料」頁面的「管道資訊」面板中編輯資料管道排程。
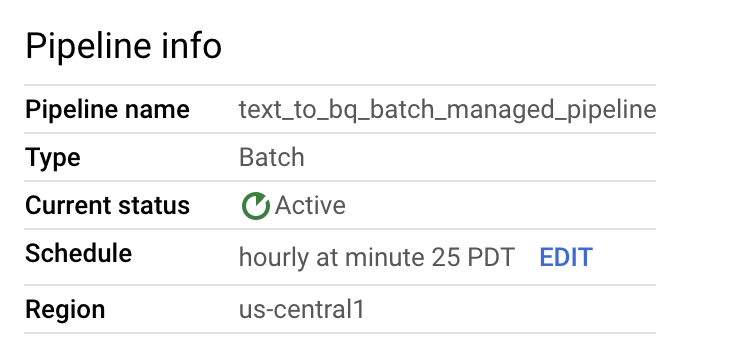
您也可以使用 Dataflow Pipelines 控制台中的「執行」按鈕,視需要執行批次管道。
建立範例串流資料管道
您可以按照範例批次管道操作說明建立範例串流資料管道,但有以下差異:
- 如果是管道排程,請勿為串流資料管道指定排程。Dataflow 串流工作會立即啟動。
- 在「Dataflow template」(Dataflow 範本) 欄位中,選取「Process Data Continuously (stream)」下方的「Text Files on Cloud Storage to BigQuery」。
- 對於「工作站機器類型」,管道會處理符合
gs://BUCKET_ID/inputs/file01.csv模式的初始檔案集,以及您上傳至inputs/資料夾的任何符合此模式的其他檔案。如果 CSV 檔案大小超過數 GB,為避免發生記憶體不足錯誤,請選取記憶體容量高於預設n1-standard-4機器類型的機器類型,例如n1-highmem-8。
疑難排解
本節說明如何解決 Dataflow 資料管道的問題。
無法啟動資料管道工作
使用資料管道建立週期性工作排程時,Dataflow 工作可能無法啟動,且 Cloud Scheduler 記錄檔中會顯示 503 狀態錯誤。
如果 Dataflow 暫時無法執行作業,就會發生這個問題。
如要解決這個問題,請設定 Cloud Scheduler 重試工作。由於問題是暫時性的,因此重試作業時可能會成功。如要進一步瞭解如何在 Cloud Scheduler 中設定重試值,請參閱「建立工作」。
調查管道目標違規情形
