Vous pouvez afficher les graphiques de surveillance de l'autoscaling pour les jobs de streaming dans l'interface de surveillance Dataflow. Ces graphiques affichent des métriques sur la durée d'une tâche de pipeline et incluent les informations suivantes :
- Nombre d'instances de nœuds de calcul utilisées par votre job à tout moment
- Fichiers journaux de l'autoscaling
- Estimation de l'évolution de la quantité de jobs en attente
- Utilisation moyenne du processeur au fil du temps
Les graphiques sont alignés verticalement pour pouvoir corréler les métriques d'utilisation des processeurs et du traitement en attente avec les événements de scaling des nœuds de calcul.
Pour en savoir plus sur la manière dont Dataflow prend des décisions d'autoscaling, consultez la documentation sur les fonctionnalités de réglage automatique. Pour en savoir plus sur la surveillance et les métriques Dataflow, consultez la page Utiliser l'interface de surveillance Dataflow.
Accéder aux graphiques de surveillance de l'autoscaling
Vous pouvez accéder à l'interface de surveillance Dataflow à l'aide deGoogle Cloud console. Pour accéder à l'onglet des métriques de l'Autoscaling, procédez comme suit :
- Connectez-vous à la console Google Cloud .
- Sélectionnez votre projet Google Cloud .
- Ouvrez le menu de navigation.
- Dans Analyse, cliquez sur Dataflow. Une liste des tâches Dataflow ainsi que leur état respectif apparaissent.
- Cliquez sur le job que vous souhaitez surveiller, puis sur l'onglet Autoscaling.
Surveiller les métriques d'autoscaling
Le service Dataflow choisit automatiquement le nombre d'instances de nœud de calcul nécessaires à l'exécution de votre tâche d'autoscaling. Le nombre d'instances de nœud de calcul peut changer au fil du temps en fonction des exigences de la tâche.
Vous pouvez afficher les métriques d'autoscaling dans l'onglet Autoscaling de l'interface Dataflow. Chaque métrique est organisée dans les graphiques suivants :
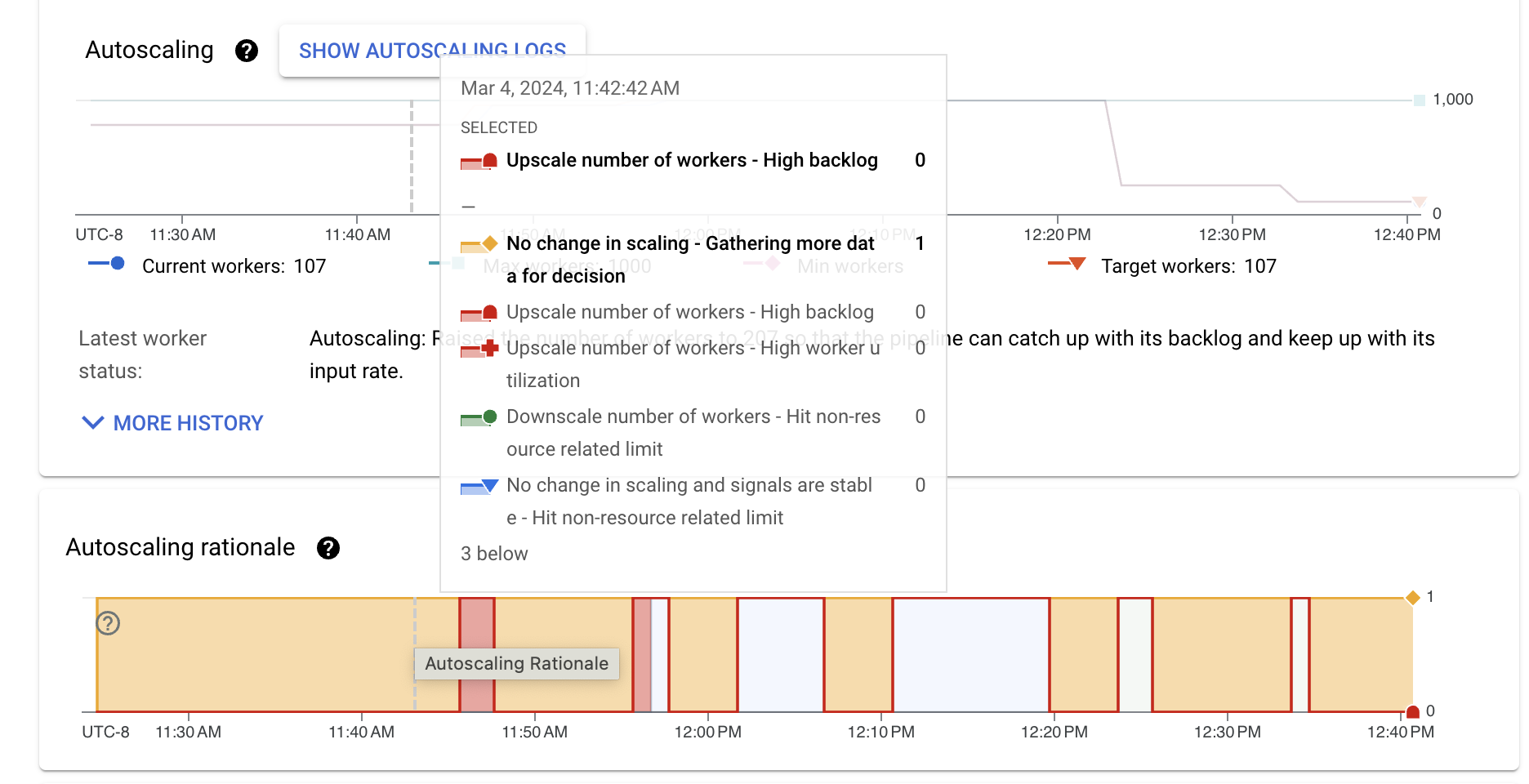
La barre d'action d'autoscaling affiche l'état actuel de l'autoscaling et le nombre de nœuds de calcul.
Autoscaling
Le graphique Autoscaling affiche un graphique de séries temporelles du nombre actuel de nœuds de calcul, du nombre cible de nœuds de calcul, et du nombre minimal et maximal de nœuds de calcul.

Pour afficher les journaux d'autoscaling, cliquez sur Show autoscaling logs (Afficher les journaux d'autoscaling).
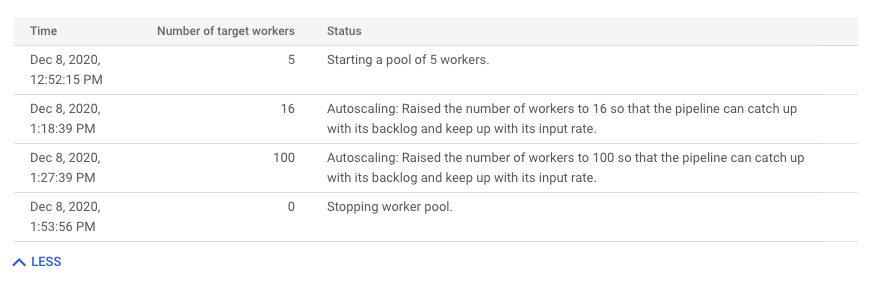
Pour afficher l'historique des modifications de l'autoscaling, cliquez sur Plus d'entrées d'historique. Une table contenant des informations sur l'historique des nœuds de calcul de votre pipeline s'affiche. L'historique inclut les événements d'autoscaling, y compris si le nombre de nœuds de calcul a atteint le nombre minimal ou maximal.
Logique d'autoscaling (Streaming Engine uniquement)
Le graphique Logique d'autoscaling indique pourquoi l'autoscaler a effectué un scaling à la hausse ou à la baisse, ou n'a effectué aucune action pendant une période donnée.