下列各節說明如何調查未達到效能目標的管道。
週期性批次管道
如要初步分析管道的健康狀態,請在控制台的 Google Cloud 「Pipeline info」(管道資訊) 頁面中,使用「Individual job status」(個別工作狀態) 和「Thread time per step」(每個步驟的執行緒時間) 圖表。這些圖表位於管道狀態面板中。
調查範例:
您有一個每小時執行一次的批次 pipeline,時間是每小時的 3 分。每項工作通常會執行約 9 分鐘。您的目標是讓所有工作在 10 分鐘內完成。
工作狀態圖顯示工作執行時間超過 10 分鐘。
在「更新/執行」記錄表格中,找出在所需時間執行的工作。按一下前往 Dataflow 工作詳細資料頁面。 在該頁面上找出執行時間較長的階段,然後查看記錄檔中是否有錯誤,判斷延遲原因。
串流管道
如要初步分析管道的健康狀態,請在「Pipeline Details」(管道詳細資料)頁面的「Pipeline info」(管道資訊)分頁中,使用資料新鮮度圖表。這個圖表位於管道狀態面板中。
調查範例:
您設定的目標是確保資料更新間隔為 30 秒。查看資料更新間隔圖表時,您會發現上午 9 點到 10 點之間,資料更新間隔突然跳到將近 40 秒。
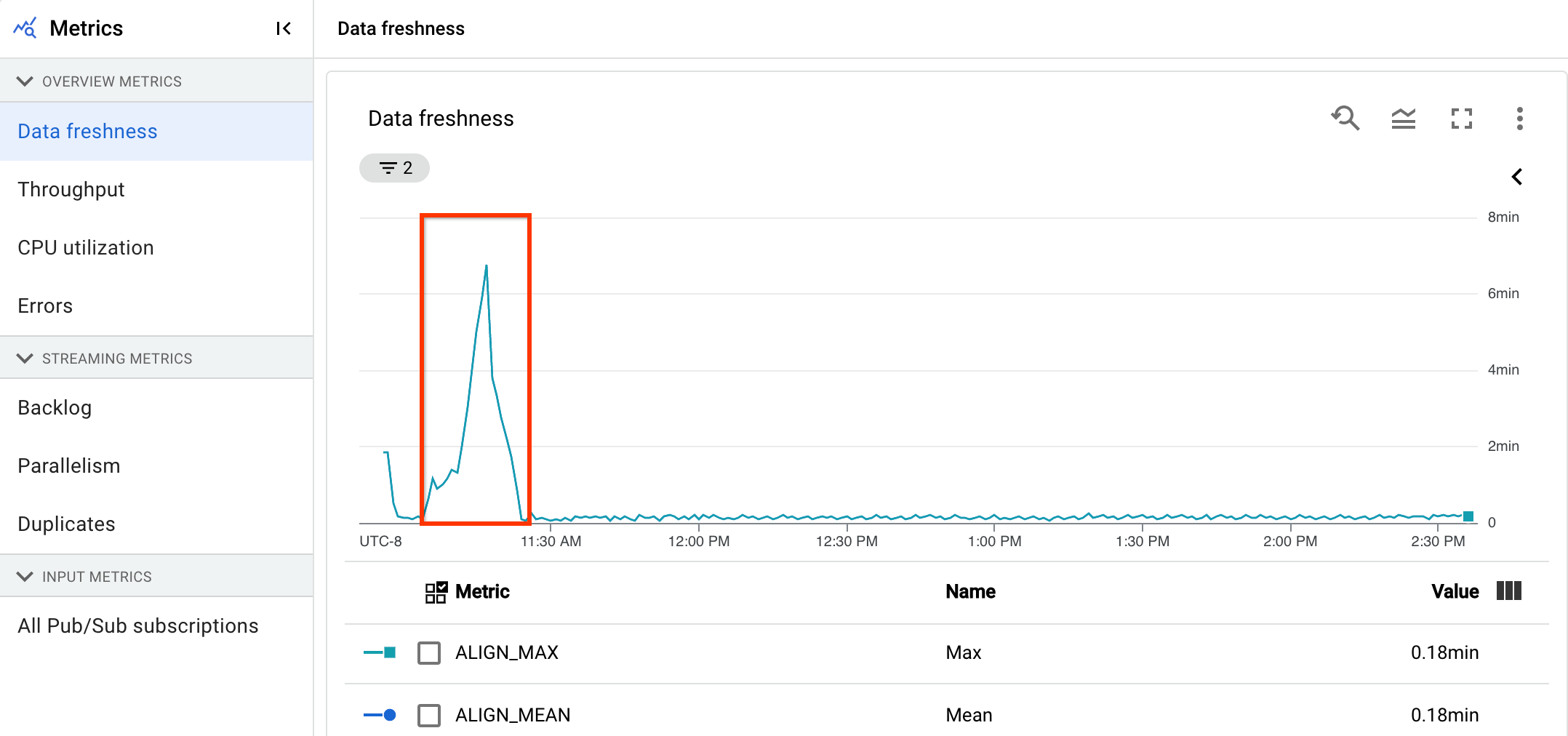
切換至「管道指標」分頁,然後查看 CPU 使用率和記憶體使用率圖表,進行進一步分析。
錯誤:專案中已有管道 ID
如果您嘗試建立新管道,但專案中已有同名管道,就會收到這則錯誤訊息:Pipeline Id already exist within the
project。為避免發生這個問題,請務必為管道選擇不重複的名稱。