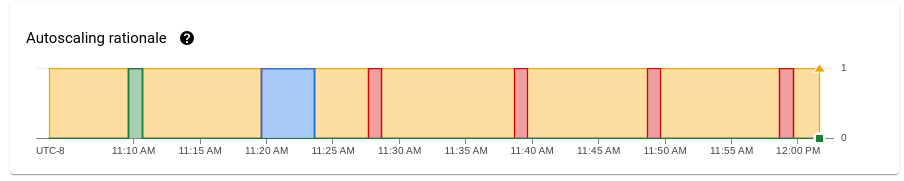
Pour afficher une description de la logique à un point spécifique, maintenez le pointeur de la souris sur le graphique.
Le tableau suivant répertorie les actions de scaling et les raisons possibles du scaling.
| Action de scaling | Explication | Description |
|---|---|---|
| Aucun changement au niveau du scaling | Nous recueillons des données supplémentaires pour prendre une décision | L'autoscaler ne dispose pas de suffisamment de signaux pour effectuer un scaling à la hausse ou à la baisse. Par exemple, l'état du pool de nœuds de calcul a récemment changé, ou les métriques d'utilisation ou de messages en attente fluctuent. |
| Aucun changement au niveau du scaling, signaux stables | Limite non liée aux ressources atteinte | La mise à l'échelle est limitée par un paramètre tel que le parallélisme des clés ou le nombre minimal et maximal de nœuds de calcul configurés. |
| Faible nombre de jobs en attente et utilisation élevée des nœuds de calcul | L'autoscaling du pipeline a convergé vers une valeur stable compte tenu du trafic et de la configuration actuels. Aucune modification de scaling n'est nécessaire. | |
| Effectuer un scaling à la hausse | Attente élevée | Nous avons augmenté nos capacités pour réduire le backlog. |
| Utilisation élevée des nœuds de calcul | Scaling à la hausse pour atteindre l'utilisation cible du processeur. | |
| Vous avez atteint une limite non liée aux ressources | Le nombre minimal de nœuds de calcul a été modifié, et le nombre actuel de nœuds de calcul est inférieur au minimum configuré. | |
| Scaling à la baisse | Faible utilisation des nœuds de calcul | Réduction de la taille pour atteindre l'utilisation cible du processeur. |
| Vous avez atteint une limite non liée aux ressources | Le nombre maximal de nœuds de calcul a été mis à jour, et le nombre actuel de nœuds de calcul est supérieur au maximum configuré. |
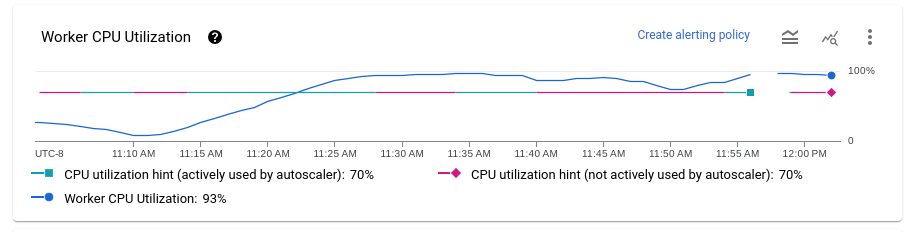
Utilisation du processeur par nœud de calcul
L'utilisation du processeur correspond à la quantité de processeur utilisée, divisée par la quantité de processeur disponible pour le traitement. Le graphique Utilisation moyenne du processeur indique l'utilisation moyenne du processeur pour tous les nœuds de calcul au fil du temps, l'optimisation d'utilisation des nœuds de calcul et si Dataflow a utilisé activement l'optimisation en tant que cible.
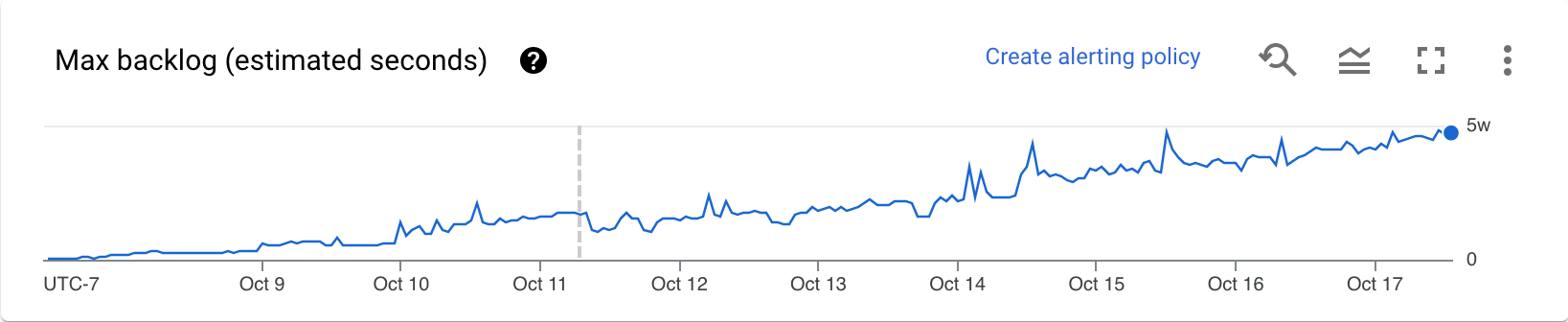
En attente (Streaming Engine uniquement)
Le graphique En attente fournit des informations sur les éléments en attente de traitement. Le graphique fournit une estimation du temps en secondes nécessaire pour absorber les tâches en attente actuelles si aucune nouvelle donnée n'arrive, et que le débit ne change pas. Le temps d'attente estimé est calculé à partir du débit et des octets en attente de la source d'entrée à traiter. Cette métrique est utilisée par la fonctionnalité d'autoscaling de flux pour déterminer quand effectuer un scaling à la hausse ou à la baisse.
Les données de ce graphique ne sont disponibles que pour les jobs qui utilisent Streaming Engine. Si votre job de streaming n'utilise pas Streaming Engine, le graphique est vide.
Recommandations
Voici quelques comportements que vous pouvez observer dans votre pipeline, ainsi que des recommandations sur la façon de régler l'autoscaling :
Réduction excessive de la taille : Si l'utilisation du processeur cible est trop élevée, il est possible que Dataflow effectue un scaling à la baisse dans un modèle. Le nombre de tâches en attente commence alors à augmenter, et Dataflow effectue à nouveau un scaling à la hausse pour compenser, au lieu de converger vers un nombre stable de nœuds de calcul. Pour résoudre ce problème, essayez de définir une valeur d'optimisation de l'utilisation des nœuds de calcul inférieure. Observez l'utilisation du processeur au moment où le nombre de tâches en attente commence à augmenter et définissez l'optimisation d'utilisation du processeur sur cette valeur.
La mise à l'échelle est trop lente. Si la mise à l'échelle est trop lente, elle peut être en retard sur les pics de trafic, ce qui entraîne des périodes de latence accrue. Essayez de réduire la valeur d'optimisation de l'utilisation des nœuds de calcul pour que Dataflow augmente la capacité plus rapidement. Observez l'utilisation du processeur au moment où le nombre de tâches en attente commence à augmenter et définissez l'optimisation d'utilisation du processeur sur cette valeur. Surveillez à la fois la latence et le coût, car une valeur d'indication plus faible peut augmenter le coût total du pipeline si davantage de nœuds de calcul sont provisionnés.
Augmentation excessive de la résolution : Si vous constatez un scaling à la hausse excessif, ce qui entraîne une augmentation des coûts, envisagez d'augmenter la valeur d'optimisation de l'utilisation des nœuds de calcul. Surveillez la latence pour vous assurer qu'elle reste dans les limites acceptables pour votre scénario.
Pour en savoir plus, consultez Définir l'indication d'utilisation des nœuds de calcul. Lorsque vous testez une nouvelle valeur d'indication d'utilisation des workers, attendez quelques minutes que le pipeline se stabilise après chaque ajustement.
Étapes suivantes
- Ajuster l'autoscaling horizontal pour les pipelines de traitement en flux continu
- Résoudre les problèmes liés à l'autoscaling de Dataflow